Fakulteten för teknik och samhälle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Cyklisters upplevda otrygghet i urban miljö – En studie med
klusteranalys
Cyclists’ perceived insecurity in urban environment - An unsupervised machine learning study
Alexander Persson Masud
Viktor Olsson
Examen: Kandidatexamen 180 hp Handledare: Johan Holmgren Huvudområde: Datavetenskap Examinator: Jan Persson Program: Informationsarkitekt
Sammanfattning
Lunds kommun har som mål att vara en ledande kommun i Sverige när det kommer till att främja användandet av cykeln som transportmedel. Genom maskininlärningstypen
klusteranalys undersöker vi om det är möjligt att analysera data generad av cyklister i Lund, för att kartlägga cyklisters upplevda otrygghet i trafiken. Syftet med att utföra klusteranalysen är att kostnadseffektivare kunna vidareutveckla en säker miljö för cyklister. Detta gör vi genom att baserat på algoritmen k-means utvecklat två olika ansatser. Dels en ansats baserad på euklidisk distans och en ansats som är punktbaserad. Dessa ansatser kontrollerar storleken på kluster för att matcha de geografiska ytor som vi arbetade med. Den euklidiska ansatsen genererar kluster baserat på storlek i meter medans den punktbaserade ansatsen genererar kluster efter antalet punkter i ett kluster. I våra experiment pekar resultaten på att den euklidiska ansatsen är bättre lämpad för
klusteranalyser. Vi anser även att användbarheten av att utföra klusteranalyser med våra ansatser inte är tillräcklig för att klusteranalyser ska bli mer användbart än icke
maskininlärningsbaserade analyser. Genom att komplettera ytterligare variabler i
datamängden och jämföra klusteranalyser över tid så anser vi att klusteranalys kan få ett mervärde.
Abstract
The municipality of Lund strives to be a leading municipality in Sweden regarding bicycle usage as a means of transportation. With the machine learning type cluster analysis, we want to examine the possibility of analysing data generated by cyclist in Lund in order to understand cyclists perceived insecurity in traffic. The purpose of performing cluster analysis was to more cost efficiently further enhance a safer environment for cyclists. We perform our analysis based on the K-means algorithm and further develop two different methods. The first method is based on Euclidian distance and the second method is based on the amount of datapoints in a given cluster. These methods control for the size of a cluster in order to match the geographical space we are working with such as roads and crossings. The Euclidian method generates clusters based on size in meters and the other method
generates clusters based on amount of datapoints. In our experiment the result shows that the Euclidian method is more suited for cluster analysis. We also believe that the usability of cluster analysis with our methods isn't sufficient in order for us to believe that cluster
analysis is more usable than none machine learning analysis. By adding additional variables to the data collection and comparing cluster analyses over time we believe that cluster analysis could be of more value.
Innehållsförteckning
1 Inledning ... 4 1.1 Syfte ... 4 1.2 Forskningsfrågor ... 4 1.3 Datainsamling ... 5 1.4 Relaterad forskning ... 5 2 Teoretisk bakgrund ... 8 2.1 Maskininlärning ... 82.2 Icke övervakad maskininlärning ... 8
2.3 Klusteranalys ... 8 2.4 Armbågsmetoden ... 10 3 Metod ... 11 3.1 Litteratursökning ... 12 3.2 Databearbetning ... 12 3.2.1 Avvikande data ... 12 3.2.2 Normalisering ... 13 3.2.3 Tidsintervall ... 13 3.3 Experiment ... 13 3.4 Validering ... 14 3.5 Metoddiskussion ... 14 3.6 Implementering ... 15 3.6.1 Utvecklingsmiljö ... 15 3.6.2 Scikit-learn ... 15 3.6.3 Pandas ... 15 3.6.4 QGIS ... 15 4 Databearbetning ... 16 4.1 Tidsintervall ... 16 4.2 Avvikande data ... 18 4.3 Klusterstorlek ... 18 5 Experiment ... 19
5.1 Experiment 1 - Euklidisk distans, tidsintervall: 00:00-24:00 ... 20
5.2 Experiment 2 - Euklidisk distans, tidsintervall: 07:00 – 09:00 ... 22
5.3 Experiment 3 - Euklidisk distans, tidsintervall: 16:00 – 18:00 ... 24
5.4 Experiment 4 - Punktbaserad, tidsintervall: 00:00-24:00 ... 26
5.6 Experiment 6 - Punktbaserad, tidsintervall: 16:00 - 18:00 ... 30
6 Analys och diskussion ... 32
6.1 Lämpligheten av metod, när är vilken metod lämplig? ... 32
6.2 Analys av grafer ... 32
6.3 Vilka delar av Lund kunde vi identifiera som problemområde? ... 32
6.4 Diskussion om hierarkisk klustermetod ... 34
6.5 Klusterstorlek ... 34
6.6 Utvärdering av klusterstorlek ... 34
6.7 Validitetshot ... 34
6.8 Lämplighet av klustermetoder på GPS-data ... 35
7 Slutsatser ... 37
8 Framtida arbete ... 38
8.1 Vädret ... 38
8.2 Årstider och dagsljus ... 38
8.3 Jämföra med olycksstatisk ... 38
8.4 Vikta data med trafikflöde ... 38
8.5 Ålder och kön ... 38
8.6 Konvex klusterkontroll ... 38
8.7 Hierarkisk klustermetod ... 39
1 Inledning
Cykeln har många fördelar jämfört med bilen, vilka till exempel innefattar minskat utsläpp av växthusgaser och minskning av hälsofarliga gaser så som koloxid samt sot [1]. Dessutom bidrar det till en lägre bullernivå, vilket bidrar till bättre hälsa [2]. Cykeln bidrar även till enklare transporter inom stadsmiljöer och bättre parkeringsmöjligheter, då den gör anspråk på mindre plats av gatorna samt gör att cyklisten spenderar mindre tid fast i kö. Kostnaden för en cykel kontra en bil är oftast lägre och på så sätt mer ekonomiskt tilltalande. Det finns flertalet olika typer av cyklar på marknaden, huvudsakligen vanliga trampcyklar och
lådcyklar. Dessa typer av cyklar finns dessutom som eldrivna alternativ. Försäljningen av elcyklar ökade 2018 med 53% jämfört med 2017 och stod för 19% av den totala
cykelförsäljningen [3]. Totalt sätt minskar dock försäljningen av cyklar, men mäter man cykelmarknadens värde så stiger den. Förklaringen till detta är att svenskar köper dyrare cyklar med högre kvalitet samt gör mer verkstadsbesök, snare än nyköp [3]. Under senare år har det även uppkommit självbemannade stationer med lånecyklar som ett sätt att främja användandet av cykeln som transportmedel.
I Lund har antalet cyklister på stadens gator ökat med 24% sedan 1992 [4]. Statistik för 2017 visar att det, under året förekom 1405 cykelrelaterade olyckor i Lunds tätort [5]; trots detta menar WHO att cyklister lever längre även om det innebär en viss ökad risk för att råka ut för olyckor [6]. Lunds kommun har samtidigt en vision om att ligga i framkant som cykelkommun både i Sverige och i Europa. Sedan 2011 har kommunen årligen legat i topp 3 bland de bästa cykelkommunerna i Sverige [7]. Kommunen har dessutom hållbarhetsmål som
innefattar minskade koldioxidutsläpp. Dessa utsläpp ska minskas bland annat genom ett mål om att cykeltrafiken per invånare ska öka 1% per år [8]. Utöver miljömål så beräknas
befolkningen att öka i antal från att 2018 vara ca 123 000 personer till att 2031 vara ca 146 000 personer [9].
Ska dessa mål och visioner infrias så måste kommunen fortsätta att arbeta med
trafiksäkerheten, för att på så sätt göra det mer främjande för cyklister att transportera sig genom staden. Ett sätt att öka säkerheten för cyklister är att skapa större förståelse för när cyklister uppfattar trafiksituationer som osäkra och genom detta skapa ett bättre underlag för framtida investeringar i vägar och cykelinfrastruktur. Genom att kartlägga osäkerhet i trafiken så undersöker vi om maskininlärning har något mervärde för att identifiera problemområde för cyklister i urbana miljöer.
1.1 Syfte
Vår studie syftar till att skapa en bättre förståelse för när cyklister uppfattar trafiksituationer som osäkra. Detta kan vara bra att utforska för att kostnadseffektivare kunna vidareutveckla en säker miljö för cyklister. Mer specifikt kommer vi undersöka mervärdet som icke
övervakad maskininlärning kan ha när man analyserar trafiksäkerhet.
1.2 Forskningsfrågor
Den fråga som uppsatsen utgår ifrån är:
Hur kan man använda icke övervakad maskininlärning för att identifiera platser för cyklisters upplevda otrygghet?
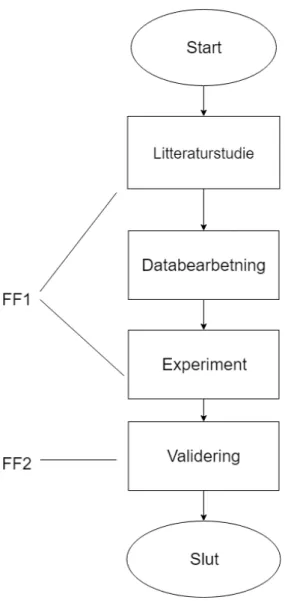
För att besvara denna fråga har vi formulerat följande underfrågor: • FF1: Vad är en lämplig klusteralgoritm för att gruppera cykeldata?
Genom att utföra en litteratursökning så undersöker vi styrkor och svagheter på kända klusteralgoritmer för att hitta en lämplig algoritm.
• FF2: Vad är en lämplig storlek på ett kluster?
Genom mätningar av geografiska ytor undersöker vi lämpliga klusterstorlekar och genom experiment undersöker vi hur vida dessa storlekar är lämpliga.
Genom att besvara FF1 och FF2 är vårt mål att implicit besvara vår huvudfråga.
1.3 Datainsamling
De data som detta arbete utgår ifrån har samlats in av Trivector AB inom ramen för det Vinnova-finansierade projektet ”Smarta Offentliga Miljöer 2”1. Företaget har med hjälp av barometrar monterat på cykelstyren samlat in data genom att deltagare tryckt på den knapp som finns på barometern när de känt sig otrygga.
1.4 Relaterad forskning
Forsberg & Gonzalez Alvarez [10] jämför prestanda mellan två olika klusteralgoritmer, där de undersöker vilken algoritm som lämpar sig bäst till undersökning av skadliga program, klassificering av trafik, nätverksdata, hälsodata och klimatanalyser. Specifik så redovisar de resultat för klustermetoderna means och DBSCAN. Då vårt arbete kommer att använda k-means så ger denna uppsats en tydlig och klar blid över vilka begräsningar och fördelar som k-means har. I uppsatsen så beskriver Forsberg & Gonzalez Alvarez även hur det går till att implementera k-means algoritmen, samt hur databearbetningen typisk går till. Resultat indikerar att k-means är bättre än DBSCAN för att hitta mönster på bekostnad av generalisering.
Grira m.fl. [11] undersöker icke övervakad maskininlärning och tekniker för att samla och klassificera data. Grira m.fl. diskuterar tekniker som till exempel hierarkiska klustermetoder som visar ett dendrogram vilket redogör relationer mellan kluster. De redogör också för hur det går till att validera och utvärdera de resultat som klusteranalyserna producerar. Här finns det ytterligare underkategorier för att på olika sätt utvärdera de resultat som finns till
exempel genom att undersöka den data som används i förhållande till de kluster som skapats. Författarna beskriver också olika frågeställningar som andra kan utgå ifrån när utvärderingar ska göras, ett exempel på detta är naturliga kluster i en datamängd och om dessa finns med i resultatet vilket kan påvisa att klusteralgoritmen har utförts korrekt.
Kodinariya m.fl. [12] studerar metoder för att bestämma det optimala antalet kluster som ska skapas av k-means. Författarna redogör för 6 olika metoder bland annat armbågsmetoden som är den äldsta för att avgöra antalet kluster. Kodinariya m.fl. redogör grundligt för varje metod för att ge en inblick i de olika metodernas styrkor och svagheter. Ett exempel på en svaghet hos armbågsmetoden är att den kurva som görs på en graf kan ibland vara svår att avläsa för bästa resultat. Då författarna grundligt redogör för experimenten och metoderna så får läsaren en guide för vilken metod som passar deras datamängd bäst.
Xu m.fl. [13] undersöker cyklisters trafikflöde, där de bland annat använder algoritmen k-means. De undersöker och testar en modell för att förutspå trafikflödet i städer. Modellen har tre steg, vilka är normalisering av data, k-means och prediktion med en stödvektormaskin. Författarna förklarar att normaliseringen behövs för att effektivare kunna skapa kluster med k-means och därmed få ett bättre resultat. Prediktion med en stödvektormaskin används för att sedan skapa modellen som förutspår trafikflödet. Detta är en studie som redovisar och nyttjar maskininlärning för att identifiera samband i data för att skapa en större förståelse för vilka parametrar som spelar roll för att avgöra beteende hos cyklister.
Knorr & Ng [14] presenterar ett antal algoritmer som hanterar avvikande punkter (eng: outliers) i stora datamängder. En av algoritmerna implementeras genom användandet av nästlade loopar för att beräkna distansen mellan punkter. I denna algoritm delas
datamängden upp i två halvor för att jämföra data i syfte att ta bort avvikande datapunkter. Värdet av de beräkningar som utförts sparas ner och kontrolleras mot ett maximumvärde. När det beräknade avståndet går över maximumvärdet så stannar beräkningarna, eftersom en avvikande punkt har blivit identifierad och tas därmed bort.
Anderson [15] undersöker möjligheten att använda klusteralgoritmen k-means för att studera platser i trafiken som är särskilt olycksdrabbade. Författaren skapar en modell för att
gruppera olyckorna för att sedan kartlägga och visualisera dessa. Anderson använder sig av kernel density estimation för att generera celler som representerar antalet olyckor. Dessa lägger sedan grunden för klusteralgoritmen k-means som används för att gruppera och analysera data. Från resultatet identifierar Anderson kluster som har störst antal punkter vilket tyder på att just dessa områden har extra mycket olyckor. Anderson nämner också att större kluster med fler olyckor beror på att ett större antal människor rör sig på dessa
områden vilket är viktigt för att vikta data. Viktning av data är viktigt för att få ett resultat som representerar verkligheten samt för att jämföra om antalet olyckor är proportionerligt med antalet människor som rör sig där.
Ganganath m.fl. [16] utvecklar en modifierad version av k-means. Den modifierade algoritmen har utvecklats så att den kan begränsa antalet datapunkter i ett kluster. Författarna beskriver även att deras algoritm kan användas på specifika kluster vilket betyder att alla kluster inte blir påverkade.
Vogel m.fl. [17] utforskar med hjälp av klusteranalys stationer för hyrcyklar. Genom att genomföra en klusteranalys, bland annat med hjälp av k-means, undersöker de möjligheten att kategorisera självbemannade hyrcykelstationer utifrån när cyklar typiskt hämtas och lämnas. Genom analyser skapar författarna en bild av vilka stationer som bör hamna i vilken av de 5 olika typerna av stationer som författarna skapat. Detta innefattar till exempel
PMRE(eng: Pickup Morning, Return Evening) och RMPE(eng: Returns Morning Pickups Evening). Genom denna studien skapar Vogel m.fl. en kartläggning i syfte att främja användandet av cykel som transportmedel genom att se till att det finns cyklar på rätt stationer utifrån hur användningsmönstret ser ut.
Abu Abbas [18] presenterar en studie som undersöker olika klusteralgoritmer.
Klusteralgoritmerna som undersöks är k-means, hierarkisk klustering, självorganiserad kartklustering och förväntan och maximerings algoritmer (EM). Författaren jämför
algoritmerna baserat på storlek på datamängd, antal kluster, typ av datamängd och typ av mjukvara. Resultaten visar att k-means och EM har bättre prestandard än hierarkisk klustering samt att k-means och EM fungerar bättre på stora datamängder. Författaren skriver också att både k-means och EM är väldigt känsliga för avvikande datapunkter. Detta innebär att resultatet blir påverkat om detta inte hanteras. K-means och EM har även en annan nackdel vilket är att algoritmerna generaliserar mer än de andra som testats vilket innebär att datapunkter inte får en lika precis indelning, vilket även visades av Forsberg m.fl. [10].
Xu & Tao [19] använder k-means för att undersöka olyckor på specifika typer av vägar. I studien så fokuserar författarna på en motorväg i Kina och med hjälp av en modell som identifierar var på vägen olika typer av olyckor typiskt förekommer. Författarna har genomfört databearbetning för att avlägsna faktorer som eventuellt kan påverka resultatet negativt. Det kan till exempel innebära att avvikande datapunkter orsakar variation i hur data blir tolkat och eventuellt leda till resultat med låg precision. Genom att utföra experiment så lyckades
författarna identifiera hotspots vilket innebär att deras metod lyckats identifiera
olycksbenägna platser. Författarna förklarar att den metod som användes bidrar till att ta bort vanligt förekommande problem som kan uppstå när flera variabler används i
klusteranalyser. En annan positiv aspekt som författarna nämner med sin modell är att den kan anpassas till andra geografiska ytor och inte är begränsad till endast motorvägar. Denna artikeln hjälper vårt arbete då vi har en utgångspunkt till vilken algoritm som används men även vilka steg som ska tas innan en klusteranalys görs.
2 Teoretisk bakgrund
2.1 Maskininlärning
Maskininlärning är ett område inom artificiell intelligens. Mer konkret är maskininlärning en process som används för att bygga datamodeller genom att automatiskt anpassa parametrar vilket ger möjligheten att forma och observera data. Genom denna process kan man säga att datorn lär sig själv att förstå data. Detta möjliggör för en dator att förutspå ny data och förstå den bättre [20].
Övergripande finns det två typer av maskininlärning. Den första är övervakad inlärning (eng: supervised learning). Denna typ av maskininlärning handlar om att bygga maskiner som lär sig generalisera baserat på märkta exempel medan icke-övervakad inlärning (eng:
unsupervised learning) handlar om att gruppera datapunkter som hör ihop baserat på datapunkternas ingående egenskaper [20]. Då vår studie fokuserar på icke övervakad maskininlärning så beskriver vi denna typ av maskininlärning mer i detalj nedan.
2.2 Icke övervakad maskininlärning
I icke övervakad maskininlärning låter man maskinen gruppera datapunkter som hör ihop avseende datamängdens ingående parametrar, vanliga metoder för detta är klustring av data eller dimensionell reduktion [20].
Icke övervakad maskininlärning kan ge mervärde när data analyseras, då klusteranalyser kan användas för att klassificera och gruppera data med gemensamma egenskaper [11]. Det som skiljer sig från övervakad maskininlärning är användandet av etiketter (eng: labels). Labels är något som är viktigt när övervakad maskininlärning används för att klassificera data medans icke övervakad maskininlärning inte använder sig av färdiggjorda labels utan skapar en egen modell som grupperar data i klasser. Icke övervakad maskininlärning används också för att analysera data när användaren inte vet vilket resultat som ska produceras [21]. Detta innebär att maskinen inte får någon tränings- eller validerings data, då personen som implementerar inte skapar modellen för hur data delas in, utan detta utförs istället av maskinen. Då vi inte vet vad ett korrekt resultat är så kommer vi inte att använda övervakad maskininlärning utan använder icke övervakad maskininlärning.
2.3 Klusteranalys
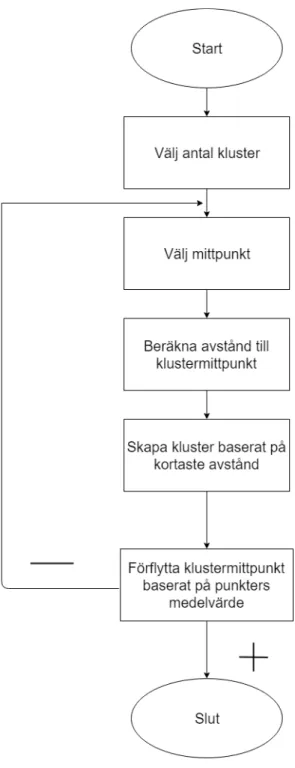
K-means algoritmen arbetar efter euklidisk distans och är bra på att upptäcka mönster i datamängder. Det är en välkänd algoritm som skapades på 1960-talet och därmed finns det mycket information om algoritmens styrkor och svagheter. K-means bygger på att algoritmen ska dela in x antal datapunkter i n antal kluster, vilket hanteras iterativt. När ett klustercenter placeras så räknas den euklidiska distansen ut och de punkter som ligger närmast kommer då att tillhöra den givna klustermittpunkten. Varje klustermittpunkts plats uppdateras iterativt så att den ligger på medelvärdet för alla tillhörande punkter. När ett kluster inte längre får några nya punkter när det itereras, så terminerar algoritmen och därmed så har en mängd kluster skapats. K-means illustreras i Figur 1.
Vanderplaas [20] förklarar att orsaken till att k-means är så effektivt beror på att den bygger på den så kallade ”Expectation and Maximization” delen av algoritmen. Denna algoritm är vanligt förekommande inom datavetenskapen och k-means använder algoritmen för att gissa var mittpunkter för kluster ska placeras. ”Expectation” steget innebär att punkter tilldelas till kluster baserat på vilken mittpunkt som ligger närmst, sedan kommer ”maximization” steget där varje klustermittpunkt flyttas till punkternas medelvärde. Dessa steg upprepas tills att ingen klustermittpunkt i en iteration inte förflyttar sig.
Ett problem som ofta uppstår i klusteranalyser är hantering av avvikande datapunkter. Avvikande datapunkter brukar sägas bero på mänskliga, mekaniska eller systematiska fel som uppstår när datainsamling sker, även datapunkter som inte är fel kan vara avvikande. Detta skapar problem i slutresultatet då kluster inte produceras optimalt och resultatet därför får minskad trovärdighet. Avvikande datapunkter kan upptäckas på flertalet sätt bland annat genom euklidisk distans då punkters avstånd mäts för att kontrollera avståndet till närmaste punkt eller genom att analysera de kluster som genererats [14].
2.4 Armbågsmetoden
En viktigt del av en klusteranalys är att bestämma vilket antal kluster som är optimalt. Då k-means tar antalet kluster som en inparameter, behöver man typiskt undersöka olika antal kluster, vilket kan göras med armbågsmetoden [12]. Detta innebär att en graf används för att visuellt avgöra optimala antalet kluster. Denna metod producerar en kurva när antalet kluster jämförs i förhållande till summan av fel i kvadrat. När förändringen i y-axeln, där andel
felaktiga värden finns avtar kraftigt så finns det optimala k-värdet, det vill säga antalet kluster vid den punkt där värdena på y-axeln slutar påvisa stora förändringar.
3 Metod
För att besvara våra forskningsfrågor har vi genomfört den sekvens av aktiviteter som vi presenterar i flödesschemat i Figur 2. I metoden ingår att ta fram modeller som vi senare använder för att utföra vårt experiment. I vår beskrivning av metoden redovisar stegvis hur resultaten skapas och vilka valideringsmetoder som används.
3.1 Litteratursökning
Vi använder litteratursökningen för att stärka det vi skriver med bevis samt för att undersöka vilka gap det finns inom vårt forskningsområde. Vårt mål är att undersöka hur andra inom arbetsområdet hanterar problem så att vi antingen kan använda existerande metoder eller använda egna metoder med inspiration ifrån den litteratur vi undersöker.
För att besvara FF 1 har vi gjort en litteratursökning och hittat en studie som gjorts utav Forsberg m.fl. [10]. I studien testas algoritmerna k-means och DBSCAN. I uppsatsen beskriver författarna att k-means är bra på att skapa tydliga mönster av data på bekostnad av större generaliseringar. Detta gör att vi väljer k-means då det finns mervärde i vårt arbete att identifiera mönster i cyklisters upplevda otrygghet för att få en uppfattning av vilka delar av Lund som cyklister anser otrygga samt vilka faktorer som kan vara gemensamma för dessa områden. En annan artikel som också diskuterar och jämföra olika klusteralgoritmer baserat på faktorer som datamängd och prestandard, artikeln är skriven av Abu Abbas [18]. I denna artikel så jämför författaren fler algoritmer för att ta reda på styrkor och svagheter när klusteralgoritmer används. Författaren kommer fram till att k-means är bra på större
datamängder och har en bättre prestandard i jämförelse med de andra algoritmerna. En negativ aspekt med k-means är att algoritmen är känslig för avvikande datapunkter, därför så är det viktigt att hantera dessa punkter innan algoritmen implementeras. I vårt arbete så värdesätter vi prestandard mycket och detta blir då en viktig aspekt till varför vi väljer k-means över till exempel en hierarkisk klustermetod.
I vår studie så använder vi grundutförandet av k-means vilket innebär att vi inte har
möjligheten att påverka klusterstorlek på samma sätt som Ganganath m.fl. [16] gör. I syfte att göra en rimlig avgränsning för vår studies storlek valde vi att inte modifiera k-means algoritmen utan istället genom en iterativ process öka antalet kluster för att på så sätt minska deras storlek.
För att hitta relevanta och vetenskapliga källor använder vi Google Scholar och IEEE Xplore. Vi använder oss av följande sökord för att utföra litteratursökningen.
• K-means bicycle • K-means clustering • K-means validation
• Unsupervised Machine Learning
• Unsupervised Machine Learning bicycle • Unsupervised Machine Learning clustering • Clustering accidents bicycle
3.2 Databearbetning
3.2.1 Avvikande data
Vi hanterar avvikande data som är irrelevant, till exempel på grund av att punkterna ligger utanför Lund eller att de ligger i Lund men är isolerade och därför inte kan antas vara en del av ett kluster. Anledningen till att ta bort dessa enskilda koordinater är att klustren annars måste inkludera dessa punkter, vilket kan komma att resultera i stora kluster som är svårare att tolka. Vi tar även bort koordinater som vi anser har för låg träffsäkerhet, det vill säga att koordinaternas precision har varit för låg och därför inte kan anses vara tillförlitliga.
Borttagning av ensamma datapunkter görs genom att mäta avståndet till närmaste punkt, om avståndet till den närmsta punkten är över ett maximalt värde så tas den bort då detta
kan påverka våra resultat, då vi inte vill att kluster ska täcka för stora geografiska områden. På grund av hur ett typiskt trafiknätverk ser ut vill vi att kluster endast ska täcka korsningar och vägar. Sedan kontrollerar vi våra datapunkter efter dubbletter, då vi identifierat att vår datamängd innehåller dubbletter, det vill säga flera datapunkter som representerar samma knapptryckning av samma cyklist.
I datakällan anges alla koordinaters precision i meter, och för att skapa tillförlitliga kluster kan det därför finnas ett mervärde att ta bort de punkter som har för hög felmarginal. Om dessa punkter inte tas bort så riskerar kluster att inkludera punkter som i verkligheten inte ligger nära varandra.
3.2.2 Normalisering
För att ge kluster tydliga avgränsningar och en användbar form har vi normaliserat våra data punkter enligt formeln z = x – min(x) / max(x) – min(x), där x syftar till varje koordinat och min(x) och max(x) är den minsta respektive den största datapunkten i hela datamängden. Normalisering används för att konvertera alla värden från GPS-koordinater till ett intervall mellan 0 och 1. Detta görs så att värdena viktas likvärdigt och för att skillnaderna mellan värdena på X och Y axlarna inte ska skilja sig i större uträckning. Anledningen till detta är att k-means annars får svårt att genom sin algoritm göra tydliga avgränsningar i klustren. Normaliseringen görs efter att alla avvikande punkter tagits bort ifrån datamängden.
3.2.3 Tidsintervall
I vår studie har vi valt att undersöka olika tidsintervall. Anledningen till detta är att se skillnader i antalet klick under olika tider på dygnet. För att hitta de mest intressanta
tidsintervallerna så har vi skapat histogram som visar hur antalet knapptryck fördelar sig på ett typiskt dygn i vår datamängd.
3.3 Experiment
I detta arbete så använder vi klustermetoden K-means. Algoritmen arbetar efter euklidisk distans och är bra på att upptäcka mönster i datamängder på bekostnad av generalisering. I detta steg så är det viktigt att ha gjort all hantering av data som krävs. Som nämnts ovan tar algoritmen k-means antal kluster som en parameter. Detta är en viktig del då antalet kluster avgör hur data blir grupperad och tolkad. Som beskrivits ovan är armbågsmetoden en vanlig metod för att avgöra hur många kluster som är optimalt, men det värdet som produceras från armbågsmetoden är dock inte alltid det bästa alternativet. Det finns situationer där enklare metoder kan användas, som till exempel att sätta antalet kluster väldigt högt för att sedan iterativt reducera det tills att ett bättre resultat uppstår.
Armbågsmetoden producerar ett väldigt lågt antal kluster på vår data, vilket gör att vi inte kommer att använda armbågsmetoden för att avgöra det optimala antalet kluster. Vi
använder istället en iterativ process som kontrollerar klusterstorlek och genom den metoden så får vi antalet kluster som används.
I undersökning av tidsintervall så finns det stora skillnader på antalet knapptryck. Under morgonen så sker det ett stort antal knapptryck vilket gör det lämpligt för klusteranalys. Samma sak gäller under eftermiddagen. Dessa två tidsintervall omfattar rusningstrafik vilket kan vara en förklarning till det höga antalet knapptryck. Antalet knapptryck under lunch, kväll och natt är inte tillräckligt höga för att någon signifikant slutsats ska kunna göras. Dessa tidsintervall inkluderas därför endast när alla tider tillsammans studeras.
I vår studie vill vi kunna visualisera och granska trafikflödet för olika tidsintervaller så som morgon och kväll. På grund av detta har vi valt att implementera en möjlighet att visualisera de olika datapunkterna baserat på när på dygnet de skapades. Anledningen till detta är att vi
vill undersöka trafikflöde för rusningstrafik och identifiera skillnader mellan olika dygnsperioder.
Inom ramen för vår studie har vi valt att utvärdera två olika ansatser för att avgöra hur många kluster som är optimalt. Båda är iterativa i avseendet att de båda bygger på att vi utvärderar olika värden på k tills dess att vi är klara.
I den första ansatsen som är punktbaserad beräknar vi antal punkter för varje kluster i en iterativ process och på så sätt kontrollerar vi att inget kluster är större än det maximala antalet datapunkter som tillåts i ett kluster. Om något kluster visar sig innehålla fler punkter än den maximala klusterstorleken så höjs värdet på k vilket innebär att k-means åter appliceras med k = k+1. Detta görs sedan tills att inget kluster innehåller fler punkter än det angivna maxvärdet för klusterstorlek.
I den andra ansatsen så kontrollerar vi storleken på kluster baserat på den euklidiska distansen av klustret räknat från klustrets mittpunkt till den punkt som ligger längst bort. Genom att mäta avståndet från varje punkt i klustret och dess mittpunkt erhåller vi en uppskattning av klustrets spatiala storlek. Om denna distans är högre än det maxvärde som vi satt så körs algoritmen om igenom med 1 kluster mer.
För att avgöra vilka maxvärden som vi sätter så granskar vi den geografiska yta som vi arbetar med. I detta fall så arbetar vi med gatutrafik vilket innebär att korsningar och vägar är av intresse, vilket har gjort att vi har mätt den generella storleken på dessa geografiska ytor för att på så sätt bestämma önskad maximal klusterstorlek. Detta har gjorts genom att mäta avstånd i Google Maps på korsningar för att få en uppfattning om deras storlekar.
Efter detta öppnar vi vår data i QGIS som är ett program som kan användas för att sätta ut koordinater på en karta. I QGIS importeras och visualiseras sedan alla
GPS-koordinater från vår data på en karta där GPS-GPS-koordinaterna har olika färger baserat på vilket kluster de tillhör. Vi producerar även en heatmap med samma kluster och punkter för att i ett senare skedde kunna jämföra eventuella skillnader mellan en heatmap och våra klustermetoder.
3.4 Validering
Validering är en viktig del av klusteranalyser. Syftet med validering i vår studie är att
kontrollera att kluster som skapas har en lämplig storlek, vilket för vår del syftar till lämpliga storlekar som matchar korsningar och vägar i ett trafiknätverk. Vi kontrollerar därför visuellt att kluster som skapas inte får en större storlek än dessa geografiska ytor. En nackdel med denna metod är att uppfattningen av vad som anses vara en lämplig klusterstorlek är subjektivt, dessutom varierar lämplig klusterstorlek beroende på korsningars storlek.
3.5 Metoddiskussion
I en av våra ansatser har vi valt att bygga kluster utifrån antal punkter i respektive kluster. Ansatsen som baseras på antalet punkter i ett kluster valdes för att den enkelt kontrollerar storleken på respektive kluster samt att metoden var så pass enkel att vi snabbt kunde utveckla den. Nackdelen med denna metod är att den blir känslig för var de ingående datapunkterna som är geografiskt lokaliserad, närmare bestämt är den känslig för antalet datapunkter i datakällan. Detta gör det i sin tur svårare att kunna uttala sig om metodens lämplighet för klusteranalys. I vår andra metod, det vill säga den euklidiska varianten så finns inte denna svagheten då algoritmen inte har någon övre gräns för hur många punkter som får lov att finnas i ett kluster. Nackdelen med denna metod är däremot att den är mycket långsammare än föregående metod.
Ett alternativ till klusteranalys är att använda sig utav enkäter och intervjuer för att identifiera platser som cyklister anser vara otrygga. Nackdelen med denna metod i jämförelse med vår är att hitta ett lämpligt antal deltagare samt tiden det tar respondenter att komma ihåg och fylla i korrekta svar i de enkäter som används, vilket kan leda till svårigheter att få tillräckligt med data till en studie samt problem med kvalitet. Med vår metod så automatiserar vi hantering och gruppering av användardata.
3.6 Implementering
3.6.1 Utvecklingsmiljö
Vi arbetar med Python 3.5 via ett verktyg som heter Jupyter Notebook. Jupyter Notebook använder celler för att köra sektioner av den kod som skrivits. Detta underlättar arbete med maskininlärning då resultat ofta behöver presenteras visuellt. Jupyter är en molntjänst vilket innebär att vi kan utföra beräkningar mycket snabbare.
3.6.2 Scikit-learn
För att implementera vår klustermetodik använder vi maskininlärningsbiblioteket scikit-learn som fokuserar på både icke övervakad och övervakad maskininlärning [22]. En viktig fördel med Scikit-learn är att paketet ger oerfarna användare möjligheten att implementera och arbeta med de större och mer välkända algoritmer som används inom maskininlärning. Scikit-learn använder sig av både biblioteken Numpy och Scipy för att hantera data och utföra matematiska beräkningar, vilket är något som uppkommer frekvent inom
maskininlärning.
3.6.3 Pandas
Då vi arbetar med dataanalys i detta arbete så har vi valt att använda paketet pandas för att modifiera och hantera data. Pandas använder PandasDataFrames [23] för att hantera importerade data från till exempel en CSV fil, PandasDataFrames behåller samma form som importerade filer har vilket gör det enkelt att arbeta med.
3.6.4 QGIS
QGIS är ett så kallat GIS-verktyg, där GIS står för ”Geografiskt informationssystem”, som möjliggör arbete med av olika typer av kartor. GIS-verktyg används ofta för analys och tolkning av objekt i geografiska miljöer [24]. Detta innebär till exempel att koordinater kan skrivas ut på en karta för att visuellt tolka hur de fördelas och vilka samband de har. QGIS har även en inbyggd Python-konsol så att användare kan köra script, importera data och automatisera förändringar som eventuellt kan uppstå på datamängder. I vår studie använde vi QGIS och importerade en karta från Google Maps. Genom detta kunde vi använda de koordinatpunkter som vi haft för att utföra klusteranalys, för att sedan tolka och presentera dessa.
4 Databearbetning
4.1 Tidsintervall
Tabell 1 visar indelningen av dygnets timmar i vår klusteranalys, där indelning är baserad på det histogram som Figur 3 visar. Tabell 1 visar tidsintervall för rusningstider vilket är det intervall som vi arbetar efter.
Rusningstrafik morgon 07:00 – 09:00
Rusningstrafik eftermiddag 16:00 – 18:00 Tabell 1: tidsintervaller
Histogrammet i Figur 3 representerar hur antalet knapptryck varierar över dygnets 24 timmar, där de ogiltiga punkterna inte finns med. Mellan tiderna 07:00 -09:00 och 16:00 - 18:00 kan man se att antalet knapptryck är som högst, vilket är anledningen till att vi valt att studera dessa tidsintervall i detalj. Som högst tenderar det att vara cirka 300 knapptryck per timme.
Figur 3: Histogram med antal knapptryck över dygnets timmar
Histogrammet i Figur 4 representerar antalet knapptryck som gjorts på morgonen mellan 05:15 - 10:00. Antalet tryck är som högst under tiderna 07:45 och 08:15, då det sker 380 knapptryck. Efter detta tidsintervall så sjunker antalet tryck och ökar inte anmärkningsvärt igen under morgontimmarna.
Figur 4: Histogram med antal knapptryck över morgon
Histogrammet i Figur 5 representerar antalet knapptryck för eftermiddagen mellan 14:15 och 18:00, där det som högst sker ca 130 knapptryck runt 16:45-17:00.
Figur 5: Histogram med antal knapptryck över eftermiddag
Baserat på histogrammen i Figur 3–5 har vi valt att genomföra våra kluster analyser för olika tidsintervall då det finns kan finnas skillnader för vilka geografiska platser som har flest knapptryck vilket kan utläsas från Tabell 1.
4.2 Avvikande data
I våra experiment väljer vi att ta bort alla punkter som har 50 meter eller mer till närmsta punkt. Anledningen till detta är att de punkter som ligger i denna kategori kan påverka skapande av kluster då dessa punkter inte kan kopplas till objekt i ett trafiknätverk på ett tydligt sätt. Om värdet är satt lägre så riskerar även de punkter som är relevanta att tas bort och om brytpunkten är satt högre än 50 meter så blir risken att punkter som inte har
mervärde att gå omärkta förbi.
Vi undersöker också värdet för felmarginalen på koordinater då vi inte vill arbeta med värde som har mäts med för stor felmarginal. Vi väljer därför 40 meter på grund av att vi ville komma ner på en så låg nivå att de återstående punkter som är kvar bildar kluster vid korsningar och vägar samtidigt som vi inte tar bort punkter som faktiskt är relevanta. Om felmarginalen har ett för stort värde så produceras inte tillförlitliga kluster.
4.3 Klusterstorlek
Efter att vi undersökt storleken på korsningar i Lund så har vi valt att variera den maximala klusterstorleken i den euklidiska metoden från 20 till 35 meter. Eftersom vi utvärderar två olika ansatser väljer vi att sätta samma värde på ansatsen som hanterar antalet punkter i ett kluster då antalen som valts ovan representerar de geografiska område som vi undersöker.
5 Experiment
Experimenten är baserade på de två metoder för att bestämma antal kluster som beskrivs i Avsnitt 4.3. Experiment 1–3 är baserat på den euklidiska metoden det vill säga att klustrens maximala storlek anges i meter där till exempel en avgränsning på 20 meter betyder att avståndet från ett klusters mittpunkt till given koordinat maximalt får lov att vara 20 meter, varje experiment görs för avgränsnings värdena 20, 25, 30 och 35. Experiment 4–6 är baserat på antal punkter i ett kluster. Detta betyder att ett klusters storlek inte bestäms av någon geografisk storlek utan endast avgränsas baserat på antal punkter i ett kluster.
Samtliga experiment tar bort koordinater som inom en radie av 50 meter ligger ensamma (se i Avsnitt 4.2). I experiment 1 och 4 inkluderas koordinater från alla tidsintervall på dygnet. Experiment 2 och 5 använder endast koordinater i tidsintervallet 07:00-09:00 och i experiment 3 och 6 används endast koordinater i tidsintervallet 16:00-18:00, en kort sammanfattning av experimenten finns i Tabell 2.
Klustertyp Klustervariabel Alla tider Morgon Eftermiddag Euklidisk 20,25,30,35 meter Experiment 1 Experiment 2 Experiment 3 Antal punkter 20,25,30,35 punkter Experiment 4 Experiment 5 Experiment 6
Tabell 2: Tabell över experiment och dess typ.
Tabellerna 3–8 visar de parametrarna som vi experimenterar med, det vill säga antingen maximal klusterstorlek i meter eller max klusterstorlek i antal punkter samt antalet kluster från varje delexperiment. Varje experiment har 4 grafer som visar storleken i kluster i
förhållande till antalet kluster. Dessa grafer är sorterade från a – d i stigande ordning där a är den minsta storleken och d är den största. Y-axeln visar på storleken inom ett kluster, X-axeln visar antalet kluster. För att utläsa graferna kan man studera grafernas lutning där en brantare minskning innebär att klustren har större varians i storlek. Graferna visar även median (röd) och medelvärde (grön) för klustrens avstånd till deras centroider.
5.1 Experiment 1 - Euklidisk distans, tidsintervall: 00:00-24:00
I detta experiment använder vi den euklidiska ansatsen för tidsintervallet 00:00-24:00. Experimentet producerar 4 grafer som finns nedan, i Tabell 3 så finns antalet kluster som producerats för varje klusterstorlek.
Maximal klusterstorlek Antal kluster Median (avstånd till centroid) Medelvärde (avstånd till centroid) 20 meter 726 1,1 6,5 25 meter 642 7,4 9,4 30 meter 589 11,4 11,7 35 meter 490 17,7 17,2
Tabell 3: resultat för euklidisk distans alla tider
a) b)
Figur 6: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter i experiment 1. I varje graf visar y-axeln storleken på ett kluster och x-axeln visar klusterantalet. Median och medelvärdet som finns i Tabell 3 representeras av de röda (median) och gröna (medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive, graf vilket beror på att vi är mer intresserade av
att undersöka formen på graferna gentemot varandra snarare än att studera dem skalenligt. För att producera den kurva som visas så har vi sorterat klustren från största till minsta.
Graferna i Figur 6 visar att antalet kluster med endast en punkt minskar när värdet för klusterstorleken ökar. Det kan utläsas då den sista delen i linjen blir rak när antalet kluster med endast en punkt börjar. Den delen av linjen blir kortare när den maximala
klusterstorleken ökas. Det går även att se att linjerna för median och medelvärde närmare sig när den maximala klusterstorleken ökar. Detta betyder att den metoden som har en större tillåten klusterstorlek generellt producerar större kluster.
5.2 Experiment 2 - Euklidisk distans, tidsintervall: 07:00 – 09:00
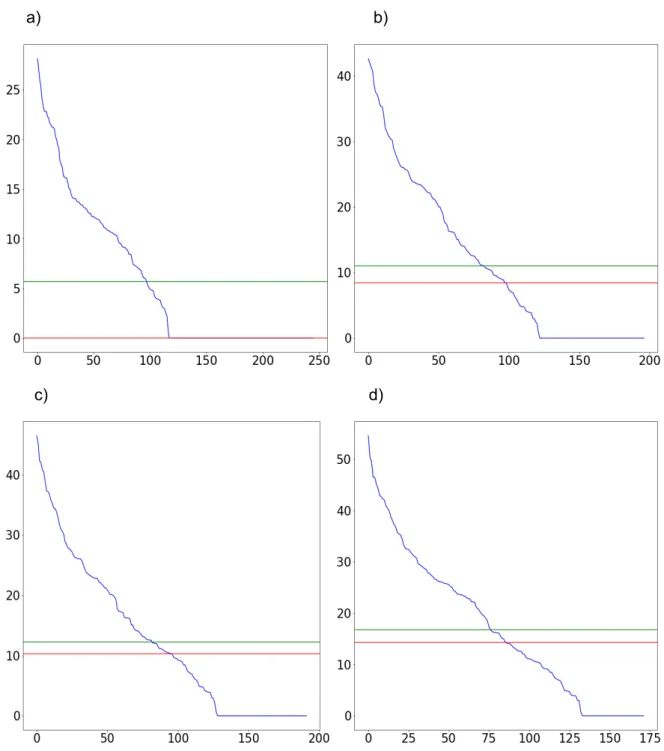
I experiment 2 så har den euklidiska ansatsen använts för att skapa kluster för tidsintervallet 07:00 – 09:00. Tabell 4 visar de resultat som hör till respektive klusterstorlek. Experimentet har producerat 4 grafer som presenteras i Figur 7.
Maximal klusterstorlek Antal kluster Median (avstånd till centroid) Medelvärde (avstånd till centroid) 20 meter 217 5,8 6,7 25 meter 180 8,7 10,1 30 meter 159 13,2 14,3 35 meter 153 13,8 15,4
Tabell 4: resultat för euklidisk distans morgonrusningstrafik a) b)
Figur 7: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter i experiment 2. I varje graf visar y-axeln storleken på ett kluster och x-axeln visar klusterantalet. Median och medelvärdet som finns i Tabell 4 representeras av de röda (median) och gröna (medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive, graf vilket beror på att vi är mer intresserade av
att undersöka formen på graferna gentemot varandra snarare än att studera dem skalenligt. För att producera den kurva som visas så har vi sorterat klustren från största till minsta.
Enligt graferna i Figur 7 kan man se samma trend som i Figur 6. Undergraferna a-d i detta experiment har dock inte lika många kluster som har 1 punkt. Skillnaden mellan a och d är även mindre än de i Figur 6 vilket innebär att antalet kluster med 1 punkt inte sjunker lika mycket som i Avsnitt 5.1. Median och medelvärde har även en minskad förändring i jämförelse med Avsnitt 5.1 vilket kan bero på att tidsintervallerna skiljer sig. Experimentet i Avsnitt 5.1 görs på alla tider under dygnet och har därmed fler datapunkter, detta kan förklara skillnaden som finns.
5.3 Experiment 3 - Euklidisk distans, tidsintervall: 16:00 – 18:00
I detta experiment använder vi den euklidiska ansatsen för att skapa kluster på tidsintervallet 16:00-18:00. Experimentet producerar 4 grafer som presenteras i Figur 8, Tabell 5 visar antalet kluster som skapas genom klusteralgoritmen samt median och medelvärde för största kluster storlek i förhållande till antalet kluster.
Maximal klusterstorlek Antal kluster Median (avstånd till centroid)
Medelvärde
(avstånd till centroid)
20 meter 246 0,0 5,5
25 meter 197 10,3 12,0
30 meter 186 11,4 13,9
35 meter 172 13,4 17,2
Tabell 5: resultat för euklidisk distans eftermiddagsrusningstrafik a) b)
Figur 8: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter i experiment 3. I varje graf visar y-axeln storleken på ett kluster och x-axeln visar klusterantalet. Median och medelvärdet som finns i Tabell 5 representeras av de röda (median) och gröna (medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive graf detta beror på att vi är mer intresserade av
att undersöka formen på graferna gentemot varandra snarare än studera dem skalenligt. För att producera den kurva som visas så har vi sorterat klustren från största till minsta.
För graferna i Figur 8 så börjar undergraf a) med trenden ifrån Figur 6 undergraf a) där ett stort antal kluster med 1 punkt finns när den maximala klusterstorleken är 20. Eftermiddags intervallet producerar även två grafer c) och d) som nästan ser identiska ut trots att den maximala klusterstorleken är höjd med 5 meter och antalet kluster är något högre.
5.4 Experiment 4 - Punktbaserad, tidsintervall: 00:00-24:00
Experiment 4 använder sig av den punktbaserade ansatsen för att kontrollera klusterstorlek, experimentet har gjorts på tidsintervallet 00:00-24:00. Experimentet har producerat 4 grafer som finns i Figur 9 Dessa grafer visar största klustret i förhållande till antalet kluster som finns. I Tabell 5 presenterar vi antalet kluster som produceras i varje del experiment.
Tabell 6: resultat för punktbaserad metod alla tider a) b)
c) d)
Maximalt antal punkter Antal kluster Median (avstånd till centroid)
Medelvärde
(avstånd till centroid)
20 punkter 293 37,9 41,6
25 punkter 246 48,1 53,1
30 punkter 250 47,6 52,2
Figur 9: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter i graferna visar y-axeln storleken på ett kluster och x-y-axeln visar klusterantalet. I Tabell 6 återfinns de värden som hör till varje graf.
Median och medelvärdet som finns i Tabell 6 representeras av de röda(median) och gröna(medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive graf, vilket beror på att vi är mer intresserade av att undersöka formen på graferna gentemot varandra snarare än studera dem skalenligt.
För att producera den kurva som visas så har vi sorterat klustren från största till minsta.
I graferna för Figur 9 så använder vi den punktbaserade metoden för att kontrollera kluster storleken. I dessa grafer så finns inte det sträck som föregående experiment har vilket betyder att antalet kluster med endast en punkt inte är lika stor som i den Euklidiska metoden. Lutningarna på den blåa linjen visar också att när det maximala antalet punkter i ett kluster är 30 så sjunker det största antalet punkter per kluster snabbare än i övriga del experiment.
5.5 Experiment 5 - Punktbaserad, tidsintervall: 07:00 - 09:00
Experiment 5 använder sig av den punktbaserade ansatsen för att kontrollera klusterstorlek, experimentet har gjorts på tidsintervallet 07:00-09:00. Experimentet har producerat 4 grafer som presenteras i Figur 10. Dessa grafer visar största klustret i förhållande till antalet kluster som finns. I Tabell 6 så presenterar vi antalet kluster som producerades i varje del
experiment.
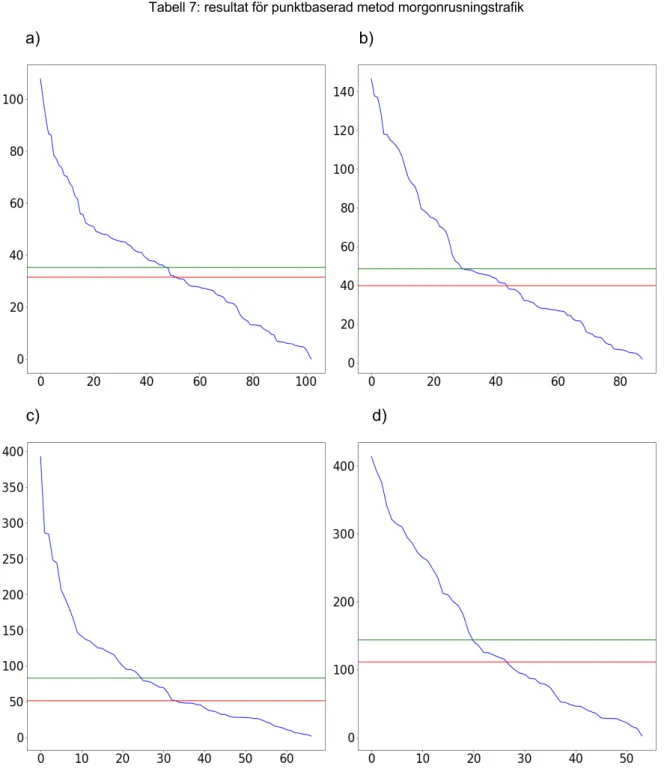
Tabell 7: resultat för punktbaserad metod morgonrusningstrafik a) b)
c) d)
Maximalt antal punkter Antal kluster Median (avstånd till centroid)
Medelvärde
(avstånd till centroid)
20 punkter 103 39,7 44,6
25 punkter 88 45,8 61,8
30 punkter 67 94,1 110,1
Figur 10: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter, graferna visar y-axeln storleken på ett kluster och x-y-axeln visar klusterantalet. I Tabell 7 återfinns de värden som hör till varje graf.
Median och medelvärdet som finns i Tabell 7 representeras av de röda(median) och gröna(medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive graf, vilket beror på att vi är mer intresserade av att undersöka formen på graferna gentemot varandra snarare än studera dem skalenligt. Detta experiment som utgår ifrån den punktbaserade metoden för tidsintervallet morgon. Graferna i Figur 10 visar att antalet punkter per kluster minskar med antalet kluster som används. Undergraf c) dyker väldigt snabbt men planar sedan ut vilket innebär att klusterstorleken minskar i en jämn takt efter det.
5.6 Experiment 6 - Punktbaserad, tidsintervall: 16:00 - 18:00
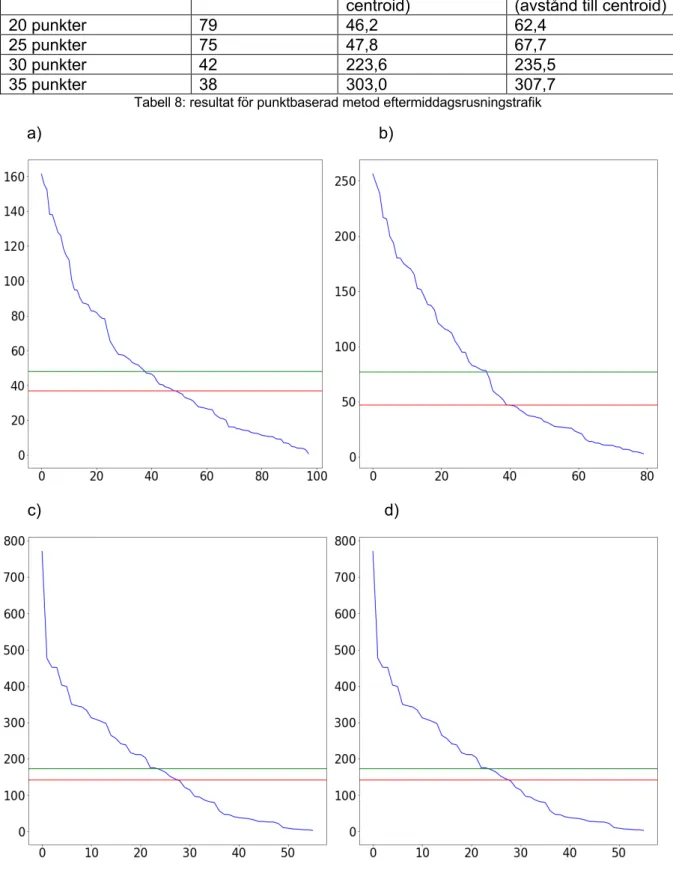
Experiment 6 använder sig av den punktbaserade ansatsen för att kontrollera klusterstorlek, experimentet har gjorts på tidsintervallet 16:00-18:00. Experimentet har producerat 4 grafer som presenteras i Figur 11. Dessa grafer visar största klustret i förhållande till antalet kluster som finns. I Tabell 8 presenterar vi antalet kluster som producerades i varje del experiment.
Tabell 8: resultat för punktbaserad metod eftermiddagsrusningstrafik a) b)
c) d)
Maximalt antal punkter Antal kluster Median (avstånd till centroid)
Medelvärde
(avstånd till centroid)
20 punkter 79 46,2 62,4
25 punkter 75 47,8 67,7
30 punkter 42 223,6 235,5
Figur 11: De 4 graferna a, b, c och d representerar klusterstorlekarna 20, 25, 30 och 35 meter graferna visar y-axeln storleken på ett kluster och x-y-axeln visar klusterantalet. I Tabell 8 återfinns de värden som hör till varje graf.
Median och medelvärdet som finns i Tabell 8 representeras av de röda(median) och gröna(medelvärde) strecken som finns i graferna. Observera att grafernas axlar inte matchar varandra i respektive graf, vilket beror på att vi är mer intresserade av att undersöka formen på graferna gentemot varandra snarare än studera dem skalenligt. I experiment 6 som kan ses i Figur 11, så används den punktbaserade metoden för
klusterstorlek på eftermiddagsintervallet. I detta experiment så dyker storleken i början med en rak linje i undergraferna b) och c) till skillnad ifrån de andra två som minskar mer stegvis. Graferna här har inte heller några långa linjer i slutet som indikerar att antalet kluster med endast 1 punkt inte är lika stort som i den euklidiska metoden. Undergraf c) påvisar dock en påbörjan till detta.
6 Analys och diskussion
6.1 Lämpligheten av metod, när är vilken metod lämplig?
I vårt resultat kan man se att graferna för våra två olika klustermetoder skiljer sig åt ganska väsentligt. De grafer som presenterades för den euklidiska metoden (se Avsnitt 5.1–5.3) visar att antalet kluster som producerades med endast en punkt är högre än i metodensom skapar kluster baserat på antalet punkter. Detta betyder inte att den euklidiska metoden är sämre; de kluster som endast har en punkt kan fortfarande ge mervärde. De kluster som endast har en punkt kan eventuellt vara en närliggande punkt som inte ligger innanför det radie som satts vid körning och på så sätt inte uppfylla kriterierna för att vara med i ett större kluster. Om de är närliggande till ett större kluster så kan det ändå vara en del av ett
geografiskt område av betydelse och kan i kombination med andra punkter och kluster ger en helhetsbild som visar om området kan anses vara otryggt. Det kan i så fall bero på annat än trafiksituationen, till exempel en mörk park. Detta gör att den euklidiska metoden är användbar då de kluster som är större håller en bra form och storlek. Som vi skrev i vår metoddiskussion så är den punktbaserade ansatsen en nackdel i att den är väldigt beroende av datamängdens storlek. Detta gör att olika körningar med olika tidsintervall presterar väldigt olika jämfört med metoden som utgår ifrån euklidisk distans. Fördelen med metoden som använder antalet punkter är att den är snabbare vilket kan vara avgörande, beroende på datamängdens storlek och tillgängliga datorprestanda.
6.2 Analys av grafer
I experiment 1–3 visar graferna ett tydligt mönster där de jämfört med graferna i experiment 4–6 dalar snabbare och har många kluster som bara består av 1 punkt. I experiment 4–6 dalar kurvan inte lika snabbt som ett resultat av att metoden producerar större kluster med vår datamängd. Det finns i samtliga experiment en tydlig trend att klustrens medianvärde närmar sig medelvärdet i takt med att det tillåts vara större. Klustren tenderar även att bli mindre till antal när klusterstorleken tillåts vara större.
6.3 Vilka delar av Lund kunde vi identifiera som problemområde?
Efter att vi gjorde samtliga experiment granskade vi de visualiseringar som QGISproducerat, och vi kunde identifiera ett antal områden med hjälp av en heatmap och en karta över kluster. De områden som frekvent uppkom oberoende av tidsintervall är Getingevägen, Kung Oskars väg och Stortorget. I rapporten Trafikräkningar och Trafikolyckor [5], utgiven av Lunds kommun, så uppkommer dessa gator som speciellt trafikerade och olycksdrabbade vilket delvis stämmer överens med den otrygghet som deltagarna i vår studie upplevde. Enligt rapporten så är Getingevägen rankad 5 avseende flest trafikolyckor i Lunds tätort och Kung Oskars väg är rankad 8. Stortorget som räknas som en korsning av Lunds Kommun är rankad 3 över korsningar i Lund med flest trafikolyckor. Vår data stämmer alltså till stor del överens med Lunds kommun, däremot visar deras mätningar att korsningarna Bangatan – Lund C och Mårtenstorget är värre än Stortorget. Gatorna Bangatan, Trollebergsvägen och Tornavägen är också mer olycksdrabbade enligt Lunds kommun än de gator som vi
identifierade. I Figur 12, 13 och 14 visade vi de största klustren från experiment 1 som är baserat på den euklidiska metoden för tidsintervallet 00:00-24:00. Vi hade dock inte med de gatorna eller korsningarna som har flest trafikolyckor enligt Lunds kommun, vilket kan bero på att Lunds kommun räknar på faktiska olyckor, vilket inte nödvändigtvis behöver korrelera med där cyklister känner sig otrygga. Dessutom tar Lunds kommun med alla olika typer av olyckor i sin statistik, medans vi endast fokuserade på cyklisters upplevelser. Skillnaderna i de olika datakällorna kan därför vara en indikation på att datakällan vi arbetade med inte är representativ för hur det faktiskt ser ut.
Figur 12: Bild på Getingevägen med de kluster som skapats av den punktbaserade metoden med maximalstorlek 20.
Figur 13: Bild på Kung Oskars väg med de kluster som skapats av den euklidiska metoden med maximalstorlek 20.
6.4 Diskussion om hierarkisk klustermetod
En metod som eventuellt skulle kunna producera mer homogena kluster är en hierarkisk metod, där algoritmen kan dela och slå ihop kluster som inte har en önskvärd storlek. Detta betyder att en hierarkisk metod kan hantera individuella kluster på ett mer pricksäkert sätt då individuella kluster kan modifieras. Där med förblir de kluster som anses vara bra
oförändrade i storlek, medans mindre bra kluster kan modifieras. Detta kan innebära att alla kluster får en jämnare storlek då det inte förekommer för små eller för stora kluster.
6.5 Klusterstorlek
Problemet med att hitta en optimal klusterstorlek för oss är att önskvärd storleken varierar mycket beroende på var klustret ligger i Lund. Till exempel kan korsningars storlek skilja sig åt vilket innebär att det är svårt att sätta en generell storlek som blir optimal för alla delar i Lund. En eventuell lösning är att implementera maskininlärning för att mäta storlekar på geografiska ytor, då skapar man en uppfattning om hur stor varje individuell korsning är och matchar detta med respektive kluster för den korsningen, på så sätt skapas kluster av lämpliga storlekar. En annan aspekt värd att tänka på är att det finns en viss osäkerhet gällande koordinaternas precision. Om man sätter en för låg klusterstorlek så finns risken att man börjar producera för små kluster som inte inkluderar de punkter som egentligen har gemensamma punkter. Punkter som egentligen hör ihop hamnar i så fall i olika kluster.
6.6 Utvärdering av klusterstorlek
Vi undersökte storleken på korsningar och kom fram till att den generella storleken på en korsning i Lund är mellan 20–35 meter. Detta kom vi fram till genom att mäta korsningar med hjälp av Google Maps. Vårt mål blev att jämföra de olika storlekarna för att se vilken klustervariabel som producerat bäst kluster. Om man återigen granskar graferna i Avsnitt 5 så kan man se att antalet kluster minskar desto högre maximal klusterstorlek som används samt att antalet kluster med endast 1 punkt minskar. Dessa två resultat kan tolkas på olika sätt då kluster med 1 punkt inte behöver betyda att det är meningslösa kluster. Som nämnts ovan så kan ett sådant kluster få mervärde genom sin placering, detta kräver dock mer geografisk analys. För att utvärdera deras värde så måste man därför kontrollera deras avstånd till närmsta kluster. Om det då visar sig att ett kluster med en punkt ligger längre bort från ett kluster så säger den punkten inte speciellt mycket.
6.7 Validitetshot
Den data som vi arbetade med har ett antal potentiella brister som kan påverka resultatet. Varje datapunkt har en tillförlitlighetsparameter, som är ett värde som representerar
pricksäkerheten för koordinater. Detta ledde i sin tur till att vi tog ta bort 350 datapunkter av totalt 3837. Detta, samt att vi tog bort avvikande datapunkter ledde till ett mindre antal datapunkter att arbeta med totalt sett. Om pricksäkerheten haft mindre värde generellt så hade vi i slutändan haft mer datapunkter att arbeta med och därmed eventuellt fått ett annorlunda resultat. Ett högre antal datapunkter skulle kunna leda till att klustermetodik och maskininlärning får ett större värde som metod i en undersökning av denna typ. Anledningen till detta är att ett större antal datapunkter kan göra det svårare att identifiera platser som har speciellt mycket mätpunkter då vi i så fall inte endast kan titta på en visualisering av alla datapunkter och göra en visuell bedömning. Om man däremot behandlar alla datapunkter med en klusteralgoritm så grupperas data på ett användbart sätt och därmed får varje område, korsning och väg ett antal punkter att förhålla sig till.
Ett annat validitetshot i vårt arbete är vår normaliseringsprocess. Avståndet mellan de yttersta koordinaterna har inte samma avstånd mellan longitud och latitudaxlarna. Det största avståndet mellan två longitudpunkter är 20,42 kilometer medans det största avståndet mellan latituder är 13,29 kilometer. Detta innebär en viss problematik när det
kommer till normaliseringen då kluster kan bli ovala. Detta innebär att punkter och platser inte ligger på rätt geografiska platser och kan skapa problem när analys ska göras.
6.8 Lämplighet av klustermetoder på GPS-data
På frågan om lämplighet av att använda sig av klustermetod så finns det en viktig följdfråga som behöver bejakas. Vad är syftet med att använda klusteranalys?
Genom våra experiment framgick det att klustringsmetoder tydligare visuellt delar upp koordinater i grupper. Detta innebär dock inte att det blir lättare att se det totala antalet punkter över ett geografiskt område eller för den delen kunna dra någon tvärsäker slutsats om rådande lägesbild. Man kan lika gärna hävda att icke klustrade gps koordinater som helt enkelt är utplacerade på en karta utan någon form av maskininlärning också har fördelar. Det kan lika väl vara så att klusteranalysen av koordinater gör att man missar andra detaljer. Till exempel kan klusteranalys exkludera koordinater från ett givet kluster där vi istället tycker att det borde tillhöra. Även de olika färgerna kan påverka hur man uppfattar klustrens
betydelse. Till exempel kan vissa färger dra till sig uppmärksamheten mer än andra. Exempel på detta kan man se i Figur 16 som visar en karta med kluster över Lunds
kommun. Vi har även i Figur 15 producerat en så kallad heatmap för att jämföra den med de kluster som visas i Figur 16.
Figur 15: Karta över alla punkter i Lund baserat på den euklidiska metoden på tidsintervallet 00:00-24:00 med en maximal klusterstorlek på 20 meter.
Figur 16: Heatmap över alla punkter som finns i Lund. Heatmapen visar punkter som skapats efter klusterstorleken 20 meter genom experiment 1 med den euklidiska metoden på tidsintervallet 00:00-24:00. Där vi ser att maskininlärning får en tydligare nytta är om man vidareutvecklar vårt arbete och inkluderar fler aspekter. Dessa aspekter diskuterar vi vidare i Avsnitt 7. Kort så innefattar de att inkludera faktorer så som väder och ljudförhållande, viktning av data, samt ytterligare arbete med klustring. Där vi också ser en större potential i är ifall man jämför mätningar över tid och mellan olika platser. Man kan antingen jämföra olika stadsdelar med varandra eller att jämföra olika städer med varandra. Ett exempel är att över en längre tidsperiod studera hela Lunds kommun med den euklidiska ansatsen för att undersöka hur många kluster som skapas. Om antalet kluster som skapas ökar så kan man anta att det har tillkommit ytligare platser som kan anses otrygga oberoende av antalet cyklister då den euklidiska ansatsen inte är känslig för antal knapptryck i förhållande till klusterstorlek.
Det är även tänkbart att klustringsmetoden kan få större värde ifall man har fler mätpunkter än vad vi har haft. Ifall man tänker sig att hela Lund är fyllt av punkter till den grad att man inte längre visuellt kan utläsa något på en karta, så kan det möjligen bli lättare att utläsa kartan ifall punkterna är tydligt klustrade. Dock är det möjligt att en heatmap kan
åstadkomma samma ändamål ifall syftet endast är att få en visuell överblick över var cyklister känner sig otrygga.
7 Slutsatser
FF1: Vad är en lämplig klusteralgoritm för att gruppera cykeldata?
Baserat på resultaten från den studie som vi gjort så drar vi slutsatsen att icke övervaka maskininlärning baserat på k-means och euklidisk distans kan användas för att klustra GPS koordinater baserat på cyklisters upplevda otrygghet. Fördelen med den euklidiska ansatsen är att den specifikt inte påverkas av antalet datapunkter i den datamängd som använts. Av just samma anledning anser vi att den punktbaserade ansatsen är olämplig då den till stor grad påverkas av antalet datapunkter i datamängden. Då vi har använt k-means för att utföra klusteranalys på vår datamängd anser vi att forskningsfråga 1 är besvarad då k-means lämpar sig till denna typ av analys.
FF2: Vad är en lämplig storlek på ett kluster?
Då olika geografiska ytor skiljer sig i storlek går det ej att fastställa en lämplig klusterstorlek. Inte heller genom våra experiment så har vi hittat en optimal storlek att skapa kluster efter. Den slutsatsen vi kan dra angående optimala klusterstorlekar är att det är beroende av vad som undersöks och hur den miljön ser ut. Vill man undersöka små korsningar bör man rimligen sätta ett lägre värde och vill man undersöka stora korsningar bör man sätta högre värde. Det finns dock flertalet undantag, ett exempel i Lund är Clemenstorget som har formen likt en rektangel där kanterna på torget består av vägar, i ett sådant fall går det inte att ange en optimal storlek. I sådana situationer måste man bestämma om man vill klustra hela torget som ett stort kluster eller flera små. Vårt svar på forskningsfråga 2 blir då att det beror på vad som undersöks men även då är det svårt sätta en optimal klusterstorlek.
8 Framtida arbete
Vi har identifierat ett antal riktningar för framtida arbete som vi presenterar i det här avsnittet. Vissa av dessa kräver kompletterande datakällor och de flesta kräver att man samlar in större mängder klickdata.
8.1 Vädret
En aspekt värd att utforska närmre är vädret. Det är tänkbart att dels mängden cyklister skiljer sig beroende på vädret, men framför allt är det tänkbart att cyklister kommer att uppleva mer eller mindre trygghet beroende på vädret. Till exempel kan tjock dimma påverka sikten, medans halt väglag i form av is på cykelvägen kan innebära sämre grepp. Det är tänkbart att en plats skulle kunna upplevas som otrygg när det är dålig sikt, men inte upplevas som otrygg när vägunderlaget är halt.
8.2 Årstider och dagsljus
Det vore även intressant att vidare utforska tiden på dygnet i form av ljusförhållanden. Genom årstiderna så är dag och natt olika lång. Ifall en cyklist uppfattar ett område som osäkert när det är mörkt så kan cyklisten uppfatta vägen som osäker på eftermiddagen på vintern när det är mörkt, men samma cyklist kan uppfatta samma väg på samma klockslag som tryggare ifall det är sommar och det är ljust ute.
8.3 Jämföra med olycksstatisk
Det skulle även vara bra att inkludera ytterligare olycksstatistik som ett sätt att validera klusteranalysen. Detta kan användas för att se om det finns samband mellan klustrets storlek samt vilka platser som faktiskt är mest olycksdrabbade. Denna kompletterande data viktar algoritmen och ökar valideringsvärdet för de zoner som identifierats som
problemzoner.
8.4 Vikta data med trafikflöde
En aspekt värd att arbeta vidare med är att vikta klusterdata med data av trafikflödet för cykeltrafiken i Lund. Det är möjligt att den datamängd som används för att skapa kluster inte är representativ för det faktiska flödet av cyklister. De människor som deltar i studien som samlat in de data vi arbetat med kan vara mer intresserade av trafiksäkerhet än gemeneman och kanske cykla oftare på vägar som är mer eller mindre olycksdrabbade. En del av
cyklisterna i Lund är studenter och dessa studenter kanske bara cyklar längst med vissa stråk mellan studentbostäderna och undervisningsbyggnaderna. Om studenterna inte är delaktiga i studien i samma grad som övriga cyklister i Lund så skulle detta kunna påverka studiens resultat.
8.5 Ålder och kön
En annan aspekt att ta med är ålder. Det är tänkbart att yngre människor tänker mindre på de negativa konsekvenserna av att inte vara försiktig och därför tar mer risker. Det skulle därför vara intressant att vikta data utifrån ålder. När en yngre person trycker på barometern kanske detta ska anses vara en extra stark indikator på att trafiksituationen faktiskt är osäker. Ytterligare en variabel att ta hänsyn till är kön. Män tenderar till att vara mer riskbenägna än kvinnor [25], och det kan därför finnas ett värde att vikta data utifrån detta.
8.6 Konvex klusterkontroll
Arbetet skulle kunna utvecklas ytterligare genom att skapa fler metoder för att identifiera lämpliga kluster. En sådan metod är att arbeta med konvex klusterkontroll. Den nuvarande problematiken i klusteranalysen är att klustren tenderar till att bli runda oavsett hur den geografiska formen på vägar ser ut. Det finns två olika former av tänkbara kluster i Lund. Dels har man korsningar som täcks in av runda kluster men ibland kanske klustren snarare
bör bli avlånga då det rör sig om längre stråk som cyklisterna har indikerat upplevs som osäkra. Dessa kluster blir i nuläget uppdelade i mindre runda kluster snarare än ett långt kluster.
8.7 Hierarkisk klustermetod
Det vore intressant att splittra upp kluster som är för stora. Vi har använt en iterativ process där antalet kluster ökar med 1 ifall något kluster enligt ett gränsvärde anses vara för stort. Istället skulle det kunna användas en metod som splittrar upp de kluster som är för stora utan att de övriga klustren behöver arbetas om.