Teknik och samhälle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Effektiv konstruktion av dataaggregeringstjänster i Java
Effective construction of data aggregation services in Java
Fredrik Andersson
Simon Cedergren Malmqvist
Examen: Kandidatexamen 180 hp Huvudområde: Datavetenskap
Program: Datavetenskap & applikationsutv. Datum för slutseminarium: 1 juni 2015
Handledare: Kristina Allder Andrabedömare: Bengt Nilsson
Sammanfattning
Stora mängder data genereras dagligen av slutanvändare hos olika tjänster. Denna data tenderar att tillhandahållas av olika aktörer, vilket skapar en fragmenterad marknad där slutanvändare måste nyttja flera programvaror för att ta del av all sin data. Detta kan motverkas genom utvecklandet av aggregeringstjänster vilka samlar data från flera tjänster på en enskild ändpunkt. Utveckling av denna typ av tjänster riskerar dock att bli kostsamt och tidskrävande, då ny kod skrivs för flera projekt trots att stora delar av funktionaliteten är snarlik. För att undvika detta kan etablerade tekniker och ramverk användas för att på så vis återanvända mer generella komponenter. Vilka av dessa tekniker som är bäst lämpade och således kan anses vara mest effektiva ur ett utvecklingsperspektiv, kan dock vara svårt att avgöra. Därför baseras denna uppsats på vad som genom analys av akademisk litteratur kan utläsas som ett akademiskt konsensus.
Innan denna uppsats påbörjades utvecklades en Java-baserad dataaggeringstjänst ba-serad på krav från ÅF i Malmö. Denna experimentella implementation har som syfte att samla in data från två separata tjänster, och tillgängliggöra denna på en enskild ändpunkt. Efter att implementationen färdigställts påbörjades arbetet på uppsatsen. Denna består av en litteraturstudie för att undersöka vilka tekniker och ramverk som akademisk forskning funnit bäst lämpad för användningsområdet. Vidare används resultaten från studien även för att analysera i vilken grad dessa korrelerar med de krav som ÅF presenterade inför den experimentella implementationen.
Litteraturstudien visar på att de teknikmässiga val som gjordes av företaget i stor utsträckning korrelerar med de tekniker som akademisk forskning funnit bäst lämpade för användningsområdet. Detta innefattar bland annat OAuth 2.0 för autentisering, JSON som serialiseringsformat samt REST som kommunikationsarkitektur. Vidare visar denna litteraturstudie på en eventuell lucka inom den tillgängliga litteraturen, då sökningar kring specifika programvaror relaterade till området endast resulterar i en mindre mängd artiklar.
Abstract
Large quantities of data are generated daily by the end users of various services. This data is often provided by different providers, which creates a fragmented market where the end users have to utilize multiple applications in order to access all of their data. This can be counteracted by the development of aggregation services that gather data from multiple services to a combined endpoint. The development of these kinds of services does however run the risk of becoming costly and time-consuming since new code is written for several projects even though large portions of the functionality is similar. To avoid this, established technologies and frameworks can be utilized, thereby reusing the more general components. Which of the technologies are the best suited, and thereby can be considered the most effective from a development perspective, can however be difficult to determine. This essay is therefore based on what can be considered an academic consensus through analysis of literature regarding earlier reasearch on the subject.
Before the writing of the essay began a Java-based data aggregation service was de-veloped, based on requirements from the company ÅF in Malmö. The purpose of this experimental implementation is to gather data from two separate services, and make them accessible on a unified endpoint.
After the implementation was finished, work on the essay began. This consists of a literature review to investigate what technologies and frameworks that has been found best suited for this area of application by academic research. The results from this study are also used to analyze the extent of the correlation between the results and the requirements presented by ÅF regarding the experimental implementation.
The literature review shows that the choices made by the company largely correlates with the technologies that the academic research has found best suited for this area of application. This includes OAuth 2.0 for authentication, JSON as a serialization format and REST for communications architecture. The literature review also indicates a possible gap within the available academic literature since searches regarding specific pieces of software related to the subject only results in a small amount of articles.
Innehåll
1 Inledning 1 1.1 Bakgrund . . . 1 1.2 Frågeställning . . . 1 2 Metod 2 2.1 Metodbeskrivning . . . 2 2.1.1 Litteraturstudie . . . 2 2.1.2 Experimentell implementation . . . 7 2.2 Metoddiskussion . . . 7 3 Resultat 9 3.1 Litteraturstudie . . . 9 3.2 Experimentell implementation . . . 9 3.2.1 Kommunikation . . . 9 3.2.2 Autentisering . . . 10 3.2.3 Serialisering . . . 11 3.2.4 Datakällor . . . 12 4 Analys 14 4.1 Auktorisering och autentisering . . . 144.1.1 Dokumentation . . . 15 4.1.2 Alternativ . . . 17 4.2 Serialisering . . . 17 4.2.1 Format . . . 17 4.2.2 Parser . . . 19 4.3 Kommunikation . . . 20 4.3.1 Arkitektur . . . 20 4.3.2 Plattform . . . 21 5 Diskussion 22 5.1 Frågeställning . . . 22 5.2 Litteraturstudie . . . 22 5.2.1 Sökning . . . 22 5.2.2 Material . . . 22 5.3 Experimentell implementation . . . 23
1
Inledning
1.1 BakgrundI dagens samhälle genereras dagligen stora mängder data av alla möjliga slag. Detta in-nefattar allt från bilder och videoklipp till chatthistorik och privatpersoners fysiska mät-värden. Olika typer av data tenderar att tillhandahållas av olika aktörer, vilket skapar en fragmenterad marknad där slutanvändare måste nyttja flera tjänster för att ta del av all sin data. Denna situation kan undvikas med hjälp av utvecklandet av programvara med uppgiften att kombinera data från flera källor och samla denna på en enskild ändpunkt. Konstruktionen av sådana aggregeringstjänster riskerar dock att bli både kostsamt och tidskrävande. Detta då helt ny kod skrivs för olika projekt trots att en omfattande del av konstruktionen riskerar att bli snarlik.
För att undvika att liknande lösningar implementeras från grunden vid varje nytt pro-jekt kan ramverk, programvaror, samt övriga etablerade tekniker inkluderas för att på så vis återanvända de mest vitala komponenterna i ett system. Detta innebär att kostnader kan hållas nere och att utvecklingsprocessen kan effektiviseras, då mindre mängd ny kod behöver skrivas.
Att avgöra vilka av dessa återanvändbara komponenter som är att föredra kan dock anses problematiskt, då utbudet är stort och olika källor tenderar att presentera vitt skilda rekommendationer. Vilka av dessa källor som är mest pålitliga kan komplicera ytterli-gare, då exempelvis företag och privatpersoner inte nödvändigtvis delar uppfattning och målsättning. Detta gör att en studie av tillgänglig akademisk litteratur kring relevanta komponenter och tekniker är tillrådlig, för att på så vis utläsa en vetenskapligt grundad konsensus.
1.2 Frågeställning
Syftet med detta arbete är att undersöka hur ett Java-baserat system som samlar data från ett flertal öppna APIer, vilka tillhandahålls av olika leverantörer, kan konstrueras på ett effektivt sätt. Med ”effektivt” menas i detta sammanhang att skrivandet av ny kod minimeras till fördel för användandet av existerande tekniker. En lösning på denna frågeställning kommer att nås genom besvarandet av tre frågor:
1. Vilka ramverk är möjliga att använda i systemets konstruktion?
2. Vilka ramverk anser tidigare akademisk forskning vara bäst lämpade för uppgiften? 3. Vad krävs av tredjeparts-aktörer för att underlätta aggregering av data?
2
Metod
2.1 Metodbeskrivning
Vid arbetets början konstruerades en experimentell implementation i samarbete med ett externt företag vid namn ÅF; ett svenskt konsultbolag vilka bland annat är verksamma inom IT och mjukvaruutveckling1. Syftet med att inkludera detta samarbete i uppsatsen är att undersöka hur en Java-baserad dataaggregeringstjänst kan konstrueras i praktiken och vilka tekniker ett företag anser vara att föredra.
Därefter påbörjades uppsatsen, där den huvudsakliga forskningsmetoden utgörs av en litteraturstudie vars syfte är att identifiera relevant akademisk litteratur kring ämnet och på så vis ge insyn i vilka ramverk och tekniker som tidigare forskning funnit bäst lämpade för detta användningsområde. Det implementerade systemet jämförs sedan med resultaten från litteraturstudien för att undersöka vad som kunde gjorts annorlunda, och på vilka områden de båda är eniga om en teknik eller programvara.
Nedan följer ytterligare redogörelser för den experimentella implementationen samt för den litteraturstudie som genomförs för att införskaffa material kring tidigare forskning inom ämnet.
2.1.1 Litteraturstudie Syfte
Litteraturstudiens syfte är att hitta litteratur kring akademisk forskning inom ämnet, och således undersöka vilka tekniker och programvaror som denna forskning funnit bäst läm-pade för det valda användningsområdet. Vidare används det resulterande materialet till att undersöka huruvida de beslut som fattats kring den tidigare genomförda experimen-tella implementationen kan betraktas som de mest effektiva eller ej, genom att jämföra de resulterande teknikerna från studien med de som användes i systemet.
Avgränsningar
På grund av problemområdets omfattning begränsas studiens fokus till att endast innefatta de delar i ett dataaggregeringssystem vilka kan anses ha störst inverkan på systemets funktionalitet och prestanda.
Detta innebär att en uppdelning görs för att abstrahera systemet, vilket resulterar i att tre mer generella områden kan granskas individuellt. Dessa områden väljs då de omfattar en adekvat del av det avsedda systemet som helhet. Nedan följer de valda områdena:
• Autentisering & auktorisering: protokoll och ramverk för autentisering och auk-torisering.
• Serialisering: format och parser-bibliotek för förmedling och hantering av data. • Kommunikation: tekniker och programvaror för hantering av kommunikation med
klienter och externa datakällor.
Studien grundas på akademisk litteratur utgiven av ACM och IEEE då de båda är väle-tablerade och erkända källor inom datavetenskapen. För att undvika att material uteblir
1
på grund av felaktig filtrering används de tjänster som direkt tillhandahålls av ACM och IEEE, istället för nyttjandet av aggregerande sökmotorer så som Google Scholar. De filter som väljs utgörs av att endast tidskrifter och konferensartiklar tillåts som sökresultat, samt att dessa ska vara publicerade av ACM respektive IEEE.
För att maximera tillgänglig data vid litteratursökningen appliceras inga filter för tillå-tet tidsintervall. Vid val av relevanta artiklar prioriteras dock artiklar utgivna mellan åren 2010-2015, för att undvika att föråldrad teknik och programvara färgar de åsikter som materialet speglar. Artiklar utgivna tidigare än denna period anses endast vara acceptabla i de fall där forskningen bidrar med unika infallsvinklar på det behandlade området, vilka inte är baserade på en specifik programvara eller implementation.
Endast teknik tillgänglig för industrin anses relevant och därmed frånses tekniker som saknar en beprövad implementation. Detta innebär att artiklar som presenterar nya tek-niker undviks till fördel för de artiklar som analyserar etablerade sådana. I de fall då information söks om en specifik implementation eller produkt görs detta i officiell doku-mentation för respektive produkt eller teknik.
Vid granskning av specifika programvaror begränsas litteraturstudien till att endast fokusera på tekniker för programmeringsspråket Java. Detta för att möjliggöra en mer djupgående granskning av teknik för ett specifikt programmeringsspråk, i kontrast till att ytligt granska programvaror för flertalet programmeringsspråk. Valet av detta språk är ett direkt resultat av de krav som ÅF ställde på den experimentella implementationen.
Tidigare sökningar kring autentisering och auktorisering klargjorde att OAuth är den enda teknik som erbjuder den funktionalitet systemet kräver, därför är denna studie av-gränsad till att endast undersöka OAuth.
Då systemet som avses vid arbetets frågeställning består av en webbtjänst vilken kan förmedla data till klienter på åtskilliga plattformar begränsas de granskade serialiserings-formaten till att bestå av JSON och XML. Detta då de utgör två av de mest populära formaten i samband med webbtjänster, vilket styrks av sökningar i databaser så som Pro-grammableWeb [1] där antalet JSON- och XML-baserade tjänster visar sig vara mång-faldigt större än antalet tjänster som använder sig av binära- eller andra textbaserade format. Vidare innebär faktumet att de valda formaten är textbaserade att de även är plattformsoberoende, vilket leder till att resultatet kan anses lättare att generalisera. Sökning
Sökning av relevant litteratur görs med sökmotorerna ACM DL och IEEE Xplore. Samt-liga söktermer används i båda databaser för att på så sätt hålla det granskade området konsekvent mellan tjänsterna. Tabellerna nedan redogör för antalet träffar vid sökning och är indelade efter övergripande ämnesområde där Tabell 1 redogör för kommunikation, Ta-bell 2 redogör för serialisering, och TaTa-bell 3 redogör för autentisering och auktorisering. Vidare är tabellerna uppdelade i kolumner vilka representerar de använda databaserna.
Sökmetoden i IEEE Xplore skiljer sig från den i ACM DL och denna skillnad har upp-märksammats i tabellerna genom användandet av olika skiljetecken mellan söktermerna. Vid sökning i IEEE Xplore har termer separerats med ”>” för att indikera att följande uttryck används för att vidare filtrera resultatet från föregående sökterm. Vid användning av ACM DL separeras söktermer istället med kommatecken då sökningar genomförs med samtliga termer simultant. Detta då denna tjänst binder samman begrepp med kommandot ”AND” för att försäkra att alla efterfrågade termer hittas i varje träff.
Vid de tillfällen där antalet träffar understiger 70 undersöks samtliga resultat genom en granskning av titel samt nyckelord. De artiklar vars titel eller nyckelord korrelerar med det aktuella ämnet väljs sedan ut för en närmare inspektion, vilket innefattar en granskning av abstract, sammanfattning, samt resultat. Detta följs av en mer djupgående granskning i de fall där artikeln bedöms som lämplig för studien. Kriterierna för denna granskning består av att artikeln ska innehålla konkreta åsikter eller påståenden kring det aktuella ämnet, i kontrast till att endast lista tekniska specifikationer eller liknande fakta. Kravet på dessa åsikter och påståenden är att de kan styrkas med litteratur kring tidigare forskning, vilken genomgått peer-review, eller genom egenhändig forskning utförd av den aktuella artikelns författare.
För de artiklar som anses lämpliga granskas referenslistan för att på så vis hitta yt-terligare relevant litteratur. Även detta urval görs med ovan nämnda metoder, och vidare granskning av referenser utförs sedan rekursivt.
Denna sökning samt filtrering resulterar i ett antal artiklar vilka i enlighet med krite-rierna ovan bedöms som lämpliga för genomförandet av litteraturstudien. Detta slutliga urval redogörs för i Tabell 4.
(a) ACM Sökterm Antal java 29036 java, jersey 702 java, jax 134 java, ”jax rs” 22 java, rest 10465 java, restful 311
java, restful, rest 223 java, restful, rest, jersey 22
java, servlet 835
java, servlet, rest 332
java, servlet, web 779
java, servlet, rest, web 312 java, servlet, rest, web, jersey 11
jersey 13792 jersey, rest* 1533 jersey, rest 1425 jersey, restful 30 (b) IEEE Sökterm Antal java 18182 java >jersey 21 java >jax 9 java >”jax rs” 0 java >rest 99 java >restful 33
java >restful >rest 15 java >restful >rest >jersey 0
java >servlet 111
java >servlet >rest 0 java >servlet >web 84 java >servlet >rest >web 0 java >servlet >rest >web >jersey 0
jersey 5250
jersey >rest* 117
jersey >rest 27
jersey >restful 1
(a) ACM Sökterm Antal serializ* 471 serializ*, json 13 serializ*, xml 76 serializ*, xml, json 9 serializ*, rest 171 serializ*, restful 5 serializ*, api 101
serializ*, rest, api 52 serializ*, api, web 52 serializ*, ”web service*” 12 serializ*, ”web 2.0” 8
serializ*, format* 89
serializ*, format*, data, web 55
serializ*, compar* 91
serializ*, compar*, format* 17
json 1396 json, compar* 175 xml 15492 xml, compar* 2021 xml, json 690 xml, json, compar* 72
xml, json, web, compar* 66
(b) IEEE Sökterm Antal serializ* 1261 serializ* >json 7 serializ* >xml 56 serializ* >xml >json 5 serializ* >rest 6 serializ* >restful 0 serializ* >api 10
serializ* >rest >api 0 serializ* >api >web 2 serializ* >”web service*” 20 serializ* >”web 2.0” 0 serializ* >format* 42 serializ* >format* >data >web 14 serializ* >compar* 209 serializ* >compar* >format* 7
json 112 json >compar* 18 xml 13053 xml >compar* 1079 xml >json 61 xml >json >compar* 14 xml >json >web >compar* 7 Tabell 2: Serialisering
(a) ACM
Sökterm Antal
auth* 11273
auth*, rest 2871
auth*, restful 60 auth*, restful, rest 42 auth*, rest, restful 42 auth*, compar* 1719 auth*, vs 1641 auth*, compar*, vs 382 auth*, vs, compar* 382 auth*, oauth* 62 auth*, web 5109
auth*, web , oauth 58 auth*, oauth, web 58
oauth* 203 oauth*, compar* 24 oauth*, vs 49 oauth*, rest 121 oauth*, pros 122 oauth*, cons 130 oauth*, ”oauth 2” 62 (b) IEEE Sökterm Antal auth* 197365 auth* >rest 602 auth* >restful 42 auth* >restful >rest 11 auth* >rest >restful 11 auth* >compar* 21764 auth* >vs 603 auth* >compar* >vs 183 auth* >vs >compar* 183 auth* >oauth* 65 auth* >web 8227
auth* >web >oauth 28 auth* >oauth >web 28
oauth* 71 oauth* >compar* 2 oauth* >vs 0 oauth* >rest 10 oauth* >pros 0 oauth* >cons 0 oauth* >”oauth 2” 63 Tabell 3: Autentisering
Titel Författare Utgivningsår Referensnummer ”POAuth: Privacy-aware Open Authorization for Native Apps on Smartphone Platforms” Nauman, Khan, Othman m. fl. 2012 [2]
”ROAuth: Recommendation Based Open Authorization” Shehab, Marouf och Hudel 2011 [3] ”Information Sharing and User Privacy in the Third-party Identity Management Landscape” Vapen, Carlsson, Mahanti m. fl. 2015 [4] ”A design of cross-terminal web system based on JSON and REST” Niu, Yang och Zhang 2014 [5] ”Modeling RESTful Applications” Schreier 2011 [6] ”REST client pattern” Upadhyaya 2014 [7] ”Is the cloud the answer to scalability of ecologies? Using GAE to enable horizontal scalability” Ramasahayam och Deters 2011 [8] ”RESTful Web service frameworks in Java” Hongjun 2011 [9] ”Federated Identity and Access Management for the Internet of Things” Fremantle, Aziz, Kopecký m. fl. 2014 [10] ”Characteristics of Scalability and Their Impact on Performance” Bondi 2000 [11] ”OAuth Based Authentication and Authorization in Open Telco API” Liu och Xu 2012 [12] ”A security analysis of the OAuth protocol” Yang och Manoharan 2013 [13] ”Federated Identity Access Broker Pattern for Cloud Computing” Reimer, Abraham och Tan 2013 [14] ”OAuth Demystified for Mobile Application Developers” Chen, Pei, Chen m. fl. 2014 [15] ”Design of a security mechanism for RESTful Web Service communication through mobile clients” Backere, Hanssens, Heynssens m. fl. 2014 [16] ”Information Sharing and User Privacy in the Third-party Identity Management Landscape” Vapen, Carlsson, Mahanti m. fl. 2015 [17] ”A Comparison of Data Serialization Formats for Optimal Efficiency on a Mobile Platform” Sumaray och Makki 2012 [18] ”Principled Design of the Modern Web Architecture” Fielding och Taylor 2000 [19] ”Google App Engine Gets Ready For Business” Charles 2012 [20] ”Comparison between JSON and XML in Applications Based on AJAX” Lin, Chen, Chen m. fl. 2012 [21] ”Analysis of the Efficiency of Data Transmission Format Based on Ajax Applications” Wang, Wu och Yang 2011 [22] ”Comparison of JSON and XML Data Interchange Formats: A Case Study” Nurseitov, Paulson, Reynolds m. fl. 2009 [23] ”Latencies of Service Invocation and Processing of the REST and SOAP Web Service Interfaces” Aihkisalo och Paaso 2012 [24] ”Performance analysis of ubiquitous web systems for SmartPhones” Hameseder, Fowler och Peterson 2011 [25] ”Performance evaluation of object serialization libraries in XML, JSON and binary formats” Maeda 2012 [26] ”A Performance Comparison of Web Service Object Marshalling and Unmarshalling Solutions” Aihkisalo och Paaso 2011 [27]
2.1.2 Experimentell implementation
Detta avsnitt behandlar utvecklandet av den experimentella implementationen. Underru-brikerna redogör således för implementationens bakgrund, syfte samt begränsningar. Bakgrund
Grunden för implementationen utgjordes av ett utvecklingsuppdrag vilket utfördes på ÅF i Malmö under våren 2015. Systemet som efterfrågades hade som huvudsaklig uppgift att agera kombinerad ändpunkt för data från två olika tredjeparts-tjänster, och avsågs därmed fungera som ett öppet API.
Ett grundkrav för systemet var att kommunikation med Sonys tjänst Lifelog utgjorde en vital del i konstruktionen. Detta då tjänstens API skulle öppnas för allmän användning inom en snar framtid och en önskan från ÅF och Sony fanns om att undersöka potentiella användningsområden. Lifelog samlar in data kring användares fysiska aktivitet via armband som kopplas till smarta telefoner via Bluetooth, och möjliggör sedan uthämtning av denna data med hjälp av den dedikerade mobil-applikationen eller tidigare nämnda webbtjänst. Syfte
Inkluderandet av den tidigare konstruerade experimentella implementationen i uppsatsen har som huvudsakligt syfte att bidra med insikt kring hur den typ av system som beskrivs i arbetets frågeställning kan konstrueras i praktiken, samt vilka programvaror och tekniker ett etablerat företag inom industrin anser vara de bäst lämpade för användning inom det valda ämnesområdet. Detta system utgör således en referentiell utgångspunkt för hur denna typ av system kan konstrueras på ett effektivt sätt.
Begränsningar
Då konstruktion av den experimentella implementationen förlades hos ÅF angavs vissa krav av dem. Krav på systemets övergripande arkitektur fastställdes till en programvara vars syfte var att tillhandahålla data från Lifelog och en ytterligare datakälla, samt hantera autentisering.
Utöver krav på arkitektur erhölls även tekniska sådana, så som krav på val av pro-grammeringsspråk och ramverk. Vissa krav resulterade i ytterligare, indirekta, krav då de innebar att endast en enskild teknik var ett gångbart alternativ. Exempelvis krävde ÅF att systemet skulle utvecklas i webbtjänst-ramverket Jersey samt autentisering-biblioteket Guja, vilket implicit resulterade i att systemet i sin helhet skulle skrivas i programmerings-språket Java samt använda OAuth 2.0 för autentisering. Vidare föreslogs användandet av PaaS-tjänsten2Google App Engine för hosting3samt Jackson för hantering av serialisering.
2.2 Metoddiskussion
Beslutet att använda de valda tillvägagångssätten för besvarande av arbetets frågeställning fastställdes då en kombination av dem kan anses vara det lämpligaste sättet att besvara de relaterade underfrågorna.
2
PaaS: Akronym för Platform as a Service. En tjänst vars syfte är att bistå en applikation med nödvändig infrastruktur så som en Internet-anslutning och hårdvara [28].
Det är dock möjligt att rikta viss kritik mot valet av litteraturstudie som primär forsk-ningsmetod. Huvuddelen av denna kritik kan argumenteras vara faktumet att svar på den frågeställning som behandlas blir beroende av det specifika forskningsmaterial som finns att tillgå vid den slutliga analysen. Detta innebär att en felaktig, eller ofullständig, lit-teratursökning kan färga det slutliga resultatet och på så vis leda till en vinklad bild av det område som granskas. Gällande det praktiska genomförandet av sökningen går dessa problem sannolikt att motverka genom att använda sig av god metodik och en strukture-rad sökprocess. Externa faktorer, så som problem hos använda databaser eller bristande tillgång till material, kan dock anses vara svårare att bemöta. I övrigt kan faktumet att det analyserade materialet riskerar att vara föråldrat, och på så vis ger en inaktuell upp-fattning kring ämnet, bidra till att kvaliteten på slutresultatet blir lidande. Detta går dock till viss del att motverka genom att applicera lämpliga avgränsningar.
För att undvika problematik relaterad till sökning och tillgång till relevant material hade användning av andra forskningsmetoder kunnat övervägas. Dessa hade exempelvis kunnat utgöras av intervjuer eller enkätundersökningar riktade till forskare inom det data-vetenskapliga området. Dock hade detta presenterat ytterligare svårigheter; så som att genomföra intervjuer med ett representativt antal forskare inom den givna tidsramen. Vi-dare går det även att spekulera kring möjligheten att de forskare vars åsikter är att betrakta som relevanta i sammanhanget redan presenterat sina resultat i publicerade artiklar, varpå intervjuer eller undersökningar hade varit överflödiga i förhållande till en litteraturstudie. Då en omfattande del av frågeställningen utgörs av att undersöka akademiens åsikter och forskningsresultat kring ämnet kan en litteraturstudie därm argumenteras vara den metod att betrakta som bäst lämpad för att skapa en bred, generell uppfattning kring ämnet inom den givna tidsramen. Man kan därmed även argumentera för att en littera-turstudie hade varit tillräcklig för att inhämta de fakta och resultat som krävs för att besvara forskningsfrågorna då en utförlig, jämförande analys av det material som hittas vid en litteratursökning hade kunnat resultera i slutsatser kring frågeställningen, förutsatt att tillräcklig litteratur finns att tillgå.
Dock hade en enskild litteraturstudie lett till behovet av en mer omfattande förstudie för att kartlägga aktuella och lämpliga tekniker, ramverk och protokoll. Det kan argumenteras för att detta även hade introducerat risker kring inbördes inkompatibilitet mellan dessa, samt riskerat att rikta litteratursökningen åt ett missvisande håll.
Därför inkluderas även en experimentell implementation vilken konstruerats tillsam-mans med ett företag inom området, utifrån deras erfarenhet och expertis, och vilken an-vänds som referentiell utgångspunkt. Detta har till följd att logiska begränsningar tillämpas i studien och ger en insyn i vilka de kritiska delarna i ett sådant system är.
Den experimentella implementationen ger på så vis mervärde till studien genom att tillföra en komparativ synvinkel, då de tekniker som valts av företaget i detta arbete således agerar motpol till de tekniker som anses bäst lämpade av akademisk forskning.
3
Resultat
3.1 Litteraturstudie
Litteraturstudien resulterade i ett antal artiklar vilka behandlar de tre områden som i frågeställningen valts att representera det tänkta systemets kritiska delar.
Ett större antal relevanta artiklar rörande autentisering har hittats under studiens gång, vilka samtliga huvudsakligen berör OAuth-protokollet samt vidareutveckling av detta [15] [4] [10] [16] [3]. Materialets fokus innebär att en kvalitativt inriktad analys har kunnat genomföras där protokollets styrkor och svagheter vägs mot varandra, för att undersöka huruvida protokollet lämpar sig för det tänkta systemet.
Ett flertal artiklar kring serialisering fokuserar huvudsakligen på direkta jämförelser av prestanda mellan olika serialiseringsformat [22] [21] [25] [24] [23] [18]. Då denna aspekt be-traktas som det mest kritiska av formatens egenskaper har detta möjliggjort utförandet av en kvantitativ analys där artiklarnas slutsatser jämförts för att utläsa en allmän konsensus kring ämnet. Ett antal artiklar innefattar även jämförelser mellan andra format än de som nämns i studiens avgränsningar, och i dessa fall togs endast resultaten för de format som tidigare bedömts som relevanta med i analysen.
Endast ett mindre antal artiklar rörande parsers för det valda serialiseringsformatet har hittats, och av dessa är endast ”Performance evaluation of object serialization libraries in XML, JSON and binary formats” [26] att betrakta som faktiskt användbar. Detta då var och en av de övriga artiklarna endast inkluderat enstaka av de parsers som bedöms som lämpliga för arbetet, och en kvantitativ analys mellan dessa artiklar anses därför vara för opålitlig då experimentens förutsättningar skiljer sig i för stor omfattning.
De artiklar som hittats kring arkitektur redogör huvudsakligen för implementations-förslag och designval vid konstruktion av en REST-baserad webbtjänst [6] [7] [5] [8]. Dessa belyser till en mindre del även skillnader och likheter mellan REST och SOA.
Relevant litteratur om forskning kring programvara för plattform har visat sig va-ra i stort sett obefintlig. Konkret information kring detta område har endast kunnat utvinnas ur ”REST client pattern” [7], vilken huvudsakligen redogör för analyser kring REST-arkitektur, och således inte fokuserar på komparativ analys av plattformar för webb-tjänster. Den information som kunnat utvinnas ur denna artikel går dock inte att verifiera, då inga andra studier finns tillgängliga för jämförelse.
3.2 Experimentell implementation
Vid genomförandet av implementationen på ÅF konstruerades ett system där Jersey i kom-bination med Guja och Google App Engine utgör systemets fundament. Den programvara som utvecklades har som syfte att hantera användarkonton samt kommunikationen med yttre entiteter, exempelvis Lifelog.
3.2.1 Kommunikation
Vid val av plattform för kommunikation hade ÅF önskemål om att använda Jersey tillsam-mans med Google App Engine. Därför är denna programvara utvecklad med ramverket Jersey.
Jersey
Open Source-projektet Jersey är en referens-implementation av JAX-RS4 vilket låter ut-vecklare bygga webbtjänster i enlighet med REST [31]. REST är ett arkitekturellt de-signmönster för att skapa webbtjänster som minimerar både väntetider (en. latency) och nätverkskommunikation samt strävar efter att förenkla caching och möjligheten att bygga distribuerade system [19].
Jersey abstraherar hanteringen av förfrågningar och svar över HTTP genom Java-annoteringar så som @GET, @PUT, @POST etcetera, liksom hantering av HTTP-headers och URL-parametrar. Jersey tillhandahåller även stöd för filter vilket abstraherar implemen-tation av roller i systemet och på så vis gör det möjligt att begränsa tillgång till resurser utifrån dessa [31].
Google App Engine
Google App Engine är ett SDK och en PaaS-tjänst för bland annat Java-servlets. App Engine erbjuder automatisk och sömlös upp- och nedskalning av systemresurser; vid de tillfällen då endast ett fåtal förfrågningar görs till tjänsten allokeras färre resurser än vid de tillfällen då stora antal förfrågningar görs, vilket gör det lämpligt för hosting av REST-tjänster [32].
3.2.2 Autentisering
Då systemet kräver användarkonton för att kunna aggregera data från andra källor innebär det att användare måste autentisera sig så att de endast ges tillgång till den data de är tillåtna att ta del av.
Token
Ett token är ett objekt, i denna kontext en maskingenererad textsträng, som används för att identifiera en användare [33]. Vid nyttjande av tokens kan en tjänst erhålla tillgång till en resurs på ett mer kontrollerat sätt. Då ett token kan knytas till en enskild tjänst och användare kan dessa användas för både auktorisering och autentisering [12]. Ett token kan ogiltigförklaras och på så vis återkalla tillgång för individuella tjänster, utan att tvingas återkalla tillgång för samtliga sådana [13] vilket är fallet om användaren istället delar med sig av sina inloggningsuppgifter i klartext [13] [10].
OAuth 2.0
OAuth5är ett protokoll för autentisering som genom tokens gör det möjligt att dela resurser mellan tjänster utan att dela användarnamn och lösenord [34].
Genom en federerad inloggning6 kan exempelvis Alice dela sina sina foton på en
foto-webbtjänst med en digital framkallningstjänst utan att framkallningstjänsten får tillgång Alice lösenord. Istället delas ett token (en. access-token) som autentiserar Alice:
1. Alice ansluter till framkallningstjänsten.
4
Specifikation JSR 311 [29] och JSR 339 [30]
5
RFC6749 [34]
2. Alice väljer att logga in på framkallningstjänsten genom foto-webbtjänsten för att ge framkallningstjänsten tillgång till bilderna.
3. Framkallningstjänsten omdirigerar Alice webbläsare till foto-webbtjänsten. 4. Alice anger sitt användarnamn och lösenord för foto-webbtjänsten.
5. Foto-webbtjänsten returnerar en URL som pekar mot foto-webbtjänstens autentise-ringsserver med en tillhörande auktoriseringskod.
6. Framkallningstjänsten validerar auktoriseringskoden hos foto-webbtjänsten genom den URL som mottogs; om den är giltig returneras en access-token och en refresh-token.
7. Nu har framkallningstjänsten tillgång till Alice bilder utan att ha kännedom om hennes lösenord till foto-webbtjänsten.
Guja
Guja är ett bibliotek för Java utvecklat av ÅF för att abstrahera och underlätta implemen-tation av OAuth 2.0 [35]. Guja stödjer Google App Engine samt federerad inloggning via Facebook utan vidare modifikation. Stöd för ytterligare tjänster implementeras med hjälp av mallar som tillhandahålls av Guja.
3.2.3 Serialisering
Då systemets syfte i grunden är att agera mellanhand för förmedling av data mellan webb-tjänst och klient behövs ett serialiserings-format för att möjliggöra att denna överföring sker på ett effektivt sätt.
JSON
JSON (JavaScript Object Notation) är ett textformat vilket primärt är konstruerat för att möjliggöra serialisering av strukturerad data samt datautbyte mellan applikationer [36]. Som namnet antyder bygger formatet på objekt-notation hämtad från JavaScript. Formatet är oberoende av plattform samt programmeringsspråk och är konstruerat för att vara lätt att läsa och tolka för både människor och maskiner [37]. Detta görs bland annat genom att göra formatet så fåordigt som möjligt.
JSON bygger på två strukturer för representation av data [37]. Den första av dessa är nyckel/värde-par där varje värde identifieras med en unik nyckel. Detta benämns ofta som ett ”JSON-objekt”. Den andra är en ordnad lista av värden eller objekt där samtliga delar en övergripande, gemensam, nyckel. Denna struktur tenderar att benämnas som en ”JSON-array”.
Jackson
Jackson är en JSON-parser för Java som sömlöst tolkar JSON och omvandlar resultatet till POJOs7 [39]. Utöver JSON hanterar Jackson även andra typer av serialiseringsformat så som XML, CSV, Smile, CBOR, Avro och YAML. För JAX-RS stöds enbart JSON, Smile, XML och CBOR.
7
3.2.4 Datakällor
Den experimentella implementationen aggregerar data från två REST-baserade webbtjäns-ter vilka båda tillhandahåller data relawebbtjäns-terad till fysisk aktivitet.
Lifelog
Nedan följer en beskrivning av Sony Lifelog, en av de valda datakällorna för den experi-mentella implementationen.
Beskrivning Lifelog valdes som den primära tjänsten för datainsamling då ÅF listade användandet av detta som ett av grundkraven för systemet.
Lifelog är en tjänst som via smartphone-applikationer, smarta klockor och aktivitets-armband samlar in data om enhetens användare [40]. Tjänsten loggar olika typer av fy-sisk aktivitet samt information kring vilka andra applikationer som körs på användarens smartphone. Insamlad data presenteras i Lifelog-applikationen för Android, eller via ett öppet REST-API.
Autentisering Tjänsten hanterar autentisering genom OAuth 2.0 i enlighet med det flöde som beskrivs i tidigare avsnitt [41]. En livslängd för utfärdad access-token inkluderas vid lyckad autentisering och då denna tid passerat måste refresh-token skickas i utbyte mot en ny access-token.
Kommunikation Tjänsten är konstruerad i form av ett REST-API på den första nivån av Leonard Richardsons mogenhetsmodell [42]. Användandet av paginering8 via hy-perlänkar vid stora datamängder kan dock betraktas som ett inslag av den tredje nivån i mogenhetsmodellen.
Tjänsten använder sig endast av HTTP-verbet GET vid anrop, och all kommunikation sker med hjälp av formatet JSON [41].
Healthgraph
Nedan följer en beskrivning av Fitnesskeeper Healthgraph, en av de valda datakällorna för den experimentella implementationen.
Beskrivning Till sekundär datakälla valdes webbtjänsten Healthgraph från företa-get Fitnesskeeper. Tjänsten aggregerar data från flera olika tjänster och applikationer vilka registrerats som samarbetspartners, och tillåter sedan uthämtning av denna via samlade ändpunkter [43]. Insamlandet av varierad data leder till att information kring flera aspek-ter av användarens hälsa och fysiska aktivitet kan hämtas beroende på vilka enheaspek-ter och tjänster som användaren nyttjar.
Autentisering Healthgraph använder sig av en förenklad implementation av OAuth 2.0 för autentisering där refresh-tokens exkluderats och utfärdade access-tokens ges en obegränsad livslängd [43]. I övrigt följer autentiseringen, precis som Lifelog, det kommuni-kationsflöde som beskrivs i tidigare avsnitt.
8
Kommunikation Healthgraph kan beskrivas som ett REST-API på den tredje nivån av Leonard Richardsons mogenhetsmodell [42]. Ett första anrop görs till en specifik änd-punkt varpå möjliga övriga resurser returneras i form av hyperlänkar [43]. Dessa resurser kan bestå både av den data som efterfrågats och av ytterligare hyperlänkar. På så sätt kan även en maskin traversera genom datan.
Tjänsten har stöd för CRUD-operationer9 och använder därmed HTTP-verben GET, PUT, POST, DELETE och HEAD [43]. Samtlig kommunikation sker i formatet JSON.
9Akronym för ”Create, Read, Update, Remove” vilket avser de operationer som kan utföras på
4
Analys
4.1 Auktorisering och autentisering
Vid hantering av personlig data är en viktig del att säkerställa att den endast är tillgänglig för de- eller dem den är avsedd för. Genom autentisering identifierar användaren vem han eller hon är, och genom auktorisering fastställs vilken data användaren har rätt att ta del av [12].
Följande avsnitt behandlar tekniker och system för auktorisering och autentisering av användare för den typ av system som avses i arbetets frågeställning. Följande sektion fokuserar primärt på OAuth då de sökningar som genomfördes i början av studien påvisade en brist på lämpliga alternativ.
En relevant aspekt kring OAuth är möjligheten till federerad auktorisering. Denna typ av auktorisering benämns som trebent OAuth-auktorisering [44], vilket innebär att använ-dare auktoriseras genom en tjänst de redan är registrerade hos, varpå denna tjänst intygar användarens identitet till det ursprungliga systemet. På så sätt undviks hantering av käns-liga användaruppgifter på ursprungssystemet, så som lösenord. I sektion 4.1.1 behandlas hur trebent auktorisering även kan användas för autentisering.
I kontrast till de vinster kring effektivitet som federerad auktorisering och autentisering OAuth erbjuder påvisar Vapen, Carlsson, Mahanti m. fl. [4] de integritetsrelaterade risker som federerad auktorisering medför. I studien kategoriseras tjänster som tillhandahåller federerad auktorisering (IDP, identity provider) utifrån vilken typ av data en tredjeparts-tjänst (RP, relying party) ges tillgång till. I studiens lägsta skala erhålls en RP tillgång till grundläggande information så som användarnamn och epost-adress samt rättighet att utföra handlingar på användarens konto, exempelvis hämta en bild från kontot. Högsta graden i studiens riskskala avser möjligheten för en RP att ta del av ovanstående rättigheter men även användarens personliga information10, information om användarens vänner samt information om exempelvis ”likes” och andra tjänst-specifika handlingar som användaren utfört på IDP-tjänsten.
Shehab, Marouf och Hudel [3] presenterar i sin studie ett system som analyserar de rättigheter en RP förfrågar av en IDP och utifrån resultatet av denna analys ger användare en rekommendation om huruvida förfrågan är rimlig i förhållande till den service som RP-tjänsten erbjuder. Ett system som detta skulle kunna ge råd för användare likt den klassificering Vapen, Carlsson, Mahanti m. fl. genomför i sin studie. Shehab, Marouf och Hudel argumenterar för att systemet de utvecklat minskar risken för användare att dela mer data än de är medvetna om, vilket Vapen, Carlsson, Mahanti m. fl. belyser som en brist i den nuvarande specifikationen av OAuth.
De tjänster som används för tillhandahållande av data i implementationen hos ÅF kan klassificeras mellan den lägsta och näst lägsta graden i studien utförd av Vapen, Carlsson, Mahanti m. fl., då Healthgraph och Lifelog i egenskap som IDP endast delar grundläggande information samt data om fysisk aktivitet om respektive användare. Genom användandet av trebent OAuth-auktorisering minimeras insamlandet av data om användare, och även inräknat den data som tillhandahålls av datakällorna skulle en användare ej kunna knytas till en person genom annat än sin epost-adress.
4.1.1 Dokumentation
Chen, Pei, Chen m. fl. [15] belyser i sin studie att OAuth är ett protokoll utvecklat primärt för auktorisering på webbsidor, vilket stärks i den officiella dokumentationen [34]. Chen, Pei, Chen m. fl. hävdar i sin studie att OAuth på grund av otydlig dokumentation övergått till att även användas för autentisering.
Dokumentationen för OAuth beskriver flertalet typer av implementation. Enligt Chen, Pei, Chen m. fl. används endast följande tre i praktiken:
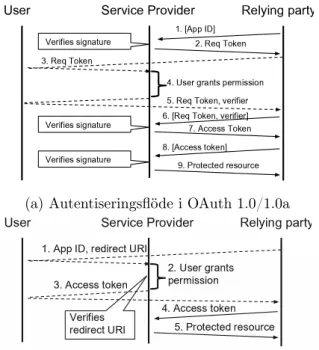
• OAuth 1.0 & OAuth 1.0a: vid användande av OAuth 1 finns endast ett möjligt sätt att implementera autentisering, se Figur 1a.
• OAuth 2.0, implicit godkännande: vid användande av OAuth 2.0 kan ett implicit godkännande göras, se Figur 1b. Vid ett implicit godkännande överförs access tokens direkt till klienten och då OAuth 2.0, till skillnad mot OAuth 1, saknar stöd för signering av tokens möjliggör detta för en tredje part att kapa ett access token och återanvända för att förfalska en inloggning. Därför är implicit godkännande ej lämpligt för autentisering.
• OAuth 2.0, godkännande via auktoriseringskod: vid användande av auktori-seringskod flyttas den sårbara delen av godkännandet från att överföras från server till klient till att överföras direkt från server till server, vilket gör det svårare för en tredje part att kapa det access token som utbytes, se Figur 1c. I systemet som utvecklats i samband med denna uppsats nyttjas denna typ av implementation. Otydlig dokumentation försvårar för utvecklare och gör autentisering- och auktoriserings-mekanismer sårbara vilket Chen, Pei, Chen m. fl. stärker i sin studie då de fann att 149 applikationer av totalt 600 använde OAuth varpå 59,7% av dessa var sårbara på grund av bristfällig implementation. Urvalet gjordes systematiskt och bestod av 300 applikationer för Android och 300 applikationer för IOS.
Fremantle, Aziz, Kopecký m. fl. [10] hävdar att OAuth skalar väl, vilket innebär att prestanda och stabilitet bibehålls även under varierat och ökat användande [11], och det faktum att företag som Google, Facebook, Twitter och GitHub nyttjar protokollet för att skydda och möjliggöra tillgång till deras APIer kan ses som bevis för att OAuth är lämpligt i globala system med krav på hög tillgänglighet och prestanda. Backere, Hanssens, Heynssens m. fl. [16] påvisar dock i sin studie att OAuth ej följer de principer som REST främjar kring ”statelessness”, att klienten hanterar och anger all nödvändig data vid varje enskilt anrop i motsats till att servern lagrar denna data mellan anrop, då OAuth kräver att servern kan validera det token som används för auktorisering. Ramasahayam och Deters [8] påstår i sin studie att denna egenskap är avgörande för möjligheten att skala horisontellt över flera servrar placerade på fysiskt skilda platser.
Då OAuth bygger på tokens för autentisering och auktorisering bör de aspekter som nämns i sektion 3.2.2 kring ämnet tas i beaktande.
Vad som kunde deduceras kring OAuth vid konstruktion av systemet på ÅF stärkte flera av ovannämnda påståenden; att använda tokens underlättade utvecklingen då de svårigheter som rör säkerhet kring användaruppgifter i stora drag undviks, eftersom detta moment kan substitueras av trebent OAuth-autentisering. Detta kan även generaliseras
(a) Autentiseringsflöde i OAuth 1.0/1.0a
(b) Autentiseringsflöde för OAuth 2.0 genom im-plicit godkännande
(c) Autentiseringsflöde för OAuth 2.0 genom auk-toriseringskod
Figur 1: Autentiseringsflöden för OAuth 1.0(a) och 2.0, illustrerade av Chen, Pei, Chen m. fl. [15]
för många andra former av dataaggregeringssystem i de fall då minst en datakälla nyttjar OAuth.
För att undvika många av de svårigheter som nämns ovan kring bristande dokumenta-tion användes OAuth-biblioteket Guja vid implementadokumenta-tion, vilket hanterade autentisering och auktorisering i systemet.
4.1.2 Alternativ
Det finns en uppsjö alternativ till OAuth för att tillhandahålla och autentisering-lösningar. I de sökningar som genomfördes vid studiens början tydliggjordes dock att kra-ven på systemet endast lämnade OAuth som ett adekvat alternativ. Övriga lösningar så som Kerberos och SAML tillför krav på XML-baserad kommunikation och dedikerade autentisering-servrar, i motsats till OAuth som lämnar val av serialiseringsformat öppet och som genom trebent autentisering låter användare autentiseras via en tredjepart-server. Vidare sker autentisering till systemets datakällor via OAuth 2.0 vilket gör ett separat autentiseringsystem redundant till trebent autentisering.
4.2 Serialisering
Vid överföring av data kan valet av serialiseringsformat påverka både systemets prestanda och användarvänlighet. Detta då egenskaper så som storlek på serialiserad data bland annat kan resultera i längre överföringstider. Serialisering och deserialisering av data till och från serialiseringsformaten hanteras av en typ av mjukvara kallad ”parser”. Då integration av flera format kräver mer tid innebär detta även att implementation av lågpresterande format bör undvikas för att säkerställa effektivitet under utvecklingen.
I delarna nedan redogörs för den analys som gjordes kring serialiseringsformat samt relaterad parser.
4.2.1 Format Inkluderade format
Då JSON och XML kan betraktas som två av de mest använda formaten för serialisering i samband med webbtjänster begränsades litteraturstudien medvetet till att fokusera på dessa (se 2.1.1). Vidare innebar begränsningen till en REST-baserad webbtjänst även att binära format så som Googles Protocol Buffers [45] eller Apache Thrift [46] inte kunde betraktas som gångbara alternativ, trots att ett flertal studier har visat på att dessa ten-derar att prestera betydligt bättre än textbaserade format vid överföring, samt generellt uppvisar mindre storlek för serialiserad data [18] [26].
XML (Extensible Markup Language) är ett märkspråk vilket bygger på SGML (Stan-dard Generalized Markup Language) [47]. Formatet skapades för att förmedla strukturerad data över Internet i form av dokument vilka själva kan beskriva sin data, samt strukturen för denna, med hjälp av taggar. Strukturen i ett XML-dokument är på så vis mycket lik den hos ett HTML-dokument, och dokumenten är läsbara för både människor och maskiner.
JSON (JavaScript Object Notation) är ett textbaserat format för datautväxling och bygger på objekt-notation hämtad från JavaScript [36]. Formatet skapades huvudsakligen för att förmedla serialiserad data i läsbar form, med så få redundanta tecken som möjligt.
Jämförelse
Genom åren har ett flertal akademiska experiment genomförts med syftet att jämföra de två formatens effektivitet vid överföring, serialisering, samt deserialisering. Då båda formaten är plattformsoberoende har dessa experiment genomförts på en uppsättning olika plattformar och system. Lin, Chen, Chen m. fl. [21] och Wang, Wu och Yang [22] jämför de två formaten vid användande med AJAX-baserade applikationer, och resultaten från båda experimenten visar på att JSON på denna plattform uppvisar betydligt lägre tid för överföring av data mellan klient och server, samt deserialisering av denna på klientsidan. Den snabbare överföringshastigheten argumenteras vara ett resultat av den lägre storlek på serialiserad data som JSON uppvisar. Denna storleksskillnad grundar sig i faktumet att JSON använder en nyckel-värde-baserad struktur där varje dataobjekt har en associerad nyckel, och de två är åtskilda med ett skiljetecken. Då ett dataobjekt även kan bestå av en array innebär detta att flera värden kan representeras med hjälp av endast en nyckel [36]. Detta leder till betydligt färre redundanta tecken än vid användande av XML där varje värde kräver en start- och en sluttagg [21] [22] [47].
Då den typ av system som avses i arbetets frågeställning bör kunna förmedla data oberoende av plattform är det viktigt att även ta mobila enheter i beaktande vid ut-värdering av serialiseringsformat. Sumaray och Makki [18] visar med sitt experiment på Android-baserade enheter att JSON uppvisar lägre tider än XML vid både serialisering och deserialisering på denna plattform. Vidare påvisas även här faktumet att data serialiserad med JSON-formatet använder sig av betydligt färre bytes vid lagring i jämförelse med samma data serialiserad som XML. Detta leder dem till slutsatsen att ”XML bör undvikas om ej nödvändigt, då JSON är ett överlägset alternativ”.
Även Hameseder, Fowler och Petersons [25] experiment utfört på Apples Iphone påvisar att JSON tenderar att använda kortare tid för deserialisering och överföring över nätverk. Vid serialisering av data uppvisar dock XML ett tidsmässigt övertag på denna plattform. Hameseder, Fowler och Peterson belyser emellertid att experimentets resultat inte kan användas till att dra vidare slutsatser kring formatens effektivitet på andra plattformar, då de exakta tiderna för serialisering och deserialisering är beroende av de bibliotek som valts för parsing.
Aihkisalo och Paaso [24] genomför jämförelser av serialiseringsformat vid användande av REST och SOAP vilka styrker påståendet att valet av parser är en av de mest kritiska faktorerna vid jämförelse av formaten. Vid förmedling av serialiserade POJO-objekt pre-sterar JSON här tidsmässigt marginellt bättre än XML, och uppvisar en mindre storlek för serialiserad data. Denna storleksskillnad minskar dock vid överföring av binärdata, och de tidsmässiga skillnaderna skiftar även till att utgöra en marginell fördel för XML. Aih-kisalo och Paaso påpekar själva att den parser som valts för hantering av JSON upplevs ha bristande prestanda vid serialisering och deserialisering vilket innebär att de fördelar som JSON tenderar att vinna på sina lägre överföringstider över nätverk går förlorade. Vidare påstår de även att förutsättningarna för experimentet inte speglar ett verkligt an-vändningsscenario då det ett slutet, lokalt, nätverk används vilket även det motverkar de fördelar som en lägre storlek ger vid överföring.
Som Hameseder, Fowler och Peterson och Aihkisalo och Paaso påpekar är de specifika tider som uppmäts för serialisering och deserialisering starkt beroende av de parsers som väljs för uppgiften. Nurseitov, Paulson, Reynolds m. fl. [23] påpekar även att faktorer så som belastning på det använda nätverket kan leda till att denna mätdata blir förvrängd.
Ett försök att motverka effekter från dessa typer av felkällor görs i denna uppsats med hjälp av inkluderandet av ett flertal experiment på flera olika plattformar, vilket möjlig-gör jämförelse av de två formatens tidsmässiga skillnader utan att fokusera på specifika, kvantitativa, resultat.
Vid konstruktion av den experimentella implementationen inkluderades JSON som enskilt serialiseringsformat. Detta beslut fattades huvudsakligen då den allmänna uppfatt-ningen hos utvecklare tenderar att vara att JSON presterar bättre än XML vad gäller överföringshastighet samt storlek vid serialisering. Granskning av den insamlade litteratu-ren visar på att detta antagande har stöd i den akademiska forskningen. Detta innebär att valet JSON över XML är att betrakta som relativt självklart vid konstruktion av en REST-baserad webbtjänst, i de fall där det endast är möjligt att implementera ett enskilt format samt där prestanda är den huvudsakliga prioriteringen. Wang, Wu och Yang belyser dock att XML har styrkor inom andra områden än datautväxling, så som en bättre etablerad standard samt en förbättrad säkerhet. Vidare bör valet av format även anpassas efter de tjänster som systemet är tänkt att kommunicera med, för att undvika onödig konvertering mellan format.
4.2.2 Parser
Då JSON i föregående stycke konstaterades vara det lämpligaste formatet för serialisering i denna typ av system utgör detta den främsta avgränsningen för valet av parser. Vidare innebär arbetets fokus på ett Java-baserat system att de möjliga valen av parsers avgränsas ytterligare.
Mängden komparativ, akademisk, forskning kring detta ämne, med tidigare nämnda av-gränsningar applicerade, är mycket begränsad. Bristen på relevant material innebär att en slutsats baserad enbart på akademisk litteratur är svår att fastslå. Detta huvudsakligen då prestanda vid serialisering och deserialisering kan anses vara de mest kritiska egenskaperna hos en parser, och jämförelse av prestanda via meta-analys inte är tillrådlig då variabler så som systemresurser och nätverkstrafik tenderar att variera mellan olika experiment [23].
Maeda [26] utför ett experiment där serialiserings- och deserialiseringstider hos bland annat ett flertal Java-baserade JSON-parsers jämförs. Resultaten visar på att biblioteket JsonSmart är den bäst presterande JSON-parsern vid deserialisering, medan Jackson är den bäst presterande JSON-parsern vid serialisering.
Även Aihkisalo och Paaso [27] jämför ett flertal parsers, men med nästintill obefintlig överlappning med Maeda vad gäller valet av granskade parsers, med undantag för inklu-derandet av Jackson. Detta innebär att en direkt jämförelse av artiklarnas kombinerade resultat blir opålitligt då förutsättningarna skiljer sig i för stor utsträckning.
Faktumet att utbudet av tidigare forskning kring ämnet anses vara för litet hindrar möjligheterna att nå fram till en akademiskt grundad slutsats. Då Jackson inkluderas i Jersey [31] kan detta argumenteras ha varit det mest effektiva alternativet av parser för den experimentella implementationen ur ett implementationsperspektiv, då inkluderandet av detta ramverk vid konstruktion av systemet hos ÅF påskyndade utvecklingen markant. Jacksons prestanda i förhållande till andra alternativ kräver dock ytterligare forskning. Vidare tillåter Jackson även hantering av XML vilket även underlättar vid implementation av detta format [39] [31]. Huruvida detta val av parser kan anses vara det mest effektiva vid konstruktion av Java-baserade dataaggregeringstjänster överlag går dock ej att avgöra
på grund av det låga antalet relevanta artiklar. 4.3 Kommunikation
För att systemet ska kunna genomföra utväxling av data med dess klienter krävs en platt-form vilken kan hantera inkommande- och utgående kommunikation, vilken sker i enlighet med den arkitektur för webbtjänster som använts vid konstruktion. Plattformen utgörs av en programvara, eller ramverk, vilket abstraherar aspekter så som nätverkskommunikation för att på så vis effektivisera utvecklingsprocessen.
4.3.1 Arkitektur
Två av de största arkitekturella inriktningarna vid konstruktion av en webbtjänst och dess funktionalitet är REST och SOA. Dessa bemöter båda problematiken kring datautväx-ling över större nätverk, men använder sig av markant åtskilda inriktningar vad gäller konstruktion och funktionalitet [42] [48].
Niu, Yang och Zhang [5] undersöker hur REST-principer kan förenkla utveckling av webbtjänster ur ett utvecklingsperspektiv. De påvisar att REST jämfört med RPC11 ökar möjligheterna för en utvecklare att återanvända kod i de fall då klienter kan nyttja en mellanhand för parsing. REST kan i dessa fall möjliggöra sömlös transformation till ett plattformsspecifikt objektformat, exempelvis JSON till POJO. Med dessa förutsättningar kan utvecklare fokusera på att utveckla affärslogik istället för plattformsspecifika server-anrop. Författarna konstaterar även att REST bibehåller låg koppling (en. coupling ) mellan server och klient till skillnad mot RPC. Detta tillåter vissa förändringar på servern utan att påverka funktionalitet på klienten. Exempelvis skulle samtliga URLer på Healthgraph, med undantag av den bas-URI12 Healthgraph anger som statisk, kunna ändras utan att detta skulle påverka den experimentella implementationen i denna studie, då uthämtning av dessa URLer sker dynamiskt [49].
Ramasahayam och Deters [8] finner i sin studie att SOA-baserade system kan ha svå-righeter att köras på PaaS-tjänser på grund av de långa körtider som SOA medför. Exem-pelvis skulle detta innebär problem i systemet på ÅF då de förfrågningar som tar mer än 30 sekunder att slutföra negligeras av Google App Engine.
De krav som ställdes på systemet hos ÅF kring kommunikation var relativt simp-la; systemet består ej av långa eller komplexa flöden av anrop, utan begränsas till ett autentiserings-anrop följt av ett anrop för uthämtning av data. I system som saknar avan-cerade flöden kan en REST-arkitektur anses mer lämplig då en sådan bibehåller låg eller ingen koppling mellan anrop [5] [6], och i många avseenden anses erbjuda högre prestanda i förhållande till tillgängliga systemresurser jämfört mot en baserad tjänst. En SOA-arkitektur lämpar sig bättre i system som involverar mer invecklade procedurer, exempelvis vid transaktioner mellan banker eller bokningssystem, där en operation (t.ex. bokning av en biljett) sker över flertalet steg med flera olika val och flöden [48].
Att istället utveckla systemet hos ÅF som ett SOA-baserat system skulle ha varit tekniskt möjligt, men sett till vad som kan deduceras från denna litteraturstudie skulle det varit högst ineffektivt. Kompatibilitet med Google App Engine hade kvarstått som
11
Remote Procedure Call, exempelvis SOA
ett problem och då samtliga datakällor är JSON-baserade hade detta introducerat parsing från XML till JSON då SOA är ett XML-baserat protokoll. I ”REST client pattern” [7] skriver Upadhyaya att stora företag så som Yahoo och Amazon fokuserar alltmer på att utveckla REST-tjänster snarare än SOA-baserade tjänster. Vidare påpekar författaren att detta har lett till bättre verktyg för utvecklare, och även fler och mer stabila ramverk. 4.3.2 Plattform
För att dataagreggeringstjänster ska kunna hantera inkommande- och utgående dataför-medling krävs ett ramverk vilket hanterar detta genom att möjliggöra kommunikation i enlighet med den etablerade REST-arkitekturen [42] vilken i tidigare avsnitt konstaterades vara bäst lämpad för användning med den typ av system som avses i arbetets frågeställning. Sökandet efter material inom detta område påvisar en tydlig lucka inom tidigare akade-misk forskning. Detta då inget material redogörande för resultat från komparativa studier kring Java-baserade ramverk för utveckling av webbtjänster har hittats vid litteratursök-ningen. Den artikel som hittades och kan anses någorlunda relevant redogör endast för översiktlig fakta kring flertalet ramverks uppbyggnad, och utelämnar därmed redogörel-ser för prestanda och andra kvantitativa aspekter [9]. Den resulterade litteraturen anses därmed vara för knapphändig för att möjliggöra fattande av en korrekt och akademiskt grundad slutsats kring den programvara som anses vara den bäst lämpade för detta an-vändningsområde.
Vid projektets början listade ÅF användandet av det REST-orienterade ramverket Jer-sey [31] som ett av grundkraven för systemet. Då ramverket har stöd för JAX-RS samt inkluderar parser-biblioteket Jackson [39] bidrar det därmed även med funktionalitet till andra områden än endast kommunikation. Upadhyaya [7] påstår även i ”REST client pat-tern” [7] att Jersey generellt anses använda få systemresurser, vilket är en kritisk egenskap hos programvara som används på PaaS-tjänster så som Google App Engine. Något material som styrker eller dementerar Upadhyayas påstående finns dock inte att tillgå.
Med ovan nämnda egenskaper i åtanke kan Jersey argumenteras vara ett av de mest effektiva ramverken att inkludera i den experimentella implementationen i detta arbete, även frånsett det implicita kravet från ÅF. Detta då stöd för flertalet av de tekniker som granskats i detta arbete finns inkluderade i Jersey, så som Jackson [39]. Som tidigare nämnt påskyndade inkluderingen av detta ramverk utvecklingsprocessen av den experimentella implementationen markant, och påvisade klara fördelar med användningen av detta. Då akademiskt grundade slutsatser inte är möjliga att uppnå är det dock inte möjligt att avgöra huruvida Jersey presterar bättre prestandamässigt än alternativa ramverk. Därmed går det inte heller att påvisa huruvida Jersey kan anses vara det mest effektiva alternativet av plattform vid implementation för Java-baserade dataaggregeringstjänster överlag.
5
Diskussion
5.1 FrågeställningDå frågeställningen till en början upplevdes som bred applicerades en rad avgränsningar i ett försök att åtgärda detta. Dessa avgränsningar är huvudsakligen ett resultat av de krav som ÅF ställde på den experimentella implementationen, men bygger även till viss del på kunskap som förvärvats via sökningar genomförda före arbetets början. Det kan dock argumenteras för att frågeställningen trots dessa begränsningar är för omfattande. Detta då samtliga av de områden som berörs i arbetets analys kan utgöra grund för fristående, individuella studier.
Samtidigt som de applicerade avgränsningarna på ett sätt har lyckats med att göra frågeställningen smalare, innebär de även att det granskade området blivit begränsat till en enskild typ av dataagreggeringstjänst. Detta gör att de slutsatser som konstaterats i litteraturstudien kan anses svåra att generalisera. Ett försök att motverka detta, och på så vis generalisera besvarandet av frågeställningen, har gjorts genom att granska serialisering, auktorisering och kommunikation individuellt vilket låter resultatet appliceras på andra system än det specifika system som redogörs för i detta arbete.
5.2 Litteraturstudie 5.2.1 Sökning
Valet att avgränsa sökandet av litteratur till endast IEEE Xplore och ACM DL visade sig mer problematiskt än väntat då de båda tjänsternas sökmotorer uppvisar vitt skilda beteenden vid specifika anrop. Inkluderandet av så kallade ”jokertecken”13 resulterar i
ra-dikalt olika träffar mellan de båda tjänsterna, och i dokumentationen för ACM DL finns tvetydigheter kring hur jokertecken bör definieras. Detta har lett till att ett stort antal sökningar fått göras flera gånger för att försäkra sig om att de blivit korrekt utförda, men trots dessa upprepade försök skiljer sig det slutliga antalet träffar markant mellan de två databaserna. Huruvida denna diskrepans är ett resultat av sökmotorernas funktionalitet eller beror på skillnader i tjänsternas utbud är dock oklart.
5.2.2 Material
Det faktum att arbetet begränsats till ett specifikt programmeringsspråk innebär att det studerade området blivit smalt och således lämnar en omfattande lucka i granskandet av tillgänglig teknik. Detta bidrar till komplikationer i form av otillräckliga mängder akade-misk litteratur. Denna begränsning påvisar även ett av problemen med att inkludera- och anpassa avgränsningar efter en experimentell implementation i samarbete med en tredje part, vilken i detta arbete utgörs av ÅF. Detta då de krav som ställdes på programme-ringsspråk och val av programvara bidragit till projektets smala fokus.
Vid genomförandet av litteraturstudien blev det uppenbart att artiklar rörande spe-cifika ämnesområden tenderar att behandla ämnet på likartade sätt, oavsett författare. Akademisk litteratur kring OAuth fokuserar till stor del på brister i protokollet eller hur det kan utökas till att bidra med ytterligare funktionalitet, medan akademisk litteratur
rörande serialisering främst handlar om olika jämförelser av prestanda. Övrig problema-tik kring denna typ av jämförelser är att konkreta slutsatser blir svåra att nå i de fall där de utförda experimenten inte har samma förutsättningar vad gäller programvara eller systemresurser.
Akademisk litteratur om specifika implementationer och programvaror så som Jersey och Jackson är näst intill obefintlig. Sådan litteratur hade möjligen kunnat bidra till mer konkreta slutsatser kring frågeställningen och således även möjliggjort reflektioner kring val av teknik i den experimentella implementationen. Det kan argumenteras för att dessa luckor i litteraturstudien kunnat undvikas med hjälp av en mer utförlig förstudie kring tillgänglig litteratur, för att sedan anpassa frågeställningen till att inte fokusera på specifika implementationer och programvaror. Dock hade detta även resulterat i att bristerna i tidigare forskning inte hade redogjorts för i detta arbete.
5.3 Experimentell implementation
Att implementera det experimentella systemet bidrog till möjligheten att undersöka hur ett system likt det som nämns i frågeställningen kan konstrueras i praktiken. Avsaknaden av ett referenssystem leder dock till att slutsatser om dessa komponenters effektivitet vid implementation enbart kan bedömas utifrån empiri.
Tidsåtgång för genomförandet av implementationen bör även tas i beaktning då litte-raturstudiens omfattning troligtvis hade kunnat breddas om den praktiska konstruktionen utelämnats. Detta då tiden för genomförandet av arbetet var begränsad, och exkluderande av detta moment hade troligen gett möjlighet att disponera tid till att undersöka ytterligare komponenter i en dataaggregeringstjänst.
Genomförandet av den experimentella implementationen i samarbete med en extern aktör har bidragit med insikter i hur denna typ av system kan implementeras i en före-tagsmiljö, och leder på så vis till en kontrast gentemot de strikt akademiska infallsvinklar som granskats i litteraturstudien. Detta då inkluderandet av implementationen i uppsatsen som en referentiell utångspunkt och motpol till de tekniker som litteraturstudien funnit lämpliga medförde att rationella begränsningar tillämpades i studien och gav en insyn i vilka de kritiska delarna i ett sådant system är. Detta har dock lett till ett smalare område att granska, vilket medför både för- och nackdelar.
Motargument till användandet av denna implementation kan dock vara att de program-varor och ramverk som förespråkas av ÅF inte är representativa för industrin överlag, och på så vis leder till en vinklad utgångspunkt.
6
Slutsatser och vidare forskning
Litteratur grundad i akademisk forskning kring specifika implementationer och programva-ror inom det granskade området tycks bristande, och leder till att konkreta slutsatser kring fråga 1 i studiens frågeställning är svåra att nå. Detta då en utförlig lista över samtliga möjliga tekniker inte går att sammanställa utifrån den tillgängliga akademiska litteraturen. I de fall där mängden relevant akademisk litteratur ansågs tillräcklig kan dock ett antal rekommenderade tekniker utläsas vilka utgjordes av OAuth 2.0 för autentisering, JSON som serialiseringsformat samt REST som kommunikationsarkitektur. Detta besvarar till viss grad fråga 2 i frågeställningen, men slutsatser kring rekommenderade programvaror går inte att fastslå utifrån resultatet av litteraturstudien. Förslag på vidare forskning utgörs därmed av komparativa studier mellan specifika programvaror och ramverk vilka används för konstruktion av webbtjänster och dataagreggeringssystem.
De rekommenderade teknikerna tycks korrelera väl med de val som gjorts av företaget i studien. Dock saknas belägg för att påvisa en genuin korrelation mellan industrin och akademin, och på så vis utesluta ett sammanträffande.
De tekniker som utgör svar på fråga 2 bidrar även till att besvara fråga 3 i frågeställ-ningen, då tredjeparts-aktörer kan implementera dessa för att underlätta användande vid utveckling av nya tjänster.
Referenser
[1] ProgrammableWeb. (2015). Programmableweb - apis, mashups and the web as plat-form. [Accessed May 18 2015], URL: http://www.programmableweb.com/.
[2] M. Nauman, S. Khan, A. T. Othman, S. ulniza Musa och N. U. Rehman, ”Poauth: privacy-aware open authorization for native apps on smartphone platforms”, i Pro-ceedings of the 6th International Conference on Ubiquitous Information Manage-ment and Communication, ser. ICUIMC ’12, Kuala Lumpur, Malaysia: ACM, 2012, 60:1–60:8, isbn: 978-1-4503-1172-4. doi: 10.1145/2184751.2184825. URL: http: //doi.acm.org/10.1145/2184751.2184825.
[3] M. Shehab, S. Marouf och C. Hudel, ”Roauth: recommendation based open autho-rization”, i Proceedings of the Seventh Symposium on Usable Privacy and Security, ser. SOUPS ’11, Pittsburgh, Pennsylvania: ACM, 2011, 11:1–11:12, isbn: 978-1-4503-0911-0. doi: 10.1145/2078827.2078842. URL: http://doi.acm.org/10.1145/ 2078827.2078842.
[4] A. Vapen, N. Carlsson, A. Mahanti och N. Shahmehri, ”Information sharing and user privacy in the third-party identity management landscape”, i Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, ser. CODASPY ’15, San Antonio, Texas, USA: ACM, 2015, s. 151–153, isbn: 978-1-4503-3191-3. doi: 10. 1145/2699026.2699131. URL: http://doi.acm.org/10.1145/2699026.2699131. [5] Z. Niu, C. Yang och Y. Zhang, ”A design of cross-terminal web system based on
json and rest”, i Software Engineering and Service Science (ICSESS), 2014 5th IEEE International Conference on, juni 2014, s. 904–907. doi: 10.1109/ICSESS.2014. 6933711.
[6] S. Schreier, ”Modeling restful applications”, i Proceedings of the Second International Workshop on RESTful Design, ser. WS-REST ’11, Hyderabad, India: ACM, 2011, s. 15–21, isbn: 978-1-4503-0623-2. doi: 10.1145/1967428.1967434. URL: http: //doi.acm.org/10.1145/1967428.1967434.
[7] B. P. Upadhyaya, ”Rest client pattern”, i Industrial Electronics (ISIE), 2014 IEEE 23rd International Symposium on, juni 2014, s. 231–235. doi: 10.1109/ISIE.2014. 6864616.
[8] R. Ramasahayam och R. Deters, ”Is the cloud the answer to scalability of ecologies? using gae to enable horizontal scalability”, i Digital Ecosystems and Technologies Conference (DEST), 2011 Proceedings of the 5th IEEE International Conference on, maj 2011, s. 317–323. doi: 10.1109/DEST.2011.5936602.
[9] L. Hongjun, ”Restful web service frameworks in java”, i Signal Processing, Commu-nications and Computing (ICSPCC), 2011 IEEE International Conference on, sept. 2011, s. 1–4. doi: 10.1109/ICSPCC.2011.6061739.
[10] P. Fremantle, B. Aziz, J. Kopecký och P. Scott, ”Federated identity and access ma-nagement for the internet of things”, i Secure Internet of Things (SIoT), 2014 Inter-national Workshop on, sept. 2014, s. 10–17. doi: 10.1109/SIoT.2014.8.