Blockkedjetekniken inom de
svenska hälso- och
sjukvårdssystemen
The blockchain technology within
the Swedish healthcare sector
Kristoffer Szilagyi
Carl Glennfalk
Informatik Kandidatnivå 13 hp VT 2018SAMMANFATTNING
Sverige är ett av de mest framträdande digitaliserade länderna inom EU. Men vissa sektorer har hamnat efter i digitaliseringsprocessen, en av dem är
sjukvården. Sjukvården är en av de mest informationsintensiva sektorerna i det svenska samhället, det är kritiskt att IT-systemen är sammanhållna och
kommunicerande med varandra, s.k. interoperabla. Just där brister sjukvårdens IT-system idag, men sjukvården som organisation brister också i att ha någon form av enhetlig standard för hur vårdinformation ska dokumenteras. Dessa brister leder till försämrad vårdkvalitet och arbetsmiljö för vårdpersonalen. Syftet med denna studie är att utveckla en artefakt för hur blockkedjeteknikens egenskaper kan användas för att förbättra interoperabiliteten i de svenska hälso- och
sjukvårdssystemen. Vi har genomfört studien med en designbaserad metod, där vi tar fram en modell baserat på blockkedjans egenskaper och presenterade problem utifrån sex intervjuer av personer som arbetar med IT i vården. Vårt resultat visar att blockkedjan har egenskaper som kan stödja interoperabilitet i sjukvården. Resultatet visar också det krävs en balans mellan säkerhet och flexibilitet samt någon form av standard för hur vårdinformation ska dokumenteras, antingen på nationell eller regional nivå, för att skapa interoperabilitet.
NYCKELORD
Artefakt, Blockkedjetekniken, E-Hälsa, Hälso-informatik (HIT), Interoperabilitet, Patientcentrerad vård, Sjukvård
ABSTRACT
Sweden is one of the most prominent digitized countries within the European Union. But some sectors have fallen behind in the digitizing process; one of them is the healthcare sector. The healthcare sector is one of the most information intensive fields in the Swedish society, where it is critical that the IT-systems are integrated and communicative with each other, so-called interoperable. Today's IT systems in healthcare are failing in terms of interoperability, but the healthcare itself as an organisation also fails to have some sort of uniform standard for documenting health data. These deficiencies lead to an impaired quality of care for the patients but also a worsened environment for the healthcare professionals. The purpose of this study is to develop an artefact for how the capabilities of the blockchain technology can be used to improve interoperability within the Swedish healthcare systems. We’ve conducted this paper by using a design-science based method, where we have developed a model based on the capabilities of
blockchain technology and issues presented based on interviews with six people working with IT within healthcare. Our findings show that the blockchain
technology has capabilities that can support interoperability within the healthcare systems. Our findings also show that to achieve interoperability there is a need to balance security and flexibility as well as some form of unified standard for how healthcare data is to be documented, on either a national or regional level. KEYWORDS
Artefact, Blockchain technology, e-Health, Healthcare, Health Informatics (HIT), Interoperability
FÖRORD
Vi vill tacka alla inblandade som har varit med och bidragit till denna studie. Vi vill framförallt tacka våra respondenter som tog sig tid att ställa upp på intervjuer och svara på våra frågor, utan er hade ej denna studie varit möjlig, tack! Sist men inte minst vill vi rikta ett stort tack till vår eminenta handledare Carl-Johan Orre för hans stöd och ledning i vått och torrt under studiens gång.
1. INLEDNING
1.1 BakgrundSverige är ett av EU:s mest digitaliserade länder (EU, 2017). Enligt Vismas (2016) digitaliseringsindex är den mest digitaliserade branschen offentlig
förvaltning (52%) tätt följt av finans- och försäkringsverksamhet (48%). Men det finns vissa sektorer som inte har tagit del av digitaliseringens fördelar fullt ut. Trots att vård och omsorg är en av de mest informationsintensiva sektorerna i det svenska samhället (Socialstyrelsen, 2010), hamnar den bara på en elfteplats i Visma digitaliseringsindex (38%) (Visma, 2016). Enligt en oberoende undersökning som konsultföretaget McKinsey (2016) utfört gällande digital teknik i den svenska vården är en viktig del av arbetet att integrera en vårdkedja mellan patienter och vårdgivare i kommuner och landsting. För att öka samverkan och informationsutbyte krävs det sammanhållna och kommunicerande IT-system. Hur väl IT-system kan samverka och kommunicera med varandra kan förstås med begreppet interoperabilitet1.
Sverige är uppdelat i 21 självstyrande landsting som själva tar beslut om vilka IT-system de vill upphandla och använda sig av. Sellberg & Eltes (2017) beskriver de olika landstingens nuvarande system som mindre ekosystem av tjänster som utgör en installerad bas2 i det nationella ekosystemet av IT-tjänster. För att öka samverkan nationellt och mellan landsting bildades företaget Inera vars syfte är att utveckla gemensamma lösningar för landsting och regioner (Inera, 2017). Målet är att utveckla regionernas installerade bas så de kan utgöra kärnkomponenter i den nationella infrastrukturen (Sellberg & Eltes, 2017). En av de främsta
utmaningarna är för att göra detta är att skapa interoperabilitet (SKL, 2017; Inera, 2016). I arbetet mot interoperabilitet och en integrerad vårdkedja har Regeringen beslutat att Vinnova i samverkan med e-Hälsomyndigheten ska ta fram och förvalta ett ramverk för hur IT i vården ska bedrivas som landstingen kan förhålla sig till (Näringsdepartementet, 2016). Detta ska leda till patientdata,
friskvårdssdata, data från biobanker etc. ska kunna kopplas ihop på ett säkert och fungerande sätt och fungera som stöd för vårdpersonal (Näringsdepartementet, 2016).
Trots dessa insatser visar Sveriges Yngre Läkares Förenings (SYLF)
undersökning om IT-stöd i vården att 83% av deltagarna är missnöjda med de nuvarande IT-systemen (SYLF, 2016). Omställningen till digital vårdinformation har inte medfört den arbetseffektivisering många i verksamheterna hade förväntat sig, eftersom IT-systemen inte har tillräckligt med stöd för den interoperabilitet som krävs (Vårdanalys, 2016). Digitalisering av journaler och olika administrativa system inom sjukvården har skapat många integrationsproblem samt svårigheter att förena sekretess, effektivitet och användarvänlighet (Olsson & Kempe, 2017). På grund av otillgänglighet av information behöver vårdpersonal ofta
dokumentera data som redan finns någon annanstans, s.k. dubbeldokumentation
1 Den förmåga hos system, organisationer eller verksamhetsprocesser att fungera tillsammans och
kunna kommunicera med varandra genom att överenskomna regler följs (Socialstyrelsen, 2017).
2 Omfattar inom hälso- och sjukvården journalsystem, medicinska avdelningar, olika grupper av
yrkesgrupper som användare (sjuksköterskor, kliniker), dispenseringsmetoder, föreskrifter etc. (Aanestad, Grisot, Hanseth & Vassilakopoulou, 2017).
(SYLF, 2016; Vårdanalys, 2016). Det ökar risken för att viktig information inte uppmärksammas vilket kan leda till försämrad vårdkvalitet (Vårdanalys, 2016). Ett land som ses i framkant inom digitaliserad vård är Estland (e-Hälsa, u.å). Sedan 2012 har de använt blockkedjetekniken3 som en del i deras nationella e-hälso-infrastruktur (e-estonia, u.å). Implementeringen av blockkedjan har möjliggjort för offentliga instanser, vårdgivare och invånare att dela all relevant medicinsk data över organisationsgränser (Mettler, 2016). I svensk kontext har blockkedjan beskrivits som en teknik vilken kan förändra landsting och regioners verksamheter (Inera, 2017; Inera, 2018a). Das (2017) beskriver hur blockkedjan kan lösa flera tekniska utmaningar inom sjukvården, däribland teknisk
interoperabilitet, integritet och säkerhet samt portabel användar-ägd data. Det är en teknik vars tillämpningsområden inom den svenska sjukvårdens IT-system Olsson & Kempe (2017) diskuterar. Olsson & Kempe (2017) menar att blockkedjetekniken kan vara en möjlig infallsvinkel mot interoperabilitet, integrerad vårdkedja och verifiering av äkthet i dokument som remisser och journaler samt säkerställandet av behörigheter och certifieringar inom den svenska sjukvården.
1.2 Problemdiskussion
I SYLFs undersökning visade det sig att 93% av de tillfrågade läkarna vill ha tillgång till
patientöversikt med en summering av patientens medicinska historik (SYLF, 2016). I samma undersökning beskriver en deltagare hur det måste läggas mer kraft på att få IT-systemen att kommunicera med varandra, kunna hämta data från varandra och varna ifall det finns motstridiga uppgifter inom systemen (SYLF, 2016). Trots omfattande satsningar, i form av nationella ramverk, som har gjorts för IT inom vården så har man inte nått hela vägen fram.
Olsson & Kempe:s (2017), Randall, Goel & Abjamra:s (2017) och Mettler:s (2016) infallsvinkel mot interoperabilitet via blockkedjetekniken fokuserar starkt på individen som en unik identifierare i nätverket och gemensam nämnare i det nationella register som finns för data som lagras. Detta är i linje vad Regeringen önskar att se i sitt ramverk och framtida vårdsystem - en integrerad vårdkedja och interoperabla IT-system med individ och behovsägare i centrum
(Näringsdepartementet, 2016). Bättre integrerade och interoperabla system skulle leda till mindre administrativt arbete, eliminera dubbeldokumentation och
underlätta samverkan mellan olika huvudmän i sjukvården. Det skulle ge
vårdpersonal möjligheter för att spendera mer tid på att behandla patienter vilket skapar förutsättningar för en ökad vårdkvalitet. Det är tydligt att det finns stora vinster i att förbättra interoperabiliteten inom de svenska hälso- och
sjukvårdssystemen.
1.3 Problemformulering och syfte
Inera beskriver att blockkedjetekniken har egenskaper med förutsättningar att kunna förändra verksamheter inom landsting och regioner. Tidigare forskning har kommit fram till att blockkedjetekniken har egenskaper för att skapa
interoperabilitet mellan system. Men det är ingen av dem som beskriver hur
3 En distribuerad och decentraliserad databas över ett nätverk, där nätverket automatiskt verifierar
blockkedjetekniken skulle kunna användas för att förbättra interoperabiliteten inom de svenska hälso- och sjukvårdssystemen.
Syftet är att utveckla ett förslag för hur blockkedjeteknikens egenskaper kan användas för att förbättra interoperabiliteten inom de svenska hälso- och
sjukvårdssystemen.
För att besvara syftet behandlar vi följande frågor:
Vilka egenskaper i blockkedjetekniken kan stödja interoperabilitet?
Vad krävs för att förbättra interoperabiliteten inom de svenska hälso- och sjukvårdssystemen?
1.4 Målgrupp
Undersökningen riktar sig främst mot beslutsfattande personer eller organisationer som arbetar med utveckla de svenska hälso- och sjukvårdssystemen. Våra
förhoppningar med studiens resultat är att inspirera beslutsfattare inom utvecklingsarbetet i framtiden.
1.5 Avgränsningar
Studien kommer att behandla de svenska hälso- och sjukvårdssystemen och blockkedjans egenskaper på en relativt abstrakt nivå. Vi gör ingen teknisk
fördjupning av blockkedjan eller i IT-systemen inom sjukvården. Det leder till att resultatet kommer att vara relativt abstrakt och inte ett exakt lösningsförslag som möjliggör implementation direkt efter studien.
1. 6 Disposition
I avsnitt 2 genomför vi en litteraturstudie för att identifiera blockkedjeteknikens egenskaper som kan stödja interoperabilitet. Metodkapitlet behandlar vårt tillvägagångssätt och studiens forskningsprocess. I nästkommande avsnitt utvecklar vi och designar en artefakt utifrån de identifierade egenskaperna från avsnitt 2 som vi anser kunna användas för att förbättra de svenska hälso- och sjukvårdssystemen. I avsnitt 5 presenteras våra genomförda intervjuer där vi identifierar vad som krävs för att skapa interoperabilitet inom sjukvården. I avsnitt 6 demonstrerar vi artefakten genom att analysera artefaktens egenskaper med resultaten från intervjuerna för att avslutningsvis vidareutveckla artefakten och sedan kritiskt diskutera den. I det avslutande avsnittet för vi en slutgiltig diskussion kring vårt resultat och slutsatser.
2. LITTERATURGENOMGÅNG
2.1 Relaterad forskning - BlockkedjeteknikenBlockkedjetekniken har fått global medial uppmärksamhet de senaste åren
(Pilkington, 2015). I medier beskrivs tekniken potentiellt ha lika revolutionerande effekt på informationsåldern som internet och world wide web hade på 90-talet
(Mettler, 2016). Blockkedjetekniken är främst förknippad med kryptovalutor (Das, 2017). Men det diskuteras och undersöks friskt andra användningsområden för tekniken, där ibland sjukvården och hälsoinformatik. I arbetet mot mer intelligenta IT-system inom vården och i en värld där konsumenters kontroll och integritet av data värderas allt högre kan blockkedjan ha en betydande roll. Det finns inte till vår vetskap en formell definition av tekniken, däremot finns det ett flertal olika beskrivningar om vad blockkedjan som teknik är. En sammanfattande beskrivning är:
Blockkedjan är en distribuerad, transparent och oföränderlig liggare för att registrera transaktioner där transaktionerna är tidsstämplade, krypterade och sker mellan parter på ett anonymt och ett säkert decentraliserat nätverk utan en traditionell mellanhand (IBM, 2016; ISO/TC, 2016; Swan, 2015; Mettler, 2016, Azaria, Ekblaw, Viaro & Lippman, 2016; Randall et al., 2017).
Mettler (2016) och Angraal, Krumholz & Schulz (2017) beskriver i sina artiklar olika informationstekniska mål och utmaningar som sjukvården står inför och hur blockkedjan kan vara en del av lösningen. Randall et al. (2017), Angraal et al. (2017) och Mettler (2016) menar att blockkedjan har potential att förändra hälsoinformatik (HIT) och beskriver hur blockkedjan kan bidra med
kostnadsbesparingar, säkerhet och interoperabilitetslösningar. Exempelvis kan olika behörighetsnivåer kontrolleras på blockkedjan vilket kan frigöra mycket tid som går åt administrativa uppgifter (Randall et al., 2017; Mettler, 2016).
Yue, Wang, Jin, Li & Wiang (2016) och Mettler (2016) beskriver hur en decentraliserad databas som inte ägs av någon men kontrolleras av alla och ständigt är uppdaterad kan ha stor positiv påverkan för sjukvården och olika typer av vårdgivare, ett argument som Randall et al. (2017) stödjer. Mettler (2016) exemplifierar bl.a. blockkedjans potentiella värde för sjukvården med hjälp av företaget Gem4 som har utvecklat en distribuerad nätverksinfrastruktur där olika vårdgivare har tillgång till samma information. Gems nätverk skapar ett
ekosystem inom sjukvården som inkluderar företag, individer och vårdspecialister. Samtidigt som en patientcentrerad vård främjas, skapas interoperabilitet inom och över organisationsgränser.
Beslut som tas inom sjukvården gällande en patient är i princip alltid påverkade av tidigare händelser som patienten har stått inför. Peterson, Deeduvanu,
Kanjamala & Boles (2016) menar att det arbetssättet passar bra in i
blockkedjestrukturen eftersom där är identiteten hos en aktuell händelse påverkad av en tidigare händelse. Vidare argumenterar Peterson et al. (2016) för vilken roll blockkedjan kan fylla inom sjukvården och menar att den inte endast kan stödja interoperabilitet men även de säkerhetsmässiga krav som ställs på datan
sjukvården hanterar.
Yue et al. (2016) beskriver i sin artikel en systemprototyp byggd med
blockkedjetekniken som tillåter patienten att kontrollera och dela sin data enkelt och säkert utan att äventyra patientens integritet. Azaria et al. (2017) har också tagit fram en prototyp baserat på blockkedjetekniken - MedRec. MedRec är ett decentraliserat system för att hantera journaler där patienter har tillgång till deras hälsodata över olika organisationsgränser.
2.1.1 Blockkedjan för interoperabilitet
Das (2017) menar att den mest fundamentala rollen blockkedjan kan ha är att möjliggöra krypterade säkra, spårbara och oåterkalleliga överföringar av data mellan olika parter. Vilket kan leda till sömlös tillgång till historisk data men även realtidsdata. Den sömlösa tillgången till historisk data är en viktig aspekt som även Peterson et al. (2016) tar upp för att kunna skapa interoperabilitet. Varje dator som är uppkopplad på blockkedjenätverket kallas en nod, varje nod har all information, en kopia, av alla tillgångar som har överförts på nätverket. Det är på grund av det decentraliserade nätverket där alla har en kopia av databaserna det enkelt går att söka efter data och på så sätt främja teknisk interoperabilitet. Enklare tillgång till data kan även öka effektivitet och därmed minska administrativa kostnader (Azaria et al., 2016). Randall et al. (2017) skriver likt Peterson et al. (2016) hur blockkedjetekniken kan användas för att främja interoperabilitet och automatisk strukturering av data från olika system, vilket är kritiskt i ett ekosystem av IT- och källsystem. De beskriver också att tekniken kan möjliggöra en integrerad vårdkedja från olika vårdgivare. Datan som finns på blockkedjan kan komma från olika källor oavsett system, utifrån entydig och överenskommen mening av hur datan ska kombineras och uppdateras. För att blockkedjan ska uppdateras krävs det någon form av konsensus över nätverket att uppdateringen är valid. Kan datan kombineras med den redan existerande datan kan den ses som valid (eftersom den är entydig och har överenskommen mening enligt nätverket) vilket i sin tur kan stödja en semantisk interoperabilitet.
2.1.2 Konsensus
Konsensusen för hur blockkedjan ska uppdateras och struktureras är grunden för hur deltagarna inte behöver ha tillit till varandra utan endast till systemet i sig (Crosby, Nachiappan, Pattanayak, Verma & Kalyanaraman, 2016). Detta innebär att användare av blockkedjan inte behöver ha förtroende för en
transaktionsmotpart eller en tredjepartsförmedlare (exempelvis en bank), utan kan istället lita på blockkedjan och nätverket. Datan på blockkedjan är digitalt
signerad (med ett hashvärde5) med en unik adress kopplat till sig och sammansätts sedan till grupper, s.k. block. Varje block innehåller data om det tidigare blocket i kedjan. Ett block läggs endast till på kedjan ifall det verifieras giltigt utifrån de konsensusregler som råder över nätverket. På grund av att varje block innehåller data om det tidigare blocket formar de en kronologisk och linjär kedja och kan ej manipuleras (Swan, 2015; Angraal et al., 2017).
2.1.3 En integrerad vårdkedja med MPI
Blockkedjetekniken använder sig av publik nyckel-infrastruktur för kryptering, autentisering och signering av data (Das, 2017). Blockkedjan i sin natur innehåller “Master Patient Identifier” (MPI) (Randall et al., 2017). MPI är den adress datan har som möjliggör dess spårbarhet och hopkoppling av datan. Blockkedjan kan främja en sömlös och integrerad vårdkedja med patienten i centrum med hjälp av en MPI (Mettler, 2016; Randall et al., 2017; Yue et al., 2016). Den personliga identifikationen ligger inte på blockkedjan, utan istället en kopia av den medicinska datan. För att koppla ihop datan är det adressen man är ute efter (publika och privata nycklar).
Eftersom datan är publik men anonym kan en forskare samla data om ett specifikt sammanhang samtidigt som patientens integritet inte äventyras. Med denna MPI-egenskap blockkedjan har, kan det skapas en mer patientcentrerad vård och transparent data som flera medicinska intressenter har tillgång till (Randall et al., 2017). Där patienten endast kan identifieras med hjälp av sina nycklar och samtycke mellan patient och vårdgivare.
Randall et al. (2017) argumenterar för hur en MPI kan bidra till en mer
patientcentrerad samt skalbar hälsovård över organisationsgränser. Ett exempel på ett land som använder blockkedjetekniken och en MPI i sin
hälsovårdsinfrastruktur är Estland (Mettler, 2016; e-Estonia, u.å; Azaria et al., 2017). Estland samarbetar med det nederländska säkerhetsföretaget Guardtime6
och har tillsammans utvecklat ett blockkedjebaserat system för att validera patienters identitet (e-Estonia, u.å, Mettler; 2016). I Estland har alla invånare ett smart kort som länkar deras elektroniska journal med deras blockkedje-identitet där varje uppdatering i journalen registreras på blockkedjan (Angraal et al., 2017). Estland har på så sätt skapat ett mer patientcentrerat och interoperabel
vårdinfrastruktur.
2.1.4 Behörighetsbaserad blockkedja och logiska instruktioner
Det finns olika typer av blockkedjor och de skiljer sig bland annat åt hur
behörigheten på nätverket ter sig (Monax, 2018a). I vilken grad behörigheten är begränsad påverkar i sin tur vilka som får utfärda s.k. smart contracts samt vilka som får delta i konsensus-mekanismen. Behörigheten kan ses som ett spektrum. Där ena sidan av spektrumet är öppet vilket innebär att alla får delta i konsensus-mekanismen (se Bitcoin7 & Etherum8) och på den andra sidan får endast en tillförlitlig/utsedd grupp delta, vilket kan vara mer passande för en statlig organisation. Vilken sida av spektrumet nätverket placerar sig på innebär avvägningar gällande skalbarhet, effektivitet och säkerhet (Mattila, 2016). Namnet smart contracts är lite missvisande då kontrakten varken är smarta eller i själva verket är ett juridiskt kontrakt. Vi kallar dem hädanefter logiska
instruktioner. De logiska instruktionerna är skript som körs på blockkedjan för att
utföra vissa uppgifter givet att vissa villkor är uppfyllda (Monax, 2018b). Skripten måste vara synliga, exekverbara, kontrollerbara samt vara i intresse för nätverket för att ses som giltiga (Monax, 2018b). Instruktionerna kan vara automatiserade, men det kan även skapas nya instruktioner av behöriga deltagare på nätverket för att lösa specifika ändamål (Monax, 2018b).
Logiska instruktioner bidrar med automatisering och spårning av dataöverföring men även tillägg av ny data. Detta öppnar upp för att skapa en automatisk
interoperabilitet för generella användarfall. Exempelvis kan en instruktion vara att spåra och logga patientrelaterade relationer som associeras med medicinsk data med visningsbehörighet och instruktioner för att hämta data. De logiska
instruktionerna kan därmed eliminera behovet av en mellanhand för att utföra en transaktion mellan två parter. Eftersom behörighetsnivån på blockkedjan kan
6 https://guardtime.com/ 7 https://bitcoin.org/bitcoin.pdf
8 http://www.theblockchain.com/docs/Ethereum_white_papera_next_generation_smart_
påverka vem som får skapa logiska instruktioner kan det i sin tur påverka nivån av interoperabilitet över nätverket.
2.2 Blockkedjans interoperabilitetsstödjande egenskaper
Forskningen visar att blockkedjetekniken har egenskaper för att fylla flera roller i arbetet mot interoperabilitet i vårdens IT-system. Tekniken möjliggör ett säkert och distribuerat register som kan uppdateras och hanteras utan behovet av en central auktoritet. Där registret kontrolleras av ett decentraliserat nätverk och information enkelt kan delas mellan deltagarna med stöd från logiska
instruktioner skapar det möjligheter för interoperabilitet. Forskningen är enig om att teknikens säkerhet och integritet är tillräckligt hög för att uppfylla kraven som ställs på den data som sjukvården hanterar. Med hash- och asymmetriska
krypteringsmetoder skapas förutsättningar för att bibehålla informationens säkerhet, integritet och anonymitet samtidigt som en transparens och spårbarhet kan främjas.
Forskningen anser också att tekniken skapar förutsättningar för att skapa en mer integrerad och sammanhållen vårdkedja vilket är i linje med Ineras vision. Sammanfattningsvis verkar blockkedjetekniken ha potential för att ha en roll i lösningen av de interoperabilitetsproblem som finns inom de svenska
sjukvårdssystemen. Det är ovanstående egenskaper som ligger till grund för design och utveckling av vår artefakt (se avsnitt 4) för hur interoperabiliteten kan förbättras inom de svenska hälso- och sjukvårdssystemen.
3. METODOLOGI
3.1 Metodisk ansatsVårt val av metodisk ansats står i relation till vårt syfte och de forskningsfrågor vi behandlade. Vi valde en kvalitativ ansats, vilket enligt Mason (2002) i kontrast till en kvantitativ tillåter forskaren att skapa djupa, komplexa och rika uppfattningar om verkligheten. Vidare beskriver Mason (2002) hur en kvalitativ
forskningsansats understryker vikten av att undersöka sammanhang på djupet. En kvalitativ metod är mer flexibel i kontrast till kvantitativ och möjliggör insamling av mer rik och mjuk data i motsats till en kvantitativ metod som genererar hård data.
Vi samlade in data för att undersöka vad som krävs för att skapa interoperabilitet inom ett så komplext område som de svenska hälso- och sjukvårdssystemen. För att se ifall blockkedjans egenskaper kan användas för att förbättra systemen innebar det att vi behövde skapa oss en djup förståelse för IT inom sjukvården. Vi behövde därmed djupa och rika svar och redogörelser för hur det dagliga arbetet bedrivs samt hur IT fungerar som verktyg för att stödja verksamheterna. Vi behövde få svar på hur- och varför-frågor. Således lämpade sig en kvalitativ forskningsansats för vår studie. Med det inte sagt att vårt resultat inte kan vara generaliserbart, däremot måste generaliseringarna ske med stor varsamhet. När både en induktiv och deduktiv ansats används kallas detta för en iterativ ansats (Bryman, 2011). Vi uppmärksammade i vår förstudie att det finns problemområden inom de svenska hälso- och sjukvårdssystemen och även att
blockkedjan beskrivs ha potential att förbättra systemen. Vi utgick från dessa problemområden för att komma fram till vårt syfte och våra forskningsfrågor vilket innebar att vi använt oss av en deduktiv ansats. För att komplettera vår kunskap inom sjukvårdssystemen och bilda en djupare förståelse genomförde vi intervjuer vilket innebär att vi även använt oss av en induktiv ansats. Vi gick fram och tillbaka mellan litteratur och empiri för att kunna utveckla ett förslag för hur blockkedjans egenskaper kan användas till att förbättra interoperabilitet inom de svenska hälso- och sjukvårdssystemen och ansåg därför att en iterativ ansats var lämpligast.
3.2 Design-baserad forskning
Designbaserad forskning är en forskningsmetod vars popularitet har ökat markant det senaste årtiondet inom IT-fältet (Peffers, Tunamen, Rothenberger &
Chatterjee, 2007). Hevner, March, Park & Ram (2004, s.77) definierar design-baserad forskning som
”En metod som skapar och utvärderar IT-artefakter som syftar till att lösa ett identifierat organisatoriskt problem.”
Utifrån Hevner et al.:s (2004) definition är metoden lämplig för att besvara vårt syfte då vårt problem är av organisatorisk karaktär, mer specifikt interoperabilitet. En design-baserad forskningsmetod passar för både kvalitativa och kvantitativa tillvägagångssätt (Johannesson & Perjons, 2012). Forskningsprocessen sker iterativt genom en lins av syntetiska och analytiska tekniker och perspektiv (som kompletterar positivistiska, tolkande och kritiska perspektiv) (Johannesson & Perjons, 2012; Vaishnavi, Kuechler & Petter, 2017).
De grundläggande principerna kan sammanfattas som en noggrann process för att utveckla artefakter som löser ett organisatoriskt problem. Detta leder till ett kunskapsbidrag som kommuniceras till ändamålsenlig publik (Johannesson & Perjons, 2012; Peffers et al., 2007). En artefakt kan vara ett fysiskt objekt såväl som abstrakta och immateriella ting som en modell eller en process i ett IT-system (Peffers et al., 2007; Vaishnavi et al., 2017; Johannesson & Perjons, 2012). I vår
studie utgörs artefakten av det förbättringsförslag vi utvecklar och slutligen presenterar i form av en modell.
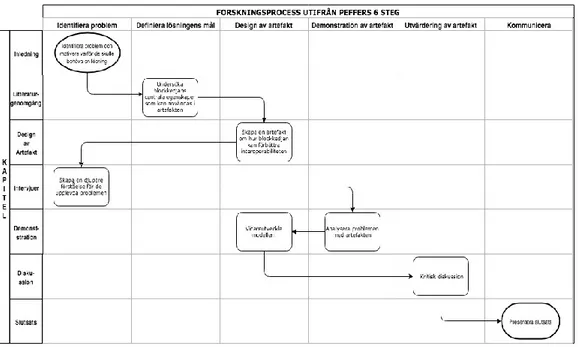
Det råder ingen konsensus för hur metoden skall tillämpas, däremot finns det gemensamma riktlinjer och steg för metodens tillvägagångssätt (Peffers et al., 2007). I vår tillämpning av metoden (figur 1) utgick vi från Design science research model (DSRM) (Peffers et al., 2007). Peffers et al. (2007) beskriver DSRM-processen utifrån sex steg och fyra olika instegspunkter9 beroende på vilka mål som finns med i forskningen. Processen itereras tills man har nått ett tillfredsställande resultat i varje steg i relation till studiens mål (Peffers et al., 2007).
9 Problemorienterad, målorienterad, design- & utvecklingsorienterad och klient-/kontextorienterad
Figur 1. Vår forskningsprocess utifrån Peffers et al.:s (2007) 6 steg
3.2.1 Forskningsrocess - de sex stegen
Vår instegspunkt i DSRM var problemorienterad då vi först identifierade problem genom en grundlig förstudie. Nedan följer en genomgång av Peffers et al.:s (2007) sex steg och hur vi förhöll oss till dem i vår studie.
1. Identifiering av problem och motivation
Peffers et al. (2007) menar att man i detta steg identifierar problem och rättfärdigar värdet av en ny lösning. Vi identifierade flera
interoperabilitets-problem inom de svenska hälso- och sjukvårdssystemen i vår förstudie som visade på behovet av en lösning. Genom att rättfärdiga en lösnings värde skapas två fördelar: det motiverar forskaren och publiken att sträva mot en lösning och det hjälper publiken att förstå hur forskaren resonerar kring problemet och lösningen (Peffers et al., 2007). Vi kom senare tillbaka till detta steg då vi upplevde att vi inte förstod problemens fulla komplexitet. Vi utförde därför intervjuer för att kunna bryta ner problemen på en begreppsmässig nivå samt förstå vad som krävs för att skapa interoperabilitet inom de svenska hälso- och sjukvårdssystemen. Detta skapade förutsättningar för att designa en bättre lämpad artefakt. 2. Definition av mål och krav samt skiss av artefakten
I linje med Peffers et al. (2007) härstammade målen för vår artefakt från de identifierade problemen kombinerat med den insamlade litteratur om
blockkedjeteknikens roll inom HIT. Detta steg handlar om att beskriva hur en ny lösning skulle kunna vara bättre än den nuvarande Peffers et al. (2007). Vi undersökte blockkedjeteknikens egenskaper och varför de kan vara en del av lösningen för nuvarande interoperabilitetsproblem utifrån olika perspektiv. Vår skiss utgjordes av de egenskaper som identifierades att blockkedjetekniken har i avsnitt 2. Teknikens egenskaper använde vi sedan som byggstenar för vår artefakt.
3. Design och utveckling av artefakt
Peffers et al. (2007) menar att denna aktivitet inkluderar att avgöra artefaktens önskade funktionalitet. Vidare menar Peffers et al. (2007) att den artefakt som tas fram kan ha ett inbäddat kunskapsbidrag i sig. Utifrån föregående stegs
definierade krav och skiss vidareutvecklade vi vår artefakt och visualiserar den i form av en modell. Artefakten (se avsnitt 4) visar på förutsättningar för att skapa interoperabilitet på ett säkert vis, dvs. den önskade funktionaliteten. En
funktionalitet som sedan skapar möjligheter för en mer patientcentrerad vård. Det är även artefakten med dess egenskaper som utgör vårt kunskapsbidrag. När vi hade tagit fram vår första artefakt insåg vi att den inte fångade problemens komplexitet. Vi hade inte en tillräcklig mättnad av problemidentifiering, vilket resulterade att vi fick återgå till steg 1.
4. Demonstration av artefakt
Peffers et al. (2007) menar att demonstrationen kan ske i form av experiment, fallstudie, simulering etc. Vår demonstration är någorlunda fallstudie-inspirerad. Vi analyserar och jämför på djupet hur vår artefakt ställer sig mot de problem som vi har identifierat utifrån litteratur och intervjuer. Vi diskuterar här vilka
fördelaktiga effekter artefaktens egenskaper har på problemen, vilket forskarna bör göra i detta steg enligt Peffers et al. (2007). Detta steg avslutades med att vi gick tillbaka till föregående steg för att vidareutveckla artefakten.
5.Utvärdering
Bider et al. (2013) påpekar att när artefaktens effekter utvärderas är det viktigt att även identifiera och utvärdera oavsedda effekter som artefakten ger upphov till. Vidare belyser Bider et al. (2013) vikten av att använda sig av adekvata
forskningsstrategier, vilket bidrar till studiens pålitlighet. Aktiviteten innebär att målen jämförs med en lösning på faktiska observerade resultat från användningen av artefakten (Peffers et al., 2007). Vi tog ett annorlunda tillvägagångssätt som skiljer sig från metodens riktlinjer eftersom vår artefakt är ett förslag för att lösa ett problem. Artefakten är på abstrakt nivå och utanför vår kapacitet att
implementera, vi kan därför inte utvärdera artefakten utifrån Peffers et al.:s (2007) riktlinjer. Vår utvärdering består istället av att kritiskt diskutera hur vi utvecklade vårt förslag, dess rimlighet att lösa de problem vi har identifierat och möjligheten för överförbarhet till andra sammanhang. En grundlig utvärdering utifrån Peffers et al.:s (2007) riktlinje med vår artefakt är en egen studie i sig.
6. Kommunikation
Det sjätte och sista steget är att kommunicera problemet och artefaktens betydelse, nytta och styrka. Kommunikationen ska rikta sig mot forskare och relevanta grupper som kan tänkas ha nytta av materialet (Peffers et al. 2007). Vi kommunicerade vår artefakt till de respondenter vi intervjuade (som önskade att läsa arbetet) och även våra kurskollegor.
3.3 Datainsamling - Intervjuer
Intervjuerna genomfördes i semistrukturerad stil, vilket är en populär intervjustil vid insamling av kvalitativ data menar Bryman (2011). Semistrukturerad intervju
innebär att intervjun utgår ifrån ett frågeschema med allmänt formulerade frågor, i vårt fall bestämda teman. Respondenten får svara fritt på frågorna och berätta sina tankar och erfarenheter med egna ord. De öppna svaren möjliggör även för
intervjuaren att ställa fördjupande följdfrågor för att söka konkreta svar. En semistrukturerad intervju möjliggör för respondenten att prata öppet men tillåter samtidigt intervjuaren att bibehålla en viss nivå av kontroll över intervjun (Bryman, 2011). En nackdel med öppna intervjuer överlag är att de är väldigt tidskrävande gällande transkribering, detta i jämförelse med enkätundersökningar där svaren är enklare att tyda. Vi är dock av åsikten att denna nackdel för med sig en betydande fördel i form av upprepning. Bryman (2011) menar att denna fördel är mest betydande ifall transkriberingen sker direkt efter intervjun är avslutad och informationen ligger färskt i närminnet. I enlighet med Brymans (2011) argument transkriberade vi våra intervjuer direkt efter de avslutades. Detta ger
förutsättningar för enklare upptäckt av nyckelord och mönster i datan som kan vara givande vid bearbetning och analys.
3.3.1 Intervjuguide
Intervjuguiden och temana formulerades utifrån blockkedjeteknikens egenskaper som identifierades i avsnitt 2. Temana som intervjuguiden bestod av var säkerhet,
integritet, spårbarhet, interoperabilitet, utvecklingsarbete och framtiden (se
bilaga 1- Intervjuguide).
3.3.2 Urval av respondenter
När vi kontaktade respondenter beskrev vi kort vad vår undersökning handlade om för att väcka intresse. Vi berättade även att intervjun uppskattningsvis skulle pågå under ca. 40 minuter vilket visade sig stämma med utfallet. Då målet med intervjuerna var att få en djupare förståelse av vad som krävs för att förbättra interoperabiliteten i hälso- och sjukvårdssystemen sökte vi efter personer som arbetar med frågor inom IT och digitalisering. Kravet var att respondenterna på något sätt skulle arbeta med och ha en helhetlig kunskap om de svenska hälso- och sjukvårdssystemen. Vissa av våra respondenter ledde oss vidare till nästa respondent och påverkade på så sätt vårt urval. Vårt urval bestod av vad Bryman (2011) kallar för snöbollsurval som är ett exempel på ett målstyrt urval vilket är lämpligt i kvalitativa studier. Urvalet resulterade till slut i en mix av målinriktat och nätverksurval. Detta är inget som vi anser negativt, snarare motsatsen. Vi blev positivt överraskade när en respondent kunde rekommendera en annan möjlig respondent med god insikt i ämnet. Kvale (1997) menar att en fördel med nätverksurvalet är att respondenten känner sin organisation bättre än vad
forskaren gör, och kan därmed troligtvis föra författaren i rätt riktning mot nästa respondent. Däremot är vi medvetna om att denna mix av urval i sin tur påverkar den insamlade datan och således resultatet. Vårt intervjumaterial består av sex intervjuer varav det var en deltagare på fem av dem. En intervju visade sig bli en gruppintervju där fyra respondenter deltog under intervjun. Av totalt 15
utskickade förfrågningar valde sex intressanta respondenter att ställa upp, de hade följande yrkesroller:
R1 - Digitaliseringsstrateg för landsting 1 och representant för landsting 1 mot Inera.
R3 - Strateg inom hälsoinformatik för samma landsting 1, objektägare för flertalet journalsystem.
R4 - IT-strateg gällande e-hälsofrågor för ett landsting 3
R5 - Gruppintervju med följande roller på Inera: Tjänsteansvarig för NPÖ och Journalen, Objektspecialist NPÖ, IT-specialist med fokus på NPÖ, Verksamhetsspecialist för NPÖ och Journalen
R6 - Arbetar på HIP AB och adjungerad professor i e-hälsa.
Vi utgick alltså från ett målinriktat urval. Genom att intervjua personer inom samma fält men med olika arbetsuppgifter kombinerat med litteratur försökte vi skapa en holistisk bild av sammanhanget.
3.3.3 Genomförande, transkribering och inspelning
Intervjuerna genomfördes under April 2018 i tysta mindre salar i Malmö Universitets lokaler.
5/6 intervjuer skedde i ett virtuellt mötesrum över Lync10, en skedde över telefon
och i endast ett av sex samtal använde vi oss av videosamtal. Med andra ord så såg vi inte de vi intervjuade och vice versa. Samtliga intervjuer spelades in i samtycke med respondenterna. Den mest betydande fördelen med att spela in intervjuer är att intervjuarna har möjlighet att gå tillbaka och spela upp innehållet (Kvale, 1997). Som inspelningsinstrument använde vi appen Dictaphone på en iPhone X, vilken håller en hög ljudmässig kvalitet. För att spela upp ljudet under Lync-intervjuerna använde vi en relativt ny MacBook Pro och en iPhone X under telefonsamtalet. Under intervjuerna som genomfördes över internet fanns det en risk att internetanslutningen kunde brytas och intervjun avbrytas. Denna risk hanterades genom att vi förberedde våra mobiler för internetdelning så vi snabbt kunde återansluta till internet och intervjun.
Varje intervju transkriberades ordagrant. Trots att det är ett väldigt tidskrävande moment hjälper det intervjuaren enligt Kvale (1997) att skapa sig en holistisk bild över sammanhanget. Vilket i sin tur leder till enklare tematisering och kodning vid bearbetning och analys av datan (Kvale, 1997).
3.3.4 Tillvägagångssätt för analys av intervjuer - Innehållsanalys
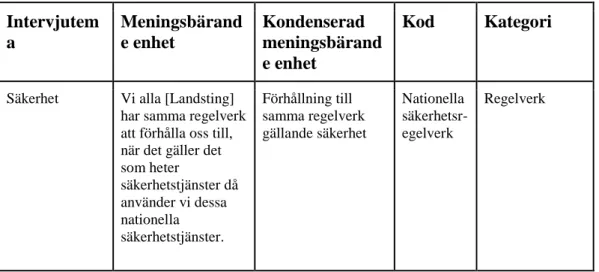
Analysen av intervjuerna utfördes linje med hur Graneheim & Lundman (2004) beskriver hur en forskare kan gå tillväga vid en innehållsanalys. Graneheim & Lundman (2004) menar att deras beskrivning är ett bidrag till debatten kring hur en innehållsanalys kan gå tillväga och inte ett försök till att nå konsensus. Vi upplevde dock deras beskrivning som passande för vårt arbetssätt och följde därför den. Graneheim & Lundman (2004) skiljer på manifest och latent innehåll vid innehållsanalys. Där det manifesta innehållet syftar till det som faktiskt står i texten och det latenta innehållet fokuserar på en djupare tolkning av texten. Vi fokuserade på det manifesta innehållet eftersom det är vad som är intressant för vår studie, inte våra tolkningar av texten betyder. Det är värt att betona att tillvägagångssättet inte behöver ske linjärt, utan forskaren kan gå fram och tillbaka mellan stegen (Graneheim & Lundman, 2004). Tillvägagångssättet grundar sig i följande fem steg:
Texten läses igenom flertalet gånger i syfte för att skapa sig en holistisk bild av
innehållet. Det andra steget består av att välja ut meningar som är relevanta för
frågeställningarna, dessa beskriver Graneheim & Lundman (2004) som
meningsbärande enheter. Efterkommande steg är kondensering av
meningsenheterna vilket görs i syfte att minska texten men bibehålla dess
innehåll. Det fjärde steget är att koda de kondenserade meningsenheterna och sätta dem i kategorier. Vi satte våra koder i olika kategorier och förde till sist in dem i teman vilket är det femte steget, se exempel i tabell 1. Vi satte kategorierna i samma teman som återfinns i vår intervjuguide (se bilaga 1 – Intervjuguide), där vi i sin tur kunde skapa subkategorier.
Tabell 1. Exempel på steg 2,3 och 4
Intervjutem a Meningsbärand e enhet Kondenserad meningsbärand e enhet Kod Kategori
Säkerhet Vi alla [Landsting] har samma regelverk att förhålla oss till, när det gäller det som heter säkerhetstjänster då använder vi dessa nationella säkerhetstjänster. Förhållning till samma regelverk gällande säkerhet Nationella säkerhetsr-egelverk Regelverk
Vi lade till ytterligare ett steg i vår analysmetod. Då vi var två stycken som genomförde denna studie så utförde vi analysen på skilda håll för att sedan
jämföra vårt resultat. I vår innehållsanalys-process fick vi ca 300 koder var som vi sedan jämförde med varandra för att slutligen föra dem till teman. Eftersom vi utförde innehållsanalysen individuellt och sedan kombinerade vårt resultat anser vi att vi fick ett resultat så riktigt som förutsättningarna tillät.
3.4 Trovärdighet - giltighet, pålitlighet och överförbarhet med design-baserad forskning
För att en forskningsstudie ska klassas som design-baserad krävs det att den uppfyller vissa krav. Den måste exempelvis förhålla sig till en redan existerande kunskapsbas för att garantera att resultaten är välgrundade och originella (Bider et al., 2013, Vaishnavi et al., 2017; Peffers et al., 2007). Med en grundad och
originell kunskapsbas blir resultatet mer trovärdigt och det stärker även dess pålitlighet (Johannesson & Perjons, 2012).
Graneheim & Lundman (2004) menar att begrepp som giltighet, pålitlighet och överförbarhet bör beaktas och behandlas för att styrka en kvalitativ studies trovärdighet. Graneheim & Lundman refererar till ansedda kvalitativa forskare (exempelvis, Guba, 1981; Lincoln & Guba, 1985; Polit & Hungler, 1999) för hur de tre begreppen ska tolkas och användas i en kvalitativ studie. Det är utifrån de råden vi har tolkat och hanterat begreppen.
Giltighet handlar om de mål och fokus studien har och hur väl data samlas in för
sammanhang, vilka deltagare man ska samla in data från och tillvägagångssättet för att samla in data. Graneheim & Lundman (2004) skriver att välja deltagare med olika erfarenheter och kunskaper ökar chansen för att belysa
forskningsfrågan ur olika aspekter. Vi har valt att ta kontakt med och intervjua personer som arbetar med IT-inom vården, på liknande eller olika sätt. Att våra deltagare jobbar inom samma fält men på olika sätt gör att vi kan få olika infallsvinklar och aspekter för att besvara syftet, vilket är i linje med vad Graneheim & Lundman (2004) förespråkar.
Pålitlighet syftar till vilken utsträckning forskaren tar hänsyn till hur data kan
förändras över tiden men även hur forskarens sätt att ta beslut förändras under analysprocessen (Graneheim & Lundman, 2004). Vid en omfattande
datainsamling som pågår över en tid finns det en ökad risk för inkonsekvens (Graneheim & Lundman, 2004). Det är viktigt att intervjun behandlar samma områden för alla deltagare. Men eftersom intervjuaren (troligtvis) utvecklas under studiens gång och får nya insikter i det hen studerar kan det påverka
uppföljningsfrågor. Detta kan behandlas med hjälp av en öppen dialog beskriver Graneheim & Lundman (2004). Vi genomförde samtliga intervjuer utifrån
förbestämda teman. Risken för att vara inkonsekventa i vår datainsamlingsprocess är något vi har känt av. Vi märkte båda av att vi ställde ”bättre”
uppföljningsfrågor ju längre vi hade kommit i datainsamlingsprocessen. Men när vi hade lyssnat igenom, transkriberat och kodat våra intervjuer så upplevde vi alla höll likartad kvalité. Något som enligt oss tyder på att vi ändå har lyckats vara konsekventa under processen.
Överförbarhet syftar till i vilken utsträckning kunskapsbidraget och resultaten kan
överföras till andra sammanhang. Graneheim & Lundman (2004) skriver hur forskarna kan ge förslag om överförbarhet, men att det i slutändan är läsaren som avgör huruvida överförbart resultatet är. Vidare betonar Graneheim & Lundman (2004) vikten av att presentera tydliga argument för sitt resultat, sammanhang och urval för att styrka överförbarheten. De betonar också att det inte finns en
universell mall för hur man når överförbarhet (Graneheim & Lundman, 2004). Det handlar om att skapa ett argument för den tolkning man vill göra från sitt resultat. I vårt fall, med en designbaserad forskningsmetod så presenterar vi en modell som ett resultat. Det blir därför en utmaning att kunna skapa överförbarhet för vårt resultat då det är riktat som ett förbättringsförslag på problem i ett
specifikt sammanhang. 3.5 Etiska aspekter
Jacobsen (2002) menar att man vid en undersökning i regel bryter in på den enskilde individens privata sfär och följaktligen skapas etiska dilemman forskaren måste ta hänsyn till. Jacobsen (2002) beskriver att forskaren bör säkerställa att tre grundkrav är uppfyllda: informerat samtycke, krav på privatliv och krav på att bli
korrekt återgiven. Vidare betonar Jacobsen (2002) att det i princip är omöjligt att
uppfylla dessa krav ifall man vill bedriva en meningsfull forskning och menar istället man får hitta en gyllene väg för hur man förhåller sig till kraven. En beskrivning av kraven och hur vi förhöll oss till dem för att skapa vår gyllene väg presenteras nedan.
3.5.1 Informerat samtycke
Jacobsen (2002) menar att den som medverkar i en studie måste göra detta
frivilligt. Vid första kontakt med våra respondenter berättade vi först vilka var och varför vi ville intervjua dem samt i vilket syfte deras medverkan skulle användas. Med våra deltagares samtycke spelade vi även in intervjuerna. Detta kan enligt Jacobsen (2002) ses som tillräcklig information. Respondenterna deltog och spelades alltså in frivilligt. Men Jacobsen (2002) menar att ett frivilligt deltagande inte är så enkelt, påtryckningar på individen från organisationen att delta i
undersökningen kan ha förekommit. Det är något vi är medvetna om men har svårt att bekräfta. Dock, som nämnt tidigare, upplevdes de genomförda
intervjuerna avslappnade och bekväma och våra respondenter upplevdes inte ha några problem att framföra sina tankar.
3.5.2 Krav på privatliv
Det är viktigt att ta hänsyn till deltagarnas rätt till privatliv, vilket utgörs av den zon som inte behövs undersökas för studiens syfte (Jacobsen, 2002). Vidare beskriver Jacobsen (2002) att information som samlas in måste värderas för hur känslig den är för respektive deltagare. Jacobsen (2002) menar även att en utomstående ej ska kunna identifiera en person i det insamlade materialet. Detta ställer krav på konfidentialitet, framförallt inom kvalitativa studier (Jacobsen, 2002). Vi har förhållit oss till detta konfidentialitetskrav genom att anonymisera respondenternas namn, istället har vi presenterat deras roller. Vi valde dock att presentera Inera som organisation, men eftersom det var en gruppintervju och vi inte presenterar vem som säger vad, kan det insamlade materialet inte knytas till en specifik person.
3.5.3 Krav på att bli korrekt återgiven
Jacobsen (2002) menar att resultaten bör återges fullständigt och i rätt
sammanhang i största möjliga mån. Detta innebär att inget material har förfalskats eller manipulerats, och ifall citat återges så är de i sin kontext (Jacobsen, 2002). Vid presentationen av vårt insamlade material var vi väldigt ingående och allt material presenteras i sitt sammanhang. Citaten är återgivna i sin kontext och i de fall vi har använt brutna citat, är det för att betona det centrala i vad som sades. Jacobsen (2002) menar att det finns en risk att brutna citat kan tas ur sitt
sammanhang och på så sätt inte ge en korrekt återgivande bild. Detta har vi tagit hänsyn till genom att kritiskt granska de brutna citaten så de inte ska kunna upplevas som missvisande.
3.6 Själv- och metodkritik
3.6.1 Vi som intervjuare
Vi hade en bristande erfarenhet gällande intervjuer, vilket såklart påverkar utfallet av intervjun. Vår kunskap gällande IT inom sjukvården var även den något
begränsad, kunskapen vi hade med oss kommer från litteratur relaterat till ämnet men även information från de intervjuade organisationernas hemsidor. Kvale (1997) beskriver hur kunskapen om det fenomen som studeras är viktig så att intervjuaren kan ställa relevanta frågor. Vår bristande (om än växande) kunskap kan därmed ha påverkat våra frågeteman men även de följdfrågor vi ställde till
respondenterna. I slutet av varje intervju ställde vi frågan ”har vi missat att fråga
något?”. En fråga som samtliga respondenter besvarade med ”nej” och följde
upp med att vi har varit väldigt grundliga.
En intervjuare ska alltid sträva för en så stor objektivitet som möjligt i
forskningssammanhang (Kvale, 1997). Vi försökte hålla en så stor objektiv grund i intervjuerna som möjligt, men att vara 100 % objektiv är naturligtvis inte
möjligt. Då vi hade en positiv inställning till blockkedjan som teknik och dess möjligheter kan det påverka vårt sätt att ställa frågor samt uppfattande av svar. 3.6.2 Källkritik
Vid val av källor så har vi i största möjliga mån använt oss av referensgranskade källor, både vad gäller artiklar och böcker. Artiklarna som vi har refererarat till har vi hittat via sökmotorerna Google Scholar och Libsearch, i vissa fall har vi använt oss av artiklarnas referenslistor för hitta fler artiklar. De ord och fraser vi använt oss av för att generera våra artiklar är följande (sökorden har använts både på engelska och svenska):
Blockchain, Blockchain in healthcare, Interoperability, Healthinformatics,
Traceability, Smart contracts, Installed Base, e-Health systems, distributed ledger technology och Health Infrastructure.
Vid beskrivning av de nuvarande svenska hälso- och sjukvårdssystemen har vi eftersträvat att använda oss av så aktuella referenser som möjligt. Det kan finnas en mer aktuell karta på infrastrukturen som presenteras i figur 3, men kan enligt oss inte förändrats avsevärt sedan 2016 då våra respondenters svar har
överensstämt med bilden. Eftersom blockkedjetekniken är en relativt ny teknik (uppfunnen 2008) men finns i olika former så har vi använt oss av referenser från varierande årtal, dock är samtliga efter 2008.
3.6.3 Genomförande
Valet av att genomföra telefonintervjuer istället för att träffa respondenterna eller genomföra videointervjuer kan ha haft påverkan på utfallet. Likaså kan utfallet påverkas av att vi var två som genomförde intervjuernrna. Enligt Bryman (2011) påverkar faktumet att det är mer än en intervjuare främst kvantitativa intervjuer och menar att den andra personen inte tillför något. Vi anser att det var positivt att båda var med och genomförde intervjuerna, dels för att vi kunde ställa följdfrågor ur två personers perspektiv men även för att vi lärde oss av att lyssna på
respondenterna.
Den kunskap som produceras i en design-baserad forskningsstudie är framför allt kunskap om artefakten i sig och i det sammanhang den presenteras (Bider et al., 2013; Vaishnavi et al., 2017; Peffers et al., 2007). Däremot ska man sträva efter att försöka få resultatet relevant för en större skala som kan använda det som modeller eller idéer. Kunskapen blir således föreskrivande kunskap (Bider et al., 2013), där resultatet (och artefakten) kan användas som modell för att lösa andra problem.
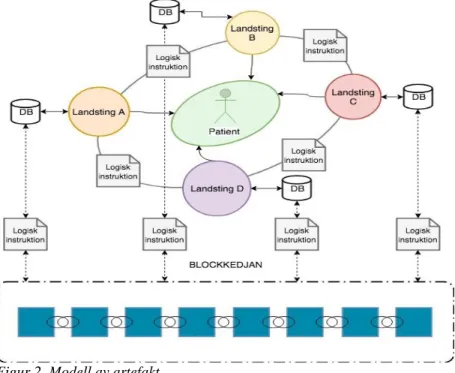
4. DESIGN OCH UTVECKLING AV ARTEFAKT
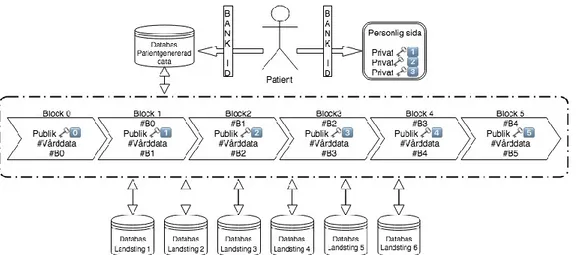
Målet med vårt förslag är att främja interoperabilitet tillsammans med en hög säkerhet och integritet där patienten är i centrum. Vår artefakt är inspirerad av Azaria et al.:s (2017) och Yue et al.:s (2016) prototyper, övrig litteratur om blockkedjans användningsområden i sjukvården, samt de IT-utmaningar som Inera (2016) och Sveriges Kommuner och Landsting (SKL) (2017) beskriver sjukvården står inför.4.1 Behörighetsbaserat decentraliserat nätverk
Vår artefakt är ett behörighetsbaserat decentraliserat nätverk där alla vårdenheter har en krypterad och hashad kopia av varandras databas där man enkelt kan söka efter data genom blockkedjan. Med ett decentraliserat nätverk där alla har tillgång till samma information (givet behörighet) kan vårdgivare få tillgång till en
patients samlade medicinska data, vilket är i linje med vad deltagarna i SYLF:s (2016) undersökning efterfrågar. Ett decentraliserat nätverk skapar också möjligheter för effektivt informationsutbyte mellan patient, vårdgivare och kommun vilket McKinsey (2016) menar är en viktig del i arbetet mot en integrerad vårdkedja. Samtliga landstings system ska kommunicera med blockkedjan via en plattform. På blockkedjan samlas och distribueras all medicinsk data över hela nätverket, men inga personliga uppgifter finns tillgängliga.
4.2 MPI – den personliga identifieraren
Information som finns på nätverket kan endast kopplas till en patient med hjälp av en MPI. Utan MPI så förblir informationen anonym och patientens integritet bibehålls intakt. Den medicinska datan (exempelvis en journal) är märkt med en publik nyckel. Det är endast den person med den motsvarande privata nyckeln som kan “låsa upp” datan och knyta den till en person. Likt hur i Estland alla invånare har ett smart card så skulle det i Sverige kunna ersättas av Bank-ID som en del i autentiseringsprocessen.
Patienten kan logga in på en sida med hjälp av Bank-ID. På sidan finns samtliga privata nycklar som kan koppla ihop patienten med datan som berör hen på blockkedjan. Patienten kan se när och vem som lagt till information och vilka som har tagit del av informationen. Patienten kan också göra egengenererad data synlig i blockkedjan som vårdgivaren kan ta del av för att få en bättre helhetsbild och därmed kunna leverera bättre vård.
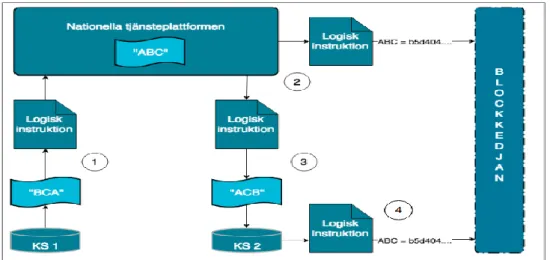
4.3 Logiska instruktioner
På nätverket finns logiska instruktioner som är synliga, exekverbara och kontrollerbara. De logiska instruktionerna kan användas för att uppdatera blockkedjan, hämta och strukturera data samt autentisera. De är en del av
konsensusmekanismen som finns på nätverket. Konsensusmekanismen bestämmer också behörighetsnivån på nätverket, eftersom vår artefakt riktar sig mot
organisationer får en utsedd betrodd grupp vara del av mekanismen och i sin tur uppdatera kedjan. Endast om gruppen godkänner att den nya informationen utifrån de förutbestämda kraven läggs datan till i vårdenhetens databas samt på blockkedjan. Konsensusmekanismen är förprogrammerad med de logiska
instruktionerna och det är datorerna på nätverket som verifierar att den nya informationen är rätt strukturerad innan den läggs till.
De logiska instruktionerna fungerar som strukturerande tolkar av information mellan källsystem och plattformar. Varje överföring eller ändring av data inom eller utanför regionerna uppfattas av de logiska instruktionerna, vi kallar detta händelser. Överför exempelvis region Jönköping information till region Halland via en plattform så finns det logiska instruktioner som översätter händelsen däremellan till rätt struktur för mottagaren. Av denna händelse finns det en kopia som är strukturerad enligt en bestämd form som sedan läggs krypterad och hashad på blockkedjan. Detta gör att förslaget kan fungera även om landsting
dokumenterar information på olika sätt. På så sätt kan data från olika källor kombineras och främja både teknisk men också semantisk interoperabilitet. Eftersom alla har en kopia av blockkedjan, kan man lätt söka igenom händelserna på den (givet behörighet som bestäms av konsensusmekanismen) för att skapa en spårbarhet i systemen.
Figur 2. Modell av artefakt
I figur 2 presenteras hur blockkedjeteknikens egenskaper utnyttjas för att förbättra det svenska hälso- och sjukvårdssystemet. Modellen skapar förutsättningar för teknisk och semantisk interoperabilitet och en mer integrerad vårdkedja.
5. SVENSKA SJUKVÅRDENS IT-SYSTEM
IDAG
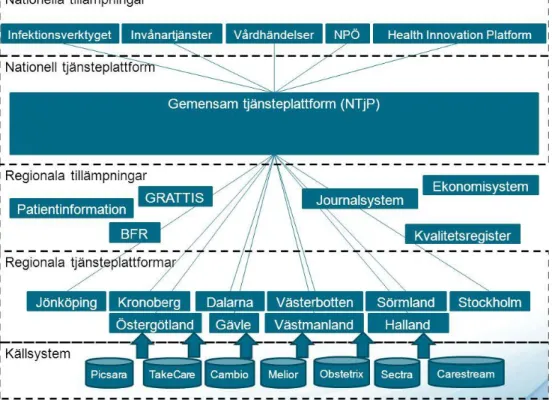
5.1 Infrastrukturen i svenska sjukvårdssystemet
Företaget Inera har på uppdrag av landsting, regioner och kommuner utvecklat en nationell tjänsteplattform som ska förenkla, säkra och effektivisera
med Nationella tjänsteplattformen är att främja interoperabilitet och skapa en virtuell koppling mellan olika informationskonsumerande och producerande tjänster och system. Där tjänster och system ska kunna läggas till men även tas bort utan att andra påverkas (Inera, 2018b). Denna tanke är i linje med hur ett tjänsteorienterat system fungerar. Inera (2018b) beskriver att Nationella tjänsteplattformen fungerar som en växel mellan olika system. När ett system kontaktar ett annat styr tjänsteplattformen information till rätt system och vårdgivare. Fördelen enligt Inera (2018b) med en virtuell plattform är att man eliminerar en punkt-till-punkt-förbindelse mellan systemen. Vilket i sin tur leder till mindre arkitektonisk komplexitet och lägre underhållskostnader. Figur 3 visar hur landstingens olika källsystem och tillämpningar kommunicerar med varandra via Nationella tjänsteplattformen.
Figur 3. Infrastrukturen i de svenska hälso- och sjukvårdssystemen (Thunholm, 2014)
5.2 Regelverk
I arbetet med regelverket är utgångspunkten att balansera rättigheter och intressen som till exempel personlig integritet, kvalitet, säkerhet och effektivitet.
Regelverket bör även hantera den tekniska utvecklingen och ansvaras av staten, SKL ska verka som stöd för huvudmännen. Inera (2016) beskriver även att om regelverket skulle behöva ändras för att förbättra kvalitet och effektivitet ska ändringen även tillgodose behovet av integritets- och säkerhetsskydd.
5.2.1 Patientdatalagen - PDL
Patientdatalagen (PDL, SFS 2008:355) utfärdades under maj 2008 och har som syfte att organisera informationshanteringen inom hälso- och sjukvården samtidigt som den tillgodoser patientsäkerhet och god vårdkvalitet. Den ska även främja kostnadseffektivitet och respektera patienters och övriga registrerades integritet. PDL (SFS 2008:355) ger möjlighet till sammanhållen journalföring vilket innebär att ett elektroniskt system gör det möjligt för en vårdgivare att ge eller få
direktåtkomst till personuppgifter hos en annan vårdgivare. Lagen beskriver att det är vårdgivaren som utför en behandling som är personuppgiftsansvarig (SFS 2008:355). PDL (SFS 2008:355) tillåter en patient att begära ut ett dokument med klinisk data om sig i analog form men ger inte rätt att begära ut vem som har tagit del av uppgifter i hens journal. Patienten har däremot rätt att begära ut vilken vårdenhet som har haft tillgång till journalen, vilken information i journal samt vilken tidpunkt åtkomsten ägde rum (SFS 2008:355).
5.2.2 Genderal Data Protection Regulation - GDPR
Den 25:e maj 2018 trädde EUs nya dataskyddslag i kraft - GDPR. Lagen syftar till att förbättra dataskyddet och individers integritet samt underlätta flödet av data inom EU (ERF, EU 2016/679). Av alla GDPRs punkter är det främst två stycken som kommer att påverka hälso- och sjukvårdssystemet i Sverige - rätten att bli bortglömd och rätt till dataportabilitet.
5.2.2.1 Rätten att bli bortglömd
Artikel 17 beskriver en persons rätt att bli bortglömd. Det innebär att en person har rätt till att, utan onödigt dröjmål, av personuppgiftsansvariga få sina
personuppgifter raderade (ERF, EU 2016/679). Detta innebär att om en patient så önskar, ska landstinget radera all information om patienten så fort som möjligt. 5.2.2.2 Rätt till dataportabilitet
En registrerad ska kunna få ut de personuppgifter som rör hen av
personuppgiftsansvarige i ett strukturerat, allmänt använt och maskinläsbart format och även ha rätt att överföra dessa uppgifter till en annan
personuppgiftsansvarig (ERF, EU 2016/679). Detta innebär en utveckling av PDL där patienten har möjlighet att få sin personuppgiftsinformation i ett fysiskt format. Men ställer även krav på att personuppgiftsansvarig, som i patientens fall är vårdgivaren, ska kunna överföra information till en annan
personuppgiftsansvarig digitalt. 5.3 Presentation av intervjuer
5.3.1 Orsaker, utmaningar och åtgärder för teknisk interoperabilitet
När de första journalsystemen upphandlades på 90-talet gjordes det per verksamhetsområde. Det kunde vara olika system regioner emellan men även inom regionerna. I systemen fanns det tekniska begränsningar för att lagra och dela information då servrar inte kunde placeras på distans utan behövde stå på den aktuella vårdenheten. Den tekniska interoperabiliteten är idag relativt bra löst menar R1 (personlig kommunikation, 2018-04-05). R2 är dock av en annan uppfattning och menar det inte finns tillräckligt teknisk stöd för interoperabilitet och en integrerad vårdkedja (personlig kommunikation, 2018-04-09). Mycket beroende på att källsystemen fortfarande lever kvar och de har ej stöd för integration med andra system (R2, personlig kommunikation, 2018-04-09). R2 vidareutvecklar och menar att detta leder till dubbeldokumentation av information (personlig kommunikation, 2018-04-09).
5.3.1.1 En sammanhållen journalföring
När möjligheten till sammanhållen journalföring blev aktuell hade man inte tagit hänsyn till detta i kravspecifikationen under utvecklingsarbetet av systemen och behövde då påbörja arbetet att integrera olika system med varandra. Dessa integrationer är väldigt dyra och kan kosta landstingen miljonbelopp för ett fåtal system. Respektive region är ansvarig för sina journaler och system. Inera har utvecklat tjänsten Nationell patientöversikt (NPÖ) (R5, personlig kommunikation, 2018-04-17). NPÖ är en tjänst som möjliggör behörig vårdpersonal med
patientens samtycke att ta del av journalinformation från andra landsting.
Vårdenheterna själva är ansvariga för att ansluta sig till NPÖ men det är en
kostsam process (R5, personlig kommunikation, 2018-04-17). Mindre vårdenheter har inte alltid resurser för detta och får då inte tillgång till tjänsten. R1 berättar att all information som kan ses på NPÖ är riktig, däremot är det inte säkert att patientens fullständiga information finns tillgänglig (personlig kommunikation, 2018-04-05). Det går inte att uppdatera en journal via NPÖ, utan en ny journal måste skapas hos varje region. Tjänsten har inte heller stöd för exempelvis röntgenbilder eller EKG-kurvor, en funktion som Inera tittar på att utveckla men det finns tekniska begränsningar då bildfilerna är för stora beskriver R5 (personlig kommunikation, 2018-04-17). Konsekvensen av detta blir att vårdgivaren får posta den kompletterande informationen alternativt faxa ifall det är bråttom (R1, personlig kommunikation, 2018-04-05). R5 beskriver att de vill kunna presentera EKG-kurvor, blodtryck, vikt och längd m.m. grafiskt för att uppvisa en mer samlad bild (personlig kommunikation, 2018-04-17).
R1 och R2 beskriver hur arbetsprocesserna inom sjukvården är fast i en traditionell struktur som är väldigt svår att bryta sig ur ifrån. Det finns en bristande ordning i hur information struktureras men även överförs (personlig kommunikation, 05; personlig kommunikation,
2018-04-09). Journalanteckningar kan sorteras på hög och missas vilket ofta leder till dubbeldokumentation och att patientgenererad data nästan aldrig hamnar i journalen (R6, personlig kommunikation, 2018-04-22).
5.3.1.2 Nationella tjänsteplattformen - navet mellan system och e-tjänster I arbetet mot mer interoperabilitet och strukturerad data har Inera utvecklat Nationella tjänsteplattformen (NTJP). R5 beskriver att NTJP utgör navet mellan system och e-tjänster som är i behov av att kommunicera och utbyta information med varandra (personlig kommunikation, 2018-04-17). Majoriteten av våra respondenter tycker att NTJP fungerar “helt okej” ur ett
interoperabilitetsperspektiv, dock upplevs utvecklingen av plattformen långsam (R2, personlig kommunikation, 2018-04-09).
På NTJP körs s.k. tjänstekontrakt, vilket är en teknisk beskrivning för hur data ska överföras strukturerat och säkert oberoende mjuk- och hårdvara (R4, personlig kommunikation, 2018-04-12; R5, personlig kommunikation, 2018-04-17). R5 beskriver hur detta ökar interoperabilitet inom sjukvården (personlig
kommunikation, 2018-04-17). R5 beskriver vidare hur NPÖ och NTJP kräver mycket administration för att hålla applikationerna uppdaterade med rätt information men även med rätt behörighetsgränser för vårdgivaren som söker information. Vid anslutning till NTJP och NPÖ så behöver vårdenheten ha en Tillgänglig patient-tjänst (TGP) ansluten, för att kunna begränsa åtkomst till
patientinformation. TGP är en tjänst som utvecklades under 2009 utifrån krav av Datainspektionen, tjänsten ska hindra vårdpersonal att komma åt obehörig
information (R5, personlig kommunikation, 2018-04-17). Nackdelen med TGP är att det skapar interoperabilitetsproblem då patienter rör sig mer över
organisationsgränser nu än vad de gjorde 2009 beskriver R5 (personlig kommunikation, 2018-04-17). Ett problem som stödjer utmaningen om den integrerade vårdkedja som enligt R2 inte fungerar (personlig kommunikation, 2018-04-09).
5.3.1.3 Ett komplext och kostsamt samspel
Det finns alltså flera komponenter som måste samspela för att en vårdgivare ska kunna använda NTJP och NPÖ på ett funktionellt sätt. Det är en väldigt kostsam och tidskrävande process att ansluta sig till de olika tjänsterna (samt uppfylla kraven), en process som framförallt de mindre vårdenheterna inte har resurser till. För att underlätta detta utvecklar företaget HIP rest-APK och rest-API:er som vårdenheterna kan använda för att ansluta sig till NTJP och få tillgång till klinisk data (R6, personlig kommunikation, 2018-04-22). HIP har utvecklat olika
mjukvarupaket som vårdgivare kan använda sig av, där de tar hand om det administrativa och de säkerhetskrav som ställs på datahanteringen.
Majoriteten av respondenterna betonar flertalet gånger att den traditionella arbetsstrukturen försvårar digitaliserings- och innovationsarbetet framåt i vården och att det är nödvändigt att ta sig ur denna struktur. Denna bristande struktur sprider sig över myndighetsgränser och drabbar flera (R1, personlig
kommunikation, 2018-04-05). Exempelvis om en myndighet vill ha
patientinformation är det en utmaning att överföra information till dem. R1 efterfrågar ett mer mobilt arbetssätt och att kunna använda mer klinisk
patientgenererad data (personlig kommunikation, 2018-04-05). Man vill att datan ska följa patienten och inte patienten datan.
5.3.2 Semantisk interoperabilitet - en stor utmaning
Den semantiska interoperabiliteten handlar om att information ska dokumenteras och tolkas på samma sätt överallt. R1 beskriver ett exempel om att blodtryck kan förkortas på fem olika sätt (personlig kommunikation, 2018-04-05). R3 beskriver att när det användes papperssystem spelade det ingen roll att informationen dokumenterades på olika sätt (personlig kommunikation, 2018-04-11). Problemen uppstår när det är system som ska hantera informationen, då måste det vara tydligt vad som menas. Ett normalt stående blodtrycksvärde kan vara ett onormalt
liggande blodtrycksvärde (R3, personlig kommunikation, 2018-04-11). När det inte råder konsensus över hur information dokumenteras finns det ingen möjlighet att använda systemen som stöd, vilket är efterfrågat.
“om en vårdgivare har en patient framför sig så är det inte så att man själv ska behöva gå in och titta på många olika parametrar utan jag ska få en score. Sen vet jag om den scoren är under 20 eller över 20 då ska jag agera på olika sätt.”
(R6, personlig kommunikation, 2018-04-22)
Om informationen som dokumenteras betyder olika saker på olika ställen måste läkaren översätta informationen istället för att använda ett system som stöd. Detta leder till, förutom att det är tidskrävande, att läkarna måste ha lång erfarenhet för att tolka datan rätt.