Teknik och samhälle Datavetenskap
Examensarbete 15 högskolepoäng, grundnivå
Studenters förhållning till Javas kodkonventioner inom
högskoleingenjörsutbildningar i Sverige
- En komparativ studie
Students’ attitude to Java code conventions within Bachelor of Science programs in Sweden - A comparative study
Andrée Höög
Christoffer Wrangenby
Examen: Högskoleingenjörsexamen 180 hp Huvudområde: Datateknik och mobil IT Datum för slutseminarium: 2016-05-31
Handledare: Dr. Ulrik Eklund Examinator: Mia Persson
Sammanfattning
Att sätta sig in i andra utvecklares kod kan vara svårt och tidskrävande. Kodkonventioner är framtagna i syfte att underlätta underhållsarbetet för andra utvecklare som arbetar med samma projekt, då det sällan är personen som skrev programmet som sedan underhåller samma program. För lite fokus läggs på kvalitétsaspekten i utvecklingsfasen av projekt vilket kostar företag pengar och resurser. Denna studie har för avsikt att undersöka hur högskoleingenjörsstudenter inom datateknik vid olika lärosäten i Sverige förhåller sig till Javas kodkonventioner, och om det går att urskilja en signifikant skillnad i kodkvalité mellan lärosäten i avseende på identifierare, kommentarer samt format och struktur. En webbenkätundersökning genomfördes vars empiri analyserades med hjälp av ANOVA som är en vedertagen metod för hypotesprövning. 21 av 23 ANOVA-test visade att ingen sig-nifikant skillnad förekom mellan lärosätena i avseende på identifierare, kommentarer samt format och struktur. Resultatet visade även att de kvalitétsaspekter studenterna tycker är viktiga och prioriterar att lägga tid på är också de aspekter som studenterna tycks ha störst förståelse och kunskap kring.
Abstract
To get acquainted with other developers code can be difficult and time consuming. Co-de conventions are Co-developed in orCo-der to facilitate maintenance work for other Co-developers working on the same project, where the person who wrote the program rarely is the per-son that maintains the same program. Little attention is paid to the aspect of quality in a projects development phase, which costs companies money and resources. This study intends to investigate how students studying for a Bachelor of Science in Engineering in Computer Science at various universities in Sweden relate to Java code conventions, and if it is possible to discern a significant difference in code quality between these universities in terms of identifiers, comments, format and structure. An online survey was conduc-ted whose empirical data was analyzed using ANOVA, which is a recognized method for statistical hypothesis testing. 21 of 23 ANOVA test showed that no significant difference existed between the institutions in terms of identifiers, comments and format and structu-re. The results also showed that the aspects of quality, which the students think are the most important, are also in fact the aspects they have the greatest understanding and knowledge about.
Förord
Vi vill rikta ett stort tack till de lärosäten och respondenter som tog sig tid att delta i vår studie. Vi vill även tacka vår handledare Dr. Ulrik Eklund för alla goda råd och tips som har hjälpt oss framåt i vårt arbete. Till sist vill vi tacka våra familjer som har stöttat oss under studiens gång.
Innehåll
1 Inledning 1
1.1 Bakgrund . . . 1
1.2 Problemformulering och syfte . . . 1
1.2.1 Forskningsfrågor . . . 2
1.3 Avgränsningar . . . 2
2 Teoretisk bakgrund 3 2.1 Definition av god kodkvalité . . . 3
2.1.1 Identifierare . . . 3
2.1.2 Kommentering . . . 4
2.1.3 Formatering . . . 5
3 Metod 7 3.1 Forskningsmodell . . . 7
3.2 Resonemang kring val av metod . . . 7
3.3 Konstruktion av enkät . . . 7
3.4 Insamling av data . . . 8
3.5 Svarsfrekvens . . . 9
3.6 Metod för analys av insamlad data . . . 9
3.7 Reliabilitet och validitet . . . 10
3.8 Bortfallsanalys . . . 10
3.9 Etiska aspekter . . . 11
4 Relaterat arbete 12 4.1 Butler et al. - Relating Identifier Naming Flaws and Code Quality: An Em-pirical Study . . . 12
4.2 Isong, B. Dominic, E. - An Investigation of Software Development Activities among Undergraduate Students: a case study . . . 12
4.3 Nurvitadhi et al. - Do Class Comments Aid Java Program Understanding? . 13 4.4 Sripada et al. - In Support of Peer Code Review and Inspection in an Un-dergraduate Software Engineering Course . . . 14
4.5 Truong et al. - Static Analysis of Students’ Java Programs . . . 14
5 Resultat och analys 15 5.1 Respondenterna . . . 15
5.2 Hypotesprövning . . . 15
5.2.1 Bakgrund . . . 16
5.2.2 Identifierare . . . 18
5.2.3 Kommentarer . . . 21
5.2.4 Format och struktur . . . 24
5.2.5 Sammanfattning . . . 26
5.3 Åsikter i relation till faktisk kod . . . 26
5.4 Inlärningsmetod . . . 28
6 Slutsats och vidare studier 29 6.1 Slutsats . . . 29 6.2 Förslag på vidare studier . . . 29 6.3 Forskningsbidrag . . . 29 A Enkäten A.1 Introduktion A.2 Del 1 A.3 Del 2 A.4 Del 3
A.5 Del 3 - kodexempel B Introduktionsbrev C Kursböcker
1
Inledning
Att skriva välskriven kod blir allt viktigare i dagens tekniska samhälle. Företag lägger ner stora mängder med pengar och resurser på att förbättra redan befintlig kod. Faktum är att fel som upptäcks sent i utvecklingsfasen, eller t.o.m. efter att en produkt har släppts kostar företagen stora mängder pengar och framförallt tid [1]. Därför är det av yttersta vikt att dagens mjukvaruutvecklare lär sig att skriva kod som håller hög kvalité och som är lätt att förstå, samtidigt som den är lätt att underhålla.
Detta inledande kapitel innehåller en kort bakgrund till denna studie samt kort om vad vi kommer att granska och som sedan övergår i en problemformulering och två forsknings-frågor. Kapitlet avslutas sedan med en presentation av de avgränsningar som har gjorts i samband med denna studie.
1.1 Bakgrund
80% av den totala kostnaden för en mjukvara går till underhåll av densamme, och knappt ett enda mjukvaruprogram underhålls av samma utvecklare som skapade programmet från första början [2]. En stor bidragande faktor till att kostnaden skenar iväg är slarvigt skriven kod, som i sin tur ofta är ett resultat av att för lite fokus läggs på kvalitétsaspekten vid ut-vecklingsfasen i ett projekt [3]. Detta trots att det existerar kodkonventioner med syfte att erbjuda riktlinjer för hur högkvalitativ kod bör skrivas. Vad som i denna studie betraktas som högkvalitativ kod definieras i kapitel 2. Kodkonventioner bidrar starkt till att bland annat läsbarheten ökar, men också struktur och tydlighet, vilket i sin tur underlättar för nya utvecklare som tar sig an ett redan existerande projekt [2].
Samtliga högskoleingenjörsutbildningar inom datateknik som erbjuds i Sverige innehåller kurser inom området programmering. De allra flesta utbildningar har Java som ”grund-språk”, dvs det programspråk studenterna lär sig först [4, 5, 6, 7]. Samtidigt som tekniken i samhället blir allt mer avancerad ställs högre krav på att den kod som skrivs håller hög standard för att systemen ska vara lätta att underhålla och samtidigt vara robusta. Tidi-gare studier menar att studenter ofta skriver dåligt konstruerad kod för att de inte tänker över andra alternativ som programmet kan skrivas på [8]. Istället nöjer de sig med sin version när de väl ha fått programmet att fungera. Studenter försöker även ofta lösa ett problem så snabbt som möjligt utan att reflektera kring kodens kvalité när programmet är färdigkonstruerat. Samma studie har visat att studenter sällan använder en etablerad designmetod för att skriva kod utan använder endast en när de blir tillsagda att göra det [8]. Av dessa anledningar är det därför av stor vikt att nyutexaminerade högskoleingenjörer äntrar arbetslivet med bred kunskap om betydelsen av högkvalitativ källkod.
1.2 Problemformulering och syfte
Syftet med denna studie är att undersöka hur studenter, som läser en treårig högskolein-genjörsutbildning inom datateknik på olika lärosäten i Sverige, förhåller sig till de redan befintliga kodkonventioner som finns. Undersökningen är kvantitativ och görs i syfte att ta reda på om studenterna följer den praxis gällande källkod som Sun Microsystems, skaparna bakom programspråket Java, rekommenderar i sina kodkonventioner [2]. Med undersök-ningen hoppas vi få en fingervisning om det finns mönster och skillnader i studenters kod, samt om kodkvalitén skiljer sig bland den kod som skrivs av studenter som studerar vid olika lärosäten.
1.2.1 Forskningsfrågor
Utifrån problemformuleringen i avsnitt 1.2 formulerades sedan två specifika forskningsfrå-gor som denna rapport har för avsikt att svara på.
1. Hur förhåller sig högskoleingenjörsstudenter inom data från utvalda lärosäten i Sve-rige till de kodkonventioner som finns gällande programspråket Java?
2. Ur ett kvalitétsperspektiv1, kan man se skillnader i Javakod mellan de utvalda läro-sätena?
1.3 Avgränsningar
Eftersom det idag finns en uppsjö av olika programmeringsspråk valde vi i denna studie att fokusera på programspråket Java och specifikt högskoleingenjörsutbildningar inom da-tateknik. Anledningen till valet av Java som programspråk var på grund av att i stort sett alla högskoleingenjörsstudenter inom datateknik har Java som grundspråk. Fokus låg i att undersöka hur studenter väljer att strukturera upp sin kod med avseende på identifierare som variabelnamn, metodnamn och klassnamn men också kommentarer och formatering. Vi valde att inte lägga någon vikt i att studera hur algoritmer är konstruerade eller att undersöka hur väl studenter följer objektorienterade programmeringsprinciper.
1
2
Teoretisk bakgrund
Detta kapitel behandlar teori som är relevant för studien. Det börjar med en förklaring av vilka aspekter av koden som senare i studien kommer att bedömas och sedan förklaras dessa mer ingående.
2.1 Definition av god kodkvalité
Det finns många aspekter som kan tas hänsyn till när man definierar kodkvalité. I denna studie bedöms detta begrepp utifrån identifierare, kommentarer samt format och struktur av källkod.
2.1.1 Identifierare
En identifierare är ett namn på en klass, variabel eller metod. Med hjälp av dessa kom-municerar författaren sitt koncept med sina läsare. Enligt Butler et al. [9] är läsbara och meningsfulla identifierare viktigt för att öka förståelsen för den kod som skrivs. Genom att endast läsa namnet på en identifierare bör man få en uppfattning av vad konceptet och dennes funktion är. Det finns en stark relation mellan namnsättning av identifierare och god källkodskvalité.
Sun Microsystems [2] har utformat kodkonventioner med riktlinjer för hur Javakod av hög kvalité bör skrivas. Här ingår en stilmall för hur namnsättning av identifierare bör se ut, se Tabell 1. Stilmallen är fokuserad på hur olika identifierare bör komponeras.
Tabell 1: Riktlinjer för namngivning av identifierare
Typ Namngivningsregler Exempel
Klasser Klassnamn skall vara ett substantiv och första boksta-ven skall vara en versal. Försök att hålla klassnamnen simpla men ändå beskrivande. Undvik att använda för-kortningar.
class Image
Metoder Inledande ord i metodnamn skall vara ett verb och
första bokstaven skall vara en gemen. Den första bok-staven i varje internt ord skall vara en versal, även kallat ”camelCase”.
run(); runFast();
Variabler Variabelnamn bör vara korta men betydelsefulla. Nam-net skall vara utformat för att ange avsikten med va-riabeln. Variabler som består av ett tecken bör undvi-kas med undantag för tillfälliga lokala engångsvariabler t.ex. en variabel som används för att loopa igenom en lista. Vanliga namn för tillfälliga variabler är i, j, k, m och n för heltal och c, d och e för tecken.
String name; int myNumber; int i;
char c;
Martin [10] menar att välja bra namn tar tid men sparar mer tid i längden. Namnsättning skall tas på största allvar och om det hittas bättre namn efter en tid ska namnen helst ändras. Detta kommer att gynna både författaren och läsarna av källkoden. Programme-rare diskuterar ofta sin kod med andra vilket gör programmering till en social aktivitet. Identifierare skall därför bestå av ord man kan uttala och känner till. En för invecklad
namnsättning som bara författaren förstår sig på är inget att föredra. Namnen skall vara så beskrivande men ändå så enkla som möjligt.
2.1.2 Kommentering
Att kommentera sin kod är enligt Martin [10] ett bra sätt att öka förståelsen för vad syf-tet med koden är. Kommentaren bör vara kort men ändå så beskrivande som möjligt. Den bör inte innehålla för mycket information och heller inte förklara det uppenbara. Om kommentaren inte bidrar till en ökad förståelse bör kommentaren tas bort eller tänkas om. Kommentarer skall inte användas för att kompensera dåligt skriven eller stökig kod, istället bör koden struktureras och skrivas om. Det finns ett bättre sätt att öka förståelsen av sin kod än med kommentarer och det är att förklara med hjälp av kod. Detta innebär att istäl-let för att kommentera vad som händer när koden exekveras väljes smarta namn på t.ex. metoder som förklarar vad dessa skall göra. Detta gör att metoderna blir självförklarande. Kommentarer bör enligt Javas kodkonventioner [2] användas för att få en översikt av koden samt ge ytterligare information om sådant som inte är självklart i koden. Kommentarer skall endast innehålla information som är relevant för att läsa och förstå koden. Till ex-empel bör information om vilka paket som används eller i vilken katalog den finns i inte ingå i en kommentar. I allmänhet skall man undvika kommentarer som troligtvis, i takt med att koden utvecklas, riskar att bli orelevanta. Risken är nämligen hög att kommenta-rer som skrivs inte kommer att ändras när koden uppdateras. För Javaprogram finns det två typer av kommentarer [2]: implementationskommentarer och dokumentkommentarer. Fördelen med dokumentkommentarer är att dessa kan med hjälp av verktyget Javadoc extraheras till en HTML-fil och ger då möjligheten att beskriva kod för utvecklare utan att utvecklarna nödvändigtvis behöver ha tillgång till källkoden. Dokumentkommentarer brukar kallas Javadoc efter verktyget som används för att skapa dem. Javadoc till skillnad från blockkommentarer inleder med två asterisker. Javadoc innehåller även information om vad för typer av variabler som metoden tar in som argument, och om metoden returnerar något finns även information om detta. Exempel 1 visar hur Javadoc kan användas som metodkommentar.
1 /∗ ∗
2 ∗ T hi s example method t a k e s two p a r a m e t e r s and ad ds 3 ∗ them t o g e t h e r and r e t u r n t h e sum .
4 ∗ @param a f i r s t p a r a m e t e r 5 ∗ @param b s e c o n d p a r a m e t e r 6 ∗ @return sum o f b o t h p a r a m e t e r s 7 ∗/ 8 public i n t sum (i n t a , i n t b ) { 9 10 return a + b ; 11 }
Inom kategorin implementationskommentarer ingår det fyra stycken olika kommentarssti-lar. I Javas kodkonventioner [2] finner man en stilmall med riktlinjer för hur implementa-tionskommenter bör skrivas, se Tabell 2.
Tabell 2: Riktlinjer för implementationskommentarer
Namn Kommentarsregler Exempel
Block-kommentar
Skall användas för att beskriva filer, metoder, data-strukturer och algoritmer. Blockkommentarer används i början av varje fil och före varje metod. De kan även användas inuti metoden och då ska kommentaren vara indragen till samma nivå som den kod som beskrivs.
/*
* Comment here. */
Enrads-kommentar
Det är korta kommentarer som visas på en enda rad indragen till nivån av koden som följer. Om kommenta-ren inte kan skrivas på en rad bör blockkommentering användas. En enradskommentar bör föregås av en tom rad.
/* Comment here. */
Efterföljande kommentar
Det är mycket korta kommentarer som skrivs på sam-ma rad som koden men flyttas tillräckligt långt i sidled för att skilja kommentarerna från koden.
/* special case */
Radsluts-kommentar
Detta är en typ av kommentar som kan användas för att kommentera små avsnitt i koden eller för att kom-mentera sektioner av koden som man inte vill använda men heller inte vill ta bort.
// Do a double-flip.
2.1.3 Formatering
Att strukturera sin kod är enligt Martin [10] något som är viktigt. En slarvigt formaterad och ostrukturerad kod kan indikera att författaren är oprofessionell och att kodens funk-tionalitet inte går att lita på. Att få koden att utföra sitt syfte är viktigt, men än viktigare är att skapa en tydlig struktur på ett sätt som gör koden lättläst. När man programmerar i Java så spelar det ingen roll för kompilatorn om man delar upp sin kod eller om man skulle skriva all kod på en enda rad då kompilatorn läser in koden på samma sätt. Anledningen till att det är så viktigt med bra strukturerad kod är enligt Swartz [11] för att öka för-ståelsen och läsbarheten av koden för människor. Martin [10] menar även att läsbarheten och kodstilen kommer att fortsätta påverka vidareutveckling och underhåll av koden långt efter att den ursprungliga koden är oigenkännlig då funktionaliteten ständigt kommer att utvecklas. Formateringen lever längre än funktionaliteten av koden.
Inspiration för hur man formaterar sin kod kan enligt Martin [10] tas från en bra skri-ven tidningsartikel. En tidningsartikel läses vertikalt där man längst upp börjar med en rubrik som kopplas till innehållet, sedan ett stycke som förklarar vad texten innehåller och fortsätter sedan att ge mer och mer detaljer tills man till slut har berättat sin historia. Om en tidningsartikel inte skulle styckeindelas utan att namn, påståenden och händelser skulle blandas och skrivas som en enda lång text så skulle ingen vilja läsa den. En klassfil kan struktureras på samma sätt. Man ger först klassen ett simpelt men ändå beskrivande namn. Sedan skriver man en sammanfattning av funktionaliteten i form av en kommentar. Mer och mer detaljer av koden skrivs sedan i form av metoder, variabler, kommentarer m.m.
Enligt Javas kodkonventioner [2] så är det mest huvudsakliga man kan göra för att öka läs-barheten av koden att använda sig av så kallade ”vita områden”. Vita områden innefattar indrag, blanksteg och tomma rader och används för att dela upp koden samt göra koden mer luftig. Nedan presenteras riktlinjer över hur dessa skall användas.
Tomma rader skall användas enligt dessa principer:
• Två tomma rader skall finnas mellan klasser och interface. • En tom rad skall finnas mellan metoder.
• En tom rad skall finnas mellan lokala variabler inuti en metod och dennes första sats. • En tom rad skall finnas före en block- eller enradskommentar.
Blanksteg skall användas enligt dessa principer:
• Ett blanksteg skall finnas efter kommatecken i argumentlistor. • Satser följda av en parentes skall separeras med ett blanksteg. • Metodnamn följt av en parentes skall ej separeras.
En annan viktigt aspekt att tänka på är den horisontella formateringen. Det handlar om hur mycket kod som skall finnas på varje rad, vilket kan anpassas med hjälp av radbrytningar och indrag. Enligt Martin [10] är det lämpligare att sträva mot att ha korta rader av kod än tvärtom. Om ett uttryck inte får plats på en rad så skall det enligt Javas kodkonventioner [2] brytas upp enligt dessa principer:
• Bryt efter kommatecken. • Bryt före en operator.
• Se till att början av det nya uttrycket är på samma nivå som föregående rad. En tumregel programmerare ofta använde förr var att aldrig behöva scrolla till höger när man läser eller skriver kod, vilket även tillämpas idag. Men då det idag finns så många skärmar av olika storlekar så lämpar sig inte denna regler så bra om koden är tänkt att delas bland många programmerare. En bra grundregel är då istället enligt Martin [10] att inte överstiga 120 tecken på en rad. Mer än så bidrar lätt till att koden bli svårläst.
3
Metod
I detta kapitel presenteras studiens genomförande samt det tillvägagångssätt som använts för att besvara forskningsfrågorna. Val av metod presenteras samt resonemang kring för-och nackdelar med denna. Kapitlet avslutas med en presentation kring hur vi bearbetade vårt insamlade material och hur tillvägagångsättet kring analysen av datan gick till.
3.1 Forskningsmodell
Med utgångspunkt i vår forskningsfråga antog vi ett explorativt förhållningssätt utifrån en induktiv ansats. Innan studien tog vid formulerade vi en nollhypotes och därefter samlade vi, med hjälp av webbenkäter, in empirin som sedan analyserades enligt en statistisk metod för hypotesprövning. Med hjälp av svaren från analysen drog vi sedan slutsatser som sågs i relation till våra forskningsfrågor. Figur 1 ger en visuell bild över vårt tillvägagångssätt, från diskussion kring val om ämne till en komplett studie.
Figur 1: Illustrerad vy över studiens förlopp
3.2 Resonemang kring val av metod
Vi valde att använda oss av Surveyundersökning [12] som vetenskaplig metod i vår studie. Specifikt valde vi en metod där vi konstruerade en webbenkät för att samla in empirisk data från respondenterna. Fördelarna med en sådan, istället för en undersökning i intervjuform, var att respondenterna själva kunde välja när de ville svara [13]. Eftersom respondenterna befann sig på olika geografiska platser i Sverige talade detta också för valet av webben-käter framför intervjuer. Med en enkätundersökning finns också vissa nackdelar som var tvungna att övervägas i valet av metod. Eftersom det var omöjligt att bistå respondenter-na med hjälp, var det därför viktigt att frågorrespondenter-na var tydliga från första början. Att ställa uppföljningsfrågor var inte heller möjligt och det var viktigt att inte ställa ledande frågor, eller frågor som respondenterna upplevde som oviktiga. Att vi valde en frågeställning som involverade och engagerade de inblandade kunde också hjälpa till att minska bortfallet av respons [13].
3.3 Konstruktion av enkät
Enkäten konstruerades med hjälp av verktyget SurveyGizmo [14]. SurveyGizmo valdes på grund av att gränssnittet var enkelt att jobba i samt att man enkelt kunde få en över-blick över hur respondenterna hade svarat. SurveyGizmo erbjöd också en okomplicerad dataexportering. I inledningen av enkäten presenterade vi syftet med enkäten, en kort bak-grundsinformation om ämnet, enkätens disposition, en tidsuppskattning för hur lång tid enkäten tar att genomföra och kontaktuppgifter om de hade några frågor kring enkäten. Detta för att de skulle vara så förberedda som möjligt innan de började svara på frågorna. Innan enkäten skickades ut genomfördes en pilotstudie där den testades på två studenter i syfte att ta reda på om enkäten var lätt att förstå och om den var bra strukturerad. Pilotstudien gav en uppfattning om hur lång tid enkäten tog att genomföra, och ett par frågor som orsakade viss förvirring hos testpersonerna korrigerades och förtydligades.
Enkäten bestod av totalt 21 frågor och delades upp i tre delar med syfte att göra enkä-ten mer överskådlig och strukturerad. Första delen bestod av åtta frågor som behandlade bakgrundsfakta om respondenten. Dessa frågor ställdes för att vi skulle få en uppfattning av vem respondenten var, hur denne föredrog att lära sig programmering samt om denne tidigare haft erfarenheter av Javas kodkonventioner. Andra delen bestod av tre underkate-gorier: ”Identifierare”, ”Kommentarer” samt ”Format och struktur”. Dessa tre subkategorier innehöll totalt 13 frågor där respondenterna fick svara på frågor angående just identifierare, kommentarer samt format och struktur av källkod. I denna del blandade vi påståenden med konkreta kodexempel där respondenterna själva fick komma med förslag på hur exempel-koden kunde förbättras. Dessa frågor ställdes med syfte att undersöka hur respondenterna förhåller sig till Javas kodkonventioner samt få en inblick i hur viktigt de tycker dessa aspekter är att lägga tid på för att öka kodkvalitén. Tredje delen bestod av exempelkod där respondenterna, utifrån angivna instruktioner, själva fick bearbeta exempelkoden med hänsyn till de aspekter som undersöktes i del två. Denna del utformades med tanke att använda för att styrka våra diskussionsargument om ämnet senare i studien. Eftersom del tre gav respondenterna full frihet att redigera koden efter sitt eget tycke och smak gav det oss möjligheten att se tendenser vad respondenterna prioriterar när det kommer till kodkvalité. För att minska bortfallet så gjordes enkäten inte för avancerad utan bestod av frågor på grundläggande nivå. Hela enkäten kan ses i bilaga A.
Den större delen av enkäten bestod av stängda frågor med svarsalternativ. Svarsalter-nativen bygger på en Likertskala [15] i syfte att mäta attityden hos respondenterna. Detta för att det skulle underlätta sammanställningen men även analysen av svaren. Likertska-lorna skiftar i grader vilket enligt Matell och Jacoby [16] inte ska påverka undersökningens reliabilitet eller validitet. Frågor med svarsalternativ bidrar också till att svarfrekvensen ökar då respondenterna enklare förstår vad som efterfrågas och enkäten går snabbare att genomföra. Några få öppna och frivilliga frågor användes för att respondenterna skulle ha möjlighet att argumentera för sina svar och kunna påvisa en högre förståelse för ämnet. De öppna frågorna bedömdes genom att jämföra svaren med vad Javas kodkonventioner rekommenderar, men också hur välmotiverade svaren var.
Länken till enkäten skickades till varje programledare tillsammans med ett introduktions-brev som beskrev vilka vi var samt syftet med enkäten, se bilaga B. Brevet beskrev även anonymiteten hos respondenterna, något som redogörs ytterligare i kapitel 3.9.
3.4 Insamling av data
För att ta reda på vilka lärosäten i Sverige som erbjöd den utbildning som studien av-gränsades kring, användes Antagning.se [17]. Vi tog sedan hjälp av de kontaktuppgifter som fanns publicerade på respektive lärosätes hemsida för att komma i kontakt med de programansvariga för varje utbildning. Vi lät sedan de programansvariga distribuera vi-dare vår webbenkät till respondenterna via deras respektive studentportal. Tiden som var avsatt för insamling av enkätsvar var satt till två veckor. Enligt Nulty [18] kan man öka antalet medverkande med hjälp av återkommande påminnelser och utlottning av något slags pris. Vi såg en utlottning av en teknisk produkt som ett bra incitament för att få fler att delta i undersökningen. För att motivera deltagande i vår undersökning lottade vi därför ut en Raspberry Pi 3. De lärosäten som valde att delta i undersökningen var Malmö Högskola (MAH), Kungliga Tekniska Högskolan (KTH), Luleå Tekniska Universitet (LTU) samt Högskolan i Halmstad (HH).
3.5 Svarsfrekvens
Målet var att utföra undersökningen på alla tio lärosäten i Sverige som tillhandahåller en högskoleingenjörsutbildning inom datateknik och som har Java som grundspråk. Eftersom vi av förklarliga skäl inte kunde påtvinga någon skola eller studenter att genomföra en-kätundersökningen skickade vi först en förfrågan till varje lärosäte och av de tio lärosäten som tillfrågades var det fyra som ställde sig positiva och ville vara med. Detta gjorde att vår population begränsades till ca 200 studenter. Totalt svarade 62 studenter på del ett, varav 57 av dessa 62 studenter svarade på del ett och två och 46 studenter genomförde hela enkäten. Det betyder att svarsfrekvensen för respektive del landade på 31% för del ett, 28,5% för del två och 23% för del tre. Enligt Gert Van Dessel [19] anses en svarsfrekvens på 20% vara bra för webbenkäter medan 30% anses vara mycket bra. Detta resulterar i att varje del i webbenkäten kom över gränsen för vad som klassas som en godkänd svarsfre-kvens. Svarsfrekvensens påverkan på resultatet diskuteras vidare i kapitel 3.8. De svar som utelämnades av vissa studenter behandlades som ”missing” i analysverktyget SPSS.
3.6 Metod för analys av insamlad data
Den insamlade datan från enkätundersökningen analyserades med hjälp av ANOVA [20] som är en metod för hypotesprövning. På svenska kallas ANOVA för variansanalys och an-vänds för att undersöka om ett medelvärde på en variabel skiljer sig för fler än två grupper. Eftersom vår undersökning utfördes på fler än två lärosäten och på så sätt resulterade i att fler än två grupper behövde analyseras motiverade detta valet av ANOVA som ana-lysmetod. Om ANOVA-testet visade att det fanns en skillnad mellan minst två grupper så utfördes ett Post Hoc-test med inställningar för ”Least Significant Difference” (LSD) [21] för att ta reda på mellan vilka grupper denna skillnad fanns. Anledningen till att LSD valdes som inställning var för att alla grupper inte hade samma samplingsstorlek [21]. ANOVA valdes dessutom för att säkerhetsnivån för testet skulle vara så hög som möjligt. Vanligast är att använda sig av en signifikansnivå på 0,05 vilket leder till en säkerhetsnivå på 95% [22], vilket även vi gjorde i vår undersökning. En säkerhetsnivå på 95% betyder att om testet skulle visa sig vara signifikant är vi 95% säkra att vi drar rätt slutsats. Hypo-tesprövningen hade också kunnat utföras med t-test, men då t-test endast lämpar sig till att jämföra två grupper åt gången hade vi således behövt göra fler t-test vilket i sin tur hade resulterat i att säkerhetsnivån hade sänkts för varje test. Vid det första testet hade vi varit 95% säkra, men vid det andra testet hade vi varit 95%*95%, dvs 90,25% säkra. Vid ett tredje test hade säkerhetsnivån sänkts ytterligare och vi hade varit 95%*95%*95%, dvs 85,74% säkra [23]. Detta är den största anledningen till varför vi i slutändan valde ANOVA som statistisk metod.
För att undersöka om det förekommer skillnader i kodkvalité mellan olika lärosäten i Sve-rige formulerades följande nollhypotes:
H0: Det finns ingen signifikant skillnad i kodkvalité för högskoleingenjörsstu-denter som läser datateknik från olika lärosäten i Sverige.
Syftet med nollhypotesen är att den skall testas mot svaren från enkäten. Efter varje ut-fört test tas sedan ett beslut om nollhypotesen bör behållas eller förkastas. Beslutet om nollhypotesen bör förkastas eller ej bygger på om signifikansvärdet för testet underskrider 0,05. Svaren från enkäten exporterades till SPSS där testen sedan utfördes.
3.7 Reliabilitet och validitet
Reliabilitet och validitet är två begrepp som används vid kvantitativa studier för att be-skriva hur väl datainsamlingen och testen har genomförts. För att kunna göra generella antaganden utifrån studiens resultat krävs en god reliabilitet och validitet [12]. För att studien skall ha en hög empirisk validitet behöver följande fyra kriterier uppnås:
• Konstruktvaliditet - Går den bakomliggande teorin ihop med vad vi mäter i vår un-dersökning? Syftet med undersökningen är att undersöka kodkvalité, är vi då säkra på att andra uppfattar begreppet kodkvalité så som vi uppfattar det? Eftersom stu-diens teori bygger på officiella riktlinjer framtagna av skaparna bakom Java har vi därför i våra analyser och jämförelser kunnat förlita oss på en allmängiltig teori som ligger fri från egna värderingar.
• Intern validitet - Belyser studiens utformning och om studiens resultat är en följd av den insamlade datan. Vanliga problem angående intern validitet är ofta att störande variabler eller att statistikverktyg inte har behandlats korrekt. Stor vikt under studi-ens gång har lagts på att undersöka och förstå hur analyser i SPSS ska utföras med vår typ av data och för att säkerheten i testen ska bli så hög som möjligt.
• Extern validitet - Generaliserbarhet är ett annat ord som ofta används istället för ex-tern validitet. Hur säkra kan vi vara på att de antaganden som görs utifrån resultaten i vår studie kan appliceras på hela populationen, eller andra grupper som står utanför vår studie? Eftersom populationen i studien är avgränsad och definierad till att bestå av studenter från specifika ingenjörsprogram har vi inte haft möjlighet att göra ett slumpmässigt urval. Detta kan utgöra ett hot mot generaliserbarheten av resultatet, men eftersom det är troligt att andra datautbildningar läser samma grundläggande Javakurser, talar det ändå för att resultatet kan appliceras på studenter inom andra datautbildningar.
• Reliabilitet - Betyder i kvantitativa studier reproducerbarhet, dvs att resultatet ha-de blivit ha-detsamma ifall någon annan haha-de utfört studien. Vanligt förekommanha-de problem vid kvantitativa studier är att den eller de som utför mätningarna, både medvetet och omedvetet kan vinkla resultatet till någons fördel. Detta har vi under hela studien haft i åtanke och därför varit konsekventa och objektiva i våra bedöm-ningar av enkätsvaren.
3.8 Bortfallsanalys
En svarsfrekvens på 31% betyder ett bortfall om 69% som inte svarade på enkäten. Dess-utom uppstod ytterligare några procentenheters bortfall då ett fåtal studenter inte valde att fullfölja enkätens alla delar. I kapitel 5.1 presenteras andelen respondenter från varje lärosäte vilket visar en tydlig underrepresentation från Luleå Tekniska Högskola (LTU). Möjliga orsaker till bortfallet kan bero på flera faktorer, men mest troligt är det faktum att vi inte hade tillgång till alla studenters e-mailadresser och således inte kunde nå re-spondenterna direkt, utan var tvungen att gå via programansvariga på respektive lärosäte. Vi fann också svårigheter att upprätthålla kontinuerlig kontakt med de programansvarige vilket gjorde det svårt att veta om studenterna hade fått tillgång till enkäten. En annan faktor som påverkar bortfallet kan vara ett mörkertal av studenter som inofficiellt har hop-pat av sina studier men som fortfarande står med som aktiva och således inkluderade i
undersökningen. Bortfallet och hur svarsfördelningen ser ut bland de inblandade lärosäte-na kan därför göra det svårt att tillåta oss att dra generella antaganden om populationen som helhet.
3.9 Etiska aspekter
Undersökningen utfördes i samförstånd med vetenskapsrådets individskyddskrav som byg-ger på fyra allmänna huvudkrav [24]. Det första kravet, informationskravet, innebär att den eller de personer som ansvarar för studien skall informera deltagarna i studien om vilka villkor som gäller för deras deltagande och vad syftet med studien är. Deltagarna skall också informeras om att medverkandet är frivilligt och att de när som helst innehar rätten att avbryta sin medverkan. Det andra kravet, samtyckeskravet, säger att deltagare i studien har rätten att själv bestämma över sin medverkan. Tredje kravet, konfidentiali-tetskravet, säger att känsliga uppgifter om deltagare skall behandlas konfidentiellt och att dessa uppgifter skall förvaras på ett sätt att obehöriga inte på något sätt kan ta del av dem. Det fjärde och sista kravet, nyttjandekravet, innebär att insamlade uppgifter om deltagare uteslutande får användas för forskningsändamål.
4
Relaterat arbete
I detta kapitel kommer tidigare forskning inom liknande områden som vår studie handlar om att presenteras.
4.1 Butler et al. - Relating Identifier Naming Flaws and Code Quality: An Empirical Study
Målet med denna empiriska studie av Butler et al. är att undersöka om det finns andra konsekvenser av dåligt namngivna identifierare än det faktum att läsbarheten av källkoden minskar. De undersöker om det finns en relation mellan mjukvara av sämre kvalité och kvalitén på identifierarnamn som används i källkoden. Genom att utgå från ett visst antal fördefinierade riktlinjer om vad som är bra praxis när det kommer till namngivning av identifierare, undersöker författarna åtta olika ”open-source”-program skrivna i Java. Butler et al. hänvisar till en artikel skriven av Philip Anthony Relf, där Relf har tagit fram 21 stycken riktlinjer för namngivelse av identifierare för båda programspråken Ada och Java [25]. Dessa riktlinjer riktar in sig på utformningen av namnen, inte hur identifiera-re ska namnsättas för att användaidentifiera-ren ska få ut så mycket information som möjligt. Butler et al. menar att dessa riktlinjer är fullt rimliga att utgå ifrån eftersom de till skillnad mot kodkonventioner är empiriskt utvärderade [9]. Av dessa valde Butler et al. ut 11 stycken riktlinjer att använda sig av i sin studie.
Butler et al. valde ut åtta stycken öppna programvaror. De utförde sedan en statisk analys av källkoden med hjälp av verktyget FindBugs [26] som används för att upptäcka olika brister i kod. Dessa klassificieras utifrån deras potentiella inverkan på programmet och i kategorier som t.ex dålig praxis, säkerhet och korrekthet. Butler et al. utvecklade ett eget automatiserat verktyg för att, med hjälp av FindBugs rapporter, upptäcka avvikelser från de framtagna riktlinjerna.
4.2 Isong, B. Dominic, E. - An Investigation of Software Development Activities among Undergraduate Students: a case study
Bassey Isong och Dominic Egbe valde att undersöka hur och varför studenter som läser datavetenskap vid Univerity of Venda i Sydafrika lär sig programmering, samt undersöka deras kunskap om programvarukvalitét [27]. Trots dålig infrastruktur och brist på lärare i utvecklingsländer fortsätter studenter att utveckla sin egen programmeringsförmåga samt utveckla egen programvara, trots att många studenter avstår från att delta i formella lek-tioner.
Det krävs att utvecklingsprocessen av programvara som skall användas i kommersiella syften följer vissa ingenjörsmässiga metoder för att programvaran skall uppnå hög kvalité. Det innefattar dels att göra programvaran pålitlig men också lätt att underhålla. Detta innebär ofta att utvecklare måste arbeta tillsammans snarare än enskilt [28]. Studenter som läser sitt andra, tredje eller fjärde år står som deltagare i denna flermetodstudie där insamling av data sker med hjälp av både enkäter och intervjuer.
Resultatet av studien visade bland annat att majoriteten av studenterna föredrog att arbeta individuellt framför att jobba i grupp på grund av tillitsproblem till klasskompisar. De ansåg också att tillgången till kod online, kombinerat med formella lektioner i
program-mering och textböcker är det bästa sätt att lära sig programmera. Mycket tid spenderas på internet med att praktisera programmering med hjälp av kod som andra utvecklare har skrivit [27].
Isong och Egbe ger också utifrån sin undersökning några rekommendationer till skolled-ningen där de föreslår hur utbildskolled-ningen kring programmering skulle kunna förbättras.
4.3 Nurvitadhi et al. - Do Class Comments Aid Java Program Un-derstanding?
Nurvitadhi et al. undersöker om klass- och metodkommentering av ett Java-program kan bidra till en ökad förståelse av programmering. Undersökningen gjordes vid Oregon State University, specifikt bland studenter som läser en kurs i objektorienterad programmering [29].
Författarna menar att skriva kod som är begriplig för andra läsare är mycket viktigt då man oftast på företag jobbar i lag. Om koden är väl skriven underlättas bland annat under-hållning, testning och felsökning av koden. Så mycket som hälften av tiden som spenderas på dessa uppgiften ägnas åt att förstå koden. Studier har visat att kommentarer har en positiv påverkan och kan öka kodens förståelse avsevärt [30, 31].
Studien gjordes med 103 studenter där de fick fyra versioner av ett Java-program. Ett utan några kommentarer alls, ett där bara metoderna var kommenterade, ett där bara klasserna var kommenterade och ett där både metoder och klasser var kommenterade. Pro-grammet består av fem klasser och sju metoder med sammanlagt 172 rader kod.
Studien visar att metodbaserade kommentarer påverkar programförståelsen mer än klass-baserade kommentarer gör. Nurvitadhi et al. tror att en möjlig orsak kan vara att Java-programmet var ganska litet och enkelt. Detta kan ha bidragit till att syftet med klasserna kan ha varit uppenbara och redan avslöjat den enkla designen av programmet. Program som används i industrin är betydligt större och mer komplicerade, vilket gör det mer troligt att klassbaserade kommentarer underlättar förståelsen av koden i högre grad. Studien lyfter också fram det faktum att olika läroböcker lär ut olika riktlinjer angående kommentering.
4.4 Sripada et al. - In Support of Peer Code Review and Inspection in an Undergraduate Software Engineering Course
Sripada et al. utförde 2015 denna studie utifrån deras hypotes att referentgranskning och kodinspektion kan öka kvalitén på kod som skrivs [32]. Deltagare i studien var andraårs-studenter som läste en kurs inom mjukvaruutveckling. Sripada et al. hade som mål att undersöka om studenterna följde de kodstandarder som rekommenderas för det givna pro-gramspråket, samt att identifiera antalet buggar som förekom under utvecklingsfasen i ett projekt. Författarna hoppades att, med hjälp av denna studie, bland annat kunna påvi-sa att referentgranskning bör användas för att tidigt kunna identifiera buggar i ett program. Studien är uppdelad i tre faser. I studiens första fas skall studenterna konstruera ett spel med fokus på funktionalitet. I andra fasen är uppgiften att åter lämna in samma spel som de konstruerade i fas ett, men i en reviderad version anpassad till en python-kodstandard. Dessutom får studenterna lära sig att kodgranska både manuellt och med hjälp av statiska verktyg för kodanalyser. I sista fasen av projektet får studenterna utföra kodgranskning på kod skriven av medlemmar i samma projektgrupp. I slutet utfördes en enkätundersökning kring kodgranskning och dess fördelar bland studenterna.
Resultatet av undersökningen visade att fyra av fem studenter ansåg att kodgransking hjälpte till att förbättra samarbetet och kommunikationen i gruppen [32]. Vidare visade undersökningen att studenter började uppskatta processen kring kodgranskning, medan andra studenter var av uppfattningen att granskningen tog extra tid. Tid som kunde ha använts till annat. I snitt identifierade och åtgärdade varje student tre till fyra buggar under granskningsprocessen.
4.5 Truong et al. - Static Analysis of Students’ Java Programs
Truong et al. beskriver i sin artikel ett statiskt ramverk för att analysera studenters, på Queensland University of Technology, Java-program och titta på vilken kvalité dessa håller. Detta genom att ge feedback till studenterna vad som är bra och vad som kan förbättras, kvalitétsmässigt i deras kod.
Truong et al. belyser problemet att en stor del av ett företags budget av ett mjukva-ruprojekt går till att förbättra programvarukvalitén. Detta tror företagsledarna beror på att för lite tid och kraft läggs ned på programvarukvalité i utvecklingsfasen av ett projekt [8]. Det är pågrund av detta ramverket skapats. Författarna menar att det är viktigt att studenter lär sig tidigt i sin utbildning att lägga tid på att skriva kod av bra kvalité. De har ofta sett studenter som försöker lösa problemen så snabbt som möjligt för att sedan nöja sig med koden bara den löser problemet [8]. Därför har författarna utvecklat ett ramverk som ska hjälpa studenterna tänka mer på kvalitétsaspekten av ett Java-program.
Ramverket består av två analyser. Den första analysen bedömer kvalitén av koden medan den andra analysen jämför studentens lösning med en ”korrekt” lösning. Sedan ger ramver-ket återkoppling på kvalitén på studentens lösning, idéer för att alternativa lösningar och tips för att förbättra studentens lösning. Analyserna sköts av ett AST (Abstract syntax tree), som representeras med hjälp av XML. Författarna menar att detta ramverk lätt kan konfigureras för att passa olika typer av övningar. Men ramverket är mest användbart för ”fylla i”-övningar, som tillhandahålls av ELP (Learning to Program).
5
Resultat och analys
För att kunna dra betydande slutsatser för studien har relevant data från enkäten i detta kapitel sammanställts och presenterats tillsammans med en diskussion och vilka slutsatser man kan dra av resultatet.
5.1 Respondenterna
Detta underkapitel innehåller kort bakgrundsfakta om respondenterna. Här förs därför ing-en närmare diskussion kring varje delresultat utan resultatet presing-enteras för att ge ing-en bild av respondenterna som deltog i undersökningen.
Av den totala populationen som valde att svara på enkäten såg fördelningen av studenter från respektive lärosäte ut som följande:
• Kungliga Tekniska Högskolan (KTH): 33,9% • Malmö Högskola (MAH): 29%
• Högskolan i Halmstad (HH): 24,2% • Luleå Tekniska Universitet (LTU): 12,9%
Fördelningen mellan andra- och tredjeårsstudenter i undersökningen var 51,6% gentemot 48,4%. Åldersfördelningen mellan respondenterna kan ses i Figur 2. Nästan hälften av respondenterna var mellan 18-23 år vilket borde kunna tyda på att de tidigare inte har någon arbetserfarenhet inom programmering.
Figur 2: Åldersfördelningen bland respondenterna
5.2 Hypotesprövning
Ett av studiens huvudmål var att söka svar på om det går att se skillnader i kodkvalité mellan olika lärosäten. För att göra detta utfördes en hypotesprövning på relevant data där vi formulerade och testade, baserat på forskningsfråga 2 i kapitel 1.2.1, följande noll-hypotes:
H0: Det finns ingen signifikant skillnad i kodkvalité för högskoleingenjörsstu-denter som läser datateknik från olika lärosäten i Sverige.
Detta kapitel är indelat i fyra underkapitel där det empiriska materialet från undersök-ningen och resultaten från hypotesprövundersök-ningen presenteras med en avslutande del där en diskussion förs kring om nollhypotesen bör förkastas eller inte.
5.2.1 Bakgrund
På frågan om hur deras tidigare erfarenhet kring programmering såg ut svarade ungefär en tredjedel av respondenterna att de hade erfarenhet av programmering innan ingenjörsstu-dierna, men att deras erfarenhet inte sträckte sig mer än över ett år. Det visade sig även att en fjärdedel av respondenterna inte hade någon tidigare erfarenhet av programmering alls, se Figur 3.
Figur 3: Studenternas tidigare erfarenhet av programmering innan ingenjörsstudierna
Majoriteten av deltagarna ansåg att en kombination av att lära sig programmering med hjälp av föreläsningar och laborationer, läsa böcker och med hjälp av internet / onlinefo-rum är det bästa sättet att lära sig att programmera. Knappt en femtedel hävdade att de endast föredrar internet och/eller onlineforum som bästa metod för att lära sig att pro-grammera, se Figur 4.
Av alla 62 studenter som svarade på del ett visade det sig att 91,9% känner till Javas kodkonventioner sedan tidigare. Figur 5 visar en sammanställning av de sista två frågorna i del ett av enkäten. Endast 9,7% instämmer helt på påståendet att de anser sig ha goda kunskaper i hur Javakod av hög kvalité bör skrivas. 3,2% av respondenterna svarade att de inte alls anser sig ha dessa kunskaper medan majoriteten svarade att deras kunskap ligger någonstans i mitten.
Ungefär en fjärdedel svarade att de instämmer helt i påståendet att de aktivt tänker på att följa Javas kodkonventioner under tiden de programmerar. Lika många svarade att de till stor del höll med medan 38,7% svarade att de endast till viss del höll med. Endast 6,5% av respondenterna svarade att de inte instämmer alls på samma påstående, se Figur 5.
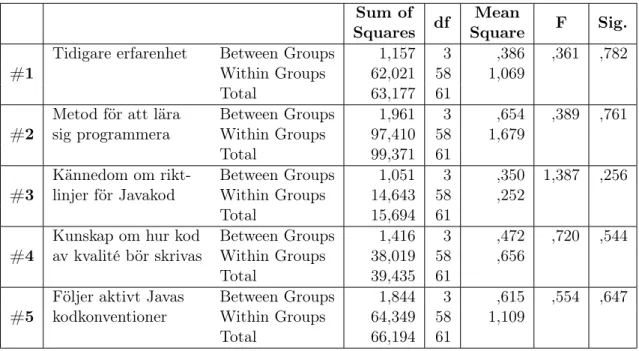
Tabell 3 visar en sammanställning av alla ANOVA-test för delen som redogör för respon-denternas tidigare erfarenhet kring programmering och deras förhållningssätt till Javas kodkonventioner.
Tabell 3: ANOVA-test på frågorna som berör bakgrundsinformationen Sum of
Squares df
Mean
Square F Sig.
#1
Tidigare erfarenhet Between Groups 1,157 3 ,386 ,361 ,782
Within Groups 62,021 58 1,069
Total 63,177 61
#2
Metod för att lära Between Groups 1,961 3 ,654 ,389 ,761
sig programmera Within Groups 97,410 58 1,679
Total 99,371 61
#3
Kännedom om rikt- Between Groups 1,051 3 ,350 1,387 ,256
linjer för Javakod Within Groups 14,643 58 ,252
Total 15,694 61
#4
Kunskap om hur kod Between Groups 1,416 3 ,472 ,720 ,544
av kvalité bör skrivas Within Groups 38,019 58 ,656
Total 39,435 61
#5
Följer aktivt Javas Between Groups 1,844 3 ,615 ,554 ,647
kodkonventioner Within Groups 64,349 58 1,109
Total 66,194 61
”Sum of Squares” är ett mått på hur spridda värden är runt sitt medelvärde. Stor spridning ger stort värde. ”df” är antalet frihetsgrader, ”Mean Square” är en skattning av variansen i populationen och ”F” är ett mått på hur långt ifrån varandra gruppernas medelvärde ligger i förhållande till hur spridda värdena är inom grupperna. ”Sig.” är ett mått på hur mycket värdena signifikant skiljer sig mellan grupperna. Inga testresultat, beträffande bakgrund och tidigare erfarenhet, visar ett signifikansvärde under 0,05 vilket betyder att alla test är icke-signifikanta och därför ointressanta att undersöka vidare. Vi kan med 95% säkerhet konstatera att det inte finns någon signifikant skillnad mellan någon av grupperna.
5.2.2 Identifierare
På frågan om respondenterna tycker det är viktigt att lägga tid på att välja bra namn på klasser, metoder och variabler svarade en övervägande majoritet att de instämmer helt eller till stor del, se Figur 6.
Utifrån följande kodavsnitt, se Exempel 2, fick sedan respondenterna utvärdera och ge sina synpunkter med hänsyn till tre faktorer; klassnamn, metodnamn samt variabelnamn. Ko-den var medvetet dåligt utformad i motsats till Javas kodkonventioner för att undersöka om respondenterna kunde hitta och åtgärda dessa fel.
1 public c l a s s c a r { 2 private i n t s p e e d ; 3 4 public c a r (i n t s t a r t S p e e d ) { 5 s p e e d = s t a r t S p e e d ; 6 } 7 8 public void A c c e l e r a t e _ C a r (i n t _ i n c r e m e n t s p e e d ) { 9 s p e e d += _ i n c r e m e n t s p e e d ; 10 } 11 }
Exempel 2: Javaklass med felaktigt utformade identifierare
Figur 7 presenterar en sammanställning av de frågor som ställdes i samband med kodav-snittet i Exempel 2. Majoriteten av studenterna svarade att de instämmer delvis eller inte alls på de olika frågorna, vilket tyder på att de flesta studenter har en viss uppfattning och förståelse kring vad som klassas som mindre god kvalité i avseende på identifierare.
Figur 7: Sammanställning av svaren från fråga 10, 12 och 14
Varje fråga följdes av en frivillig följdfråga där studenterna kunde ge förslag vad de hade velat ändra i koden. På följdfrågan för fråga 10 valde 43 stycken studenter att lämna syn-punkter på vad de hade velat förbättra i koden. Det som flest studenter påpekade var att klassnamnets första bokstav alltid skall vara en versal.
På följdfrågan för fråga 12 valde 49 studenter att lämna sina synpunkter. Här var den mest frekventa synpunkten att metodnamnet skulle utformas enligt camelCase-formatet, samt att konstruktorn skall vara identiskt med klassnamnet, dvs att den skall börja med en versal. Några få tyckte att metodnamn endast bör innehålla verb och således utesluta ”_Car” ur namnet ”Accelerate_Car”.
På följdfrågan för fråga 14 valde 47 studenter att lämna sina synpunkter på vad som hade kunnat förbättras. Majoriteten av respondenterna ville ta bort understrecket i inledningen av ”_incrementspeed” och skriva samma namn enligt camelCase-formatet. Men det var också en hel del studenter som endast ville ta bort understrecket men behålla namnen i övrigt.
Efter summering av respondenternas åsikter kring identifierare kan vi slå fast att genom-snittsstudenten reagerar starkast på stor eller liten bokstav i klassnamn, att namnsättning av identifierare bör utformas enligt camelCase-format och att variabler inte bör börja med ett understreck.
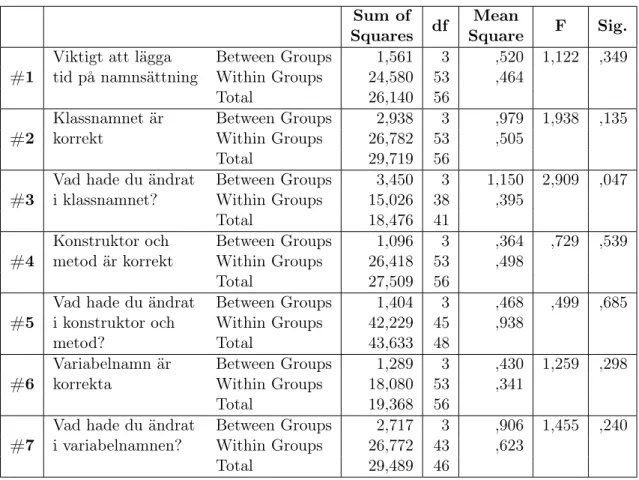
Tabell 4 visar resultet för alla ANOVA-test för alla påståenden som ingick i delen för identifierare i enkäten.
Tabell 4: ANOVA-test på frågorna som berör identifierare Sum of
Squares df
Mean
Square F Sig.
#1
Viktigt att lägga Between Groups 1,561 3 ,520 1,122 ,349
tid på namnsättning Within Groups 24,580 53 ,464
Total 26,140 56
#2
Klassnamnet är Between Groups 2,938 3 ,979 1,938 ,135
korrekt Within Groups 26,782 53 ,505
Total 29,719 56
#3
Vad hade du ändrat Between Groups 3,450 3 1,150 2,909 ,047
i klassnamnet? Within Groups 15,026 38 ,395
Total 18,476 41
#4
Konstruktor och Between Groups 1,096 3 ,364 ,729 ,539
metod är korrekt Within Groups 26,418 53 ,498
Total 27,509 56
#5
Vad hade du ändrat Between Groups 1,404 3 ,468 ,499 ,685
i konstruktor och Within Groups 42,229 45 ,938
metod? Total 43,633 48
#6
Variabelnamn är Between Groups 1,289 3 ,430 1,259 ,298
korrekta Within Groups 18,080 53 ,341
Total 19,368 56
#7
Vad hade du ändrat Between Groups 2,717 3 ,906 1,455 ,240
i variabelnamnen? Within Groups 26,772 43 ,623
Total 29,489 46
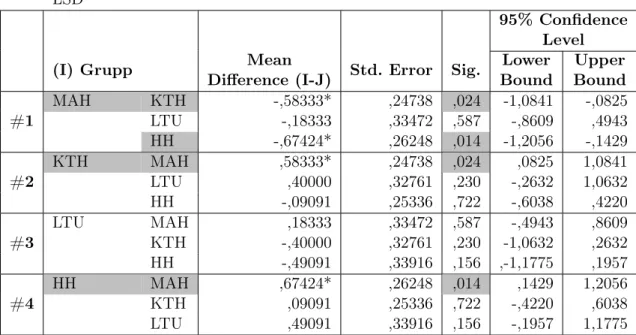
Alla test utom test #3 har ett signifikansvärde över 0,05 d.v.s. resultatet för dessa är icke-signifikant. Därför är det meningslöst att gå vidare med dessa och undersöka skillna-der mellan enskilda skolor. Test #3 visar däremot ett signifikansvärde (se kolumn ”Sig.” i Tabell 4) under 0,05 vilket innebär att vi kan med 95% säkerhet säga att det finns en statistisk skillnad mellan minst två gruppers medelvärden i detta test som inte beror på slumpen. Nollhypotesen för detta test kan därför komma att behöva förkastas. För att ta reda på detta och mellan vilka grupper resultatet skiljer sig åt gjordes ett Post Hoc-test för test #3. Resultatet för detta test presenteras i Tabell 5. De gråa cellerna i tabellen markerar mellan vilka grupper medelvärdesskillnaden är som störst samt deras respektive signifikansvärde.
Tabell 5: Post Hoc-test för test #3 Dependent Variable: Vad hade du ändrat i klassnamnet? LSD
95% Confidence Level
(I) Grupp Mean
Difference (I-J) Std. Error Sig.
Lower Bound Upper Bound MAH KTH -,58333* ,24738 ,024 -1,0841 -,0825 LTU -,18333 ,33472 ,587 -,8609 ,4943 #1 HH -,67424* ,26248 ,014 -1,2056 -,1429 KTH MAH ,58333* ,24738 ,024 ,0825 1,0841 LTU ,40000 ,32761 ,230 -,2632 1,0632 #2 HH -,09091 ,25336 ,722 -,6038 ,4220 LTU MAH ,18333 ,33472 ,587 -,4943 ,8609 KTH -,40000 ,32761 ,230 -1,0632 ,2632 #3 HH -,49091 ,33916 ,156 ,-1,1775 ,1957 HH MAH ,67424* ,26248 ,014 ,1429 1,2056 KTH ,09091 ,25336 ,722 -,4220 ,6038 #4 LTU ,49091 ,33916 ,156 -,1957 1,1775
*. The mean difference is significant at the 0.05 level.
I detta test visade det sig att signifikansvärdet underskrider 0,05 mellan Malmö Högsko-la (MAH) och Kungliga Tekniska HögskoHögsko-lan (KTH) samt Malmö HögskoHögsko-la (MAH) och Högskolan i Halmstad (HH). Vi kan därför med 95% säkerhet konstatera att det finns en statistisk skillnad mellan dessa lärosäten och således förkasta vår nollhypotes för denna specifika fråga. Detta kommer att diskuteras ytterligare i kapitel 5.2.5.
5.2.3 Kommentarer
På frågan om respondenterna tycker det är viktigt att lägga tid på att kommentera sin kod svarade de allra flesta att de instämmer helt. En mindre skara tycker inte alls att detta är något man bör lägga ner tid på och svarade följaktligen instämmer inte alls på frågan, se Figur 8.
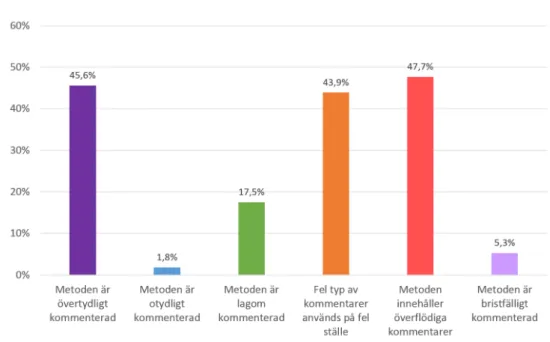
Utifrån följande kodavsnitt, se Exempel 3, ställdes en flervalsfråga där respondenterna fick välja fritt antal påståenden de tyckte kunde appliceras på kommentarerna i Exempel 3. Respondenterna hade sex svarsalternativ att välja mellan och resultatet presenteras som ett stapeldiagram i Figur 9. Även i detta exempel var kommentarerna medvetet dåligt utformade utifrån ett kvalitétsperspektiv och med hänsyn till Javas kodkonventioner. Re-sultatet visar att respondenterna verkar vara överens om att för många, och framförallt uppenbara, kommentarer inte fyller någon funktion mer än att ta upp plats.
1 // T h i s method t a k e s two p a r a m e t e r s , a d d s them t o g e t h e r 2 // and r e t u r n s t h e sum . 3 public i n t sum (i n t a , i n t b ) { 4 5 /∗ R e t u r n s t h e t o t a l v a l u e o f a + b ∗/ 6 return a + b ; 7 }
Exempel 3: Kommenterad Javametod
Figur 9: Studenternas åsikter kring kommentarerna i Exempel 3
På följdfrågan som var frivillig och där respondenterna fick möjlighet att lägga till, ta bort eller ändra någon kommentar i kodsnutten, valde 44 personer att ge sina synpunkter. Majoriteten tyckte att metoden skulle föregås av en Javadoc-kommentar och att den sista kommentaren borde tas bort helt. Några få tyckte att metoden förklarar sig själv och därför inte bör kommenteras alls.
Tabell 6 visar resulten för alla ANOVA-test som ingick i kommentarsdelen av enkäten. Tabell 6: ANOVA-test för kommentarsdelen
Sum of
Squares df
Mean
Square F Sig.
#1
Viktigt att lägga Between Groups 3,271 3 1,090 1,529 ,218
tid på kommentering Within Groups 37,782 53 ,713
Total 41,053 56
#2
Vilka alternativ Between Groups 1,946 3 ,649 2,819 ,048
passar in på kod- Within Groups 12,194 53 ,230
snutten? Övertydlig Total 14,140 56
#3
Vilka alternativ Between Groups ,059 3 0,020 1,136 ,343
passar in på kod- Within Groups ,923 53 0,017
snutten? Otydlig Total ,982 56
#4
Vilka alternativ Between Groups ,366 3 ,122 ,820 ,489
passar in på kod- Within Groups 7,880 53 ,149
snutten? Lagom Total 8,246 56
#5
Vilka alternativ Between Groups 1,133 3 ,378 1,552 ,212
passar in på kod- Within Groups 12,902 53 ,243
snutten? Fel typer Total 14,035 56
#6
Vilka alternativ Between Groups ,190 3 ,063 ,239 ,869
passar in på kod- Within Groups 14,056 53 ,265
snutten? Överflödig Total 14,246 56
#7
Vilka alternativ Between Groups ,032 3 ,011 ,198 ,897
passar in på kod- Within Groups 2,811 53 ,053
snutten? Bristfällig Total 2,842 56
#8
Vad hade du ändrat Between Groups ,374 3 ,125 ,232 ,874
i kommentarerna? Within Groups 21,512 40 ,538
Total 21,886 43
Alla test utom #2 har ett signifikansvärde (se kolumn ”Sig.” i Tabell 6) över 0,05 d.v.s. resultaten för dessa är icke-signifikanta och därför ointressanta att undersöka vidare. Test #2 visar däremot ett signifikansvärde under 0,05 vilket innebär att vi kan med 95% säkerhet säga att det finns en statistisk skillnad mellan minst två gruppers medelvärden. För vidare analys genomfördes även här ett Post Hoc-test på svaren för denna fråga, vilket kan ses i Tabell 7. De gråa cellerna i tabellen markerar mellan vilka grupper medelvärdesskillnaden är som störst samt deras respektive signifikansvärde.
Tabell 7: Posthoc-test för svarsalternativet ”övertydlig”
Dependent Variable: Vilka alternativ passar in på kodsnutten? Övertydlig LSD
95% Confidence Level
(I) Grupp Mean
Difference (I-J) Std. Error Sig.
Lower Bound Upper Bound MAH KTH ,15000 ,16088 ,355 -,1727 ,4727 LTU -,37500 ,20770 ,077 -,7916 ,0416 #1 HH ,19231 ,17910 ,288 -,1669 ,5515 KTH MAH -,15000 ,16088 ,355 -,4727 ,1727 LTU -,52500* ,20066 ,012 -,9275 -,1225 #2 HH ,04231 ,17089 ,805 -,3004 ,3851 LTU MAH ,37500 ,20770 ,077 -,0416 ,7916 KTH ,52500* ,20066 ,012 ,1225 ,9275 #3 HH ,56731* ,21554 ,011 ,1350 ,9996 HH MAH -,19231 ,17910 ,288 -,5515 ,1669 KTH -,04231 ,17089 ,805 -,3851 ,3004 #4 LTU -,56731* ,21554 ,011 -,9996 -,1350
*. The mean difference is significant at the 0.05 level.
Detta Post Hoc-test visar att signifikansvärdet underskrider 0,05 mellan Luleå Tekniska Universitet (LTU) och Kungliga Tekniska Högskolan (KTH) samt Luleå Tekniska Universi-tet (LTU) och Högskolan i Halmstad (HH). Vi kan därför med 95% säkerhet konstatera att det finns en statistisk skillnad mellan dessa lärosäten och således förkasta vår nollhypotes för denna specifika fråga. Detta kommer att diskuteras ytterligare i kapitel 5.2.5.
5.2.4 Format och struktur
På frågan om respondenterna tycker det är viktigt att lägga tid på att strukturera sin kod svarade en stor majoritet att de instämmer helt, se Figur 10. Ingen respondent svarade att de inte höll med alls och endast 1,8% av respondenterna svarade att de till viss del höll med. Detta tyder på att studenter anser att struktur är av stor betydande karaktär när det kommer till att göra koden tydlig.
Figur 11 visar en sammanställning av de påståenden och svar som ingick i slutet av del två som behandlar struktur och formatering av kod.
Figur 11: Svarsfördelningen på fråga 20 och 21
Andelen respondenter som höll med helt i påståendet att en välstrukturerad kod bidrar till en markant ökad läsförståelse uppmättes till 89,5%, se fråga 20 i Figur 11. På fråga 21 svarade 61,4% att de inte instämmer alls. En mindre del, 31,6% höll med till viss del på samma påstående medan ytterst få personer svarade att de instämmer helt eller till stor del. Diagrammen i Figur 10 och Figur 11 visar att majoriteten av respondenterna är tydliga i sina svar och vi bör därför av svaren kunna avläsa att format och struktur är en aspekt som anses vara viktig för att öka läsbarheten och kvalitén på koden.
Tabell 8 visar alla ANOVA-test för alla påståenden som ingick i delen för formatering i enkäten.
Tabell 8: ANOVA-test för formateringsdelen Sum of
Squares df
Mean
Square F Sig.
#1
Viktigt att lägga Between Groups 1,100 3 ,367 1,515 ,221
tid på struktur Within Groups 12,830 53 ,242
Total 13,930 56
#2
Välstrukturerad Between Groups ,105 3 ,035 ,307 ,820
kod leder till ökad Within Groups 6,036 53 ,114
läsförståelse Total 6,140 56
#3
Spelar mindre roll Between Groups 1,103 3 ,368 ,776 ,513
med välstrukturerad Within Groups 25,108 53 ,474
kod Total 26,211 56
Alla test har ett signifikansvärde (se kolumn ”Sig” i Tabell 8) över 0,05 dvs. alla test är icke-signifikanta och ointressanta att undersöka vidare. Vi kan, likt de flesta ANOVA-test i kap 5.2.1, 5.2.2 samt kap 5.2.3, därför med 95% säkerhet konstatera att det inte finns någon statistisk skillnad mellan grupperna rörande format och struktur enligt våra mätningar.
5.2.5 Sammanfattning
Det övergripande resultatet av studien visar att studenters förhållningssätt till Javas kod-konventioner inte signifikant skiljer sig nämnvärt mellan de lärosäten som deltog i under-sökningen. Detta trots att vid två test visade ANOVA-testen en signifikant skillnad mellan minst två lärosäten. Det ena resultatet som visade en signifikant skillnad var test #3 i Tabell 4 i kapitel 5.2.2. Resultatet bestod av öppna svar från en frivillig följdfråga till påståendet att klassnamnet i Exempel 2 (se kapitel 5.2.2) är självförklarande och korrekt utformat. Det visade sig att medelvärdesskillnaden var som störst mellan Malmö Högsko-la och Kungliga Tekniska HögskoHögsko-lan samt Malmö HögskoHögsko-la och HögskoHögsko-lan i Halmstad. Från svaren kunde vi identifiera olika trender. Majoriteten av respondenterna påpekade att klassnamnet alltid skall inledas med en versal. På andra frågor, som t.ex berörde iden-tifierare där resultatet var icke-signifikant, var det tydligt att respondenterna reagerade starkast på inkonsekvensen gällande metod och variabelnamnen. Det populäraste förslaget för hur koden kunde förbättras var att använda camelCase-format på alla identifierare. De förslag studenterna angav går i linje med vad Javas kodkonventioner säger vilket påvisar en förståelse för konventionerna.
Det andra resultatet som visade en signifikant skillnad var test #2 i Tabell 6 i kapitel 5.2.3, där resultatet från svartsalternativet ”metoden är övertydligt kommenterad” analy-serades. Det visade sig att medelvärdesskillnaden var som störst mellan Luleå Tekniska Universitet och Kungliga Tekniska Högskolan samt mellan Luleå Tekniska Universitet och Högskolan i Halmstad. En möjlig bidragande faktor till varför vissa studenter tycker koden är övertydligt kommenterad kan vara tidigare erfarenhet. Vana programmerare kan tendera att tycka att koden är övertydligt kommenterad medan mindre erfarna programmerare ser det som nödvändigt för att kunna följa och förstå koden bättre. Att skolorna skiljer sig åt i våra mätningar kan således bero på att den genomsnittliga erfarenheten bland studenterna varierar.
Då 21 av 23 ANOVA-test visade ett icke-signifikant resultat kan vi därför slå fast att på det stora hela skiljer det sig inte nämnvärt mellan de lärosäten som deltog i under-sökningen. Det skall dock påpekas att alla svar inte var homogena, det fanns de svar som påvisade tendenser till skillnader, men inte tillräckligt för att vi skulle kunna förkasta vår nollhypotes.
5.3 Åsikter i relation till faktisk kod
Studien syftade också till att söka svar på hur högskoleingenjörsstudenter inom datateknik förhåller sig till de kodkonventioner som finns angående Java. De flesta studenter kände till Javas kodkonventioner sedan innan och ungefär hälften av dem ansåg sig ha goda kunska-per i hur kod av hög kvalité bör skrivas. För att underlätta har vi i Figur 12 sammanställt påståendena kring hur viktiga de olika aspekterna är enligt respondenterna. Diagrammet visar tydligt att den övervägande majoriteten av studenterna tyckte att det var viktigt att lägga tid på att namnsätta, kommentera och strukturera sin kod. Resultatet visar att studenterna inte nöjer sig med att koden endast utför sitt syfte utan värdesätter att ha en bra strukturerad kod av bra kvalité. Enligt Truong et al. [8] kan studenter i många fall annars snabbt konstruera sitt program utan att reflektera över kodens kvalité och vara nöjda när de väl fått sitt program att fungera utan att fundera över om programmet kan skrivas på annat sätt. Men studenterna i vår studie visar överlag att de är villiga att lägga tid på saker som kan bidra till att kvalitén av koden ökar.
Figur 12: Översikt över alla påståenden som berör vikten av att lägga tid på de olika aspekterna I del tre av enkäten, där studenterna själva fick modifiera en stökig och dåligt utformad kod efter eget tycke och smak, kan man urskilja ett mönster mellan deras åsikter om hur viktiga de olika aspekterna är och den kod de själva fick redigera. Som kan ses i Figur 12 var det flest respondenter som tyckte det det var viktigt att lägga tid på att strukturera sin kod. Detta visade sig också vara den aspekt som studenterna överlag presterade bäst på i del tre av enkäten. Den aspekt studenterna tyckte var näst viktigast att lägga tid på var namnsättning av identifierare, vilket också visar sig var den del studenterna pre-sterade näst bäst på i del tre av enkäten. Kommentarer var det som enligt studenterna var minst viktigast att lägga tid på, vilket också gick att urskilja i del tre. Att välja rätt kommentarstyp vid rätt tillfälle var något många generellt hade problem med. Vid jäm-förelse mellan lärosätena visade det sig att studenterna vid Malmö Högskola procentuellt sett visade tendenser till att ha högre förståelse för hur kommentarer skall utformas enligt Javas kodkonvention. Detta kan bero på många faktorer men som Nurvitadhi et al. [29] diskuterar i sin artikel så ger många Javaböcker olika riktlinjer för hur kommentarer skall skrivas. En kombination av vad läraren väljer att lära ut samt vilken lärobok de väljer att använda sig av kan komma att spela roll för hur duktiga studenter blir på att skriva kommentarer av rätt typ. En noga genomgång av varje lärosätes kursplan för Javakurser visar även att de alla använder sig av olika läroböcker i sina kurser, se bilaga C, vilket då skulle styrka tesen som Nurvitadhi et al. [29] presenterade i sin artikel.
Vi kan efter detta dra slutsatsen att studenternas åsikter om hur viktiga de olika aspek-terna av kodkvalité är speglar det resultat vi ser i del tre av enkäten. Överlag tenderar studenterna ha svårt att veta vilka kommentarstyper som skall användas vid olika tillfällen men har koll på vad en kommentar bör innehålla och inte innehålla samt förstå vad t.ex. en överflödig kommentar är, se Figur 9. Men att studenterna istället har en bra uppfattning av hur strukturering av kod skall gå till samt hur namnsättning av identifierare skall sättas, enligt Javas kodkonventioner.
5.4 Inlärningsmetod
Hur studenter förhåller sig till Javas kodkonventioner kan grunda sig i hur de väljer att lära sig programmering. Som visas i Figur 4 i del 5.2.1 så ansåg majoriteten av de svarande att en kombination av föreläsningar, laborationer, läsa böcker och med hjälp av Internet och/eller onlineforum var det bästa sättet att lära sig programmering. Knappt en femtedel hävdade att de endast föredrar Internet och/eller onlineforum som bästa metod. En lik-nelse kan dras mellan detta resultat och det resultat Isong och Dominic [27] presenterar i sin studie. Det gör att det finns skäl att anta att böcker allt mer ses som ett förlegat sätt att lära sig programmering, och att allt fler använder Internet som källa för att inhämta information. Den enkla tillgången till plattformar på nätet som bedriver online-kurser i programmering kan också ses som ett skäl till varför allt mindre studenter föredrar böcker som läromedel. Det är därför rimligt att misstänka att Internet har lett till att studenter tidigare har kommit i kontakt med Javas kodkonventioner än om de skulle läsa böcker om programmering, då dessa konventioner ligger närmare till hands på nätet.
91,9% av de svarande sade sig känna till Javas kodkonventioner sedan tidigare och stu-denterna presterade överlag bra på del tre av enkäten. Trots att bara 25% av stustu-denterna aktivt tänker på kodkonventionerna när de programmerar, kan vi ändå dra slutsatsen att studenterna generellt enligt våra mätningar har koll på vad Javas kodkonventioner säger och hur de skall användas. Även om att de flesta studenter inte alltid direkt tänker på kodkonventionerna under tiden de programmerar så kan det tänkas att de indirekt pro-grammerar efter dem även om de inte själva är medvetna om det.
5.5 Studiens giltighet
I studien används en form av triangulering, datatriangulering, som betyder att ta in infor-mation (intervjuer, enkäter, mätningar) från flera källor och sedan analysera dessa och dra paralleller till vad tidigare forskning säger. Enligt Jick [33] gör triangulering att trovärdig-heten för resultatet i studien ökar samt ger skäl till att det går att lita på de slutsatser som dras för att svara på forskningsfrågorna. Men då samplingsstorlekarna från de olika lärosätena var så pass olika och en underrepresentation av Luleå Tekniska Universitet så måste detta tas hänsyn till och vi måste vara försiktiga med att dra generella slutsatser för hela populationen.
Som tidigare nämns i kapitel 3.7 har vi under studiens gång varit väl medvetna om att subjektiva bedömningar av svar kan påverka studiens reliabilitet. Bedömningarna har där-för varit stränga, konsekventa och fria från egna tolkningar i den bemärkelsen att otydliga svar inte har försökt att tolkas där budskapet inte klart framgår i svaret.