Examensarbete
15 högskolepoäng, grundnivå
Parametrar med stor påverkan på
FRS matchning.
Parameters having significant impact
on FRS matching.
Daniel Lenander
Examen: Kandidatexamen 180 hp
Huvudområde: Datavetenskap
Handledare: Bengt J. Nilsson
Andrabedömare: Rolf Axelsson
Sammanfattning
Facial Recognition Systems är något som har blivit populärt de senaste åren, speciellt efter den 11 september 2001. Möjligheten att kunna över-vaka personer som rör sig i olika miljöer har varit av intresse för bland annat regeringar, till exempel USA:s regering. Eftersom det finns mängder med olika typer av undersökningar och alla försöker göra så bra matchningar som möjligt av personer mot databaser, fast de utförs på olika sätt, är det intressant att se om det finns någon parameter som har en större påverkan på resultaten, oavsett om undersökningen görs med 2D, 3D eller en kombination av metoderna. Det finns många olika faktorer och parametrar som påverkar matchningsprocenten därför skall denna littera-turstudie försöka lokalisera och se om det finns någon parameter som har en större påverkan på matchningsprocenten. Det visar sig att två parametrar har en större påverkan än övriga parametrar. De är antalet bilder av varje objekt som finns att matcha i databasen och kvaliteten på indata vilket innebär kontrast och upplösning samt hur kompletta ansiktena är.
Summary
Facial Recognition Systems is something that has become popular in recent years, especially after 11 September 2001. The ability to monitor people that are moving in different environments has been of interest to particular governments, for instance the US government. Since there are a lot of different types of surveys, though performed in different ways, all trying to do the best matches of people to databases as possible, it is interesting to see if there is any parameter that has a major impact on the result. Whether the survey is done with 2D, 3D or a combination of methods, there are many different factors and parameters that affect the matching percentage. Therefore this study tries to locate and see if there is any parameter that has a greater impact on the matching percentage. It appears that two of the parameters have a greater effect on the result, than the others. These are the number of images of a test subject in the database and the quality of the input data. The quality is defined by contrast and resolution as well as how complete the faces are.
Innehållsförteckning
1 Inledning... 6 1.1 Bakgrund ... 6 1.2 Syfte ... 7 1.3 Frågeställning ... 8 1.4 Avgränsningar ... 8 2 Metod ... 82.1 Generell beskrivning av algoritmer och metoder ... 10
2.2 Vanliga databaser för FRS-tester... 12
2.3 Artiklarnas metodbeskrivning ... 13
2.3.1 Three-dimensional facial surface modelling applied to recog-nition. ... 13
2.3.2 2D and 3D face recognition: A survey ... 14
2.3.3 Color Face Recognition for Degraded Face Images ... 14
2.3.4 iBotGuard: An Internet-Based Intelligent Robot Security System Using Invariant Face Recognition Against Intruder ... 15
2.3.5 Synergistic Face Detection and Pose Estimation with Energy-based Models ... 15
2.3.6 Fovea intensity comparison code for person identification and verification ... 16
2.3.7 Report on the Evaluation of 2D Still-Image Face Recognition Algorithms ... 16
2.3.8 Facial Recognition in Uncontrolled Conditions for Information Security ... 17
2.3.9 Face recognition with disguise and single gallery images ... 17
2.3.10 Face Recognition from Still Images to Video Sequences: A Local-Feature-Based Framework ... 18
2.3.11 Using backpropagation neural network for face recognition with 2D + 3D hybrid information ... 19
2.3.12 Face Recognition: A Literature Survey ... 19
3 Resultat ... 20
3.1 Artiklarnas resultat ... 20
3.1.1 Three-dimensional facial surface modelling applied to recog-nition. ... 20
3.1.2 2D and 3D face recognition: A survey ... 20
3.1.3 Color Face Recognition for Degraded Face Images ... 21
3.1.4 iBotGuard: An Internet-Based Intelligent Robot Security System Using Invariant Face Recognition Against Intruder ... 22
3.1.5 Synergistic Face Detection and Pose Estimation with Energy-based Models ... 23
3.1.6 Fovea intensity comparison code for person identification and verification ... 23
3.1.7 Report on the Evaluation of 2D Still-Image Face Recognition Algorithms ... 24
3.1.8 Facial Recognition in Uncontrolled Conditions for Information Security ... 25
3.1.9 Face recognition with disguise and single gallery images ... 25
3.1.10 Face Recognition from Still Images to Video Sequences: A Local-Feature-Based Framework ... 27
3.1.11 Using backpropagation neural network for face recognition with 2D + 3D hybrid information ... 28
3.1.12 Face Recognition: A Literature Survey ... 29
4 Analys ... 29
5 Diskussion ... 32
5.1 Bildkvalitet ... 33
5.2 Antal bilder i databasen ... 34
5.3 Generell diskussion ... 34
6 Slutsatser och vidare forskning ... 37
7 Referenser ... 40
7.1 Artiklar ... 40
7.2 Referenser härledande tabellinformation... 41
1 Inledning
Ansiktsigenkänningssystem (kallas även för ”Facial Recognition System” eller FRS) blev ett populärt system efter terrorattackerna 11 september 2001 i USA. Det ansågs vara och framställdes nästan som ett ultimat säkerhetssystem och dess förträfflighet spreds i medier. Ett av syftena med systemet är att känna igen terrorister och brottslingar redan när de anländer till ett land samt när de rör sig ute på allmänna platser. Men, hur bra är då ansiktsigenkänningssystemet? Fungerar systemet som det är tänkt eller är systemet som ett nyfött barn med mängder av barnsjukdomar som hindrar det att fungera tillräckligt effektivt och går det att lära systemet att utföra sin uppgift utan att påverka indata i allt för hög grad? Systemet har olika problem som det tampas med. Problemen uppstår när olika faktorer påverkar en ansiktsavläsning, till exempel ljusförhållande, maskering, upplösning, vinklar, grå- eller färgskala, åldersdifferens mellan indata och matchningsdata i databas med mera. Undersökningar visar att systemet fungerar bra när det går att styra vissa faktorer i kontrollerad miljö, vilket kan vara svårt i en öppen och okontrollerad miljö. Det finns många olika frågor angående FRS. Dock kommer denna litteraturstudie att inrikta sig på om det är möjligt att använda sig av systemet inom ett företag i dess lokaler på ett adekvat sätt.
1.1 Bakgrund
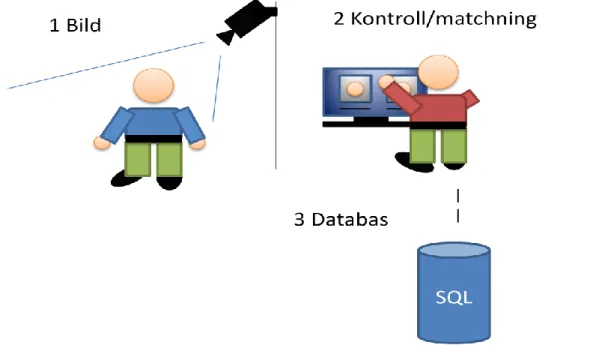
Det finns många påtänkta användningsområden för FRS, framförallt inom säkerhets- och reklambranschen. Det finns även tankar på och idéer om att använda systemet som hjälpmedel för blinda och synskadade samt till robotar [2]. Inom säkerhetsbranschen finns det en önskan om att kunna ha ett fungerande system för kontroll av personer som inte är lika integri-tetskränkande som ögonskanning och fingeravtryck. Forskarna använder sig av olika biometriska algoritmer för att läsa av specifika ansiktsdrag från indata som presenteras i form av till exempel en bild tagen av en övervak-ningskamera (figur 1). Algoritmerna gör uträkningar baserat på vilka punkter de är satta att ta ut. Till exempel kan punkterna från ett ansikte vara iris, näsa, mun, kindben, läpp mm. Avståndet mellan punkterna räknas ut och jämförs med bilder i databasen för att få en matchning. Algoritmer har för- och nackdelar och fungerar olika beroende på om indata är i form av 2D eller 3D [10]. Det framgår även att det finns ett visst samband mellan antalet korrekta matchningar och antalet bilder som applikationen kan matcha per individ. En kombination av de två olika indatametoderna, 2D och 3D, ger ett fördelaktigare resultat jämfört med att använda dessa enskilt. Problemet med metoderna är inte algoritmerna,
indata inte är helt korrekt och leder till att matchningarna som görs mot databasen inte blir helt rättvisa. Detta resulterar i att många olika personer kan identifieras som träffar i systemet. Detta är anledningen till varför det behövs en person som kontrollerar resultatet av en undersökning och som kan bistå systemet med att välja ut rätt matchning alternativt meddela systemet när fel uppstår.
Några av anledningarna till att indata som sänds till systemet blir fel beror på yttre faktorer som till exempel ljusförhållande och vinklar. Det kan även bero på att personer har attiraljer som hindrar systemet från att kunna göra rätt avläsningar.
Figur 1: FRS fungerar enkelt förklarat så att den tar en bild av ett ansikte (1). Data av ansiktet sänds till applikationen (2) som med hjälp av algoritmer jämför indata med data i databasen (3). Vid eventuella matchningar som uppfyller de kriterier som har ställts in visas dessa i systemet och en operatör (2) gör en sista kontroll av matchningarna.
1.2 Syfte
Syftet med litteraturstudien är att undersöka problematiken med FRS i sin nuvarande form. Detta görs på grund av att FRS på den senaste tiden har blivit väldigt populärt och kan vara väldigt användbart om det fungerar som det är tänkt. Litteraturstudien skall därför ge svar på vilka utmärkande parametrar som skapar störst problematik för ansikts-igenkänning. En intressant aspekt är om de tilläggsapplikationer som används för att modifiera indata är tillräckligt utvecklade för att till exempel kvaliteten på indata inte ska ha en markant påverkan av matchningar och därför fortfarande kan vara en avgörande parameter.
1.3 Frågeställning
Frågeställningen som skall besvaras genom litteraturstudien är om det finns några parametrar som har en betydande påverkan vid matchning av data inom FRS oavsett undersökningsteknik. Frågeställningen är riktad till ansiktsigenkänningssystem inom semikontrollerade områden, till exempel inom företag och myndigheter.
1.4 Avgränsningar
På grund av att systemet kan användas inom många olika branscher och på olika sätt har litteraturstudiens fokus lagts på FRS inom säkerhets-branschen. Parametrarnas betydelse kan variera beroende på vilken bransch det gäller. I reklambranschen har kvaliteten på indata inte samma betydelse för att känna igen i fall ett ansikte tillhör en man eller kvinna gentemot att matcha ansiktet exakt mot en efterlystperson. Därför kan systemet användas i till exempel en vänthall för att avgöra om personerna är övervägande män eller kvinnor. Detta kan användas för att rikta reklam mot respektive målgrupp. Mängden av algoritmer och variationer för införskaffandet av indata skiljer sig mellan testerna i de studier som ligger till grund för litteraturstudien. Detta innebär att det som har en gemensam påverkan och betydelse för samtliga tester är de olika parametrarna som finns.
2 Metod
För att besvara frågeställningen och för att se om det går att använda FRS i sin nuvarande form och med nuvarande tekniska utveckling som ett pålitligt och adekvat säkerhetssystem, kommer olika vetenskapliga artiklar och statliga beställda undersökningar att läsas och sammanställas i form av en kvantitativ litteraturstudie. Författaren har valt att besvara frågeställningen med hjälp av en litteraturstudie för att få ett bättre och bredare underlag med större mångfald än vad som skulle vara möjligt med ett enskilt eget experiment. Att göra en heltäckande egen empirisk studie för att besvara frågeställningen skulle heller inte vara möjligt inom tidsramen för ett examensarbete på kandidatnivå. De olika artiklarna kommer att sammanfattas och en sammanfattning kommer presenteras för läsaren. Relevant resultatinformation från artiklarna kommer även presenteras i tabellform för att underlätta för läsaren. Detta görs för att läsaren skall kunna ta till sig informationen på ett lätt sätt utan att behöva sätta sig in i alla termer och algoritmer samt kunna få en komplett överblick. Studien riktar sig till personer inom datavetenskap och personer som har ett allmänt intresse av FRS.
ana-av FRS där olika algoritmer, åtgärder och uppsamling ana-av data skiljer sig i viss mån. Detta har inte gjorts enbart för att få olika infallsvinklar utan även för att det inte finns en specifik standard för hur testerna utförs. Syftet av att få med olika infallsvinklar är att lokalisera olika parametrar som verkar ha en större betydelse och påverkan på resultaten oavsett hur undersökningen eller litteraturstudien har gjorts. I studien ingår även en utvärdering av FRS med 2D-bilder som har gjorts av NIST (National Institute of Standards and Technology). NIST är en del av USA:s handelsdepartement som hanterar och skyddar standarder som används inom områden som fysik, kemi, data, matematik med mera. Denna studie används som en neutral kontrollmall för att se om det finns några specifika parametrar som sticker ut. Till skillnad från de vetenskapliga artiklarna finns det i NIST-studien sju etablerade företag inom branschen och tre universitet som alla har samma uppgift att lösa och som alla har tillgång till samma bildgalleri fast använder sig av olika algoritmer.
Tabell 1: Sökvägar av vetenskapliga artiklar i databasen, nyckelord för sökning, position och artikel namn. Datum för sökning: 2013 februari-mars.
Inställningar Nyckelord Plats Namn
ACM Digital Library
Journal/Transactions 3D face modeling 8
Three-dimensional facial surface modeling applied to recognition
Science Direct
Computer science 2d recognition 3d face 1 2D and 3D face recognition: A survey ACM Digital Library
Journal/Transactions 3d search databases 1
Feature-based similarity search in 3D object databases
IEEE/Xplore
Journal Face color recognition 2 Color Face Recognition for Degraded Face Images IEEE/Xplore
Journal Facial recognition security 3
iBotGuard: An Internet-Based Intelligent Robot Security System Using Invariant Face Recognition Against Intruder
ACM Digital Library
Journal/Transactions Face pose detection 2
Syneric Face Detection and Pose Estimation with Energy-Based Models ScienceDirect Journal, ComputerScience, Article Identification facial comparison 7 Fovea intensity comparison code for person identification and verification
NIST
Projects/Programs Facial recognition 2d 1
Report on the Evaluation of 2D Still-Image Face Recognition Algorithms ACM Digital Library
Journal/2010-2013 Facial recognition uncontrolled condition 1 Facial Recognition in Uncontrolled Conditions for Information Security Science Direct
Journal/ 2005-present Face disguise recognition 1
Face recognition with disguise and single gallery images
ACM Digital Library
Journal/Transactions Face image video recognition 1
Face Recognition from Still Images to Video
Sequences: A Local-Feature-Based Framework
Science Direct Journal/Computer science Face recognition 2d 3d 5 Using backpropagation neural network for face recognition with 2D + 3D hybrid information ACM Digital Library
Journal/Transaction
Downloads(Overall) Face recognition 2
Face Recognition: A Literature Survey
2.1 Generell beskrivning av algoritmer och metoder
I artiklarna som ligger till grund för litteraturstudien förekommer det ett antal namn och förkortningar av algoritmer och metoder. Dessa algoritmer och metoder förklaras på ett lättförståligt sätt nedanför.
PCA, principalkomponentsanalys
PCA används för att vid en analys minimera antalet dimensioner i data. Genom att välja ut komponenter som representerar de största varianserna och samtidigt ta bort de mindre varianserna minskar antalet dimensioner och data blir mer lätthanterlig att analysera. De största varianserna anses innehålla tillräckligt med data medan de mindre varianserna anses reflektera ”brus”. Det blir lättare att finna olika samband när endast de större komponenterna används och de mindre komponenterna tas bort.
Bayesian
Metoden är en linjär regression som undersöker om det finns en statisk samhörighet mellan olika värden. Metoden kan använda sig av nya och gamla värden för att räkna ut var ett värde borde vara. Metoden kan användas för att ta fram värden som är dolda. Om till exempel iris valts till referenspunkt men döljs av ett par solglasögon kan man med metoden Bayesian beräkna var referenspunkten borde vara.
BP, Backpropagation
En metod som lär sig känna igen skillnader på bland annat ett ansikte från andra ansikten. Detta görs genom att de värden som tillförs testas iterativt mot de som finns lagrade tills rätt match-ningar hittas.
FLDA, Fisher´s linear discriminant
FLDA går ut på att hitta variationer och avvikelser i de linjära kombinationerna precis som i PCA. Dock försöker FLDA hantera varianserna i data genom olika klassifikationer vilket inte görs i PCA.
GF, Geometric Feature
Genom en kombination av datorseende och maskininlärning samlas geometriska drag in från bilder. Dragen kan vara kurvor, linjer, punkter eller ytor som sedan används för igenkänning.
LFA, Local Feature analysis
Metoden skapar en topografi som gör det möjligt att ta ut värden av framhävda drag ur ett ansikte såsom näsa, kindben, ögon med mera.
IGF, Independent Gabor Feature
IGF använder sig av Gaborfiltret som är ett linjärt filter för att kunna identifiera kanter i 2D. Filtret är användbart för att extrahera till exempel specifika drag i ett ansikte från en bild.
LAC, Local Autocorrelation Coefficient
Metoden letar efter mönster/signaler som upprepar sig eller likheter mellan mönster/signaler
LBP, Local Binary Patterns
LBP delar in bilden i celler som är 16x16 pixlar stora. Pixlarna jämförs sedan var för sig mot de 8 angränsande pixlarna i form av en cirkel runt ursprungspixeln. Om centerpixelns värde är högre än en angränsande pixel markeras detta. Pixlarna får då ett binärt nummer som kan användas för att få fram ansiktsdrag ur en bild.
MD, Minimum Distance
Metoden räknar ut det minsta avståndet mellan de punkter som anges. Dessa värden kan i sin tur matchas mot andra värden för att finna rätt matchning.
MRH, Multi Region Historygram
Varje ansikte är indelat i ett antal regioner. Regionerna är i sin tur indelade i mindre bitar på en storlek av 8 x 8 pixlar som överlappar varandra. För att få nytta av värdena kan man använda ett DCT (Discrete cosine transform) som hanterar bildkodningen av värdena i tvådimensionella bilder.
MMD, Mainfold-Mainfold Distance
Delar upp bilden i tre dimensioner subspace, point och mainfold. Avståndet mellan de tre nivåerna används för att skapa en multinivå. Sedan matchas modellen mot bilderna från ett bildgalleri.
MSM, Mutual Subspace Method
Metoden jämför vinkeln mellan två linjära subspaces och använder det som mått. Metoden kan användas med linjära algoritmer.
Feature Averaging, Avg-Feature
Metoden går ut på att jämföra en bild med varje stillbild i ett videoflöde. Detta är en tids- och datorresurskrävande metod. Till exempel görs ca 90000 uträkningar för en bild när en video är 10 sekunder lång med en normal bilduppdatering på 30 rutor per sekund.
Affine Hull Method, AHM
Den här metoden gör bilden till punkter i en linjär funktion och varje bildset namnges som ”Affine hull”, vilket är en konvex geometrisk region som görs av de specifika punkterna.
SVM, Support Vector Machin
SVM är en linjär algoritmmetod som används inom dataseende, språkteknologi och optisk teckenigenkänning
2.2 Vanliga databaser för FRS-tester
I artiklarna omnämns ett antal databaser som används för tester. Nedanför finns en sammanställning i tabellform av de vanligaste allmänna FRS-databaserna som används vid testning.
Tabell 2: Allmän information om några av de vanligaste databaserna[16]
Databas RGB/Grå Bild storlek Antal testpersoner Bilder per
person Tillgång FERET RGB/Grå 256x384 1199 Ca 12 Ja SCface RGB/Grå X 130 Ca 32 Ja Multie-PIE CMU RGB X 337 Ca 2225 Ja Yale Face Database Grå X 15 11 Ja PIE Database, CMU RGB X 68 Ca 608 Nej M2VTS RGB 286x350 37 5 Ja GavabDB RGB X 61 9 Ja
FRAV2D RGB 320x240 109 32 Ja
LFW RGB X 5749 1 till 2 Ja
AR RGB 768x576 126 Ca 31 Ja
MIT-CBC FR RGB X 10 324 Ja
2.3 Artiklarnas metodbeskrivning
2.3.1 Three-dimensional facial surface modelling applied to recog-nition.
Författarna [1] valde att göra två olika tester med 3D ansiktsigenkänning. Det ena testet gjordes med en stödvektormaskin (SVM) och det andra med principalkomponentanalys (PCA). PCA identifiera en linjär avbildning av data där det finns störst variation. Dessa variationer används sedan för att plocka ut de betydande värdena som används för testerna. Testerna gjordes även i två olika miljöer, okontrollerad och kontrollerad miljö. Databasen som författarna använde sig av var GavabDB. GavabDB är enligt författarna den databas som erbjuder bäst variation av 3D ansikten för att kunna göra undersökningen.
Databasen innehöll bland annat variationer av ansiktsuttryck vilket gjorde den lämplig att använda. 427 stycken 3D ansiktsnät av 549 valdes ut från ett underlag av 61 testpersoner med 7 olika ansiktsnät vardera i databasen. Bilderna av en testperson bestod av två bilder tagna framifrån och med ett neutralt uttryck, en bild där personen tittar upp och en där personen tittar ner, båda med neutralt uttryck och var vinklade i ± 35°. De övriga tre bilderna var även tagna framifrån fast med olika uttryck. 12 stycken bilder av testpersonerna hade någon form av blockering i form av skägg, hår som hänger ner, mustasch mm. De punkter som doldes av blockeringar i ansiktsnätet fylldes i av 3D programmet och eventuellt små fel kunde uppstå i ansiktsnätet. Alla bilderna sparades i två olika kate-gorier, upplösning 1-1 där lika många punkter används som i originalbilden och 1-4 där ¼ av punkterna från originalbilden används. Detta gjordes för att se om upplösningen hade någon påverkan på matchningen.
Tre olika voxelstorlekar valdes ut i skapandet av ansiktsnätet, 30x30x30, 45x45x45 och 55x55x55. Detta gjordes för att se om voxelstorleken hade någon påverkan på matchningsresultatet. Upplägget var att undersök-ningen gjordes i fyra steg. I steg ett togs saker som inte hade någon betydelse för 3D matchningen bort som till exempel nacke, öron och hår. I steg två ställdes ramarna för hur ansiktena skulle visas och matchas in. Detta gjordes för att alla ansiktena skulle få samma lutning, vinkel etc. När
steg två var gjort fördes ansiktsnät in i voxeln och i steg fyra utfördes matchningen. Matchningen gjordes genom att jämföra vertikala och hori-sontella genomskärningar av ansiktet för att få ut de biometriska match-ningspunkterna för näsa och ögon.
2.3.2 2D and 3D face recognition: A survey
Författarna [2] av litteraturstudien jämförde olika tester av FRS och dess tillvägagångssätt. Data från de olika testerna sattes in i förbestämda parametrar för att undersöka om de kunde leda till en framtida utveckling och förfining av FRS. De parametrar som användes var bland annat igenkänningsprocent, antal problem, bildstorlek, färg- eller gråskala, ansiktsuttryck, ålder, poser, tidsdifferens mellan ny och gammal bild, samt om delar av ansiktet var skymt. Metoden gick ut på att jämföra data från både 2D och 3D samt hybrid av 2D + 3D tester. Informationen som framkom sattes sedan in i tabeller för att underlätta utvärderingen av de olika utvecklingsmetoderna.
2.3.3 Color Face Recognition for Degraded Face Images
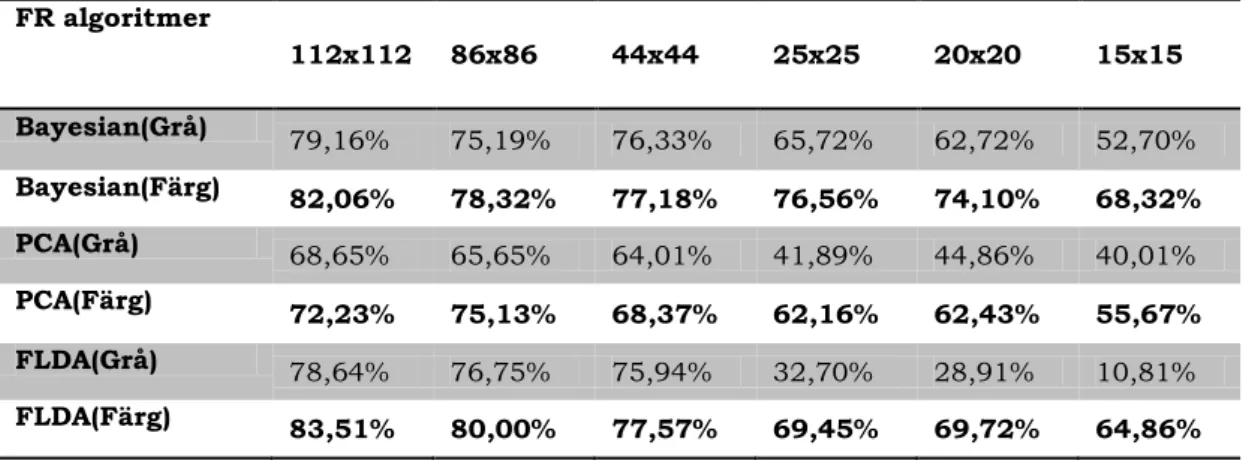
I artikeln belyste författarna [3] problemet med lågupplösta bilder. Med en ny metod som författarna kallade VRG ville de påvisa att det går att förbättra resultatet av ansiktsmatchningar om bilderna är i färgskala istället för i gråskala. Matchningsprocenten är baserade på de biometriska punkter som används för algoritmen. VRG är den skillnad som uppstår mellan färg- och gråskalamatchningen. I undersökningen använde de sig av ca 3000 färgbilder från tre olika databaser. Den ena databasen som användes var CMU PIE som innehåller färgbilder av ansikten i olika poser. Den andra databasen var Color FERET som innehåller bilder i färg- och gråskala samt att bilderna på personer kan vara tagna med upp till två års mellanrum. Den tredje databasen var XM2VTSDB som innehåller digitala videoinspelningar av roterande och pratande ansikten i högupplösning (Se även tabell 2). Från CMU PIE valdes 1428 bilder tillhörande 68 personer ut. 700 bilder tillhörande 140 personer valdes ut från Color FERET databasen. De sista 1064 bilderna tillhörande 133 personer togs från XM2VTSDB databasen. Samtliga bilder var tagna framifrån. Bilderna härstammade från 341 testpersoner och testerna gjordes i algoritmerna PCA, FLDA och Bayesian.
Bilderna gjordes sedan om till sex olika upplösningar för att matcha över-vakningskamerors bildkvalité, 112x112, 86x86, 44x44, 25x25, 20x20 och 15x15. De roterades även och skalades för att bilderna skulle få samma förutsättning när matchningarna gjordes. Bilderna gjordes även i gråskala och de biometriska punkterna hämtades även ut ur dessa för att kunna göra jämförelserna i matchningarna.
2.3.4 iBotGuard: An Internet-Based Intelligent Robot Security System Using Invariant Face Recognition Against Intruder
Författarna [4] ville med undersökningen ta reda på om det gick att använda sig av en mobil robot för att läsa av personers ansikten med hjälp av en kamera. Detta skulle bland annat underlätta arbetet för säkerhetspersonal. Roboten skulle kunna skötas av en person via en trådlös internetuppkoppling. Internetuppkopplingen i experimentet gjordes via ett 33,6 kb/s modem. Datorsystemet var gjort i två delar där den ena delen hade hand om spårningen av ansikten och den andra delen stod för själva ansiktsigenkänningen. Ansiktsigenkänningsprogrammet skannade av en yta efter ansikten medan spårningsfunktionen gav utslag vid en matchning av ett inskannat ansikte. Vid en positiv matchning gick ett larm till säkerhetspersonal som kunde ta över kontrollen av roboten manuellt och följa efter personen. Ansiktsigenkänningsprogrammet använde sig av CPA (Chroma Processing Agent) för att ta ut ansikten från indata. CPA används för att se om det finns ett ansikte på en bild/indata med hjälp av färgskillnader. Efter att ett ansikte hade verifierats användes matematiska uträkningar för att rensa ansikten från små fel som kunde störa indata. När felen var åtgärdade togs värden ut med hjälp av algoritmer. Värdena baserades på avstånden mellan ögonen, mätt från iris, samt munnens längd.
För att testa systemet användes 2000 bilder med olika förhållanden från 200 testpersoner. Fem biometriska värden togs ut från bilderna för att med hjälp av Gaussfilter användas i jämförelser. De biometriska värdena var kind, näsa, mun samt höger och vänster öga. 100 tester gjordes på bilder med olika vinklar och de övriga 100 gjordes på bilder där ansiktena hade dolts i olika stor utsträckning. Eftersom det uppstod problem när kameran var fixerad på roboten visades bilderna istället framför kameran och avlästes.
2.3.5 Synergistic Face Detection and Pose Estimation with Energy-based Models
I artikeln beskrev författarna [5] hur de med hjälp av neuronnät kunde kartlägga ansikten på bilder och hämta ut parametrar som skulle kunna känna igen ansikten i realtid. Systemet skulle hantera indata utan att behöva modifiera den till en specifik mall samt hantera olika typer av ansiktsvinklar, framifrån, roterade och profiler. En detektor byggdes för att känna igen profiler och upp/ner rotationer på ± 45° med käken som utgångspunkt.
Neuronnätets arkitektur byggde på att plocka ut 32x32 bitar för varje 4 pixlar horisontellt och vertikalt. Dessa delades i sin tur upp i mindre bitar
så att 9 dimensionslager skapas. Detta gjordes för att få ut de bästa parametrarna. Systemet testades på bilder inhämtade från NEC Labs. 30000 bilder ändrades så att de fick en enhetlig skala. De roterades även så att mittpunkterna för ögon och mun blev likartade. Dessutom togs de delar av ansiktet som inte behövdes bort. Bilderna spegelvändes även vilket innebar att det totala antalet bilder blev 60 000. Vissa bilder togs bort för att skapa en jämn spridning av ansikten från olika vinklar och kvar för testning fanns 52 850 bilder i gråskala.
För att testa om systemet kunde hantera data utfördes tre olika ansiktsigenkänningstester. De tre ansiktsigenkänningstesterna utfördes med en kombination av vinklade bilder och bilder i profil. Bilderna som användes kunde vara i färg- eller gråskala.
2.3.6 Fovea intensity comparison code for person identification and verification
Författarna [6] gjorde en undersökning om ansiktsigenkänning som baser-ades på FICC (fovea intensity comparison code). FICC är baserat på att plocka ut värden från mun- och ansiktsområden som används till ansikts-igenkänningen. Till hjälp använde författarna sig av grå- och färgfilter för att få ut de biometriska punkterna. Testet utfördes i realtid i en kon-trollerad laboratoriemiljö samt mot en databas. Databasen som används till testerna var XM2VTS. För att få ut värdena använde de sig av ett ovalt nät som lades över ansiktet beroende på var ögonen fanns. Munnens mitt-punkt räknades ut med hjälp av ögonens och munnens placering. För att göra testerna användes en kamera med en upplösning av 160x120. 50 testpersoner användes till FICC testerna i laboratoriemiljön. Ur databasen använde de sig av 248 testpersoner vars videoinspelningar ändrades från en upplösning av 720x576 till 320x240.
Bilderna av testpersonerna som togs i realtid hade variationer, till exempel olika storlekar, uttryck, lutningar och utseende trots att de var tagna fram-ifrån. Författarna använde sig av tre olika skalor när de plockade ut vär-dena det gjorde att de fick 150 ansiktspunkter att utgå från per testperson (50 stycken). Tre olika identifieringstester gjordes, ögon-, mun- och ögon plus munidentifiering.
2.3.7 Report on the Evaluation of 2D Still-Image Face Recognition Algorithms
Rapporten om ansiktsigenkänning av 2D stillbilder gjordes av NIST (Nat-ional Institute of Standards and Technology) [7]. Tre universitet och sju företag deltog i undersökningen och fick testa sina algoritmer för FR. Algoritmerna testades mot bilder i tre olika program. Dessa var körkorts-, pass- och identitetsregister. Bilderna som användes var av olika kvalitet,
tagna i olika ljusförhållande och av varierande ålder. Antalet bilder per testperson varierade från 1 till 23 stycken. Bilderna som användes till testerna valdes ut slumpmässigt från de olika databaserna. Bilderna som jämfördes med varandra var stillbilder. Bilderna som valdes var från 1960-talet fram till 2008. Bildernas storlek varierade mellan 240x240, 300x252, 480x640 och 768x960. De fyra olika databaserna som bilderna inhämtades från hade mellan 263 till 1 802 874 testpersoner.
2.3.8 Facial Recognition in Uncontrolled Conditions for Information Security
Författarna [8] ville hantera problemet med verifikation av användare vid en dator. Därför skapade de ett FRS system som använde sig av videobaserad övervakning av datoranvändaren. Webbkameran tog bilder av användaren som satt framför datorn med jämna mellanrum för att verifiera att det var rätt användare som utnyttjade datorn och dess program. Eftersom bilderna påverkades av bland annat ljusvariationer, uttryck och ansiktsvinklar blev en del indata korrumperad. För att åtgärda detta försökte författarna att skapa en algoritm som kunde hantera dessa avvikelser när de uppstod. De gjorde tre olika experiment på två databaser, CIM och FERET. Testerna gjordes med vinklarna ±30°, ±10° och 0°.
Först avläste webbkameran på datorn ansiktet genom att hitta använd-arens iris. Upplösningarna på bilderna kunde då vara upp till 1024x768. Programmet använde sig av iriskoordinaterna för att rättställa ansiktet till en 0° vinkel så att irisen befann sig på samma våglängd. Bilden gjordes sedan om så att den hade 40 pixlar mellan ögonen. Efter det delades bilden upp i 64x64 och den övre delen av ansiktet vid hårfästet togs bort. Även nacke och skuldror editerades bort. För att handskas med eventuell ljus-påverkan filtrerades bilden till två endimensionella signaler i stället för två-dimensionella. De filter som användes för att få ut de biometriska punkt-erna var Gaussian- och Homomorffilter.
Bilderna i CIM-databasen innehöll ett flertal bilder av varje person. 19 av de 43 personerna i databasen fick komma tillbaka vid ett senare tillfälle för att ta fler fotografier. Detta gjordes för att skapa variation bland bilderna på personerna. På de nya fotografierna hade personerna andra frisyrer och attiraljer jämfört med när de första bilderna togs. FERET databasen innehöll 725 testpersoner, 580 av dem valdes ut slumpmässigt för att genomföra testet, de resterande 145 fungerade som utfyllnad.
2.3.9 Face recognition with disguise and single gallery images
I artikeln beskrev författarna [9] en algoritm som skulle kunna ta hand om två stora problem inom Facial Recognition. De två problemen var att jämföra bilder med ett begränsat antal bilder av en individ i en databas
samt att kunna hantera bilder där delar av ett ansikte var dolda. Författarna använde sig av ett neuronnät för att hämta ut specifik data ur 2D-bilder som skulle komma att bli referenspunkter. För att lokalisera de biometriska referenspunkterna använde författarna sig av Gaussian- och Garbofilter. Bilderna matchades mot både syntetiska och riktiga ansikten där någon del av ansiktet var dolt.
Bilderna som användes var tagna framifrån där vissa ansikten på bilderna kunde ha smärre lutningar. Ansiktena som valdes ut var till viss del dolda med bland annat mustasch, mössor, glasögon och hårstilar samt att bild-erna innehöll olika ansiktsuttryck och hade olika ljusskärpa. Algoritmen testades mot bilderna från tre olika databaser, National Geographic, AR och en databas med egenkonstruerade bilder. För att göra de syntetiska ansiktena använde författarna sig av mjukvaruprogram som bland annat polisen använder för att skapa fantombilder.
Den egna algoritmen jämfördes sedan mot PCA, GF, LFA, IGF och LBP (se avsnitt 2.1). De olika algoritmerna testades med en bild som matchades mot en databas som innehöll en, två eller tre liknande bilder av personen för att se om antalet bilder av en person i databasen hade någon betydelse. Det andra testet gick ut på att jämföra bilder med delvis dolda partier av ansiktet mot en bild i databasen utan dolda delar.
2.3.10 Face Recognition from Still Images to Video Sequences: A Local-Feature-Based Framework
Författarna [10] ville med sina tester få fram ett system som kunde hantera indata från stillbilder och videobaserade bilder från övervakningskameror. De fyra olika metoderna som provades var Avg-feature, Mutal Subspace Method, Manifold to Manifold Distance och Affine Hull Method (se avsnitt 2.1). Metoderna testades mot stillbilder i en LFW-databas och mot videobaserade i en MOBIO-databas. LFW-databasen innehöll 13 233 ansiktsbilder. Bilderna hade varierande ljussättningar, vinklar, upp-lösningar, uttryck och bakgrunder (tagna på olika platser). Bilderna till LFW-databasen hämtades från internet och modifierades när det gällde skala och centrering. Ansiktena standardiserades även till 64x64 format. Inställningar för LFW testet gjordes genom att författarna successivt ökade bildbiblioteket från 2 till 4096 objekt och ökade antalet regioner från 1x1 till 4x4. De olika metoderna testades sedan mot 3 till 4 bilder mot MRH- och LBP-algoritmer samt pixelintensitet i LFW-databasen. MOBIO-data-basen hade 1500 videor som jämfördes med bilderna av 27 män och 20 kvinnor. Varje person i galleriet hade fem olika videor. Ett externt program fick användas för att känna igen ansiktena eftersom detta inte fanns att
ade Classifier för att känna igen ansikten. Det är en applikation som kan vara förbestämd att leta efter specifika objekt på en bild av till exempel en bil eller ett ansikte. För att identifiera ett ansikte letar applikationen till exempel upp specifika punkter som kan matcha ögon, mun, näsa med mera.
Eftersom videofilmerna i MOBIO var av så dålig kvalitet kunde bara upp till två ansiktsbilder per video tas ut. På grund av det låga urvalet användes bara metoderna Avg-feature, AHM och MSM. Det som undersöktes var genomsöks hastigheten som krävdes för att ta ut 4, 8 och 16 bilder ur videoklipp med de olika metoderna.
2.3.11 Using backpropagation neural network for face recognition with 2D + 3D hybrid information
I artikeln [11] beskrev författarna hur de ville testa att kombinera 2D- och 3D-indata för att försöka få fram ett bättre matchningsresultat. 3D-data från ansiktena extraherades med hjälp av ett neuronnät. Författarna använde sig även av lagerkartläggning av bilderna (Depth map) för att få så bra biometriska värden som möjligt. För 2D-bilderna användes 38 lager och för 3D-bilderna 64 lager. De ansiktsdrag som valdes ut, valdes ut med hjälp av PCA algoritmen och konfigurerades med LAC (local autocorrelation coefficient). I undersökningen användes 100 testpersoner. 13 bilder med olika uttryck togs från varje person. Sex bilder av varje person användes för testet och sju användes för att ställa in programmet. Upplösningen på bilderna var 1376x1032 pixlar.
Författarna testade tre metoder mot 2D, 3D och en kombination av 2D+3D. Dessa lagrades i tre olika databaser. Metoderna gick ut på att testa bilder som antingen var konfigurerade med LAC, eller som hade fått ansikts-dragen uttagna med PCA samt en kombination av LAC och PCA. Metoderna räknades ut mot BP (backpropagation) och MD (minimum distance). Testerna gjordes i en kontrollerad miljö.
2.3.12 Face Recognition: A Literature Survey
Författarna [12] hade gjort en litteraturstudie om video- och stillbilder samt om utrustning som används i FR-undersökningar. Både för- och nackdelar med de olika bildtyperna identifierades i studien. Det framkom att det kan vara en nackdel att plocka ut bilder från en videosekvens eftersom kvaliteten på bilder från en videokamera överlag är av sämre kvalitet. En sämre bildkvalitet påverkade matchningsprocenten till det sämre. Undersökningen visade dock även en fördel med att använda videobilder. Det går att plocka ut ett antal bilder från en videosekvens och sedan sätta samman dem och skapa en ”ny” bild med bättre kvalitet.
De tog även upp information om de olika metoderna som används samt tog upp problem som kan förstöra indata, till exempel ljusvariationer. Detta gjorde författarna genom att gå igenom ett antal olika undersökningar samt sammanställa informationen från dessa undersökningar. Ljuspåverkan visade sig ha en påtaglig inverkan på bilderna. Ljuset påverkar de punkterna som behövs för en korrekt matchning vilket kan leda till att det blir fler felmatchningar (se 3.1.12).
3 Resultat
3.1 Artiklarnas resultat
3.1.1 Three-dimensional facial surface modelling applied to recog-nition.
Testerna [1] visade att den bästa matchningen för öga och näsa var PCA-algoritmen som hade ett ansiktsnät på 45x45x45 och en upplösning på 1x1. Matchningsprocenten låg på 78-79%. Det bästa resultatet för SVM var också ett ansiktsnät på 45x45x45 och en upplösning på 1x1 där match-ningsprocenten låg runt 75%. Även för matchningar gjorda i 1x4 upp-lösning var det PCA-algoritmen som gav bäst utslag med 30x30x30 ansiktsnät. Matchningsprocenten var runt 67-68%. Även för SVM var det ansiktsnätet 30x30x30 som gav bästa matchningarna, ca 67-68%. När testerna jämfördes med horisontella bitar mellan ögon och näsa gav SVM med ansiktsnät 30x30x30 och upplösning 1x4 bäst resultat på 78%. PCA med samma upplösning och ansiktsnät gav endast 68% rätt matchning. Även för upplösning 1x1 var det SVM som gav bäst utslag med en matchning på 77 % och ansiktsnät på 30x30x30. PCA algoritmen gav bäst resultat med upplösningen 1x1 och ansiktsnät på 55x55x55 med en matchning på 72%. Dessa tester var gjorda i en okontrollerad miljö.
Det bästa resultatet i kontrollerad miljö var på 90,16% med algoritmen PCA, med upplösningen 1x1 och ett ansiktsnät på 45x45x45. SVM kom på andra plats med 88,52% med samma ansiktsnätsstorlek och upplösning. De bästa resultaten var de med upplösning 1x1 inom SVM och PCA. Absolut sämst var PCA med ansiktsnät 30x30x30 på 65,57 match-ningsprocent.
3.1.2 2D and 3D face recognition: A survey
Författarna [2] sammanställde resultaten från olika algoritmer som an-vändes på och 3D-bilder. Vid sammanställningen av resultatet av 2D-matchningen visade det sig att matchningsprocenten minskar ju fler para-metrar som påverkar bilderna som fanns med. Om bilderna bara match-ades mot andra bilder i en databas som inte hade några modifikationer (bra
ansikten med olika utryck fanns med i databasen minskade match-ningsprocenten eftersom de olika ansiktsuttrycken försämrade bild-kvaliteten och försvårade för algoritmen att avläsa nödvändiga värden. Speciellt märktes skillnaden när det fanns ansikten där vissa delar var dolda (sämre bildkvalitet). Då hamnade matchningen runt 65-81%. Detta var i kontrollerade förhållande.
3D-sammanställningen visade att matchningarna av bilderna inte på-verkades i samma grad av korruption vid ansiktsvridning, dolda ansikts-partier, ljus och uttryck som vid 2D-avläsning. Detta visar att 3D-avläsningen inte är lika avhängig av bildkvalitet när det gäller dolda partier eller ta ut rätt värden från bilder med ansiktsuttryck som 2D-avläsning. Den 3D-undersökning som hade dolda ansiktspartier med i testerna gav en matchningsgrad på 91.67% till skillnad från 2D-bilderna där matchningsprocenten låg mellan 65-81%. I de båda jämförelserna fanns det få avvikelser från normen. Författaren påpekade att det fanns en del andra faktorer som kunde påverka resultaten till exempel antalet testpersoner som fanns i databasen, bristen på variation bland bilderna (antalet bilder per person).
3.1.3 Color Face Recognition for Degraded Face Images
Resultatet av undersökningen [3] visade att skillnaden mellan gråskala och färgskala i låg upplösning var markant. I upplösningarna 112x112, 86x86 och 44x44 blev VRG-värdet runt 4,2% till 6,8% med en avvikelse på 1,55% till 2,56%. Däremot blev VRG-värdet större när upplösningarna minskade. Upplösningen 15x15 gav VRG-värdet 47,2%. Upplösningen 20x20 gav ett värde på 48,9% och upplösningen 25x25 gav VRG-värdet 51,2%. Gråskala och färgskala påverkade de tre olika algoritmerna olika.
Tabell 3: Tabellen visar matchningsprocenten för de olika algoritmerna i gråskala och färgskala FR algoritmer 112x112 86x86 44x44 25x25 20x20 15x15 Bayesian(Grå) 79,16% 75,19% 76,33% 65,72% 62,72% 52,70% Bayesian(Färg) 82,06% 78,32% 77,18% 76,56% 74,10% 68,32% PCA(Grå) 68,65% 65,65% 64,01% 41,89% 44,86% 40,01% PCA(Färg) 72,23% 75,13% 68,37% 62,16% 62,43% 55,67% FLDA(Grå) 78,64% 76,75% 75,94% 32,70% 28,91% 10,81% FLDA(Färg) 83,51% 80,00% 77,57% 69,45% 69,72% 64,86%
Den algoritm som visade störst skillnad i matchningsprocent mellan gråskala och färgskala var FLDA. Det kan ses i Tabell 3 att FLDA
påverka-des mest av färgskala kontra gråskala i upplösningarna 25x25 och neråt. Den algoritm som visade minst påverkan av färgskala kontra gråskala var Bayesian. Dock framträdde skillnader även i denna algoritm framförallt i de lägre upplösningarna. Den förbättrade bildkvaliteten som inträffade från gråskala till färgskala underlättade matchningen för samtliga algoritmer. När bilderna var i gråskala fanns det mer orenheter som kunde förvilla algoritmerna när värdena togs ut. Dessa orenheter minskade när bilden var i färg och underlättade avläsningen och matchningen. I tabell 3 går det att se att bilder med låg upplösning påverkades i större grad av bildens kvalitet. I tabell 3 går det även att se fördelen med högre upplösning (bättre kvalitet) då matchningsprocenten överlag blev bättre både i grå- och färgskala för samtliga algoritmer. Dock hade algoritmerna PCA(Grå och Färg) och FLDA(Färg) en bättre matchningsprocent i 20x20 upplösning än 25x25 fast ökningen var marginell.
3.1.4 iBotGuard: An Internet-Based Intelligent Robot Security System Using Invariant Face Recognition Against Intruder
För IDT (Intelligent Detection Test) [4], som letade efter ett ansikte på en bild, låg igenkänningsprocenten mellan 95% och 98%, trots ljusvariationer, smärre lutningar av ansikten samt att det förekom mer än ett ansikte på en och samma bild som försvårade tolkningen av data. Dock hade IDT pro-blem att läsa av ansikten som till viss del var dolda. Då blev igen-känningsgraden 85%. FET–testet (Feature Extraction Test) visade att om en dator per punkt användes för att iordningsställa punkterna minskade processtiden med 65%. Det var tre datorer som användes för att läsa av punkterna. Av de 100 testmönster som användes på bilder i olika vinklar hamnade snittmatchningen på cirka 85%. Detta innefattade bilder som hade en lutning på ±20° horisontellt och vertikalt.
De 100 testmönsterna med ansikten med delvis dolda partier gav match-ningsprocenten 77%. Vid enbart olika ansiktsuttryck blev matchnings-procenten 81% och om ansiktet endast hade glasögon för att dölja ögon-partier blev matchningsprocenten 82%. I artikeln redovisades ingen exakt uppdelning av antalet bilder per person i databasen. Författarna förklarade att det fanns 2000 bilder på 200 personer. Om bilderna var jämnt fördelade skulle det innebära att det fanns 10 bilder per testperson i databasen att matcha mot. Eftersom siffran inte går att verifiera går den inte att använda till jämförelser. Undersökningen gav heller inget svar på om resultaten hade gett ett annorlunda utslag vid färre antal bilder i databasen. Resultatet av undersökningen visade däremot att bildkvaliteten hade en påverkan på matchningsprocenten.
3.1.5 Synergistic Face Detection and Pose Estimation with Energy-based Models
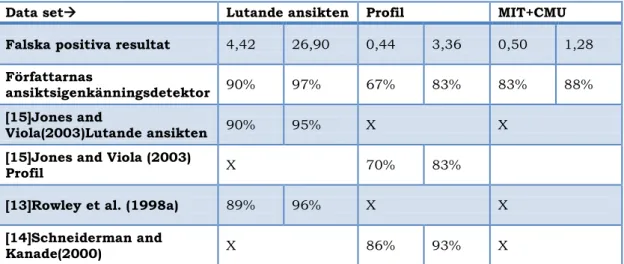
Resultatet av experimenten [5] gav olika matchningsprocent och olika antal falska positiva utslag per bild beroende på vilken matchningsgrad som skulle uppnås. Testen gick ut på att tolka indata för att hitta mönster av ansikten. Vid jämförandet av 225 lutade ansikten fick man 4,42 falska positiva utslag vid en ansiktsigenkänningsprocent på 90%. Vid en ansikts-igenkänningsprocent på 97% blev det 26.9 falska positiva resultat. Matchningarna mot 353 profilbilder gav 0,44 falska positiva resultat vid en ansiktsigenkänningsprocent på 67% och om ansiktsigenkänningsprocenten höjdes till 83% fick de 3,36 falska positiva resultat per bild. Vid en kombi-nation av MIT (Massachusetts Institute of Technology))+CMU (Carnegie Mellon University) blev resultatet bättre. MIT innehåller ca 200 syntetiska högupplösta bilder tagna framifrån, i profil och i halvprofil. CMU innehåller ca 337 bilder tagna i olika ljusförhållanden. För en ansiktsigenkännings-procent på 83% blev det 0,5 falska positiva resultat och en ansiktsigen-känningsprocent på 88% gav 1,28 falska positiva resultat.
Tabell 4: Författarnas igenkänningsdetektor sätts till att ge samma falska positiva resultat som andra tidigare detektorer. Dock är det bara författarnas detektor som kan kombinera MIT och CMU för testning.
Data set Lutande ansikten Profil MIT+CMU
Falska positiva resultat 4,42 26,90 0,44 3,36 0,50 1,28
Författarnas
ansiktsigenkänningsdetektor 90% 97% 67% 83% 83% 88% [15]Jones and
Viola(2003)Lutande ansikten 90% 95% X X
[15]Jones and Viola (2003)
Profil X 70% 83%
[13]Rowley et al. (1998a) 89% 96% X X
[14]Schneiderman and
Kanade(2000) X 86% 93% X
3.1.6 Fovea intensity comparison code for person identification and verification
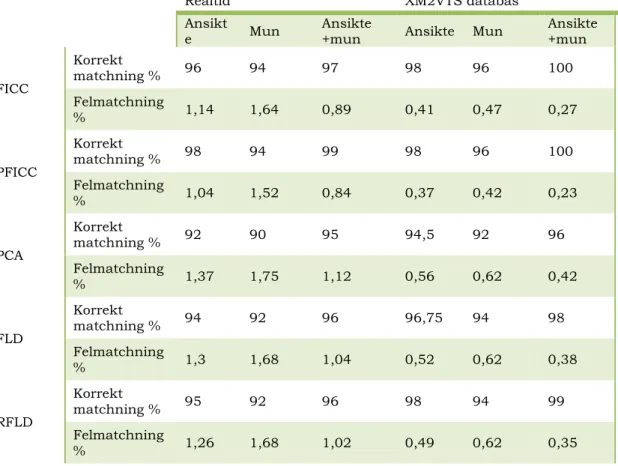
Experimenten [6] utfördes med algoritmerna FICC, Projected FICC (färdig beräknade FICC), PCA, FLD och RFLD. Resultatet visade att FICC och PFICC överlag gav bättre matchningsresultat i realtid samt mot databasen än de övriga algoritmerna. Även antalet felmatchningsprocent låg något lägre än för övriga algoritmer som användes.
Tabell 5: Resultaten av FICC, PFICC mot PCA, FLD, RFLD
Realtid XM2VTS databas
Ansikt
e Mun Ansikte +mun Ansikte Mun Ansikte +mun FICC Korrekt matchning % 96 94 97 98 96 100 Felmatchning % 1,14 1,64 0,89 0,41 0,47 0,27 PFICC Korrekt matchning % 98 94 99 98 96 100 Felmatchning % 1,04 1,52 0,84 0,37 0,42 0,23 PCA Korrekt matchning % 92 90 95 94,5 92 96 Felmatchning % 1,37 1,75 1,12 0,56 0,62 0,42 FLD Korrekt matchning % 94 92 96 96,75 94 98 Felmatchning % 1,3 1,68 1,04 0,52 0,62 0,38 RFLD Korrekt matchning % 95 92 96 98 94 99 Felmatchning % 1,26 1,68 1,02 0,49 0,62 0,35
Även om alla algoritmerna visade bättre resultat mot databasen än i realtid samt att vissa algoritmer hade en större minskning av felmatchningar än FICC och PFICC visade resultaten att FICC och PFICC var bättre på att matcha trots att bildkvaliteten var densamma för alla algoritmerna. En intressant faktor var att avläsningar som gjordes av munnen gav ett sämre resultat för alla algoritmer oavsett om matchningarna gjordes i realtid eller mot databasen.
3.1.7 Report on the Evaluation of 2D Still-Image Face Recognition Algorithms
När algoritmerna från de sju företagen och de tre universiteten testades [7] visade det sig att det fanns stora skillnader i antalet felmatchningar. Den bästa algoritmen nådde en matchningsprocent på 92%. Matchningarna gjordes med en okänd bild mot de 1,6 miljoner bilderna i databasen. Dock minskade matchningsprocenten ju större antal individer som fanns inlagda i databasen. Resultatet påvisade att det behövs fortsatta undersökningar med större databaser. Om däremot en person utvärderade träffarna och gjorde ett manuellt urval av de bilder som matchade, steg värdet på rätt matchningar till 97% och 97,5%. Ungefär 3 bilder som kom upp i
match-ningsresultatet behövde inspekteras för att kunna göra en korrekt matchning.
Om algoritmerna använde sig av ljusförändring genom att manipulera indata låg snittet på 89% matchning. Dessutom gav en av två matchningar felmatchning. Vid inställningen att bara en av tio fick vara felmatchningar sjönk matchningsprocenten till 85%. Därför påvisades det att en annan typ av algoritm bör användas. Dålig bildkvalitet samt dåliga ljusförhållanden visade sämre resultat. De algoritmer som gav bäst matchningsresultat var de som även hanterade vridna ansikten på bilderna.
3.1.8 Facial Recognition in Uncontrolled Conditions for Information Security
Det första experimentet [8] som utfördes visade att bilder tagna framifrån fick en sämre matchningsprocent än bilder tagna i andra vinklar. Match-ningsprocenten framifrån låg på runt 90% medan ±10° och ±30° visade på en matchningsprocent på 92,31% respektive 97.03%. När man testade mot FERET hamnade EER (Equal Error rate, sannolikheten för en felaktig avvisning) på 7,5%. FERET är en databas som innehåller bilder i färg- och gråskala samt bilder på personer tagna med upp till två års mellanrum. Detta innebar en matchningsprocent på 92,5%. Det här resultatet kunde enligt författarna jämföras med det dåvarande bästa publicerade resultatet på 6% EER som gjorts på FERET). Dock genomfördes författarnas test endast på åtta personer och möjligen kan resultatet skulle resultatet kunna avvika vid testning mot ett större urval.
Det tredje testet utfördes på CIM-databasen (Center for Intelligent Machines, McGill Universitys databas). Där visade bilder med ±0° vinkel sämst resultat. För att få fram resultaten räknade författarna ut var de olika värdena FAR (False Acception rate, sannolikheten att en felmatchning accepteras) och FRR (False Recognition rate, sannolikheten för en felaktig avvisning) möttes i en kurva. Där linjerna bröt varandra fick de fram vinkelns EER. På en vinkel av ±0° blev EER 7,42%. Vid vinkeln ±10° var EER 6,8% och vinkeln ±30° gav EER 4,86%. Resultaten visar alltså att algoritmer som kan hantera vinklar kan ge bättre resultat vid matchningar med vinklade ansikten och vara sämre på att matcha bilder tagna framifrån.
3.1.9 Face recognition with disguise and single gallery images
I resultatet från testerna [9] där en bild matchades mot ”1 till 3 bilder” i databasen framkom det att författarnas egen algoritm gav bättre match-ningsresultat än algoritmerna PCA, LFA, IGF, GF och LBP. Tabell 6 visar även klart och tydligt att samtliga algoritmer i undersökningen gav ett bättre resultat om det fanns fler bilder av en person i databasen att matcha
mot. Skillnaden mellan att ha tillgång till en eller tre bilder på en person i databasen hade såldes en stor betydelse för matchningsprocenten.
Tabell 6: Författarnas egen algoritm jämförs mot fem vanliga algoritmer för att se skillnader i matchningsprocenten. Databaser Antal bilder per person Matchningsprocent Författarnas
algoritm PCA GF LFA IGF LBP
AR 3 94,5 50,6 49,8 68,5 92,0 93,2 2 90,0 38,7 41,7 51,5 86,6 87,9 1 81,2 28,4 36,4 40,6 77,1 78,7 Förklädnad 3 86,8 26,2 37,4 54,8 80,3 81,1 2 81,1 20,5 31,6 43,2 71,6 72,9 1 74,3 16,7 23,0 35,3 62,8 63,4 Syntetisk, Förklädnad 3 95,6 86,5 90,1 92,9 93,4 94,1 2 91,8 77,2 82,2 85,5 86,8 88,3 1 83,2 69,6 79,0 80,2 80,6 81,4
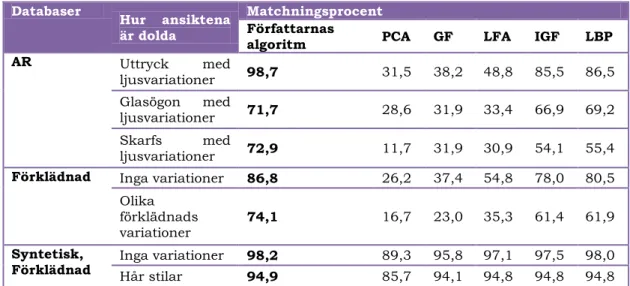
I det andra testet testades algoritmerna mot samma databaser fast bilderna matchades mot bilder med dolda partier istället. Dessa bilder var dolda på olika sätt och resultatet presenteras i tabell 7. Författarnas egen algoritm toppade matchningsprocenten i nästan alla testerna. Det test där den egna algoritmen inte fick bäst värde var mot GF algoritmen (se avsnitt 2.1) när skägg och mustasch finns med på bilderna.
Tabell 7: Författarnas egen algoritm samt vanliga algoritmer testas mot bilder med dolda partier.
Databaser Hur ansiktena
är dolda
Matchningsprocent
Författarnas
algoritm PCA GF LFA IGF LBP
AR Uttryck med ljusvariationer 98,7 31,5 38,2 48,8 85,5 86,5 Glasögon med ljusvariationer 71,7 28,6 31,9 33,4 66,9 69,2 Skarfs med ljusvariationer 72,9 11,7 31,9 30,9 54,1 55,4
Förklädnad Inga variationer 86,8 26,2 37,4 54,8 78,0 80,5 Olika
förklädnads
variationer 74,1 16,7 23,0 35,3 61,4 61,9
Syntetisk,
Skägg + mustasch 84,6 59,1 85,2 81,3 82,8 83,5 Glasögon 85,2 70,9 55,1 84,4 84,6 84,9 Mössa 94,7 82,6 90,9 91,7 92,8 93,1 Läppar, ögonbryn, näsa 97,1 87,4 78,6 96,3 96,7 96,8 Ålder och rynkor 95,4 77,5 81,8 92,9 94,0 94,4 Multipla
variationer 71,2 19,7 49,1 61,3 63,3 63,5
Tabell 7 visar tydligt att valet av algoritm är väldigt betydande när det gäller att avläsa en bild med dålig kvalitet där till exempel ljusförhållande eller attiraljer försvårar avläsningen i bilden.
3.1.10 Face Recognition from Still Images to Video Sequences: A Local-Feature-Based Framework
I det första testet [10] jämfördes MRH (se avsnitt 2.1) 1x1 till 4x4 regioner mot LFW-databasen där galleriet gick från 2 till 4096 bilder. Resultatet för 1x1 låg lägst i matchningsprocenten men när databasens storlek ökade visades en klar ökning av matchningsprocenten. Resultatet för 4x4 regioner visade initialt en jämn ökning av matchningsprocenten fram till 1024 bilder. Efter det minskade matchningsprocenten något från ca 72% till 71% vid 4096 bilder. Bäst resultat visade 3x3 som låg runt 73% från 1024 till 4096 bilder. 2x2 regioner hade en ojämn ökning av matchningsprocenten och låg lägre än 3x3 och 4x4 fram till 4096 bilder. Där fick 2x2 en bättre matchningsprocent än 4x4. Författarna jämförde sedan det bästa matchningsresultatet från regiontestet mot PCA (i samma förhållande). 3x3 MRH fick som bäst på 1024 bilder, 72,95% och PCA 59,82%.
I test nummer två jämförde författarna MRH, LBP och pixelintensiteten med hjälp av metoderna MMD, MSM, AHM och Avg-feature (se avsnitt 2.1 och tabell 8) samt metoderna min-, max- och medel avstånd mellan vektorer med tre och fyra bilder. Testet gjordes mot LFW-databasen innehållande stillbilder. I tabell 8 framgår det klart och tydligt att ett större antal bilder i databasen per person ger ett bättre resultat för algoritmerna. Detta gäller även för ren pixelintensitet (upplösning).
Tabell 8: Resultat av matchning av bilder i LFW Antal
bilder Metoder Olika avstånd
MSM MMD AHM Avg-feature Min-min Max-min Avg- min Min- avg
MRH
3 86,45 86,45 81,62 88,06 86,77 77,10 84,84 84,19 4 90,82 88,89 90,74 92,59 89,35 78,70 88,43 87,04
LBP 3 75,81 75,81 73,23 77,74 77,42 67,74 78,39 75,16 4 78,70 80,09 81,48 83,80 80,09 67,13 79,17 76,39 Pixel intensitet 3 65,48 57,87 66,13 61,29 59,03 58,39 60,0 56,13 4 72,69 67,13 68,52 67,13 64,35 58,8 63,89 63,89
Eftersom bildkvaliteten på bilderna i MOBIO-databasen var dåliga användes bara metoderna Avg-feature, AHM och MSM för det tredje testet där ett antal bilder från videoinspelningar togs ut och processades. Man mätte processtiden för 4, 8 och 16 bilder. Avg-feature processade en video snabbast med en medeltid på 0,51, 0,51 och 0,52 sekunder. Det lägsta resultatet fick AHM med 23,95, 44,95 och 88,73 sekunder. Även MSM-metoden var förhållandevis långsam med värdena 3,0, 5,48 och 10,44 sekunder.
3.1.11 Using backpropagation neural network for face recognition with 2D + 3D hybrid information
Resultatet av testerna [11] visade att kombinationen av PCA och LAC gav ett bättre BP resultat i 2D, 3D och 2D+3D. Kombinationen 2D+3D och PCA + LAC gav överlägset bäst resultat, 99% i MD och 100% i BP (se avsnitt 2.1). Databasens storlek påverkade även resultaten. 3D-igenkänning gav sämre resultat ju större databasen var däremot gav 2D-igenkänning ett stabilare resultat i takt med att databasens storlek ökade. 3D-igenkänning gav sämre resultat än 2D-igenkänning med PCA och LCA metoden. Testerna påvisade att användning av 2D+3D ökade matchningsprocenten överlag med tre till tio procentenheter.
Tabell 9: Metodernas matchningsresultat med MD och BP
Metod Klassificering Ansikten
2D 3D 2D +3D PCA MD 98,00 93,83 98,33 BP 99,50 96,83 99,83 LAC MD 96,03 87,17 97,50 BP 99,05 92,17 98,67 PCA + LAC MD 98,07 91,50 99,00 BP 99,83 100 100
3.1.12 Face Recognition: A Literature Survey
Författarnas [12] sammanställning av behandling av 2D-bilder visade att utvecklingen av FR har gått framåt. Utvecklingen av olika upplärnings-system, såsom SVM och Gaussians, har förbättrat ansiktsdetektion och igenkänning. Olika metoder har olika för- och nackdelar. Av den anled-ningen bör de olika metoderna användas på olika typer av bilder för att få fram det bästa matchningsresultatet. Bildernas storlek verkade inte ha någon större negativ påverkan när det gäller ansiktsdetektion. Det fanns till och med vissa fördelar med mindre bilder, till exempel mindre brus (störningar, fel) i bilderna. Däremot var en av de viktigaste punkterna att lokalisera och ta ut de data som användes för att bestämma ansikts-dragens specifika placering. Författarna belyste även det problem som kan uppstå när algoritmer ändrar och normaliserar indata. Om till exempel en bild som är tagen i vinkel modifieras för att se ut att vara tagen framifrån, genom att ansiktet vrids och ett nytt skapas efter en mall kan problem uppstå. Människors ansikten är inte helt symmetriska.
Resultatet visade även att det inte går att ta ut ansiktsdrag från bilder med en upplösning på ungefär 15x15 eftersom det anses för lågt. Det framkom också att valet av system inte alltid är lätt eftersom vissa fungerade bättre med färre bilder, till exempel PCA, och andra som till exempel LDA, var att föredra när det fanns många bilder. Författarna tog även upp problemet med att det inte fanns någon hybridmetod som kombinerade de olika metoderna. De antog även att systemet skulle få problem att samverka med större databaser.
Sammanställningarna av 3D-bilder från videor visade att en av fördelarna var att det fanns mer data att tillgå eftersom det går att plocka ut många bilder från en videosekvens. Dock var kvaliteten på 3D-bilderna oftast sämre än 2D-bilderna men det gick att åtgärda till viss del genom att ta multipla delar av videon för att skapa en bild med högre kvalitet. Den faktor som hade störst negativ påverkan på bildkvaliteten från 3D var enligt författarna ljusvariationer. Ljuset påverkade oftast indata till den grad att det inte gick att få ut specifika punkter för att kunna göra korrekta ansiktsmatchningar.
4 Analys
Resultaten av de olika undersökningarna gav oftast fördelaktiga utslag på den egna metoden eller undersökningen som gjorts. Generellt var algorit-merna och metoderna specifikt gjorda för att identifiera 2D- eller 3D-bilder. [2] Tester som är gjorda för att hantera algoritmer för 2D+3D bilder, så kallade hybridmetoder bör vara av stort intresse för att kunna utnyttja
Facial Recognitionsystemet till fullo. Detta eftersom hybridmetoder visar fördelaktiga resultat jämfört med att använda metoder var för sig (se även 3.1.11). Resultaten från undersökningarna kommer från testmiljöer som är kontrollerade i någon utsträckning, vilket både har nackdelar och fördelar. Nackdelen är att det är svårt att applicera tester gjorda i kontrollerade miljöer på okontrollerade miljöer då påverkan av olika parametrar kan bli för stor och göra att resultatet inte blir lika tillförlitligt eller användbart. Fördelen är att om det går att kontrollera miljöerna för FRS i specifika situationer i en öppen miljö bör systemet teoretiskt ge data som är tillräkligt tillförlitlig att informationen systemet presenterar går att använda.
Flera av testerna visade att underlaget av antalet testpersoner som finns med i databaserna som används i undersökningarna är dåligt. Till exempel [10] finns det bara 47 testpersoner med i MOBIO-databasen som användes för att plocka ut bilder ur videoinspelningar och [1] 61 personer användes för att kontrollera matchning av 3D-algoritmer i GavabDB där ansiktsnät jämförs. I tabell 2 visas en översikt av de vanligaste databaserna där data för FRS kan testas. Tabellen ger en överblick över skillnaden i antalet testpersoner som finns inlagda i de olika databaserna. Eftersom antalet testpersoner som används i undersökningarna oftast är lågt bör man som läsare vara återhållsam i tolkningen av resultatet eftersom eventuella felmarginaler och snävt utbud av testpersoner kan förvränga resultatet. Generellt används ett antal standarddatabaser i de olika undersökningarna vilket borde vara en fördel när jämförelser mellan testerna görs. Dock spelar algoritmer, filter, manipulation av bilderna för stor roll för att kunna göra rena adekvata jämförelser. Ett annat problemen är att vissa databaser innehåller bilder som är väldigt gamla samt att bildgallerier inte alltid uppdateras. Detta begränsar både urvalsmaterialet samt ifrågasätter kvaliteten på bilderna som finns lagrade. Eftersom bildernas ålder i de olika databaserna varierar kraftigt hade nyare teknik kunnat bidra med bilder av bättre kvalitet vilket skulle kunna ge ett annat utslag i testerna. Till exempel innehåller [8] FERET-databasen bilder från år 1993 och MOBIO-databasen bilder från år 2008.
I undersökningarna går det också att utläsa att det är problem med bilder där delar av ansiktena är [4] dolda eller saknas. [9] Detta gör att algorit-merna antingen får klara sig med de indata algoritmen får för att göra sina jämförelser eller ”gissa” sig till med hjälp av uträkningar hur ansiktet bör se ut. Detta ökar risken för att ytterligare matchningsfel inträffar. Match-ningsfelen visar sig även i matchningsprocenten på så vis att den dalar från stabila värden runt [4] 98% till [9] 71% eller sämre beroende på vilken algoritm som används och hur pass dolt ansiktet är. Detta gäller speciellt

![Tabell 2: Allmän information om några av de vanligaste databaserna[16]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4156577.89560/12.892.135.756.764.1096/tabell-allmän-information-vanligaste-databaserna.webp)


![Tabell 10: [9][10] Visar sambandet mellan antalet bilder av en person i databasen och ökad matchningsprocent, från två olika studier där LBP algoritmen har använts](https://thumb-eu.123doks.com/thumbv2/5dokorg/4156577.89560/37.892.137.750.1048.1115/tabell-sambandet-antalet-databasen-matchningsprocent-studier-algoritmen-använts.webp)
