Fakulteten för teknik och samhälle Datavetenskap
Examensarbete 15 högskolepoäng, grundnivå
Procedurell Generering av Tredimensionella
”Pseudo-oändliga” Dungeons genom L-system
Procedural Generation of Three Dimensional ”Pseudo Infinite” Dungeons through L-systems
Fabian Sturk
André Tran
Examen: (Kandidatexamen 180 hp) Huvudområde: (Datavetenskap) Program: (Spelutveckling) Datum för slutseminarium: (2016-08-23)Handledare: Steve Dahlskog
Sammanfattning
I den här uppsatsen presenteras ett nytt sätt att procedurellt generera pseudo-oändliga dungeons som kan traverseras i tre dimensioner. För att hålla genereringen koherent både under och mellan spelsessioner utgår genereringen från ett ”seed”. Ett seed garanterar sam-ma innehåll på samsam-ma plats varje gång miljön genereras. Med en metod som är baserad i L-system genererar vi här en maze dungeon med tvådimensionell grammatikexpansion och vi undersöker sedan hur duglig den är. Vi försöker få svaret på hur avancerade L-system som krävs för att nå en nivå av variation som känns tillräcklig för en miljö av pseudo-oändlig karaktär. Variationstestet samlar data från ett urval områden i den färdiggenererade dung-eonen. Resultaten visar på att den utvecklade metoden i det här projektet fungerar väl för ändamålet.
Abstract
In this paper we present a novel way of procedurally generating pseudo infinite dungeons that can be traversed in three dimensions. To ensure consistent generation both during and between playing sessions the generation is ”seeded”. Seeded generation guarantees the same content in the same place every time the environment is generated. Using a method based in L-systems we generate a maze dungeon with two dimensional grammar expansion and explore its viability. We try to find the needed complexity of the L-system to achieve a level of variation that feels adequate for an environment of pseudo infinite character. The variation tests collect data from sample areas in the generated dungeons. The results indicate that the method used in this project works well for the intended purpose.
Innehåll
1 Inledning 1
1.1 Bakgrund och tidigare forskning . . . 1
1.1.1 Dungeons . . . 1 1.1.2 Pseudo-oändlighet . . . 3 1.1.3 L-system . . . 3 1.2 Syfte . . . 3 1.3 Frågeställning . . . 3 1.4 Hypotes . . . 4 1.5 Relevans . . . 4 2 Metod 4 2.1 Metodbeskrivning . . . 4 2.2 Design Science . . . 4
2.2.1 Vad Design Science är . . . 4
2.2.2 Hur Design Science användes under projektet . . . 5
2.3 Litteraturstudie . . . 6 2.4 Demonstration . . . 6 2.4.1 Testmiljö . . . 7 3 Lösning 7 3.1 Algoritmen . . . 7 3.1.1 Nummergenerator . . . 7 3.1.2 Seed-generator . . . 8 3.1.3 L-System . . . 8 3.1.4 BFS . . . 9 3.1.5 Union-Find . . . 10 3.1.6 Vertikala öppningar . . . 10 4 Resultat 11 4.1 Produktionsregler . . . 11 4.2 Variationstest . . . 12 5 Analys 14 5.1 Analys av resultaten . . . 14 5.1.1 Produktionsregler . . . 14 5.1.2 Variationstest . . . 15 5.2 Analys av lösningen . . . 16 5.2.1 Matematisk analys . . . 16 6 Diskussion 16 6.1 Saker vi inte gjorde . . . 17
7 Slutsatser och vidare forskning 17
Appendix A: Söktermer 20
Appendix B: Ordlista 21
1
Inledning
1.1 Bakgrund och tidigare forskning
Procedural Content Generation (PCG) är ett begrepp som beskriver metoder för att genere-ra innehåll främst för digitala spel. Forskningen inom PCG fortsätter att växa och används i allt fler spel. Det finns många olika användningsområden för PCG och sträcker sig från nödvändigt innehåll som spelnivåer till ickenödvändigt som rekvisita och bakgrundsobjekt. Kraven på innehåll i spel ökar i takt med att datorkraft och budgetar för spel ökar. Vi har kommit till en punkt där kostnaden av att göra spel har blivit så högt att det inte längre är rimligt att producera allt innehåll för hand [1]. När både kvalitet och kvantitet av spelinnehåll förväntas av många spel så har procedurell generering blivit ett verktyg inom spelutveckling som allt fler förlitar sig på i någon grad. Metoder och system som kan produ-cera varierande och högkvalitativt innehåll som liknar det handgjorda kan spara både tid och pengar i många projekt. Procedurell generering har varit en komponent i framgångsri-ka spel [2, 3]. Ett framträdande koncept inom procedurell generering är pseudo-oändlighet, exempelvis storleken på spelvärlden [2] eller antalet vapen [4]. Spelvärldar saknar ofta höjdimensionen, tredimensionella världar blir därför ofta endast tvådimensionellt pseudo-oändliga. Höjd är en intressant dimension i spel men är fortfarande ett relativt outforskat område.
1.1.1 Dungeons
En innehållskategori med omfattande forskning bakom sig är dungeons, vilket är spelnivåer som ofta är slumpartade för att göra spelet med oförutsägbart och omspelbart. Dungeons förekommer i många former och formerna har tidigare delats upp i fem kategorier; Con-nected Rooms, Rooms & Corridors, Maze, Labyrinth och Open area [3]. Maze-baserade dungeons har tidigare gjorts med hjälp av flera metoder, ett par välanvända metoder är Kruskal, Prim, DFS, Recursive Backtracker och Cellular Automata [5].
1. Connected rooms är en av de vanligaste typerna av dungeons i klassiska textbase-rade aventyrsspel. Den är uppbyggd så att spelaren kan röra sig från ett rum utan korridorer, vägar eller tunnlar till ett annat rum. Exempel på spel med den här upp-byggnaden är Binding of Isaac [6], Zork [7] och The Legend of Zelda [8] (se Figur 1).
2. Rooms & Corridors är en typ av dungeon med rum som är kopplade med icke-förgrenande (non-branching) korridorer. Korridorerna är ett funktionellt spelutrym-me där olika händelser kan ske. Ett vanligt exempel på ett spel spelutrym-med Rooms & Cor-ridors är Rogue [9] (se Figur 2).
3. Labyrinths är dungeons som har en envägsstruktur där det endast finns en väg som leder spelaren genom nivån. Ett exempel är Ultima II [10] (se Figur 3).
4. Mazes är dungeons som har en flervägsstruktur där flera olika vägar kan leda spelaren genom nivån. Spel som World of Doom och Ultima I [11] har sådana strukturer i sina dungeons (se Figur 4).
5. Open area är oftast väldigt öppna (för dungeons) och innehåller hinder (t.ex. smala väggar) som hindrar spelaren från att förflytta sig hur de vill. Den här typen har en taktisk uppbyggnad som spelar en större roll där spelaren behöver analysera den direkta omgivningen mer än i andra former av dungeons. I en open area-dungeon så är korridorer ovanliga. Spel som Telengard [12] och Diablo [13] tillhör den här kategorin (se Figur 5).
Figur 1: Illustration av Connected
Rooms Figur 2: Illustration av Rooms and Cor-ridors
Figur 3: Illustration av Labyrinth Figur 4: Illustration av Maze
Figur 5: Skärmbild från spelet Diablo som visar Open Area
1.1.2 Pseudo-oändlighet
Oändlighet är ett tillämpningsområde för PCG som utforskats både akademiskt och inom spelindustrin. Äkta oändlighet i en virtuell värld och samtidigt behålla både variation och koherens i världen är en svår uppgift. Det här är en anledning till att benämna procedurell generering av oändlig karaktär “pseudo-oändlig”. För en ensam spelare är det genererade innehållet praktiskt sett oändligt då begränsningarna i genereringen endast syns på en makroskopisk nivå. Trots begränsningarna är därför pseudo-oändlig generering av ett visst innehåll fortfarande effektivt i en spelmiljö.
Tidigare har Greuter et al. visat att man kan generera pseudo-oändliga städer med varierande byggnader med hjälp en seedad nummergenerator baserad på byggnadernas positioner i världen [14]. Johnson et al. har visat att man kan uppnå oändlighetsstorlekar på spelnivåer som ser som grottor med hjälp av Cellular Automata [15]. Kommersiella spel som har pseudo-oändliga spelvärldar inkluderar Minecraft och det kommande No Man’s Sky.
1.1.3 L-system
L-system [16] är ett genereringssystem som producerar strängar eller symboler efter spe-cifika produktionsregler. L-system kallas även för generativ grammatik och använder sig av ett alfabet med startsymboler, eller axiom, och en rad produktionsregler för varje sym-bol. Generativ grammatik körs i ett förbestämt antal generationer beroende på syfte och tillämpning. Det finns flera sätt att designa L-System med olika komplexitet på önskad utdata. Den minst komplexa genereringen är endimensionell, en sträng som endast expan-deras. Den endimensionella generingen har visat sig vara användbar inom spelforskning för att generera uppdrag samt dess utrymmen [17]. Komplexiteten kan därefter ökas för andra syften och ett exempel på det inom spelforskning är generering av virtuella stenar [18]. De virtuella stenarna kunde åstadkommas med hjälp av en tredimensionell grammatikexpan-sion som kan producera unika stenformationer.
1.2 Syfte
Målet med den här forskningen är att utveckla en metod för att generera pseudo-oändliga dungeons i tre dimensioner. Genererade dungeons ska kunna traverseras utifrån antingen ett första- eller tredjepersonsperspektiv. Vid samma förhållande ska en dungeon alltid genereras likadant och ska hålla sig koherent under spelets gång och innehållet ska vara varierande.
1.3 Frågeställning
Hur avancerat L-system krävs för att generera en maze dungeon av pseudo-oändlig karaktär med mätbar variation?
1.4 Hypotes
Vi tror att man kommer att se en tillräckligt varierande maze dungeon när man kommer över tio axiom och produktionsregler för varje genererade block. Generering med färre axiom och produktionsregler bör inte vara tillräckligt för att åstadkomma det önskade resultatet och kommer visa på liten variation.
1.5 Relevans
Det här arbetet kan komma att ge en ny inblick inom forskning kring såväl pseudo-oändlighet inom digitala spel, grammatikexpansion och maze-generering.
2
Metod
I det här kaptilet förklaras metoden som har använts under projektets gång. 2.1 Metodbeskrivning
För att undersöka den frågeställning som arbetet är baserat på har fyra metoder använts; Design Science, litteraturstudie, själva algoritmen och utvärdering. Design Science gav oss en arbetsstruktur som bevisats vara effektiv och passande för arbeten som vårt. Littera-turstudien gav oss den förkunskap inom ämnet som vi behövde för att kunna genomföra arbetet. Algoritmen som utvecklades gav oss den artefakt som passade in på den fråge-ställning vi ville undersöka. Testerna gav oss till sist den data på vår artefakt som vi kunde använda till analys och resultat.
2.2 Design Science
2.2.1 Vad Design Science är
Det är viktigt att skapandet av en artefakt görs på ett vetenskapligt och koherent sätt. Vi har därför valt att använda oss av Design Science som inom datavetaskap anses vara en av de bättre metodikerna för skapande av artefakter [19]. Fokuset med Design Science är att den specifikt riktar sig mot att hitta svar på problem som är relevata för skapandet av ny teknik. Metoden är uppdelad i sex steg, som beskrivs kort här nedan. Följande definitioner är baserade på Peffers et al. [19] och Hevner et al. [20].
1. Problemidentifikation och motivering: Först bör ett specifikt forskningsproblem bli definierat och sedan bör det motivera värdet av en lösning. Eftersom problemde-finitionen kommer att användas som en bas för utvecklingen av en artefakt kan det här vara användbart att skala ner problemet så att man kan förstå dess komplexitet [19].
2. Definition av målen för en lösning: I det här steget så ska man utifrån problem-definitionen bestämma målet för en lösning och få en uppfattning om vad som är genomförbart. Målet kan vara kvantitativt, där den önskvärda lösningen är bättre än nuvarande lösningar. Målet kan också vara kvalitativt, där en ny artefakt kan stödja tidigare lösningar för ett visst problem. Det som behövs i det här steget är en uppfattning om problemet och en planerad lösning på problemet [19].
3. Design och utveckling: I det här steget så skapar man artefakten [19]. Hevner et al. [20] definierar olika typer av artefakter. Dessa är följande: constructs (vokabulär och symboler), models (abstraktioner och representationer), methods (algoritmer och kutymer) och instantiations (implementerade system och prototypsystem) [20]. 4. Demonstration: Här ska man demostrera användningen av sin artefakt för att lösa
en eller flera instanser av de definierade problemen. Experimenten kan genomföras genom simulering, fallstudier, bevis, eller andra lämpliga aktiviteter [19].
5. Utvärdering: Efter demostationen av sin artefakt så ska man observera och mäta hur väl artefakten stöder lösningen till problemet. Det här innefattar att jämföra lösningen med det faktiska observerade resultat från användning av artefakten i de-monstrationen. Beroende på problemet och artefakten så kan evalueringen ta många olika former. Utvärderingen kan innehålla olika typer av empiriska eller logiska bevis. I det här steget så kan man antingen iterera tillbaka till aktivitet 3 för att förbättra effektiviteten av artefakten eller välja att fortsätta vidare till kommunikation och lämna ytterligare förbättring till senare projekt [19].
6. Kommunikation: I detta steget så ska man vidarebefodra det information man har samlat ihop som problemet, artefakten, verktyget, användningsområde m.m. till forskare eller relevanta målgrupper [19].
2.2.2 Hur Design Science användes under projektet
1. Problemidentifikation och motivering: I början av projektet så började vi med att undersöka om vad det fanns för potentiella problem inom PCG. Det här gjorde vi med hjälp av en litteraturstudie tillsammans med egna iaktagelser av spelbranschen. 2. Definition av målen för en lösning: Efter att ha identifierat problemet så satte vi upp ett mål, för att se om vad som är möjligt eller ej och hur vi ska gå tillväga för att avsluta arbetet. Vi bestämde oss för att sätta upp ett kvalitativt mål.
3. Design och utveckling: Efter målen var uppsatta och vi hade samlat in tillräckligt med litteratur och forskning som stöd så startade vi designprocessen och utvecklings-processen av våra artefakt. Vi valde att skapa en artefakt av typen methods [20] men det finns delar av artefakten som även hamnar i de andra kategorierna.
4. Demonstration: Demonstationen av artefakten sker med hjälp av ett variationstest, där vi testar x antal axiom åt gången för att se vad skillnaden är mellan dem. Detta gör vi genom att låta en agent gå genom vår dungeon. Det agenten gör sen är att den kollar hur varierande dungeonen är beroende på antal axiom. I avsnitt 2.4 följer en mer djupgående förklaring.
5. Utvärdering: Under det här steget så har vi samlat in data från testerna. För att visualisera resultaten så använder vi oss av heatmaps, där vi visar upp hur varierande dungeons man får beroende på hur många axiom man har. Se kapitel 3 för en mer djupgående förklaring.
6. Kommunikation: För att dela med oss om den kunskap vi fått under det här arbetet har vi dokumenterat vår arbetsgång och tillvägagångssätt och samlat allt i den här uppsatsen. Den här uppsatsen kommer sedan vara tillgänglig för de målgrupper som kan finna intresse av vårt arbete.
2.3 Litteraturstudie
För att fördjupa oss i forskningsområdet inom PCG så gjorde vi en litteraturstudie. Forsk-ningslitteraturen till studien är hämtade från ett antal databaser där IEEE och ACM är de två som användes mest under processen. Litteraturen var även hämtad från en annan databas, Digra, som är en databas mer riktad mot forskning inom spel. Litteraturstudien började med att söka efter information relaterat till PCG, med syfte att besvara forsk-ningsfrågan. Sökningarna gjordes genom databasernas egna sökverktyg. Detta ger oss en möjlighet att granska kvaliteten på litteraturen, med hjälp av noggrant dokumenterad in-formation som publikationsfakta, antalet gånger artikeln har blivit refererad och om det har blivit granskad av externa läsare. Utifrån den information som hittades så valde vi ut artiklar som var relevant för uppsatsens syfte. Detta gav oss den fördjupning för PCG som behövdes för att kunna utveckla en artefakt som kan hjälpa till med att hitta svar till forskningsfrågan.
Snowball-metoden användes under processens gång, syftet med metoden är att hitta forskning som är lik de framsökta artiklarna. Snowballing innebär att man använder re-ferenser från de artiklar som man har läst till att antingen få en djupare förståelse av litteraturen eller hitta andra artiklar som är relevanta till forskningen [21].
För att söka fram relevanta artiklar användes söktermer som: Procedural content ge-neration, pseudo infinite, dungeon, L-system, Breadth-first search.
2.4 Demonstration
För att evaluera vår artefakt använder vi oss av en metod som kan illustrera varierande drag som är karaktäristiskt för en pseudo-oändlig maze. Testet är uppbyggt för att visa skillnaden på variation utefter antalet axiom och produktionsregler i L-systemet som ligger i grund för genereringsalgoritmen. Vi testar fyra grupper; 4 axiom och produktionsregler, 8 axiom och produktionsregler, 10 axiom och produktionsregler, samt 15 axiom och pro-duktionsregler. För varje grupp så placeras en agent i mazen. Agenten besöker varje tile i en 30x30-matris och samlar data från varje tile. För att samla data från en specifik tile så ”skjuter” agenten strålar från sig själv utåt till strålen når närmaste vägg, så kallat raycasting. Varje stråle innehåller information om hur lång den själv hann bli innan den träffade en vägg och det är det mätvärdet som kommer användas.
Vid varje tile som agenten besöker skjuts två grupper med strålar. Den första gruppen, med fyra strålar, i riktningarna 3, 6, 9 och 12 på en klocka och illustrerar korridorfrekvens, se Figur 6. Den andra gruppen, med åtta strålar, i riktningarna 1, 2, 4, 5, 7, 8, 10 och 11 på en klocka illustrerar öppenhet, se Figur 6. När alla tiles i 30x30-matrisen har besökts läggs summorna från respektive grupp samman till två värden som representerar korri-dorfrekvensen och öppenheten för det testade området. För varje grupp testas 60 stycken områden med respektive 30x30 tiles eller 56,000 tiles per grupp.
Figur 6: Figur som illustrerar strålarna under testningen med färger för respektive grupp. 2.4.1 Testmiljö
För att utföra testerna utvecklade vi ett verktyg i samma miljö som artefakten är byggd i; Unity 5 [22]. På det här sättet kunde vi integrera verktyget med artefakten på ett smidigt sätt med direkt tillgång till de motorverktyg och den data som var nödvändig för att utföra testerna.
3
Lösning
För att bygga vår artefakt använde vi en algoritm som vi konstruerade utav flera kända datastrukturer inom datavetenskap samt PCG. Det här avsnittet kommer att gå igenom algoritmen steg för steg och beskriva ansvarsområdet för varje del.
3.1 Algoritmen
Algoritmen som vi utvecklade består av flera delar för att kunna producera rätt innehåll. Den centrala delen av algoritmen består av ett L-system som med indata från en seedad nummergenerator producerar väggar för sitt givna block. Ett block är en tvådimensionell struktur med 64 tiles. En bredden-först-sökning (BFS) går sedan igenom den genererade strukturen för att bygga dörrar mellan eventuellt slutna utrymmen, ”rum”, som uppkommit under väggenereringen. BFS används här tillsammans med Union-Find för att identifiera dessa rum och veta var det bör genereras dörrar. Den sista delen i genereringen är att bygga hål till den våning som ligger ovanför.
Den här sektionen kommer att beskriva algoritmens alla centrala delar och hur de är sammankopplade.
3.1.1 Nummergenerator
För att producera pseudo-slumpade nummer användes i det här fallet en generator inbyggd i den utvecklingsmiljö vi arbetade i; Unity 5 [22]. Den här nummergeneratorn har stöd för att använda ett så kallat seed, och alla nummergeneratorer med det här stödet fungerar för den här metoden. Ett seed är ett tal som används för att kontrollera den utdata som nummergeneratorn producerar. Vid samma seed så kommer nummergeneratorn alltid att producera samma talsekvens, och det här garanterar koherens vilket är essentiellt för vårt arbete.
3.1.2 Seed-generator
S e e d G e n e r a t o r ( w o r l d C o o r d )
g e n e r a t e d S e e d = ( w o r l d C o o r d . x * 111 + w o r l d C o o r d . y * 11 + w o r l d C o o r d . z ) * pi
r e t u r n g e n e r a t e d S e e d
Varje block som genereras behöver vara unikt och för att åstadkomma det så används en metod för att generera ett unikt tal för en tredimensionell position; blockets relativa position i spelvärlden. De tre dimensionsparametrarna multipliceras individuellt med tre respektive tal; 111, 11 och 1. De tre produkterna adderas med varandra och summan multipliceras med π. Den slutgiltiga produkten kommer sedan att användas som seed till nummergeneratorn som nu kommer att kunna producera samma unika talsekvens för ett block varje gång det behöver genereras.
3.1.3 L-System L S y s t e m ( ax iom ) s w i t c h ( axi om ) case a : r e t u r n a , a , g , o case b : r e t u r n o , b , g , b case c : r e t u r n o , g , c , c case d : r e t u r n d , g , d , o
L-system används för att generera symboler utifrån produktionsregler - så kallad gramma-tik - där en eller flera startsymboler, axiom, kan producera en sekvens med nya symboler. I det här arbetet används L-system för att generera grundstrukturen av en maze dung-eon. Vi använder L-system som en tvådimensionell grammatikexpansion där varje symbol kan expandera till fyra nya symboler som tar förälderns plats. Den här sortens gramma-tikexpansion har utforskats tidigare, fast med tredimensionell expansion, för att generera virtuella stenar [18].
Vi använder här 15 unika axiom, A-O, med sina egna produktionsregler där varje sym-bol i slutet av genereringen representerar varsin ”tile” i blocket. Varje symsym-bol innehåller information om vilka väggar dess tile ska få. Varje block innehåller fyra axiom där varje symbol kommer att expandera två generationer vilket kommer att resultera i 64 symboler per block i en 8x8-matris.
De flesta metoder för att generera maze-strukturer är antingen sök- eller agentbaserade. En fördel med att använda en mer grafisk generering, oberoende av sina närliggande delar, som grammatikexpansion är just att man kan sätta flera genererade block intill varandra som byggblock utan problem och extra arbete.
3.1.4 BFS B F S _ F i n d R o o m s ( list , s t a r t T i l e ) t i l e Q u e u e . E n q u e u e ( s t a r t T i l e ) s t a r t T i l e . v i s i t e d = true wh ile ( t i l e Q u e u e not em pt y ) t e m p T i l e = t i l e Q u e u e . D e q u e u e () for ( all n e i g h b o u r s )
if ( n e i g h b o u r not v i s i t e d && n e i g h b o u r not b l o c k e d ) n e i g h b o u r . v i s i t e d = true t i l e Q u e u e . E n q u e u e ( n e i g h b o u r ) Un ion ( tempTile , n e i g h b o u r ) B F S _ G e n e r a t e W a l l s A n d D o o r s ( list , s t a r t T i l e ) t i l e Q u e u e . E n q u e u e ( s t a r t T i l e ) s t a r t T i l e . v i s i t e d = true wh ile ( t i l e Q u e u e not em pt y ) t e m p T i l e = t i l e Q u e u e . D e q u e u e () for ( all n e i g h b o u r s ) if ( n e i g h b o u r not v i s i t e d && n e i g h b o u r is b l o c k e d ) if ( Find ( n e i g h b o u r ) == Find ( t e m p T i l e ) ) C r e a t e W a l l () else n e i g h b o u r . v i s i t e d = true t i l e Q u e u e . E n q u e u e ( n e i g h b o u r ) C r e a t e D o o r () Un ion ( tempTile , n e i g h b o u r ) n e i g h b o u r . b l o c k e d = f als e else n e i g h b o u r . v i s i t e d = true t i l e Q u e u e . E n q u e u e ( n e i g h b o u r ) if ( any u n b l o c k e d n e i g h b o u r s ) G e n e r a t e w al ls b e t w e e n u n b l o c k e d n e i g h b o u r s
Bredden-Först-Sökning är en välkänd sökalgoritm som traverserar graf- och trädbaserade datastrukturer. Algoritmen letar igenom datastrukturens noder efter grannar utifrån spe-cificerade sökregler och fortsätter leta till det inte finns fler obesökta noder tillgängliga. I vårt arbete används BFS vid två tillfällen. Första tillfället är när ett blocks struktur är färdiggenererad. Här går BFS igenom blocket med reglerna att den aldrig får titta på grannar på andra sidan av en vägg. Det här resulterar i att sökalgoritmen måste köras för varje rumstruktur i ett block och görs just för att ha möjlighet att identifiera dessa rumstrukturer. Vid andra tillfället går sökalgoritmen igenom hela blocket utan att stanna för väggar för att identifiera på vilka platser man kan sätta dörrar för att koppla samman hela blocket.
3.1.5 Union-Find Find ( X ) if ( X == X . p a r e n t ) r e t u r n X else r e t u r n Find ( X . p a r e n t ) Un ion (X , Y ) xR oot = Find ( X ) yR oot = Find ( Y ) xR oot . p a r e n t = yR oot
Union-find är en datastruktur som används för att organisera element i ett eller flera subset. För att göra det så har algoritmen två användbara operationer find och union.
• Find: Används för att leta upp i vilket subset ett visst element ligger i. • Union: Sätter ihop två subsets till ett subset.
I vår algoritm används Union-Find först för att identifiera rum i ett genererat block där ett subset representerar ett rum och ett element representerar en tile i sitt respektive rum. Det här sker under första BFS-omgången. När alla rum i ett block är identifierade och satta i egna subset körs en ny omgång av BFS. Under den här omgången kommer BFS leta igenom hela blocket för att koppla ihop alla rum genom att lägga dem i samma subset och sätta en dörr mellan rummen. Det här görs till alla rum tillhör samma subset och alla tiles är besökta. Det här garanterar att man som spelare kan komma åt varje tile i ett block. 3.1.6 Vertikala öppningar
C r e a t e V e r t i c a l O p e n i n g s ( axiom , list )
for ( int i = a xio m ; i <= axi om * 4; i += axi om ) C r e a t e hole on list [ i ] p o s i t i o n
Den sista delen av vår genereringsalgoritm bestämmer var ett block ska placera sina ver-tikala öppningar. Förflyttning vertikalt kan hanteras på olika sätt men metoden för att placera ut de här öppningarna till nästa våning behöver inte skilja sig. I det här arbetet så används en metod för att garantera att varje block har fyra öppningar till blocket över. Metoden bygger på att titta på blockets första axiom och beroende på vilken position i vår axiomlista det ligger så bestäms avståndet mellan öppningarna utifrån en start-tile i blocket. Den här metoden kan göras mer eller mindre avancerad, i vårt fall är lösning enkel men effektiv. Vår metod garanterar fyra vertikala öppningar per block där öppningarnas position bestäms utifrån blockets startaxiom. Den här lösningen använder endast en varia-bel för att hitta positionerna. En mer avancerad lösning hade kunnat använda sig av flera variabler för att skapa större variation hos de vertikala öppningarna.
4
Resultat
I det här kapitlet presenteras all data som använts och som har framkommit under utveck-lingen och testningen.
4.1 Produktionsregler
Produktionsreglerna som användes i testerna utformades utefter hur många axiom som fanns tillgängliga där reglerna endast fick producera resultat som innehöll de givna axio-men. Fyra grupper axiom och produktionsregler designades för testerna. Grupperna inne-höll 4, 8, 10 och 15 axiom och produktionsregler respektive. Produktionsreglerna vi valde visas i tabellen i det här avsnittet 1.
Produktionsregler Axiom 4 8 10 15 a a, a, d, b a, f, a, c a, f, a, c a, a, g, o b a, b, c, b b, b, d, g b, b, d, g o, b, g, b c d, b, c, c a, c, h, c a, c, h, c o, g, c, c d d, a, d, c e, b, d, d e, b, d, d d, g, d, o e - e, a, d, e e, i, d, d e, a, d, e f - a, f, f, b a, f, a, j a, f, f, b g - g, b, c, g b, b, i, g g, b, c, g h - d, h, h, c j, c, h, c d, h, h, c i - - i, f, d, i i, a, c, i j - - a, j, j, g j, b, d, j k - - - k. f. d. b l - - - a, l, c, g m - - - d, b, h, m n - - - e, a, n, c o - - - g, g, e, e
Tabell 1: Produktionsregler som användes under testet.
4.2 Variationstest
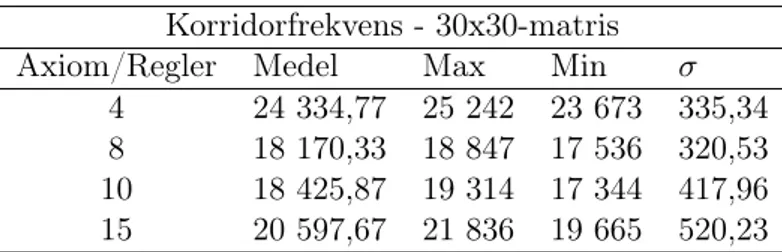
Datan som presenteras i det här avsnittet är framtagen vid testning av artefakten. Datan kommer att visas med hjälp av tabeller och heatmaps som kommer visa på skillnaderna mellan olika testgrupper. Datan i tabellerna visar korridorfrekvens och öppenhet i de fyra olika testgrupperna med medelvärde, maximum, minimum samt standardavvikelse. Datan för varje testgrupp baseras på 60 tile-områden där varje område innehåller 900 tiles. Det här innebär att varje testgrupp innehåller data från 56,000 unika tiles.
Korridorfrekvens - 30x30-matris Axiom/Regler Medel Max Min σ
4 24 334,77 25 242 23 673 335,34 8 18 170,33 18 847 17 536 320,53 10 18 425,87 19 314 17 344 417,96 15 20 597,67 21 836 19 665 520,23
Tabell 2: Sammanställd data från variationstest för korridorfrekvens. Öppenhet - 30x30-matris
Axiom/Regler Medel Max Min σ 4 25 824,25 26 204 25 502 145,05 8 24 659,27 25 047 24 254 207,90 10 23 059,35 23 479 22 484 233,83 15 24 461,72 25 046 23 877 281,30 Tabell 3: Sammanställd data från variationstest för öppenhet.
Alla heatmaps visas utifrån samma omfång på X-värde, Y-värde och Z-värde för att ge en så objektiv överblick av resultaten som möjligt. Datan består av punkter med två värden, ett för korridorfrekvens och ett för öppenhet. Varje heatmap består av lika många ”pixlar” där varje pixel representerar värden inom ett visst omfång för att kunna illustrera liknande datapunkter. Flera liknande datapunkter med värden inom samma omfång kom-mer att visualiseras med en färg som representerar mängden liknande datapunkter. Blå färg representerar lågt antal medan röd färg representerar högt antal. Heatmaps används här för att illustrera spridning i data för de olika testgrupperna. En samling med färgade pixlar som innehåller data kommer att refereras som datakluster (Exempel: det övre högra hörnet i Figur 7).
Figur 7: Heatmap med fyra axiom och produktionsregler
Figur 8: Heatmap med åtta axiom och produktionsregler
Figur 9: Heatmap med tio axiom och produktionsregler
Figur 10: Heatmap med femton axiom och produktionsregler
5
Analys
5.1 Analys av resultaten
Resultaten från testerna tyder på flera saker som stöder vår hypotes och all testdata kom-mer i det här avnitt analyseras i detalj.
5.1.1 Produktionsregler
Tabell 1 i avsnitt 4.1 visar produktionsreglerna som de fyra testgrupperna använde sig av i sina respektive grammatikexpansioner. För varje testgrupp försökte vi designa produk-tionsregler som kändes naturliga för de tillgängliga axiomen. I första testgruppen med fyra axiom och produktionsregler fanns stora designbegränsningar då endast fyra tillgängliga axiom sätter en gräns på valmöjligheter. Begränsningen här ger inte bara problem med design utan hela dungeongenereringen stöter på problem med hur varierad miljön kan bli. För andra och tredje testgruppen med åtta respektive tio axiom och produktionsregler är begränsningarna inte lika stora. Eftersom att vi försökte hitta de bästa produktionsregler-na för varje grupp och dessa två grupper innehöll nästan samma antal axiom kunde vi här designa produktionsreglerna lika varandra. Det enda som skiljer dem åt är att gruppen med tio axiom innehåller två extra produktionsregler utöver de åtta som även används i gruppen med åtta axiom. Dessa två grupper har inte riktigt samma begränsningar som första testgruppen och dungeongenereringen här lider inte lika mycket av variationspro-blem i miljön. Den sista testgruppen med 15 axiom och produktionsregler är designad individuellt från tidigare testgrupper då antalet axiom skiljer sig avsevärt från resten. Med fler valmöjligheter kring designen av produktionsregler ger det den här gruppen en egen stil som skiljer sig från resten och det leder också till att dungeongenereringen slipper lida ännu mer av variationsproblem i miljön.
5.1.2 Variationstest
Resultaten från variationstestet visar på flera punkter man kan titta närmre på och göra en analys av. I det här avsnittet kommer vi att presentera ett antal av de här.
1. Standardavvikelse: Om man tittar på standardavvikelsen, σ, i de båda tabellerna 2 och 3 i avsnitt 4.2 så kan man se en generell ökning av σ samtidigt som vi ökar antalet axiom och produktionsregler. För korridorfrekvens tyder det här på att det är färre återvändsgränder nära varandra samt att man kan resa längre sträckor åt gången utan att nödvändigtvis behöva göra en sväng. Standardavvikelsen på 4 respektive 8 axiom och produktionsregler är det enda exemplet på en minskning i värdet istället för en ökning. En iaktagelse här är att värdena är relativt lika om man jämför med de två andra gruppena. En förklaring på det här hade kunnat vara att det finns en begränsning av hur stor standardavvikelsen kan bli i just det testet och att vi ser spår av den här lägre gränsen.
En ökning av standardavvikelse när det kommer till öppenhet tyder på en mindre instängd miljö med större valmöjlighet när det kommer till vägval och större chans till visuell variation i sin direkta omgivning. Ökningen sker här för alla grupper och tyder därför på att det antingen inte finns någon lägre gräns av värdet eller att värdet är så lågt att vi inte kommer åt det från det här testet. Testerna, oberoende av kategori/typ, har inte gett oss någon indikation på en övre gräns när vi tittat på värdet för standardavvikelse.
2. Spridning av datapunkter i ett datakluster: Genom att titta på varje dataklus-ter isolerat och bortse från dess position i heatmappen så kan vi få information om de individuella testerna. De fyra dataklustren, från Figur 7, 8, 9 respektive 10, beter sig på liknande sätt med hur spridningen av data ser ut. Alla verkar gravitera mot ett område där heatmappen visar att det finns en större mängd liknande datapunkter, med allra flest kring några ”pixlar”. Det första man kan iakta när man tittar på de olika dataklustren är att ju färre axiom och produktionsregler som använts så verkar spridningen bli allt mindre medan fokuspunkten verkar innehålla allt fler ”pixlar” med delade datapunkter (rödare färg) vilket tyder på mindre variation i miljön. Ju fler axiom och produktionsregler som använts visar på fler använda ”pixlar” överlag samt få ”pixlar” med rödare nyans vilket också visar en större spridning av data vilket tyder på större variation i den testade miljön.
3. Positionering av datakluster: Om man bortser från spridningen av datapunkter inom datakluster och enbart tittar på deras positioner i heatmappen, så kan man se att figurerna 7, 8, 9 och 10 skiljer sig från varandra. Under analys av positione-ring letar vi fördelaktingen efter datakluster som befinner sig på en sådan plats att dess datapunkter inkluderar såväl lägre som högre värden av korridorfrekvens och öppenhet. Vi kan börja med att titta på hur dataklustret är positionerat i Figur 7 som illustrerar generering med fyra axiom och produktionsregler. Här ser vi att da-taklustret befinner sig i övre högra hörnet av heatmappen. Det här tyder på att de axiom och produktionsregler som använts i det testet ger dungeons med hög öppen-het samt många och långa korridorer. Antalet axiom och produktionsregler begränsar här möjligheten att generera en föredragen miljö. Komplexiteten är så låg att den struktur som uppkommer saknar beteendet som kan väntas utav en maze dungeon.
Nästa figur, Figur 8, illustrerar generering med åtta axiom och produktionsregler. Positioneringen av dataklustret i det här testet är på vänstra sidan i mitten. Även om vi här har ett datakluster med god positionering för öppenhet så är positionering-en för korridorfrekvpositionering-ens tillräckligt dålig för att tillsammans gpositionering-enerera positionering-en föredragpositionering-en miljö. Komplexiteten ökas från föregående test men är fortfarande på en nivå där de genererade strukturerna saknar det beteende som kan väntas utav en maze dungeon. Testet som illustreras i Figur 9 med tio axiom och produktionsregler är nära släkt med föregående test som har flera likadana axiom (se Tabell 1). Det här kan även ses i heatmappen då positioneringen av de båda dataklustren är snarlika. I Figur 9 är korridorfrekvensen dock lägre än det i Figur 8.
Den sista figuren, Figur 10, illustrerar generering med 15 axiom och produktions-regler. Dataklustret i den här heatmappen är det enda som både är positionerat i mitten av öppenhet och korridorfrekvens samtidigt vilket tyder på att det finns en balans mellan de olika värdena. Komplexiteten har nått en sådan höjd där den struktur som uppkommer har ett beteende som kan väntas utav en maze dungeon. 5.2 Analys av lösningen
Den lösning vi ger i denna uppsats för det problem vi stod inför är både kvantitativ och kvalitativ. Den använder välkända datastrukter på ett helt nytt sätt för att generera en viss sorts spelinnehåll som tidigare gjorts genom andra metoder. En metod byggd på tvådimensionell grammatikexpansion för att generera maze dungeons tar inspiration från ett par tidigare arbeten inom PCG-forskning [17, 18] och sätter samman idéer från dessa till en unikt fungerande metod med goda resultat.
5.2.1 Matematisk analys
Rent matematiskt så finns det begränsingar på kombinationer av axiom i ett block. För 15 axiom så blir det 154 eller 50 625 stycken kombinationer för ett block, för 10 blir det
104 eller 10 000, för 8 blir det 84 eller 4 096 och för 4 blir det 44 eller 256. Men sen har varje område en unik kombination med grannblock som ökar variationen ännu mer. För 15 axiom så blir det 50 62510eller ca 1.1 ∗ 1047kombinationer medan det för 4 axiom ”endast”
kommer att finnas 25610 eller 1.2 ∗ 1024.
6
Diskussion
Den samling metoder vi använt i det här arbetet verkar efter analysering av resultaten vara en god lösning av det framställda problemet. Vi lyckades med att generera en pseudo-oändlig dungeon och analys av våra resultat tyder på att vi hittade den komplexitet som krävdes utav ett L-system för att nå tillräckligt god variation. Vi ser själva potential i vår lösning och hoppas att fler kan använda sig av i alla fall någon del av vår lösning i sina egna projekt eller egen forskning. Lösningen har flera delar som kan ändras för att passa in i andra sorters projekt och möjligheten att göra sin egen implementation personlig är stor. Som färdig artefakt är den inte mycket mer än ett bevis för att lösningen fungerar väl i praktiken och egen implementation hade krävts för att optimera för sitt eget projekt.
6.1 Saker vi inte gjorde
En fråga man kan ställa är, varför gjorde vi inte användartester/studier? När vi satte oss ned och skulle bestämma vad för test vi skulle göra, så kom vi fram till ett antal olika sätt att testa vår artefakt. En av testidéerna var ett AB-test där vi skulle jämföra en handgjord bana med en bana som vår artefakt hade skapat, sedan låta testpersonerna testa och efteråt intervjuar vi dem. En annan idé vi hade var att låta spelaren röra sig i vår dungeon, där vi håller koll på hur de rör sig med hjälp av att rita ut en linje från där de börjar till deras nuvarande position. Vi hade ytterligare en idé där vi skulle bygga en AI som skulle röra sig i vår dungeon och samla data om omgivningen. Efteråt ställde vi frågorna, kan dessa tester ge det resultat vi letar efter? Kan de hjälpa oss med att svara på vår forskningsfråga? Det visade sig att de inte gjorde det. Vilket var anledningar till varför vi inte gjorde användartester. En annan anledning var tidsåtgången, då det hade tagit för lång tid för varje testperson att testa vår artefakt. Anledningen till det är för att artefakten skapar banor som är pseudo-oändliga, om testpersonen hade fått röra sig i vår dungeon så hade antingen det tagit för lång tid innan vi får ut det resultat vi önskar, eller så hade vi inte fått ut något alls. Det var även svårt att utveckla frågor som skulle hjälpa oss med att svara på vår forskningsfrågan. Frågeställningarna kändes ofta enformiga, vilket vi ville undvika. På grund av tidsbristen så bestämde vi oss för att inte göra ett test med hjälp av en AI.
7
Slutsatser och vidare forskning
Vi ser på det här arbetet som ett lyckat sådant. Vi gick in i projektet med funderingar över hur man kunde lösa problemet med pseudo-oändliga dungeons och lösningen vi tog fram var både lyckad och nytänkande. Några delar av vårt arbete ger kvantitativ information kring hur man kan använda vissa metoder inom PCG-området, medan andra delar ger kvalitativ information kring hur man procedurellt kan generera maze dungeons. Vi fick svar på hur avancerat L-system som krävdes för att nå den nivå av variation som vi kände var tillräcklig med stöd från testdata. Vi tror att de utforskade metoderna och de sätt vi implementerat dem på kan vara användbara för andra som letar efter lösningar för såväl pseudo-oändlighet som dungeongenerering.
Vi tror att det finns utrymme för vidare forskning i flera delar av arbetet. Pseudo-oändlighet kan lösas på flera sätt och beroende på hur levande och föränderlig ens miljö ska vara kan det vara nödvändigt att forska vidare kring hur man mest effektivt löser det här. Vår lösning av pseudo-oändlighet, som även tidigare använts, kan ha begränsningar i mer avancerade system samtidigt som det fungerar väl för vårt ändamål. Det hade även varit intressant att se hur andra kan använda den grammatikexpansionsteknik vi utvecklade. Det finns flera saker i den som hade kunnat utforskas, bland annat vilka axiom som används, vilka produktionsregler som används och så vidare. Vårt arbete undersökte inte vidare vad som hade hänt om man hade fortsatt lägga till axiom med tillhörande produktionsregler men det hade varit intressant att se vilka resultat det här hade gett.
Referenser
[1] Dataspelbranchen, “Digital spelförsäljning i Sverige 2013-2015,” 2016. [Online]. Avai-lable: http://www.dataspelsbranschen.se/media/153159/digital%20spelf%C3%B6rs% C3%A4ljning%202015.pdf
[2] M. Persson, “Minecraft,” [Digital Game], 2011.
[3] S. Dahlskog, J. Togelius, and S. Björk, “Patterns, dungeons and generators,” in Pro-ceedings of the 10th Conference on the Foundations of Digital Games, 2015.
[4] Gearbox Software, “Borderlands,” [Digital Game], 2009.
[5] W. D. Pullen, “Maze classification,” June 2015. [Online]. Available: http: //www.astrolog.org/labyrnth/algrithm.htm
[6] E. McMillen. and F. Himsl., “The Binding of Isaac,” [Digital Game], 2011.
[7] P. Lebling, M. Blank, and T. Anderson, “Special Feature Zork: A Computerized Fan-tasy Simulation Game,” Computer, vol. 12, no. 4, pp. 51–59, April 1979.
[8] Nintendo R&D4, “The Legend of Zelda,” [Digital Game], 1986.
[9] M. Toy, G. Wichman, K. Arnold, and J. Lane, “Rogue,” [Digital Game], 1980. [10] R. Garriott, “Ultima II: The Revenge of the Enchantress,” [Digital Game], 1982. [11] R. Garriott, “Ultima,” [Digital Game], 1981.
[12] D. Lawrence, “Telengard,” [Digital Game], 1982.
[13] Blizzard North, “Diablo,” [Digital Game], December 1996.
[14] S. Greuter, J. Parker, N. Stewart, and G. Leach, “Real-time Procedural Generation of ‘Pseudo Infinite’ Cities,” in Proceedings of the 1st International Conference on Computer Graphics and Interactive Techniques in Australasia and South East Asia, ser. GRAPHITE ’03. ACM, 2003, pp. 87–ff.
[15] L. Johnson, G. N. Yannakakis, and J. Togelius, “Cellular Automata for Real-time Generation of Infinite Cave Levels,” in Proceedings of the 2010 Workshop on Procedural Content Generation in Games, ser. PCGames ’10. ACM, 2010, pp. 10:1–10:4. [16] A. Lindenmayer, “Mathematical models for cellular interactions in development I.
filaments with one-sided inputs,” Journal of Theoretical Biology, vol. 18, no. 3, pp. 280–299, 1968.
[17] J. Dormans, “Adventures in level design: generating missions and spaces for action adventure games,” in Proceedings of the 2010 Workshop on Procedural Content Gene-ration in Games, ser. PCGames ’10. ACM, 2010, pp. 1–8.
[18] I. M. Dart, G. De Rossi, and J. Togelius, “SpeedRock: Procedural Rocks Through Grammars and Evolution,” in Proceedings of the 2Nd International Workshop on Pro-cedural Content Generation in Games, ser. PCGames ’11. ACM, 2011, pp. 8:1–8:4.
[19] K. Peffers, T. Tuunanen, M. A. Rothenberger, and S. Chatterjee, “A Design Science Research Methodology for Information Systems Research,” Journal of Management Information Systems, vol. 24, no. 3, pp. 45–77, December 2007. [Online]. Available: http://www.tandfonline.com/doi/full/10.2753/MIS0742-1222240302
[20] A. R. Hevner, S. T. March, J. Park, and S. Ram, “Design science in information systems research,” Design Science in IS Research MIS Quarterly, vol. 28, no. 1, pp. 75–105, 2004.
[21] C. Wohlin, “Guidelines for snowballing in systematic literature studies and a replica-tion in software engineering,” in Proceedings of the 18th Internareplica-tional Conference on Evaluation and Assessment in Software Engineering - EASE ’14. New York, New York, USA: ACM Press, 2014, pp. 1–10.
[22] Unity Technologies, “Unity 5,” [Software], 2015. [Online]. Available: https: //unity3d.com/
Appendix A: Söktermer
Akronymer som används i tabellen: Institute of Electrical and Electronics Engineers (IEEE) Xplore, Association for Computing Machinery Digital Library (ACM DL), Digital Games Research Association (DIGRA).
Databaser Begränsningar Söktermer Träffar
IEEE Xplore Procedural content generation 106
IEEE Xplore Pseudo infinite 90
IEEE Xplore Dungeon 21
IEEE Xplore L-system 160
ACM DL Journal (+procedural +content +generation) 30 ACM DL Proceeding (+procedural +content +generation) 319
ACM DL Journal (+pseudo +infinite +dungeon) 114
ACM DL Proceedings (+pseudo + infinite +procedural +generation) 37
ACM DL Proceedings (+pcg +expressive +range) 1
ACM DL Proceedings (+procedural +content +generation +grammar) 9
ACM DL Proceedings (+l-system +dungeon) 19
DIGRA Procedural content generation 2
DIGRA Dungeon 2
Tabell 4: Söktermer som användes under litteraturstudien
Appendix B: Ordlista
• Axiom: En startsymbol i ett L-system.
• Dungeon: En spelmiljö som ibland liknas vid fängelsehålor men kan representeras på flera olika sätt som beskrivs i avsnitt 1.1.1.
• Heatmap: En grafisk representation av data som visar tendenser med hjälp av färger i en matris.
• Produktionsregler: Regler som beskriver hur en symbol i ett L-system ska expan-dera.
• Tile: En representation av en punkt som befinner sig i en tvådimensionell matris. En tile är i vårt arbete samma sak som ett axiom eller en symbol med vägginformation.
Appendix C: Axiom
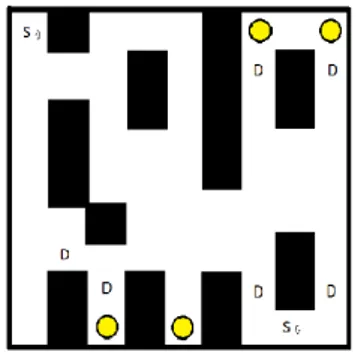
En bild på de axiom som användes under projektet, där det svartmakerade är väggar och det vitmakerade är tomrum.
Figur 11: Axiom som användes under projektet