Förtroendeskapande vid
person-uppgiftsbehandling
En studie om verksamheters behandling av
person-uppgifter och dess påverkan på förtroende.
Fabian Östling
Patrik Nilsson
IT & Ekonomi Kandidatuppsats 13 högskolepoäng VT-2018SAMMANFATTNING
Verksamheter har idag behov av uppdaterade kundregister för att skapa konkur-rensfördelar, detta har gjort att personuppgifters värde ökat. Detta har i sin tur gjort att insamlingen av personuppgifter har ökat kraftigt de senaste åren. Samtidigt har oron för hur verksamheter behandlar personuppgifter vuxit. För att göra behand-lingen av personuppgifter säkrare och skydda den enskilda individen har EU tagit fram den nya dataskyddsförordningen GDPR vilken träder i kraft 25 maj 2018. Studiens syfte var att undersöka vilka variabler i verksamheters personuppgiftshan-tering som har störst påverkan på kundförtroende. Vår huvudhypotes var att trans-parens skulle vara den huvudsakliga faktor som skulle skapa förtroende, men vi ansåg även att tid och säkerhet var två viktiga faktorer. För att uppnå syftet utfor-mades två hypoteser där första hypotesen ställer variablerna transparens mot tid+sä-kerhet och i andra hypotesen ställs transparens+sätid+sä-kerhet mot transparens+tid. Båda hypoteserna testas i fyra olika scenarier som grundar sig i GDPR. Dessa scenarier är:
1. Insamling 2. Registerutdrag 3. Portabilitet
4. Rätten att bli glömd
Studiens kvantitativa data har samlats in genom två webbenkäter och den kvalita-tiva datan samlades in genom kortare intervjuer.
Studiens resultat indikerar att transparens är den variabeln som har störst positiv påverkan på kunders förtroende vid insamlingen av personuppgifter. Däremot visar resultatet att variabeln säkerhet har störst påverkan på förtroendet i de senare sce-narierna.
Nyckelord
General data protection regulation (GDPR), förtroendeskapande, personuppgiftsbe-handling, transparens, säkerhet.
ABSTRACT
Businesses are today in need of updated customer records to create competitive advantages, which has led to an increased value of personal data. This has in turn led to an increase in the collection of personal data in recent years. At the same time concerns are increasing regarding how personal data is managed. To make data processing more secure and to protect the individual person, a new data protection regulation has been developed which will become enforceable on 25 May 2018. The purpose of this study was to investigate which variables in data processing have the greatest impact on customer trust. Our main hypothesis was that transparency would be the main factor that would create confidence, but we also thought that time and security were two important factors. To achieve this purpose, two hypoth-eses were designed, in the first hypothhypoth-eses the variable transparency is up against time+security and in the second transparency+security is up against transpar-ency+time. Both hypotheses is tested in four different scenarios which all are based on parts of GDPR. These scenarios are:
1. Collection
2. Subject access requests 3. Portability
4. Right to erasure
The study’s quantitative data was collected through two web surveys and the qual-itative data was collected through shorter interviews.
The study's results indicate that transparency is the variable that has the greatest positive impact on customer confidence during the collection of personal data. However, in the case of processing data in later stages of the relationship, security was most likely to affect confidence.
Keywords
General data protection regulation (GDPR), trust-building, personal data manage-ment, transparency, security.
FÖRORD
Malmö Juni, 2018
Processen som vi genomgått när vi skrivit denna uppsats har både varit rolig och lärorik men vi har även stött på många hinder. Så vi vill tacka Simon Winter som har hjälpt oss genom hela processen samt Hans Berggrund för han expertis inom GDPR.
Vi vill även passa på att tacka alla nära och kära som har stöttat oss under hela våren.
__________________ _________________
Innehåll
INLEDNING ... 1 Bakgrund ... 1 Syfte ... 4 Avgränsning ... 4 TEORIAVSNITT ... 5 GDPR ... 5Syftet med Dataskyddsförordningen ... 5
Definition av personuppgifter ... 5
Definition av hantering av personuppgifter ... 5
Samtycke ... 6
Rätten till tillgång av sina personuppgifter ... 6
Portabilitet ... 6
Rätten till att raderas ... 6
Sanktionsavgifter ... 7
Tidigare forskning ... 7
Vad är förtroende? ... 7
Sambandet mellan förtroende och konkurrensfördelar ... 8
Hur skapas förtroende? ... 8
Transparens och påverkan på förtroende ... 9
Sammanfattning av tidigare forskning ... 10
METOD ... 10 Deduktion ... 11 Metodval ... 11 Datakällor ... 12 Källkritik ... 13 Hypoteser ... 13 Enkäternas utformning ... 15 Intervjuernas utformning ... 16 Pilotstudie ... 16 Urval ... 17 Dataanalys ... 17 Enkäter ... 17 Intervjuer ... 18 RESULTAT ... 18 Respondent ... 18
Enkätresultat ... 20 Intervjuresultat ... 21 ANALYS ... 21 Scenario 1 - Insamling ... 21 Scenario 2 - Registerutdrag ... 23 Scenario 3 - Portabilitet ... 25
Scenario 4 - Rätten att bli glömd ... 26
Skillnaden i förtroende mellan olika åldersgrupper ... 28
DISKUSSION ... 28
Resultatdiskussion ... 28
Metoddiskussion ... 30
SLUTSATS ... 31
Förslag till vidare forskning ... 31
REFERENSLISTA ... 32
1
INLEDNING
Bakgrund
Handeln i Sverige kommer att förändras snabbare under de kommande tio åren än under de senaste femtio förutspår Svensk Handel (2017). Den största bidragande faktorn är digitaliseringen som möjliggör effektivare affärsmodeller och ökade möj-ligheter att leverera produkter på rätt plats vid rätt tidpunkt. Den pågående digitaliseringen har på många sätt förändrat människors sätt att leva, söka information och kommunicera. Idag delar människor ständigt med sig av sina personuppgifter vid användning av tjänster såsom sociala medier, nätbutiker och söktjänster. En effekt av detta är framväxten av en mängd nya verksamheter i en ny digital ekonomi där verksamheterna är beroende av IT för att förmedla produkter och tjänster (Graef, 2015). Kunders personuppgifter har i takt med digitaliseringen ökat enormt i kommersiellt värde och spridningen är större än någonsin tidigare. Enligt Internetstiftelsen i Sveriges (2017) årliga studie “Svenskarna och Internet” använder 94 procent av alla människor i Sverige internet. Det är däremot bara 32 procent av deltagarna i studien som säger sig dela med sig av sin information när de surfar på internet. Internetstiftelsen i Sverige (2017) tror däremot att denna siff-ran är betydligt högre då människor inte ser sina digitala aktiviteter som ett delande av information trots att det egentligen är just det som händer. Verksamheter som är aktiva på internet samlar in personlig information om sina kunder genom att spåra deras aktiviteter såsom köptransaktioner, besök på hemsi-dor och kontakt med säljare, beskriver Kotler, Armstrong och Parment (2017). Per-sonuppgifters värde har idag ökat så mycket att The Economist (2017) rankar det som den mest värdefulla resursen för verksamheter. Anledningen till detta är att verksamheter med hjälp av all tillgänglig kunddata kan skapa många olika konkur-rensfördelar. Wu, Kosinski och Stillwell (2015) visade i sin studie att det med hjälp av data från 58 000 Facebookanvändare och avancerade algoritmer är möjligt att lära sig förstå en person bättre än dennes närmaste vänner och familj. Forskarna kunde med hög träffsäkerhet förutspå ålder, IQ, religion, politiska åskådningar och sexuell läggning hos användarna. Denna studie visar hur värdefulla personuppgifter är för verksamheter eftersom det genom god kännedom om sina kunder kan perso-nanpassa tjänsterna helt och hållet. Dessa möjligheter kan även missbrukas vilket blev känt under våren 2018 då vetskapen om att Cambridge Analytica samlat in personuppgifter utan samtycke från Facebook användare i syfte att utveckla indi-vidinriktad propaganda till politiska kampanjer. Cambridge Analytica tillsammans med ytterligare två företag påstås ha samlat in information om mer än 87 miljoner personer. Informationen tros först ha använts under Brexit-folkomröstningen om Storbritanniens medlemskap i EU och sedan under det amerikanska presidentvalet 2016 (Bowcott & Hern, 2018, 10 april; Confessore, 2018, 4 april).
“The defendants effectively abused the human right to privacy of ordi-nary Facebook users and, if that were not enough, then the fruits of that abuse are alleged to have undermined the democratic process. This case will go some way to ensure that neither of these things can happen in the future”. - Jason McCue i Bowcott & Hern (2018, 10 april)
2
Vetskapen om dessa incidenter har lett fram till en växande oro över hur personlig information hanteras och Facebooks största kris någonsin. (Confessore, 2018, 4 april).
Mark Zuckerbergs första uttalande om händelserna riktades mot användarna av Fa-cebook, till vilka han bad om ursäkt för att ha svikit deras förtroende. Vidare dis-kuteras transparensen kring den reklam som förmedlas på Facebook. Zuckerberg säger själv att transparensen måste öka inom området och menar att det bör införas vissa förordningar för att kontrollera transparensen på sociala medier. (Segall, 2018, 21 mars). Facebook sjönk med över 5 procent på börsen när nyheterna kom om att utredningen mot Facebook inletts. Bolaget tappade under en 10 dagarsperiod över 100 miljoner dollar i börsvärde vilket motsvarade 821 miljoner kronor.
3
Zuckerbergs förhör inleddes den tionde april (Valinsky & Mullen, 2018, 4 april). Under förhören lades stor fokus på de lagar och förordningar som finns i USA för att reglera hanteringen av personuppgifter. Många parter inklusive Zuckerberg själv delade åsikten om att det krävs nya lagar och förordningar för att hantera det nya snabbt växande digitala och uppkopplade samhället. (Hern, 2018, 11 april). Facebook är inte den enda verksamheten som delar och säljer sin kunddata, Li, Sarathy och XU (2010) redogör för att verksamheter såsom Amazon, Paypal och eBay delar med sig av sin insamlade data till hundratals av deras samarbetspartners utan kundens medvetenhet. Denna utveckling är något som privatpersoner inte uppskattar lika mycket som verksamheterna. Internetstiftelsen i Sveriges (2017) undersökning “Svenskarna och internet” visar på att 33 procent av studiens tillfrågade har en stor oro för att stora internetföretag såsom Google och Facebook ska kränka den personliga integriteten. Ytterligare bevis för detta visas i Insight intelligence’s (2017) undersökning “Svenska folkets attityder till digital integritet 2017” som beskriver att människors oro över vad verksamheter gör med information som de lämnat ifrån sig på internet ökat med 17 procent de senaste två åren. Detta har gjort att många av kunderna lämnar falska personuppgifter till verksamheterna (Li m.fl. 2010; Nam, Song, Park & Ik, 2006) vilket ingen av parterna vinner på då konsumenterna inte får en lika personlig upplevelse och det blir svårt för verksamheter att bygga starka kundrelationer. Zhang och von Dran (2000) menar att kundernas oro kopplat till säkerhet och integritet är hygienfaktorer vid e-handel och måste därmed behandlas för att en online transaktion överhuvudtaget ska vara möjlig. Suh och Han (2014) beskriver att säkerhet i e-handel är en av de största utmaningarna och källan till den oron som konsumenter upplever. Problemen uppstår genom de säkerhetsbrister som finns på internet och det är därför nödvändigt att verksamheter använder sig av teknologier för att öka säkerheten och minimera kundernas upplevda risker.
Eggert och Helm (2003) beskriver att många produkter på dagens marknader är nästintill identiska och att produktkvalitet inte längre räcker som differentieringsfaktor. Därför är aktörerna tvungna till att hitta andra sätt att skapa konkurrensfördelar. Kundrelationer och mer specifikt transparens i relationer har i modern marknadsföringslitteratur beskrivits som en källa till kundvärde och kundnöjdhet. Eggert och Helms (2003) studie visar på att fler verksamheter med fördel bör ägna mer tid åt konceptet transparens då det kan reducera kostnader för kundrelationerna och befästa olika fördelar som båda parter kan dra nytta av. Detta går i linje med Eisingerich och Bell (2008) som beskriver vikten av att som verksamhet vara transparent och förse sina kunder med omfattande och öppen information kopplat till sin tjänst då det utvecklar förtroendebaserade relationer. Kunder söker sig till relationer med verksamheter som agerar mer professionellt, som lyssnar, bryr sig och relaterar till deras känslor, idéer och oro. Problemformulering
Den digital utvecklingen som pågår idag har gjort så att både värdet och spridningen av personuppgifter har ökat. Detta har lett till att personers medvetenhet och oro kopplat till spridning av personuppgifter ökat. Detta har i sin tur resulterat i nya lagar och förordningar kopplat till hur personuppgifter hanteras digitalt i form av EU-parlamentets förordning GDPR. När GDPR börjar gälla den 25:e maj stundar förändringar för samtliga aktörer med någon form av koppling till EU och dess
4
medborgare. Många företag har skjutit upp sina förberedelser inför implementationen för dataskyddsförordningen (Busvine, Fioretti & Rosemain, 2018, 8 maj). Detta kan bero på att verksamheter inte ser dataskyddsförordningen som något positivt. Men kan verksamheter som arbetar transparent leda till ett högt kundförtroende.
Syfte
Syftet med vår studie är att undersöka hur variablerna transparens, säkerhet och tid påverkar kundförtroende vid verksamheters personuppgiftsbehandling i tillämpningsområdet GDPR.
Avgränsning
Denna studie har avgränsats till att studera hur förtroende skapas vid personupp-giftshantering online och inte i fysiska butiker. Detta då stora delar av verksamhet-ers insamling av pverksamhet-ersonuppgifter och kommunikation med kunder idag sker via in-ternet. De variabler som studeras i studien är avgränsad till tre stycken då fler vari-abler hade gjort studien betydligt mer omfattande. Varivari-ablerna valdes då vi ansågs att de vara mest relevanta för studien utifrån tidigare forskning och den nya data-skyddsförordningen.
5
TEORIAVSNITT
Teoriavsnittet är indelat i två delar. I den första delen presenteras en sammanfattning av studiens tillämpningsområde, dataskyddsförordningen GDPR. Sedan presenteras tidigare forskning angående förtroende, transparens och säkerhet.
GDPR
Syftet med Dataskyddsförordningen
Ett av de mest grundläggande syftena med dataskyddsförordningen är att skydda varje enskild persons rättigheter, frihet och speciellt rätten till skydd av personupp-gifter. Vidare syftar GDPR till att skapa en enhetlig och likvärdig nivå för varje enskild individs skydd av sina personuppgifter inom EU. Men förordningen ska inte hindra det fria flödet av personuppgifterna inom EU. Detta kommer uppnås genom att förordningen kommer tillämpas i alla medlemsstater och på så sätt kommer la-gen gälla lika för alla medlemsländer inom EU även om det kan finnas skillnader i ländernas tolkning.
GDPR är en modernisering av reglerna i dataskyddsdirektivet från 1995, detta för att förordningen ska anpassas till det nya digitala samhället. (Datainspektionen, 2017a)
Definition av personuppgifter
För att förstå GDPR i sin helhet är det nödvändigt att först åta sig en god förståelse för vad personuppgifter är och vad det innebär. Datainspektionen (u.å.) beskrivning av personuppgifter är:
“All slags information som direkt eller indirekt kan hänföras till en fy-sisk person som är i livet räknas enligt personuppgiftslagen som per-sonuppgifter. ”
Datainspektionens beskrivning av personuppgifter är väldigt bred och diffus. För att förtydliga deras beskrivning menar de att personuppgifter även kan vara något som är indirekt kopplat till en person och inte enbart direkta personuppgifter som namn och personnummer. Sådan information kan vara ett IP-nummer, diarienum-mer, krypterade uppgifter och elektroniska identiteter. Det som Skatteverket (2017) beskriver som en avgörande faktor för om det är en personuppgift eller inte, är om en person på något sätt kan bli identifieras av en annan person. Ett exempel som Skatteverket (2017) beskriver är:
“Ibland kan uppgifter vara så detaljerade att det går att förstå vilken person som avses utan att någon direkt eller indirekt personuppgift anges, t.ex. ”kyrkvaktmästaren i Salems församling”. En sådan uppgift är också en personuppgift. ”
Definition av hantering av personuppgifter
6
“Alla former av åtgärder med personuppgifter är personuppgiftsbe-handling, till exempel insamling, registrering, organisering, strukture-ring, lagstrukture-ring, bearbetning, ändstrukture-ring, framtagning, läsning, användning, utlämning, spridning eller tillhandahållande på annat sätt, justering el-ler sammanförande, begränsning, radering elel-ler förstöring.”
Samtycke
För att en verksamhet ska få samla in och använda en individs personuppgifter krävs det att den registrerade frivilligt ger sitt samtycke. Detta ska verksamhetens person-uppgiftsansvarige kunna bevisa på förfrågan (Datainspektionen, 2017c). Om den registrerades samtycke lämnas skriftligt och verksamheten tänker behandla person-uppgifterna i någon annan fråga, så måste verksamheten på ett klart och tydligt sätt lägga fram sin begäran. Detta genom att verksamheten skriver sina frågor så att de är lättillgängliga med ett språk som är klart och tydligt.
När den registrerade har lämnat sitt samtycke ska detta samtycke kunna återkallas när som helst. Det ska vara lika lätt för den registrerade att återkalla sitt samtycke som att lämna sitt samtycke. Detta måste verksamheten informera den registrerade om innan samtycke lämnas.
Rätten till tillgång av sina personuppgifter
När GDPR träder i kraft kommer den registrerade ha rätten till att få en bekräftelse från verksamhetens personuppgiftsansvarige om dennes personuppgifter blir be-handlade av verksamheten (Datainspektionen, 2017d). Vid en sådan förfrågan ska den registrerade få information om ändamålet med behandlingen och den kategorier av personuppgifter som det rör sig om. Det ska även framgå om verksamheten har lämnat ut den registrerades personuppgifter till någon annan.
Om det är möjligt för verksamheten att förutse vilken period de tänker behandla personuppgifterna ska detta också framgå. Om detta inte är möjligt ska verksam-heten beskriva de kriterier som används för att fastställa denna period. Har inte verksamheten samlat in personuppgifterna själva så ska de skicka med all inform-ation samt förklara var dessa uppgifter kommer ifrån.
Portabilitet
Enligt Europaparlamentets och rådets förordning (ERF, EU 2016/679) kommer det göras möjligt för den registrerade att begära ut de personuppgifter som verksam-heten har samlat in från den registrerade. Vid en sådan förfrågan ska verksamverksam-heten tillhandahålla dessa personuppgifter på ett strukturerat, allmänt använt och maskin-läsbart format. Den registrerade har även rätten till att få dessa personuppgifter vi-darebefordrare till en annan verksamhets personuppgiftsansvarig. Om det är tek-niskt möjligt ska detta ske utan att den personuppgiftsansvarige på verksamheten som innehar personuppgifterna hindrar det. Enligt GDPR konsulten H. Berggrund (personlig kommunikation, 29 mars 2018) finns det dock ingen lag som gör att en verksamhet måste mottaga personuppgifter från en annan verksamhet.
7
Varje registrerad person kommer att ha rätten till att få sina personuppgifter rade-rade hos en verksamhet som behandlat dennes personuppgifter. Verksamheten måste genomföra denna förfrågan om personuppgifterna inte längre behövs för de ändamål som verksamheten samlat in dem för, eller om samtycket återkallas. Verk-samheten måste även radera den registrerades personuppgifter om de har använts till direktmarknadsföring och den registrerade motsätter sig att uppgifterna behand-las eller om verksamheten behandlade personuppgifterna på ett olagligt sätt. Om verksamheten även lämnat ut personuppgifterna till en annan verksamhet måste dessa också informeras om raderingen. (Datainspektionen, 2017e)
Sanktionsavgifter
Om en verksamhet inte följer reglerna i dataskyddsförordningen kommer de att få betala en administrativ sanktionsavgift. Storleken på denna sanktionsavgift beror på vilken bestämmelse som verksamheten överträder samt omständigheterna i varje enskilt fall. Datainspektionen kommer även ta hänsyn till hur stor överträdelsen är och hur stor skada som skett. Den högsta summan en verksamhet kan bli skyldiga att betala om de bryter mot reglerna i dataskyddsförordningen är fyra procent av verksamheten globala årsomsättning eller max 20 miljoner euro. Vilket av dessa två belopp verksamheten ska betala beror på vilket av beloppen som är högst. (Da-tainspektionen, 2018)
Tidigare forskning Vad är förtroende?
Svenska Akademien definierar förtroende som följande (1) övertygelse om att man kan lita på någon eller något, (2) anseende för pålitlighet i viss krets eller i allmänhet (Svenska Akademin, u.å)
Eisingerich och Bell (2008) definierar förtroende ur en affärskontext där kunden är i fokus, “customers’ confidence in a service seller’s reliability and integrity and the expectation that it can be relied upon to deliver its promises.”. En definition som går i linje med hur Lim, Sia, Lee och Benbasat (2006) definierar förtroende i en e-handels kontext, den tillförlitlighet en online-kund har till en online-försäljare. Och om kunden är villig att ingå i en transaktion online trots riskerna som finns baserat på förväntan om att försäljaren kommer att arbeta på ett allmänt accepterat sätt, och levererar den utlovade produkten eller tjänsten.
Inom vetenskapen beskrivs flera olika typer av förtroende, däribland kunskapsba-serat förtroende vilket bygger på kunskap om motparten i relationen. Utgångspunk-ten för kunskapsbaserat förtroende är att en person känner den andra parUtgångspunk-ten tillräck-ligt bra för att ha möjlighet att förutse dennes handlingar. En kunskap som kan ut-vecklas genom observation av motpartens handlingar och upprepade interaktioner men främst från erfarenheter från själva relationen. Desto mer en person vet om en annan desto större förtroende finns i relationen eftersom hen kan förutse hur mot-parten kommer att reagera och agera i de flesta situationerna (Lewicki & Bunker, 2006; Holsapple & Wu, 2008; Johansson, Jönsson & Solli, 2006).
Zucker (1986) beskriver hur förtroende producerades i USA mellan 1840 till 1920 vilket var en period då stora förändringar pågick i landet. I stor utsträckning produ-cerades förtroende under denna period genom att regler och formella strukturer
8
skapades inom den privata sektorn. Samtidigt började den ekonomiska sektorn styra transaktioner mellan verksamheterna genom samhällsomfattande lagar och förord-ningar. Standardisering var med andra ord vad som genererade förtroende. Denna beskrivning går i linje med Lim m.fl. (2006) presentation av institutions-baserat förtroende som en faktor vilket påverkar det initiala förtroendet hos en kund. In-stitutions-baserat förtroende är den säkerhet en individ upplever i en given situation på grund av de säkerhetsnät, garantier, eller andra föreskrivande och legala struk-turer.
Sambandet mellan förtroende och konkurrensfördelar
Bijlsma och Koopman (2003) beskriver att de i teorin inte råder något tvivel om de konsekvenser som förtroende skapar. De menar att det är allmänt känt att förtroende främjar många olika typer av organisatoriska processer genom att förbättra relationer mellan aktörer och reducera transaktionskostnader relaterade till kontroll.
När en relation mellan två parter utvecklas och de under tiden får erfarenhet om varandra och förtroendet ökar till varandra kommer engagemanget inom relationen gradvis att växa genom transaktionsspecifika investeringar i produkter och processer. Om förtroende skapas genom trygghet, säkerhet och trovärdighet kommer de uppoffringar en köpare står inför att minska och detta anses värdefullt i sig själv (Dwyer, Schurr & Oh, 1987; Selnes, 1998). Desto större förtroende en kund har gentemot en viss verksamhet desto villigare är kunden att dela med sig av sina personliga uppgifter. Verksamheter med högt förtroende kan samla in data genom att bara fråga kunderna. Detta är möjligt eftersom kunderna är nöjda med deras tidigare interaktioner och de fördelar som skapats utifrån att de delat med sig av sina personliga uppgifter samt att de har ett förtroende i att deras uppgifter skyddas. Det är å andra sidan mycket svårt och ibland omöjligt för verksamheter med lågt kundförtroende att samla in kunduppgifter oavsett värdet kunderna erbjuds för utbytet (Morey, Forbath & Schoop, 2015).
Hoffman, Novak och Peralta (1999) undersökning visar att bristande förtroende mot en verksamhet är en stor anledning till att konsumenter inte vill dela med sig av personlig information på webbplatser. 63 procent av respondenterna menar att de inte litar på verksamheterna som samlar in data, och 69 procent beskriver att anledning till att de inte lämnar ifrån sig personlig information är att webbplatserna inte ger någon beskrivning till hur informationen kommer att användas.
Hur skapas förtroende?
Enligt Kim, Xu och Koh (2004) byggs förtroende när den part som är förtrodd age-rar utifrån de förväntningar som den förtroende (motparten) har. En enkätstudie som genomfördes av Westin och Maurici (1998) visade att 84 procent av ameri-kanska folket kände en oro över integritetsintrång och en rädsla för att känslig in-formation såsom personnummer, kontonummer och lösenord hamnar i fel händer. Säkerhet är en av kunders största oro när de interagerar med aktörer online (Miya-zaki & Fernandez, 2000). Däremot minskar kundernas oro kopplat till integritetsin-trång och informationsstöld när en aktör använder sig av teknologier för att skapa en säker webbplats (Pavlou, 2003). Därmed är det mer troligt att kunder får större förtroende till de aktörer som använder sig av säkerhetsåtgärder på sin webbplats
9
då de ökar uppfattningen av säkerhet och vänder sig till dessa när de ska handla (Jarvenpaa & Tractinsky, 1999).
Morey m.fl. (2015) menar att det inte räcker att förse kunder med användarvillkor för personuppgiftsanvändningen. Vill en verksamhet öka sitt förtroende i kundens ögon är en av de viktigaste aktiviteterna att utbilda sina kunder om deras person-uppgifter. En aktivitet som Apple och Facebook gör bra, trots att de stött på mot-gångar och vid flera tillfällen haft låg grad av kundförtroende. Det som Apple har gjort bra är att sätta upp en sektion på sin hemsida dedikerad till utbildning inom integritet och datasäkerhet, där sidrubriken tydligt beskriver sidans syfte “Din in-tegritet är viktig för Apple. Därför har vi utvecklat en inin-tegritetspolicy som beskri-ver hur vi samlar in, använder, delar, öbeskri-verför och lagrar din information.”. Denna förändring gav Apple högsta möjliga poäng, sex stjärnor år 2015 från den ideella föreningen Electronic Frontier Foundation vilka arbetar med digitala rättigheter. Betyget 2015 var en stor ökning från 2013 då Apples poäng var en stjärna (Morey m.fl., 2015). Ytterligare en framgångsrik aktivitet för att bygga förtroende är att ge kunder kontroll över hur deras personuppgifter används och vem som har åtkomst till personuppgifterna. Över 72 procent av webbanvändare skulle ge ut sin demo-grafiska information och personuppgifter om webbplatserna förser dem med en för-klaring till vad och hur den insamlade informationen kommer att användas (Hoff-man m.fl., 1999)
Selnes (1998) menar på att förtroendet i en relation kommer påverkas genom hur en kund uppfattar en leverantörs kompetens. Hög upplevd kompetens kommer att öka förtroende från kunden. Utöver kompetens leder även goda kommunikations-egenskaper till ökat förtroende eftersom det leder till minskad osäkerhet och skapar en gemensam uppfattning av relationen mellan parterna.
Lim m.fl. (2006) beskriver att utveckling av förtroende i online miljöer är extra utmanande, eftersom det inte finns någon direkt kontakt med fysiska butiker, per-sonal och fysiska produkter i den digitala världen. Detta stämmer i allra högsta grad för besökare som för första gången besöker en okänd webbshop utan ett etablerat namn och rykte.
Transparens och påverkan på förtroende
Auger (2014) redogör att de personer som är förespråkare av transparens inom or-ganisationer menar på att ett transparent arbete leder till ökad substans i verksam-hetens autenticitet, legitimitet, trovärdighet och utvecklar intressenternas förtro-ende. En ståndpunkt som stärks av Edelman Trust Barometer som år 2010 för första gången inkluderade transparens som en mätparameter. Samma år rankades transpa-rens som nummer ett, följt av förtroende som de viktigaste aspekterna för att en verksamhet ska stärka sitt rykte (Edelman, 2010).
Bandsuch, Pate och Thies (2008) menar att transparens kan förekomma i flera for-mer. Aktiv transparens är då information avslöjas och bekräftatas av den part som informationen berör, passiv transparens är då informationen är tillgänglig men framställs först efter förfrågan. Eller ensidig transparens från verksamheten till in-tressenterna eller ömsesidig transparens då verksamheten svarar till inin-tressenternas förväntningar. Kärnan för transparens är dock densamma för alla typer, nämligen att informationen måste vara träffsäker och tillgänglig. Med träffsäker menar Bandsuch m.fl. (2008) att informationen är tydligt formulerad och relevant. Med
10
tillgänglig menar de att informationen faktiskt går att få tag på och att den är lätt att hämta för intressenter. Utöver detta ska informationen och dess betydelse vara lätt att förstå för alla typer av intressenter.
Auger (2014) presenterar två konstruktioner av transparens, organisationstranspa-rens och kommunikativtranspaorganisationstranspa-rens, båda påverkar förtroendet och behovsintention-erna hos kunder. Organisationstransparens är ryktet om en organisation och dess transparens, vilket påverkas av medias intryck, intressenters tidigare interaktioner med verksamheten och stödet från andra aktörer. Kommunikativtransparens hand-lar om att kommunicera pålitlig och faktisk information, öppet och transparent. Båda konstruktionerna påverkar individuellt graden av förtroende och behovsin-tentionerna hos kunden. Däremot kan en organisation med hög organisationstrans-parens inte utesluta en transparent kommunikation utan negativa effekter (Auger, 2014).
Kunders krav på transparens har vuxit under de senaste åren, både inom offentlig och privat sektor (Auger, 2014). Vid organisationers etiska felsteg kan transparens vara en lösning för att återuppbygga förtroende och minska riskerna att förstöra verksamhetens rykte. Transparens kan även öka stabiliteten hos verksamhetens in-tressenter och skapa konkurrensfördelar (Bandsuch m.fl., 2008; Rawlins, 2009).
Rawlins (2008) visade i sin studie att det finns en direkt relation mellan transparens och förtroende. Studien visade även att de komponenter i transparens som respon-denterna ansåg påverka förtroendet mest var ansvarstagande från verksamheten i att göra det som förväntas av kunden, att informationen är hållbar och att verksam-heten visar öppenhet. Enligt Bandsuch m.fl. (2008) är transparens en av de ledande katalysatorerna för att både återuppbygga och öka förtroendet mellan verksamheter och intressenter. Om en verksamhet är transparent i hur de använder, hanterar och skyddar kundens personuppgifter kommer förtroendet förstärkas (Morey m.fl., 2015).
Sammanfattning av tidigare forskning
Det finns många olika definitioner av förtroende och vi har valt att dela Eisingerich och Bell (2008) samt Lim m.fl. (2006) synsätt då de båda kopplar förtroende till kontexter som denna studie syftar att undersöka förtroende inom. Det är utifrån den tidigare forskningen tydligt att förtroende kan ses som en konkurrensfördel, inte minst i den digitala värld vi lever i idag. Den tidigare forskningen visar att förtro-ende främst skapas genom att arbeta transparent och utbilda kunder i hur deras per-sonuppgifter hanteras och vad syftet med behandlingen är. Ytterligare aktiviteter som skapar förtroende är implementationen av olika säkerhetsåtgärder för att skydda kundernas personuppgifter från att hamna i fel händer och missbrukas. Om en verksamhet bygger förtroende genom att arbeta transparent och implementera olika typer av säkerhetsnät kommer köpvilja att öka i takt med att förtroendet ökar vilket indikerar att förtroende är en konkurrensfördel.
METOD
Metodavsnittet inleds med en introduktion till studien för att sedan beskriva dedukt-ion och en motivering varför metodkombinatdedukt-ion valdes. Vidare så beskrivs studiens
11
hypoteser som följs upp av tillvägagångssätten vid enkäterna och intervjuerna samt pilotstudie. Detta följs upp av urval och dataanalys för de båda metoderna i stu-dien.
Introduktion till studien
Utifrån studiens inledning och syfte har vi utvecklat ett teoretiskt ramverk vilket omfattar relevanta teorier kring transparens, säkerhet och dess påverkan på förtro-ende. De mest relevanta delarna av den nya dataskyddsförordningen GDPR för denna studie är även en del av studiens teoretiska ramverk, de samlade teorierna ligger till grund för vår undersökning i studien.
Studiens metod är av kvantitativ karaktär men med kvalitativ validering, detta för att den kvantitativa metoden möjliggör statistiskt tillförlitliga resultat och den kva-litativa valideringen låter oss fördjupa förståelsen av dessa resultat. För att samla in data till den kvantitativa analysen valde vi digitala enkäter som datainsamlingsme-tod och utformade två enkäter. För att validera resultaten från analysen av den kvan-titativa datan genomfördes tio intervjuer som kvalitativ datainsamlingsmetod.
Enkäterna bygger på fyra scenarier som grundar sig i fyra områden i dataskydds-förordningen GDPR. Till varje enskilt scenario kopplades det fyra olika verksam-heter och en beskrivning av deras arbete med personuppgifter. Verksamhetsbe-skrivningarna utformades utifrån variablerna transparens, säkerhet och tid. De två första variablerna valdes utifrån teorier om förtroendeskapande medan variabeln tid ansågs vara relevant då det i dataskyddsförordningen beskrivs att en verksamhet måste behandla registrerades förfrågningar inom en viss tidsram.
Intervjuerna genomfördes först och främst för att skapa en djupare förståelse för respondenternas resonemang när de besvarade enkäten. Genom intervjuerna fick vi även en inblick i vilka variabler utöver transparens, säkerhet och tid som kan på-verka förtroendet hos en kund.
Deduktion
Vår studie grundar sig i existerande teorier om förtroende, transparens och säkerhet samt allmänna rättsprinciper från den nya dataskyddsförordningen. Utifrån detta teoretiska ramverk har vi skapat de hypoteser som ska prövas mot studiens empi-riska data. Detta tillvägagångssätt är karaktäristiskt för en deduktiv metod (Patel & Davidson, 2011).
Metodval
Vår studie är en metodkombination som utgår från en kvantitativ forskningsmetod med ett deduktivt angreppssätt i kombination med en kvalitativ metod. Valet att använda en metodkombination grundar sig i att vi vill söka en förklaring till sam-bandet mellan kunders förtroende och verksamheters arbete med personuppgifter utifrån olika variabler, samt skapa en djupare förståelse för sambandet. För att få så tillförlitliga resultat som möjligt var vårt mål att samla in minst hundra enkätsvar inom vår uppsatta tidsram och med rätt hjälpmedel är det enkelt att strukturera den insamlade datan och identifiera samband (Denscombe, 2016; Björklund & Pauls-son, 2012). För att samla in den kvalitativa datan valde vi att använda intervjuer
12
istället för fokusgrupper då dessa kan vara kostsamma och tidskrävande att arran-gera samt att respondenterna kan påverka varandras åsikter.
Både enkäter och intervjuer utgår ifrån att respondenten berättar något för forskaren men intervjuer är en källa till rikare och mer detaljerade data än den data som samlas in vid enkäterna, men resultatet från enkäterna går att generalisera (Denscombe, 2016).
Kritik som finns mot den kvantitativa forskningsmetod är att de som genomför en studie använder sig av sitt egna omdöme och gör val när de analyserar datan vilket kan komma att påverka resultatet. Genom att vi använde en metodkombination kunde vi säkerställa validiteten i datan genom att respondenterna berättade mer ut-förligt hur de tänkte när de besvarade enkäterna. Men att använda metodkombinat-ion i studien gjorde att det tog längre tid att sätta sig in i båda metoderna och det är inte säkert att resultatet skulle bekräfta varandra (Denscombe, 2016).
Datakällor
Primärdata är data som samlats in till en specifik studie och har till syfte att ligga till grund för resultatet i studien (Björklund & Paulsson, 2012).
Stora delar av denna studies primärdata har samlats in genom två internetbaserade enkäter som skapades med verktyget SurveyMonkey vilket är en tjänst som tillhan-dahåller verktyg för att skapa och distribuera enkäter via internet. Björklund och Paulsson (2012) menar att en studie kan få in en stor mängd primärdata genom enkäter med en relativt låg grad av ansträngning. Nackdelen med enkäter som da-tainsamlingsmetod är däremot flera, först och främst är det svårt att med säkerhet veta vem som svarar och vilken funktion respondenten har. För att säkerställa att respondenterna till denna studie uppfyller kravet att de någon gång delat med sig av sina personuppgifter online distribuerades enkäterna via Facebook och LinkedIn där alla användare per automatik delar med sig av sina personuppgifter när de an-vänder tjänsterna. Genom att välja denna distributionskanal hanterade vi ytterligare ett vanligt problem med metoden, nämligen risken med låg svarsfrekvensen och att validiteten i studien därmed blir låg (Björklund & Paulsson, 2012), genom valet av distributionskanal nådde vi ut till en stor mängd respondenter.
Vid valet av enkäter som metod är även risken till misstolkning av svaren större än vid metoden intervju eftersom det då finns en möjlighet till förtydligande både från respondenten och intervjuaren. För att minska risken för misstolkning av enkäterna genomfördes en pilotstudie. För att komplettera den insamlade datan från enkäterna använde vi oss av intervjuer för att samla in primärdata och för att validera och fördjupa förståelsen av enkätresultaten. Intervjuer gör det möjligt att skapa en dju-pare förståelse för hur respondenten tänker genom att anpassa frågorna som ställs till varje enskild respondent och på så sätt minskas graden av misstolkning (Björk-lund & Paulsson, 2012).
Sekundärdata är data som redan är insamlad och dokumenterad och används i stu-dien men som däremot oftast är framtagen till en annan studie och i ett helt annat syfte än den aktuella studien (Denscombe, 2016; Björklund & Paulsson, 2012). Den sekundärdata vi använt oss av i studiens inledning är undersökningar om allmän-hetens syn på internet och dess åsikter om digital integritet. Vetenskapliga artiklar om förtroende, transparens och personuppgifts säkerhet. Vidare användes relevanta internetkällor om värdet av personuppgifter och välkända tidningars rapportering av Facebook och Cambridge Analytica skandalen.
13
I teoriavsnittet har stora delar av sekundärdatan kopplat till GDPR hämtats från Datainspektionen vilket är den förvaltningsmyndighet som arbetar med GDPR i Sverige, denna informationen har även kompletterats med information från skatte-verket och EU. Den teoretiska referensramen bygger på vetenskapliga artiklar om tidigare forskning inom området förtroende, hur det skapas och varför det är värde-fullt, samt hur transparens och säkerhet påverkar kunders förtroende gentemot verk-samheter i dess hantering av personuppgifter.
Källkritik
De vetenskapliga artiklarna som användes i studien hämtades från Malmö Univer-sitets Libsearch samt Google Scholar. För att säkerställa trovärdigheten i dessa ar-tiklarna kontrollerade vi hur ofta de hade refererats till i andra artiklar. Majoriteten av artiklarna har refererats till över 100 gånger och vi anser dem då som trovärdiga. De få vetenskapliga artiklar som inte refererats till över 100 gånger var ofta nyare artiklar, vilka vi fortfarande anser är relevanta för studien.
De internetkällor och tidningar som används i studien valdes noga ut från välkända aktörer vilket ökar källans trovärdighet.
Hypoteser
Patel och Davidson (2011) beskriver hypoteser som antaganden om hur två eller flera begrepp är relaterade till varandra, hypoteser ska vara enkla och täcka gene-rella företeelser och inte bara specifika händelser. Hypoteserna bygger på hur vi tror att olika kombinationer av variablerna transparens, säkerhet och tid påverkar kunders förtroende. Varje hypotes ställer två variabelkombinationer mot varandra, och antagandet som görs i varje hypotes är kopplat till den kombination som vi tror genererar störst förtroende.
Valet av variabelkombinationer grundar sig i vår uppfattning av de enskilda vari-ablernas påverkan på förtroende. Vi trodde att variabeln transparens har större på-verkan än de övriga två variablerna och att säkerhet har större påpå-verkan än tid. För att undersöka om säkerhet genererar större förtroende än tid ställdes de mot varandra. Däremot ansåg vi att de som enskilda variabler inte skulle skapa en till-räckligt tydlig skillnad för att jämförelsen skulle vara intressant. Vi valde därför att inkludera transparens i både variabelkombinationerna för att göra analysen tydli-gare. Vi lät däremot säkerhet och tid forma en kombination då vi ansåg att de till-sammans har tillräckligt stor påverkan för att generera intressanta resultat i jämfö-relse mot transparens.
Vi har utöver tid och säkerhet som enskilda variabler uteslutit kombinationerna då samtliga variabler är positiva respektive negativa. Anledningen är att en kombinat-ion med enbart positiva variabler per automatik bör generera högst grad förtroende av alla kombinationer och då samtliga variabler är negativa bör lägst förtroende genereras. Dessa kombinationer hade därmed inte möjliggjort en intressant jämfö-relse.
Sammanfattningsvis ställer vi transparens mot tid+säkerhet vilket är studiens hypo-tes 1 och transparens+tid mot transparens+säkerhet är studiens hypohypo-tes 2. Båda hy-poteserna kommer testas i studiens fyra olika scenarier och kommer fortsättningsvis
14
benämnas HxSx, H står för hypotes, S står för scenario. Således är H1S1 hypotes 1 i scenario 1.
Scenario 1 - Insamling:
H1S1: En verksamhet som vid insamlingen av personuppgifter transparent beskri-ver anledningarna till varför insamlingen sker och hur behandlingen går till kommer skapa ett större förtroende än verksamheter som fokuserar på säkerhet och tid.
H1S1: Variabler: Transparens > Tid + Säkerhet
H2S1: En verksamhet som transparent beskriver anledningarna till varför de samlar in personuppgifter och vidtar säkerhetsåtgärder för att skydda din identitet vid in-samlingen kommer skapa större förtroende än en verksamhet som tydligt beskriver anledningarna till varför de samlar in personuppgifter och fokuserar på en snabb och effektiv process.
H2S1: Variabler: Transparens + Säkerhet > Transparens + Tid
Scenario 2 - Registerutdrag:
H1S2: En verksamhet som transparent beskriver anledningarna till varför de be-handlat och hur de bebe-handlat personuppgifter kommer skapa större förtroende än verksamheter som enbart fokuserar på en säkerhet och snabb behandling vid för-frågningar gällande personuppgifter.
H1S2: Variabler: Transparens > Tid + Säkerhet
H2S2: En verksamhet som transparent beskriver anledningarna till varför och hur de behandlat personuppgifter samt arbetar med att skydda kundens personuppgifter kommer skapa större förtroende än en verksamhet som strävar efter en snabb be-handling samt transparent beskriver anledningarna till varför och hur de behandlat personuppgifter.
H2S2: Transparens + Säkerhet > Transparens + Tid
Scenario 3 - Portabilitet
H1S3: En verksamhet som transparent beskriver anledningarna till varför och hur de behandlar personuppgifter kommer skapa större förtroende än verksamheter som enbart fokuserar på säkerhet och snabb behandling vid förfrågningar gällande per-sonuppgifter.
H1S3: Variabler: Transparens > Tid + Säkerhet
H2S3: En verksamhet som transparent beskriver anledningarna till hur de behand-lar personuppgifter och arbetar med att skydda kundens personuppgifter kommer skapa större förtroende än en verksamhet som strävar efter en snabb behandling och transparent beskriver anledningarna till varför de samlar in personuppgifter.
H2S3: Variabler: Transparens + Säkerhet > Transparens + Tid
15 Scenario 4 - Rätten att bli glömd
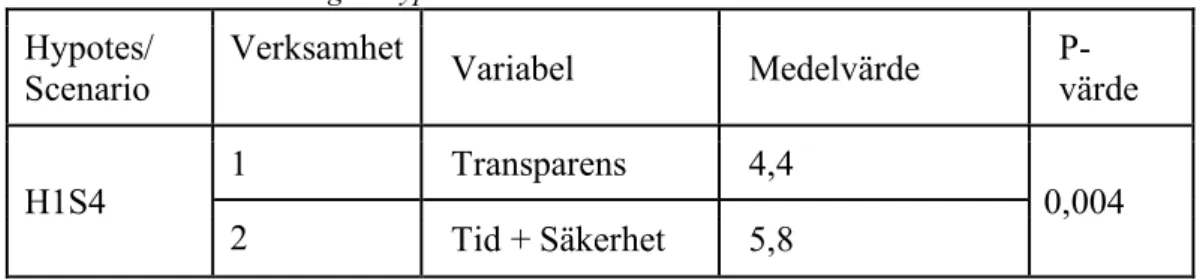
H1S4: En verksamhet som transparent beskriver processen för hur raderingen går till kommer skapa större förtroende än verksamheter som fokuserar på säkerhet och snabb behandling vid förfrågningar gällande radering av personuppgifter.
H1S4: Variabler: Transparens > Tid + Säkerhet
H2S4: En verksamhet som transparent beskriver processen till hur raderingen av personuppgifter går till och arbetar med att skydda kundens personuppgifter kom-mer skapa större förtroende än en verksamhet som strävar efter en snabb behandling och transparent beskriver hur raderingen går till.
H2S4: Variabler: Transparens + Säkerhet > Transparens + Tid Enkäternas utformning
När vi fastställt vilka variabler och kombinationer som skulle användas i studien började vi utforma de fyra scenarier som ligger till grund för enkäterna. Scenarierna grundar sig i situationer som kunder kan komma att stöta på när GDPR sätts i bruk. Första scenariot grundar sig i de skärpta kraven på samtycke vid insamling av per-sonuppgifter, det andra scenariot bygger på rätten till tillgång av sina personuppgif-ter. Tredje scenariot bygger på portabilitet av sina egna personuppgifter och det fjärde scenariot bygger på kundens rätt att bli glömd av verksamheter. Vi valde dessa fyra scenarier eftersom vi tror att de kommer vara de mest relevanta för en verksamhet och deras personuppgiftsbehandling utifrån GDPR. Ett scenario som vi valde bort var verksamheternas skyldighet att anmäla en personuppgiftsincident till tillsynsmyndigheten då detta antagligen kommer ske ytterst sällan.
Vi valde att dela upp enkäten i två olika enkäter där scenarierna var likadana men bara två av verksamheterna presenterade i varje enkät. Detta gjordes då vi försökte få enkäten så avskalad som möjligt eftersom motsatsen skapar en ovilja att svara på enkäten enligt Hagevi (2016).
Verksamhetsbeskrivningarna bygger på positiva och negativa värden av variablerna transparens, tid och säkerhet. I scenariot insamling är variabeln tid positiv när verk-samheten använder sig av en välkänd betaltjänst som automatiskt fyller i kundens personuppgifter och är negativt när kunden själv behöver fylla i personuppgifterna. I de tre övriga scenarierna är variabeln tid positiv när personuppgiftsbehandlingen genomförs snabbare än i de andra verksamheterna som då får ett negativ värde. Medan transparens som variabel är positiv inom alla scenarier när verksamheterna tydligt beskriver varför de samlar in och och hur de behandlar personuppgifter. Och är negativ när verksamheterna inte redogör för syftet med insamling och behandling av personuppgifter. Variabeln säkerhet är positiv i samtliga scenarier när verksam-heterna använder sig av BankId för att legitimera kunden och säkerställa att rätt person har tillgång till sina personuppgifter. Variabeln säkerhet är negativ när verk-samheten inte använder sig av BankID för legitimering.
I tabell 1 visas hur hypoteserna är fördelade i enkäterna. För att se enkäterna i helhet se bilaga 1.
16
Insamling Registerutdrag Portabilitet Rätten att raderas
Enkät 1 H1S1 H2S2 H1S3 H2S4
Enkät 2 H2S1 H1S2 H2S3 H1S4
H=Hypotes, S=Scenario
Intervjuernas utformning
När vi kontaktade respondenterna klargjorde vi syftet med studien och att deras medverkan är viktig. Sedan förklarade vi att de kommer vara anonyma i presentat-ionen av datan samt att datan hanteras konfidentiell. Respondenterna blev aldrig informerade om vilka variabler som ligger till grund för studien, varken i enkäterna eller under intervjuerna. Anledningen till att vi inte informerade om variablerna var för att minimera vårt inflytande på respondenterna.
De två aspekterna som vi tog hänsyn till när vi utformade intervjuerna var graden av standardisering och strukturering. Intervjuerna i vår studie har en hög grad av standardisering då frågorna och deras ordning är förutbestämda medan strukture-ringen är låg då respondenterna får tolka frågorna fritt och prata öppet (Patel & Davidson, 2011).
Eftersom det är nästintill omöjligt att få tillräckligt med detaljerade anteckningar under en intervju (Justesen & Mik-Meyer, 2012) inleddes intervjuerna med att fråga varje respondent om de samtycker till att vi spelade in samtalet. Vi valde sedan att inleda intervjuerna med två enkla frågor angående respondenternas spridning av personuppgifter. Dessa frågor ställdes för att göra respondenterna bekväma i situ-ationen men frågorna hade ingen större betydelse för studien. Vidare frågade vi respondenterna hur de resonerade när de genomförde enkäterna.
Avslutningsvis fick respondenterna berätta vad som i allmänhet gör att deras för-troende ökar eller minskar när verksamheter behandlar deras personuppgifter. Frågorna formulerades så enkelt och rakt som möjligt för att minska graden av missförstånd. Under intervjuerna valde vi att inte stressa respondenten genom att ställa en ny fråga så fort det uppstod tystnad. Detta då en kortare paus kan ge re-spondenten tid att tänka efter och kan på så sätt ge ett mer uttömmande svar (Trost, 2010).
Pilotstudie
Innan vi skickade ut enkäterna genomförde vi en pilotstudie för att säkerställa att frågorna fungerade och var rätt formulerade. Enkäterna skickades ut till totalt fyra personer som fick besvarade enkäterna i sin helhet, två personer genomförde enkät 1 och de två andra besvarade enkät 2. De synpunkter pilotstudiens respondenter hade var relaterade till mindre grammatiska fel, dessa grammatiska fel åtgärdades innan vi distribuerade ut enkäten. Vi genomförde även en pilotintervju för att sä-kerställa att intervjufrågorna var formulerade på ett sådant sätt att respondenterna inte missförstår frågornas innebörd. Vi fick inga betydande synpunkter på förbätt-ringsområden för intervjun under pilotstudien.
17 Urval
Icke-sannolikhetsurval.
Enligt Denscombe (2016) finns det två tillvägagångssätt som kan användas när ur-valet av respondenter görs, dessa två tillvägagångssätt är sannolikhetsurval och icke-sannolikhetsurval. Sannolikhetsurval utgår från att de som genomför en studie inte har något som helst inflytande på vem som kommer besvara enkäten medan icke-sannolikhetsurval finns en viss bestämmanderätt eller valfrihet någon gång un-der urvalsprocessen. Vi valde att arbeta med strategin bekvämlighetsurval som är en underkategori till icke-sannolikhetsurval. Valet grundar sig i att det är den mest fördelaktiga strategin för denna studie då det finns en tydlig tidsram på tio veckor och en begränsad budget. Strategin utgår från att de som genomför studien använder de personer som finns tillgängliga och denna strategi tenderar till att få en hög svars-frekvens (Bryman, 2011).
För att enkäterna skulle besvaras av rätt urvalsgrupp distribuerades enkäterna via Facebook och LinkedIn. Valet av distributionskanal säkerställde per automatik kra-vet att respondenterna någon gång ska ha delat med sig av sina personuppgifter. Detta då personer som antingen har ett konto på Facebook eller LinkedIn måste ha delat med sig av sina personuppgifter. Utskick via sociala medier möjliggör en ef-fektiv och gratis distribution till en stor grupp potentiella respondenter (Denscombe, 2016). Det var inte enbart respondenter i våra egna kontaktnät som fick tillgång till enkäten, när någon gillar eller delar våra inlägg på Facebook eller LinkedIn ser även deras kontaktnät inlägget och på så sätt blir det en bred spridning av enkäten. Valet av distribution över webben är dock inte helt problemfritt, en risk är självselektion. Vilket innebär att respondenter som svarar utser sig själva som relevanta för studien men behöver nödvändigtvis inte vara det (Denscombe, 2016).
Dataanalys Enkäter
Det finns olika typer av mätnivåer av data såsom nominalskalenivå, ordinal-skalenivå, intervallskalenivå och kvotskalenivå (Denscombe, 2016). Denna studie använder sig av ordinalskalenivå, vilket innebär att det går att beräkna och katego-risera den insamlade datan. På så sätt får de olika kategorierna ett specifikt nummer som sedan går att jämföra med andra kategori. Den tydligaste ordinalskaledata är den som används i enkäter och brukar benämnas som Likertskalan vilken i regel går från värdena “tar fullständigt avstånd” till “instämmer fullständigt”. Valet av att använda ordinalskalenivå gjordes då verksamheterna i enkäterna utgör olika kate-gorier som vi ville jämföra. Under varje verksamhetsbeskrivning valde vi att pla-cera en Likertskala där värdena går från “inget förtroende alls” till “mycket stort förtroende”.
För att kunna analysera den insamlade data från enkäterna sammanställdes datan i Excel. För att fastställa mittpunkten på enkätsvaren valde vi att använda medel-värde. Kritiken mot medelvärde är att den påverkas av extremvärde men eftersom skalan som används i enkäterna går från ett till tio så anser vi att det inte finns något extremvärde.
18
Utöver att undersöka den insamlade datan i sin helhet valde vi att undersöka skill-naden mellan olika åldrar och delade därför in respondenterna i två grupper 29 år och yngre samt 30 år och äldre. Valet av åldersindelningen gjordes då snittåldern hos de som svarade på enkäten var 30,4. Utöver denna indelning ansåg vi att en jämförelse mellan utbildningsnivå skulle vara intressant men då 90 procent av re-spondenterna hade eftergymnasial utbildning var fördelningen för ojämn och hade inte resulterat i något intressant fynd.
För att undersöka om det finns en statistisk signifikant skillnad mellan verksamhet-erna som ställs mot varandra i hypotesverksamhet-erna valde vi att utföra ett T-test. Testet utgår från två datauppsättningar och deras standardavvikelse. Testet ger ett p-värde vilket beskriver hur stor sannolikheten är att skillnaden mellan de två datauppsättningarna är ett resultat av en tillfällighet eller inte. Är p-värdet mindre än 0,05 eller 5 procent räknas skillnaden som statistiskt säkerställt och anses då inte vara en tillfällighet. Användningen av t-testet ger studiens resultat en ökad trovärdighet (Denscombe, 2016).
Intervjuer
Vi valde att vara selektiva i transkribering av intervjuerna. Detta för att vi genom-förd kortare intervjuer där vi sökte efter djupare förståelse av respondenternas tan-kar angående enkätsvaren och mindre citat som illustrerar detta. För att det ska vara möjligt att återvända till relevanta stycken i det insamlade materialet under analysen katalogiseras och indexeras vi datan.
Det empiriska underlaget från intervjuerna presenteras först i analysavsnittet då den syftar till att validera fynden i den kvantitativa datan och tillsammans analyseras utifrån studiens teoretiska ramverk. Eftersom att respondenterna inte alltid talar i fullständiga och avslutade satser har vi bearbetat och snyggat till den rådat som används i syfte att öka förståelsen för vad respondenterna kommunicerat utan att förändra innebörden (Denscombe, 2016).
RESULTAT
Resultatavsnittet inleds med att presentera respondenterna för att sedan presentera medelvärdena för de båda enkäterna. Avslutningsvis beskriver vi hur många intervjuer som genomfördes samt intervjuernas medellängd, detta följs upp med några citat som inte tas med i analysen men kommer diskuteras under diskussionsavsnittet.
Respondent
Vi fick svar från totalt 103 respondenter. 46 svarade på enkät nummer ett och 57 svarade på enkät nummer två. Snittåldern för det totala antalet respondenter ligger på 30,4 år. Könsfördelningen var 57 män och 46 kvinnor (Se figur 1). Det var ett bortfall på totalt 36 respondenter som inte slutförde enkäterna och vi valde därför att helt exkludera dessa svar i detta resultat.
19
Utöver att testa hypoteserna valde vi att undersöka om det finns någon skillnad i variablernas påverkan på förtroende mellan olika åldrar. Vi delade därför upp re-spondenterna i två grupper utifrån snittåldern, 29 år och yngre samt 30 år och äldre (Se figur 2).
Figur 1. Könsfördelning. Figur 2. Åldersfördelning.
55% 45%
Könsfördelning
Män Kvinnor 37% 63%Åldersfördelning
30 + 29-20 Enkätresultat
Nedan i tabell 2 visas en sammanställning av medelvärdet för samtliga verksam-heter samt p-värdet.
Tabell 2. Enkätresultat.
Hypo- tes/Sce-nario
Verksam-het Variabel Medelvärde P-värde Enkät 1 H1S1 1 Tr 7,1 0,84 2 Ti + Sä 6,6 H2S2 3 Tr + Ti 5,4 0,15 4 Tr + Sä 6,5 H1S3 1 Tr 6 0,00007 2 Ti + Sä 7,5 H2S4 3 Tr + Ti 5,9 0,004 4 Tr + Sä 7,6 Enkät 2 H2S1 3 Tr + Ti 5,2 0,15 4 Tr + Sä 6,3 H1S2 1 Tr 4,9 0,58 2 Ti + Sä 5,7 H2S3 3 Tr + Ti 5 0,04 4 Tr + Sä 6,3 H1S4 1 Tr 4,4 0,005 2 Ti + Sä 5,8
Tr=Transparens, Ti=Tid, Sä=Säkerhet.
Nedan i tabell 3 visas en sammanställning av båda enkäternas medelvärden för de olika variabelkombinationerna.
Tabell 3. Totala medelvärde för variabelkombinationer.
Variabel Tr Ti+Sä Tr+Ti Tr+Sä
Medelvärde 5,6 6,4 5,4 6,7
Tr=Transparens, Ti=Tid, Sä=Säkerhet.
Nedan i tabell 4 visas skillnaden i variabelkombinatationernas medelvärde för de olika åldersgrupperna samt p-värdet.
Tabell 4. Medelvärde för variablelkombinationerna i de olika åldersgrupperna. Åldersfördelning Tr Ti+Sä Tr+Ti Tr+Sä
29 och yngre 6,1 7,0 6,4 6,8
30 och äldre 4,9 5,8 4,8 6,3
P-värde 0,00161 0,00197 0,00001 0,20783 Tr=Transparens, Ti=Tid, Sä=Säkerhet.
21 Intervjuresultat
Vi genomförde totalt tio intervjuer med en snittlängd på cirka tio minuter. Respon-denterna var fem kvinnor och fem män och samtliga har en pågående eller avslutad eftergymnasial utbildning. Intervjurespondenterna var i åldrarna 23 till 27 år. Intervjuresultaten kommer att presenteras i samband med analysen av de olika hy-poteserna i analysavsnittet.
Under intervjuerna visade det sig att flera av respondenterna ansåg att en hemsidas design har stor påverkan på förtroendet. Vår studie syftade inte till att undersöka hur hemsidors design påverkar förtroende och variabeln var således inte inkluderad i enkäterna. Därmed utesluts detta ur analysavsnittet. Vi anser att de tankar som respondenterna presenterade är mycket intressanta och kommer därför presentera citat från intervjuerna nedan. Detta för att diskutera hemsidors design i diskussions-avsnittet.
“Om du tänker dig att ett företag som verkar befinna sig i 93 jämför med 2018 vilken skulle du lita på när det gäller GDPR. Det är klart att dem som känns uppdaterade ger förtroende genom det.” Respondent 8 “Jag lämnar bara ifrån mig personuppgifter på hemsidor som jag kän-ner mig trygg skulle aldrig slänga runt mina personuppgifter hur som helst. Jag skulle inte lämna ut mina personuppgifter till en shady hem-sida där jag inte känner till varumärket.” Respondent 9
ANALYS
Analysavsnittet är uppdelat i de fyra olika scenarierna som användes vi enkätut-formningen. I varje scenario presenteras medelvärdena för de fyra olika verksam-heterna för att sedan analysera resultatet med hjälp av intervjuerna. Analysavsnit-tet avslutas med att jämföra skillnaden mellan medelvärdena hos de olika ålders-grupperna.
Scenario 1 - Insamling
H1S1; Enkät 1: En verksamhet som vid insamlingen av personuppgifter transpa-rent beskriver anledningarna till varför insamlingen sker och hur behandlingen går till kommer skapa ett större förtroende än verksamheter som fokuserar på säkerhet och tid.
I tabell 5 presenteras medelvärdet för verksamheterna som arbetar med transparens respektive tid+säkerhet vid insamling av personuppgifter. Verksamheten som arbe-tar med transparens fick medelvärdet 7,1 medan verksamheten som arbearbe-tar med tid+säkerhet fick medelvärdet 6,6. Detta indikerar att H1S1 stämmer, men variabeln transparens är bara 1,08 gånger högre än tid+säkerhet. P-värdet på 0,84 betyder att resultatet inte är statistiskt säkerställt.
22 Tabell 5. Sammanställning av hypotesresultat.
H1S1=Hypotes 1/ Scenario 1.
H2S1; Enkät 2: En verksamhet som transparent beskriver anledningarna till var-för de samlar in personuppgifter och vidtar säkerhetsåtgärder var-för att skydda kun-dens identitet vid insamlingen kommer skapa större förtroende än en verksamhet som tydligt beskriver anledningarna till varför de samlar in personuppgifter och fokuserar på en snabb och effektiv process.
I tabell 6 presenteras medelvärdet för verksamheterna som arbetar med transpa-rens+tid respektive transparens+säkerhet vid insamling av personuppgifter. Verk-samheten som arbetar med transparens+tid fick medelvärdet 5,2 medan verksam-heten som arbetar med transparens+säkerhet fick medelvärdet 6,3. Detta indikerar att H2S1 stämmer, men variabeln transparens+säkerhet är bara 1,2 gånger högre än transparens+tid. P-värdet på 0,15 betyder att resultatet inte är statistiskt säkerställt. Tabell 6. Sammanställning av hypotesresultat.
H2S1=Hypotes 2/ Scenario 1.
Jämför man båda enkäternas svar inom scenariot insamling kan vi se att transparens som enskild variabel fick högst medelvärde under området “insamling”. Det visar att kunder har högre förtroende för verksamheter som tydligt redogör för hur och varför de hanterar deras personuppgifter än för verksamheter som arbetar snabbt och med stort fokus på säkerhet vid insamlingen. Detta stämmer överens med Morey m.fl. (2015) som skriver att förtroende förstärks genom att en verksamhet arbetar transparent och förklarar hur de använder, hanterar och skyddar kundens personuppgifter. Intervjuerna stärker detta då det råder konsensus hos responden-terna att villkoren som måste godkännas vid registrering ska vara enkelt och tydligt formulerade.
“Vara öppna med vad datan ska användas till och skriva tydligt i avta-len och inte i en 40 sidor lång text.” Respondent 1.
“Informationen om hur uppgifterna används ska inte vara gömt i något långt avtal man aldrig har tid att läsa igenom när man ska handla något på internet.” Respondent 3.
Hypotes/
Scenario Verksamhet Variabel Medelvärde
P-värde H1S1 1 Transparens 7,1 0,84 2 Tid + Säkerhet 6,6 Hypotes/
Scenario Verksamhet Variabel Medel-värde P-värde
H2S1
3 Transparens + Tid 5,2
0,15
4 Transparens +
23
“Informationen är ofta för otydlig och det krävs för mycket av en som kund. Jag ska inte behöva söka upp all information. informationen ska vara tydlig och det ska vara enkelt att ta sig igenom den.”
Respondent 7
“Jag gillar verkligen transparens jag vill veta exakt vad dem har gjort med dem och om dem har delat dem med någon annan och vem i så fall. jag vill veta att dem har förvarats säkert enligt någon standard antag-ligen.” Respondent 8.
“Något som kan öka förtroendet är när man accepterar användarvill-kor, det ska vara väldigt enkelt och tydligt vad kärnan av villkoren fak-tiskt handlar om sen så kan “fikon texten” komma efter om man vill grotta ner sig i det. Det skulle kunna räcka med 5 punkter.” Respondent 9.
Att transparens som enskild variabel fick högst medelvärde av enkäternas samtliga kombinationer finner vi intressant. Då en kombination av transparens+säkerhet bör vara det som skapar störst förtroende. Detta då tidigare forskning visar på att både transparens och säkerhet har en positiv påverkan på förtroende.
Scenario 2 - Registerutdrag
H1S2; Enkät 2: En verksamhet som transparent beskriver anledningarna till var-för de behandlat och hur de behandlat personuppgifter kommer skapa större var- för-troende än verksamheter som enbart fokuserar på en säkerhet och snabb behand-ling vid förfrågningar gällande personuppgifter.
I tabell 7 presenteras medelvärdet för verksamheterna som arbetar med transparens respektive tid+säkerhet vid förfrågan om registerutdrag. Verksamheten som arbetar med transparens fick medelvärdet 4,9 medan verksamheten som arbetar med tid+sä-kerhet fick medelvärdet 5,7. Detta indikerar att H1S2 inte stämmer, men variabeln tid+säkerhet är bara 1,16 gånger högre än transparens. P-värdet på 0,15 betyder att resultatet inte är statistiskt säkerställt.
Tabell 7. Sammanställning av hypotesresultat.
H1S2=Hypotes 1/ Scenario 2.
H2S2; Enkät 1: En verksamhet som transparent beskriver anledningarna till var-för och hur de behandlat personuppgifter samt arbetar med att skydda kundens personuppgifter kommer skapa större förtroende än en verksamhet som strävar ef-ter en snabb behandling samt transparent beskriver anledningarna till varför och hur de behandlat personuppgifter.
Hypotes/
Scenario Verksamhet Variabel Medelvärde P-värde
H1S2
1 Transparens 4,9
0,15
24
I tabell 8 presenteras medelvärdet för verksamheterna som arbetar med transpa-rens+tid respektive transparens+säkerhet vid förfrågan om registerutdrag. Verk-samheten som arbetar med transparens+tid fick medelvärdet 5,4 medan verksam-heten som arbetar med transparens+säkerhet fick medelvärdet 6,5. Detta indikerar att H2S2 stämmer, men variabeln transparens+säkerhet är bara 1,20 gånger högre än transparens+tid. P-värdet på 0,58 betyder att resultatet inte är statistiskt säker-ställt.
Tabell 8. Sammanställning av hypotesresultat.
H2S2=Hypotes 2/ Scenario 2.
Jämförs enkäternas medelvärde inom scenariot registerutdrag får variabelkombi-nationen transparens+säkerhet högst medelvärde och näst högst fick tid+säkerhet kombinationen. Den gemensamma nämnaren för dessa variabelkombinationerna är säkerhet, vilket tyder på att säkerhet har en betydande påverkan på förtroendet, vil-ket går i linje med Suh & Han (2014) som beskriver att säkerhet är en ständig oro vid e-handel. Implementationen av teknologiska säkerhetsåtgärder på en hemsida kan resultera i minskad oro och ökat förtroende eftersom webbplats då uppfattas som mer säker (Pavlou, 2003; Holsapple & Wu 2008; Jarvenpaa & Tractinsky, 1999).
Ett återkommande tema under intervjuerna är säkerhet och därmed stärker intervju-underlaget bilden av att den upplevda säkerheten har en betydande påverkan på kunders förtroende.
“Jag tycker att om man identifierar sig med BankID så vet man att det bara är jag som får den informationen, skickar man ett mail kan det vara vem som helst.” Respondent 2
“Dom som har utvecklat BankID har hög legitimitet. Det är ju storban-kerna som har fixat det här för att det ska vara tryggt och säkert, det är ju de main purpous med hela BankID. Så för min del implementera det så gått det går när det handlar om känslig information.” Respondent 9 Att transparens som enskild variabel får lägst medelvärde i detta scenario kan bero på att konsumenter har en rädsla för att deras personuppgifter kan lämnas ut till fel personer. För att en verksamhet ska skapa förtroende när de skickar ut personupp-gifter vid en förfrågan räcker det inte med att transparent berätta hur behandlingen går till, utan det är viktigare att säkerställa identiteten av individen som genomför förfrågan.
“BankID säkerställer vem jag är helt enkelt. Det ser jag som väldigt viktigt att de inte lämnar ut uppgifterna till fel person. Alla företag nu med GDPR verkar krisa med hur man ska genomföra själva Hypotes/
Scenario Verksamhet Variabel Medelvärde P-värde
H2S2
3 Transparens + Tid 5,4
0,58
4 Transparens +