Evaluering av
prestanda mellan
RestSharp och Flurl
HUVUDOMRÅDE Datateknik
FÖRFATTARE: Fredric Lundberg Andersson, Joakim Brandt HANDLEDARE: Muhammad Ismail
Examinator: Johannes Schmidt Handledare: Muhammad Ismail Omfång: 15 hp (grundnivå) Datum: 24 augusti 2020
Postadress: Besöksadress: Telefon:
Box 1026 Gjuterigatan 5 036-10 10 00 (vx) 551 11 Jönköping
Förord
Vi vill tacka vår handledare Ismail Muhammad och Consid AB, speciellt Sebastian Öwall, för stöd och hjälp vid skrivandet av denna högskoleingenjörsuppsats.
Speciellt tack till Marcus Gullstrand som hjälpte oss med värdefulla insikter vid skri-vandet, och till Anders Andersson för hjälpen med vår statistiska analys.
Abstract
Purpose - To examine if there is any difference in performance between the two HTTP clients RestSharp and Flurl, to make it easier for developers and companies when deve-loping software.
Method - A comparative study with a hypothesis based on earlier studies are tested with experiments, code analytics and reviewing literature.
Findings - Both client libraries have similar performance when fetching small amounts of data. Flurl is performing better than RestSharp when the amount of data increases and the amount of parallel calls increase.
Implications - This study contributes to a field where little to no research exists cur-rently. The study facilitates the choice on which HTTP client library is more preferable to use.
Limitations - The study only includes RestSharp and Flurl, and no conclusions can be applied to any other HTTP clients, any other frameworks or environments.
Sammanfattning
Syfte - Syftet med studien var att undersöka om det finns någon skillnad i prestanda mellan HTTP-klienterna RestSharp och Flurl, så det blir enklare för utvecklare och fö-retag när de väljer mjukvara.
Metod - En jämförande studie som baserat på tidigare forskning och litteraturstudier formulerat en hypotes som beprövats genom olika experiment.
Resultat - Båda klienterna har snarlik prestanda vid hämtning av mindre mängder data. Flurl presterar bättre än RestSharp när mängden data och antalet parallella anrop ökar. Implikationer - Den här studien bidrar till ett fält där det finns ett väldigt smalt urval av tidigare forskning. Studien underlättar vid valet av bibliotek för datahämtning över HTTP.
Begränsningar - Studien omfattar enbart RestSharp och Flurl, inga slutsatser kan ap-pliceras på andra HTTP-klienter, ramverk eller utvecklingsmiljöer.
Innehåll
1 Introduktion 1
1.1 Bakgrund . . . 1
1.2 Problembeskrivning . . . 2
1.3 Syfte och frågeställningar . . . 4
1.3.1 Frågeställningar . . . 4
1.4 Omfång och avgränsningar . . . 4
1.5 Disposition . . . 5
1.6 Begreppsdefinition . . . 6
2 Teoretisk bakgrund 7 2.1 Tidigare forskning . . . 7
2.2 Vad en HTTP-klient är . . . 7
2.3 Ursprungsklasser för RestSharp och Flurl . . . 8
2.4 RestSharp . . . 8 2.4.1 RestSharps kodbas . . . 9 2.5 Flurl . . . 9 2.5.1 Flurls kodbas . . . 10 2.6 REST API . . . 11 2.7 Databas . . . 12 2.8 Caching . . . 12 2.9 Kompression . . . 12
3 Metod och genomförande 13 3.1 Koppling mellan frågeställningar och metod . . . 13
3.2 Hypotes . . . 14 3.3 Arbetsprocessen . . . 14 3.3.1 Utvecklingsmiljöer . . . 14 3.3.2 Enhet . . . 15 3.3.3 Implementation . . . 15 3.4 Design . . . 21 3.5 Datainsamling . . . 22 3.5.1 Förexperiment . . . 22 3.6 Dataanalys . . . 23 3.6.1 Standardavvikelse . . . 24 3.6.2 Signifikansanalys . . . 24
3.8 Validitet och reliabilitet . . . 28
4 Empiri 29 4.1 Empiri från experiment med cache . . . 29
4.2 Empiri från experiment utan cache . . . 32
5 Analys 35 5.1 Frågeställning 1 . . . 35
5.1.1 Analys av experiment med cache . . . 35
5.1.2 Analys av experiment utan cache . . . 36
5.2 Frågeställning 2 . . . 37
5.3 Frågeställning 3 . . . 38
6 Diskussion och slutsatser 39 6.1 Diskussion kring analys av kodbas . . . 39
6.2 Resultat . . . 39
6.3 Implikationer . . . 40
6.4 Begränsningar . . . 40
6.5 Slutsatser och rekommendationer . . . 41
6.6 Vidare forskning . . . 41
Bilagor 46
Bilaga A Github repository 46
1
Introduktion
1.1
Bakgrund
En HTTP-klient är mjukvara som använder filöverföringsprotokollet HTTP för att an-sluta till- och kommunicera med webbservrar, en anslutning som görs i mån om att konsumera data. Olika bibliotek har tagits fram för att hantera HTTP-anrop på ett en-kelt sätt för utvecklare som arbetar med tjänsten. För även om det finns ursprungliga standardbibliotek för att hantera HTTP-kommunikation är dessa oftast svåra att konfi-gurera och kräver mycket tid och resurser av utvecklaren för att kunna brukas [1]. Att konfigurera och anpassa ursprungsklasser medför förhöjd komplexitet och försvårar för utvecklare i allmänhet. Därför har det skapats mängder med tredjepartsbibliotek som hanterar data via HTTP. Nyutvecklade bibliotek har stort fokus på asynkron funktio-nalitet, användarvänlighet och stöd för anpassning för utvecklaren. I allmänhet är det sällsynt att programmerare skriver egna HTTP-bibliotek från grunden, då utvecklare sällan vill återuppfinna hjulet.
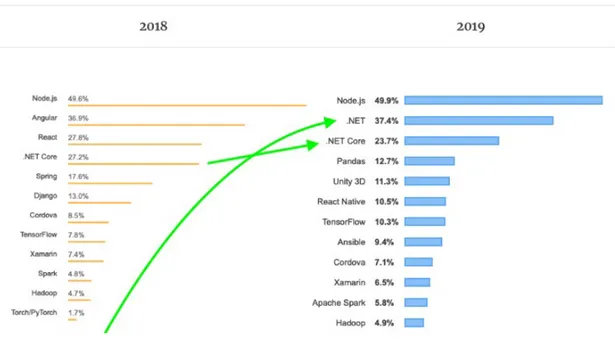
Vissa programmeringsspråk används oftare än andra för att skapa webbapplikationer och webbtjänster. Dessa språk har ofta ett stort urval HTTP-klienter att välja mellan, utvecklade med olika prioriteringar och funktionalitet i åtanke. .NET som är utvecklat
av Microsoft [2] tillsammans med C# stiger i popularitet bland utvecklare [3], se figur 1.
Vid valet av HTTP-klient måste utvecklare ta ställning till om den tekniska prestandan är av prioritet. Den här forskningen kommer att bidra med att kunna göra valet med avseende på vilken klient som bistår med överlägsen teknisk prestanda. Valet beror till stor del av projektet och dess skala, samt målgruppen. Det finns inga rätt och fel vid valet av klient, men man kan välja ett bristfälligt bibliotek baserat på vilka specifikationer man har. Det är alltid fördelaktigt att välja rätt verktyg för rätt arbete. Då .NET blir populärare med tiden och i takt med att internet växer och expanderar, leder det till att fler utvecklare kommer stå inför valet av bibliotek för HTTP-klienter. Resultatet av denna studie fyller förhoppningsvis den kunskapsluckan.
Problemet som uppstod när Microsoft lanserade .NET version 4.5 under 2012 var att äldre maskiner inte kunde använda deras förfinade dataklass HttpClient. Bland utveckla-re fanns det dem som löste problemet genom att utveckla RestSharp, som kan appliceras på vilken .NET version som helst. Flurl dök upp som konkurrent under 2018. Författar-na lyfter därför problemfrågorFörfattar-na där man vill undersöka om det finns tillämpningar där man bör använda RestSharp istället för Flurl och vice versa.
1.2
Problembeskrivning
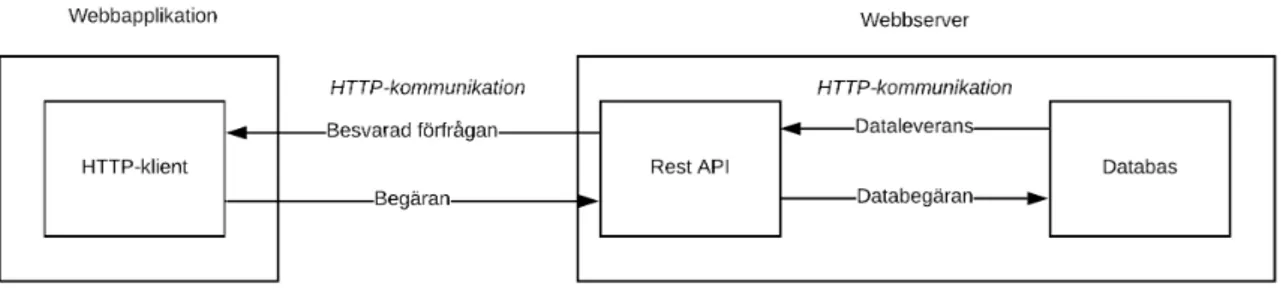
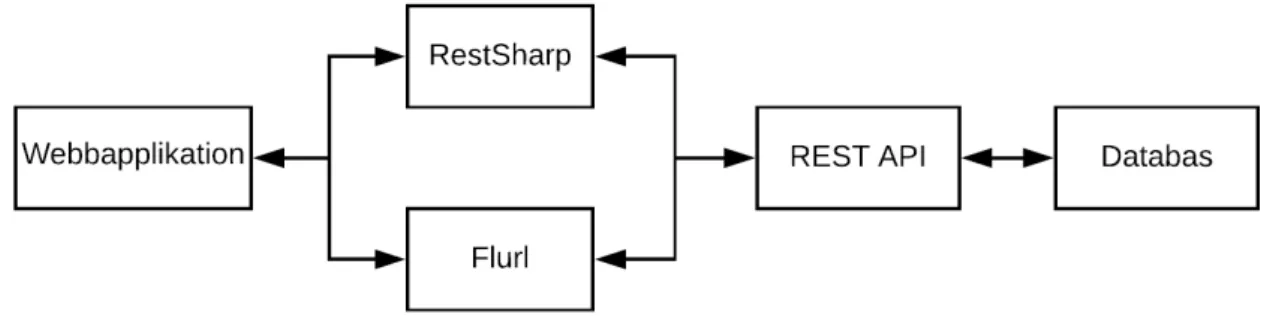
I ett klassiskt flödesschema när en webbläsarklient begär att få hämta data från en ser-ver sker anrop enligt figur 2. Tidigare forskning fokuserar på prestandan i koppling till dataöverföring mellan databas och REST API [4] [5]. Dock fokuseras det väldigt lite på prestandan mellan webbapplikation och REST API i forskningsvärlden.
I tidigare forskning har det gjorts väldigt få experiment på HTTP-klienters bibliotek med faktorer som: antal anrop som sker med avseende på datamängd som efterfrågas. Vi undersöker den prestandamässiga skillnaden mellan HTTP-klienternas kommunikation med webbservern.
Nätverksprogrammering och teknologin för att skicka digitala signaler mellan datorer på internet är komplext [6]. Utvecklare som använder sig av programmeringsspråket C# har sedan länge använt avancerade klasser för att låta datorer kommunicera med varandra över internet [7]. Då det generellt är ett misstycke kring att återupprepa kod, och skriva ny kod för saker som redan är implementerade, började programmerare ut-veckla bibliotek för HTTP-klienter. Detta för att reducera mängden arbetstimmar som läggs på projekt, men även för att underlätta vid utvecklandet av mjukvara. Detta är en av anledningar till att både RestSharp och Flurl implementerades.
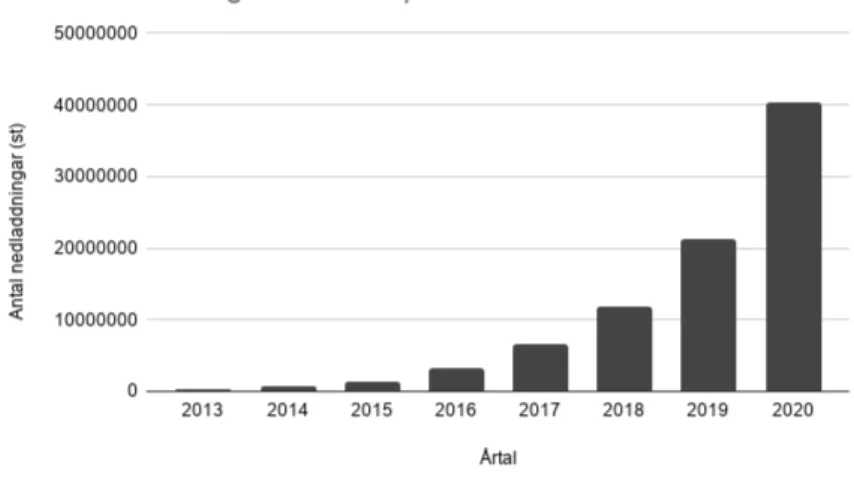
RestSharp och Flurl blir alltmer populärt och dess nedladdningar ökar för varje år [8] [9] vilket visas i figur 3 och i figur 18 i bilaga B. Problemet ligger i att utvecklare enbart väljer klient utifrån ej vetenskapliga rekommendationer. Påståendet baseras på att det ej finns tidigare forskning som jämför HTTP-klienter. Den här studien bryter dessa mönster genom att bidra med forskningsbaserad data och statistik.
Figur 3.Graf över antal nedladdningar för RestSharp
För både RestSharp och Flurl har det gjorts väldigt lite dokumentation på hur bibliote-kens kod påverkar deras prestanda, baserat utifrån dessa tre faktorer:
• Antalet anrop (hur många gånger samma klient begär att få hämta data parallellt och asynkront från webbservern)
• Fördröjningstid (hur lång tid det tar att processa ett anrop på data, från början till slut)
1.3
Syfte och frågeställningar
Syftet är att evaluera två klienter för att konsumera data via HTTP i mån av prestanda och svara på nedanstående frågor. Det här kommer bidra med en insikt för Consid, men även andra IT-företag, mjukvaruutvecklare samt projektledare när det kommer till valet av metoder för att hämta data. För ett konsultbolag som Consid sparar de även konsulttimmar om utvecklarna använder befintliga HTTP-klienter istället för att bygga egna från grunden, vilket stärker relevansen av denna studie. Då det inte redan existerar forskning som nämner vare sig Flurl eller RestSharp tidigare, är målet att minska denna kunskapslucka och bidra med relevanta insikter om prestandan för de två biblioteken. Då Consid ofta arbetar med projekt inom .NET kommer de att kunna nyttja denna studie när valet faller på dem att välja en HTTP-klient för applikationen de ska utveckla.
1.3.1 Frågeställningar
1. Är det någon skillnad mellan RestSharp och Flurl i fördröjningstid när det gäller att hämta data via HTTP med avseende på olika stora datamängder och antal anrop som sker parallellt?
2. Oavsett om det är en substantiell skillnad eller ej i fördrjöningstiden, vill vi ta reda på varför, genom att utföra en litteraturstudie på de två olika HTTP-klienterna RestSharp och Flurl.
3. Finns det tillämpningar där man skulle kunna rekommendera RestSharp framför Flurl, och vice versa?
1.4
Omfång och avgränsningar
Studien omfattar hämtning av data via HTTP med hjälp av två olika HTTP-klienter, RestSharp & Flurl, och deras prestanda med avsikt på fördröjningstid. Resultaten ger
läsaren information som kan användas till att underlätta valet att välja den ena HTTP-klienten framför den andra, om prestandan är den enda faktorn som spelar roll. Till följd av detta kan studien alltså inte klargöra för läsaren vilken HTTP-klient som passar bäst just för dem. Studien kan alltså bara rekommendera från ett prestandaperspektiv vilken HTTP-klient som föredras. Detta med tanke på andra faktorer som exempelvis vilken .NET version de använder, hur erfaren utvecklaren är och hur företaget ser på att använda tredjeparts-bibliotek med mera.
Studien kommer inte att omfatta alla olika teknologier och språk som finns på markna-den för .NET utan endast de som beskrivs i kapitel 3 Metod och genomförande, eftersom tidsramen för studien inte är tillräcklig.
Studiens resultat kommer heller inte att kunna generaliseras till vilken .NET miljö som helst då hårdvaran för databasen samt REST API:en och webb-applikationen befinner sig just på den datorn som beskrivs i kapitel 3 Metod och genomförande.
1.5
Disposition
Kapitel 2 Teoretisk bakgrund, beskriver de teorier författarna använder i studien. Kapitel 3 Metod och genomförande beskriver tillvägagångsättet författarna följt för att besvara frågeställningarna och hur arbetsprocessen sett ut.
Kapitel 4 Empiri, ger en översiktlig överblick och beskrivning över empirin som extra-herats ur studien.
Kapitel 5 Analys, ger svar på studiens frågeställningar och hypoteser genom att behand-la insambehand-lad empiri och teoretiskt ramverk.
Kapitel 6 Diskussion och slutsatser, ger en sammanfattande beskrivning av studiens resultat. Vidare beskrivs studiens implikationer och begränsningar. Dessutom beskrivs studiens slutsatser och rekommendationer. Kapitlet avslutas sedan med förslag på vidare forskning.
1.6
Begreppsdefinition
API - Ett API, eller ett applikationsprogrammeringsgränssnitt, är ett protokoll för hur olika applikationer kan kommunicera med en specifik programvara.
HTTP - Är en akronym för Hypertext Transfer Protocol, och har som huvudsaklig upp-gift att strukturera förfrågningarna och gensvaren till- och från till exempel en webbser-ver [10].
Klient - Är inom datalogi en mjukvara som är avsedd att kommunicera med ett server-program
Klass (programmering) - Klasser finns inom objektorienterad programmering. Det är ett avsnitt programkod som kan bära på attribut och funktioner.
.NET - Ett plattformsoberoende ramverk med öppen källkod utvecklat av Microsoft. Ramverket används för bland annat att bygga spel, applikationer, appar för webb, mobil med mera. .NET stödjer flera sorter programmeringsspråk och arkitekturer.
REST - REpresentational State Transfer är en arkitektonisk stil för att designa kommu-nikationssystem mellan datorer. Huvudkonceptet är att ha tillståndslös kommunikation mellan systemen [11].
SQL - Structured Query Language är ett standardiserat språk avsett för att hämta och modifiera data i relationsdatabaser.
2
Teoretisk bakgrund
Detta kapitel presenterar en mer utvidgad bakgrund och beskriver i korthet om de teo-rier och teknologier som har använts i studien.
2.1
Tidigare forskning
Tidigare forskning fokuserar på prestandan i koppling till dataöverföring mellan databas och REST API [4] [5]. Ytterligare forskning har gjorts mellan klient och server för att jämföra RESTful Web services och Advanced Message Queuing Protocol (AMQP) protokollets prestanda gällande att skicka data i form av HTTP paket sinsemellan [12]. Återigen med fokus på servern.
Vi fyller hålet i kommunikationsflödet genom att fokusera på prestandan mellan web-bapplikation och REST API, alltså mindre fokus på servern. Detta för att få en mer omfattande bild av hela flödet från klient till server.
Då världen blir allt mer digitaliserad krävs det konstant nytänkande samt omprövning av aktuella metoder inom mjukvaruutveckling. Då internet expanderar till fler enheter (världen uppskattas komma ha 50 miljarder uppkopplade enheter under 2020, vilket är en ökning) tillkommer även mer kommunikation mellan klienter och webbservrar värl-den runt [13]. Att optimera processen av kommunikation mellan klienter och servrar är minst sagt relevant, allt för att spara på tid och bandbredd. Som även tidigare forskning fokuserar på.
2.2
Vad en HTTP-klient är
Först och främst är en HTTP-klient inte en webbläsare. Syftet med en HTTP-klient är att skicka och hämta data via HTTP, det vill säga starta ett kommunikationsflöde mellan två datorer. Ett bibliotek för en HTTP-klient används främst av utvecklare för att underlätta vid utvecklingen av mjukvara, som krävs för att kommunicera. Den har ingen hantering av cachning och modifierar inte heller förfrågningar via URIs [14].
2.3
Ursprungsklasser för RestSharp och Flurl
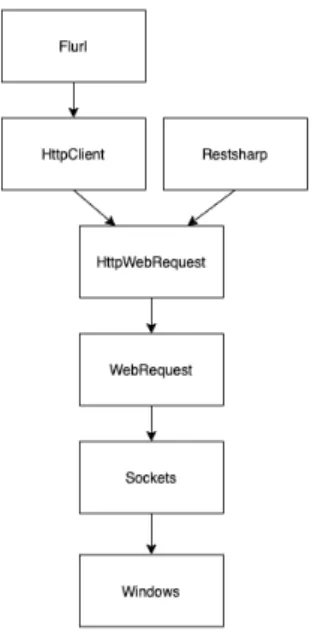
Flurl och RestSharp ärver funktionalitet från Windows .NET-klasser som visas i fi-gur 4. HttpClient ingår numera i basklass-biblioteket av .NET-ramverket [15]. Det är en basklass för att skicka förfrågningar och erhålla gensvar över HTTP, till- och från en resurs. Resursen identifieras av en Uniform Resource Identifier (URI). HttpClient är byggd i ett högnivåspråk ovanpå HttpWebRequest-klassen, som i sin tur hanterar HTTP-anslutningar med hjälp av den abstrakta klassen WebRequest [16] [17]. HttpCli-ent innehåller extra funktionalitet som till exempel en annan sorts hantering av trådar, där också tekniken awaits har tillkommit [18]. Vidare använts sockets som är byggda i ett lågnivåspråk för att processera information, som sedan skickas ut över ett nätverk.
Figur 4.Flödesschema som visar klasser som Flurl och RestSharp ärver ifrån.
2.4
RestSharp
RestSharp är det mest populära HTTP-klientsbiblioteket ute för .NET. Med automa-tisk serialisering och deserialisering, automaautoma-tisk detektering av format på förfrågan, och med stor arsenal för autentisering, används RestSharp i hundratusentals projekt.
RestSharp passerade över 40 miljoner nedladdningar på NuGet [19], vilket är pakethan-teraren för .NET, med ett genomsnitt på 12,000 nedladdningar per dag.
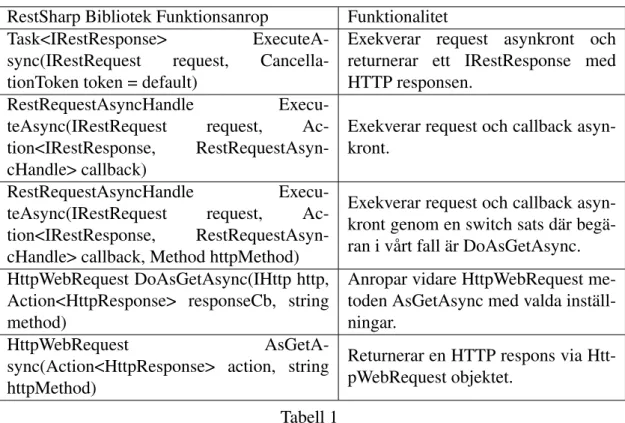
2.4.1 RestSharps kodbas
Tabell 1 visar flödet i tur och ordning vilken funktion som anropas när webbapplikatio-nen anropar RSFetchAsync(). Vilket är den funktion som får HTTP-klienten att begära data från REST API:et. Se kapitel 3.3.3 Implementation för experimentets implementa-tion. Funktionen i experimentet som exekveras när webbapplikationen hämtar data från databasen är följande kodrad:
v a r r e s p o n s e = a w a i t c l i e n t . E x e c u t e A s y n c ( g e t R e q u e s t )
RestSharp Bibliotek Funktionsanrop Funktionalitet Task<IRestResponse>
ExecuteA-sync(IRestRequest request, Cancella-tionToken token = default)
Exekverar request asynkront och returnerar ett IRestResponse med HTTP responsen.
RestRequestAsyncHandle
Execu-teAsync(IRestRequest request,
Ac-tion<IRestResponse, RestRequestAsyn-cHandle> callback)
Exekverar request och callback asyn-kront.
RestRequestAsyncHandle
Execu-teAsync(IRestRequest request,
Ac-tion<IRestResponse, RestRequestAsyn-cHandle> callback, Method httpMethod)
Exekverar request och callback asyn-kront genom en switch sats där begä-ran i vårt fall är DoAsGetAsync. HttpWebRequest DoAsGetAsync(IHttp http,
Action<HttpResponse> responseCb, string method)
Anropar vidare HttpWebRequest me-toden AsGetAsync med valda inställ-ningar.
HttpWebRequest
AsGetA-sync(Action<HttpResponse> action, string httpMethod)
Returnerar en HTTP respons via Htt-pWebRequest objektet.
Tabell 1
RestSharps kedjereaktion av funktioner som anropas i ordning - det första momentet längst upp
2.5
Flurl
Flurl är en av de senaste HTTP-klienten som fått uppmärksamhet i .NET-världen. Det finns säkerligen ett flertal nyutvecklade klienter ute på marknaden, men Flurl är den senaste som tagit höjd i antalet nedladdningar på NuGet. Flurl har över 8 miljoner ned-laddningar på NuGet, tillsammans med cirka 3,500 nedned-laddningar per dag. Flurl utveck-lades för att förhöja utvecklarens upplevelse när hen arbetar med HttpClient, vilket visar
sig i användarvänligheten av biblioteket.
2.5.1 Flurls kodbas
Tabell 2 visar flödet i tur och ordning vilken funktion som anropas och vad dem in-nebär när webbapplikationen exekverar FLFetchAsync(), vilket är motsvarigheten till RestSharps RSFetchAsync(). Funktionen i experimentet som exekveras när webbappli-kationen hämtar data från databasen är koden i kodavsnitt 4.
Kodavsnitt 4. Kod för klassen Result från applikationsprogrammeringsgränssnittet v a r r e s p o n s e = a w a i t c l i e n t . R e q u e s t ( )
. A p p e n d P a t h S e g m e n t ( " e m p l o y e e s / " ) . A p p e n d P a t h S e g m e n t ( a m o u n t O f D a t a ) . G e t S t r i n g A s y n c ( ) ;
Flurl Bibliotek Funktionsanrop Funktionalitet IFlurlRequest Request(params object[]
url-Segments)
Skapar ett IFlurlRequest som sedan ytterligare kan bli byggd ovanpå.
bool IsValid(string url) Returnerar sant om string url är en
välformaterad URL.
FlurlRequest(Url url = null) Tilldelar inkommande url till klassens egna attribut _url.
string Combine(params string[] parts) Försäkrar att bara en ’/’ separerar var-je segment.
string EncodeIllegalCharacters(string s, bool encodeSpaceAsPlus = false)
Returnerar en välformaterad URL-sträng.
Url AppendPathSegment(object segment, bool fullyEncode = false)
Returnerar Url objektet med objektet segment påbyggd.
string ToInvariantString(this object obj) Returnerar en sträng som represente-rar nuvarande objekt.
IEnumerable<string> ParsePathSeg-ments(string path)
Delar strängen path till olika segment och eliminerar bort tecken som ’?’ och ’#’.
Task<string> GetStringAsync(this string url, CancellationToken cT = default, HttpCom-pletionOption c = _c)
Skapar ett FlurlRequest och skickar ett asynkront GET anrop.
Task<string> GetStringAsync(this IFlurlRe-quest r, CancellationToken cT = default(cT), HttpCompletionOption cO = HttpCompletio-nOption.R)
Returnerar en Task vars resultat är kroppen ifrån en HTTP respons som en sträng genom HTTPClient objek-tet.
Tabell 2
Flurls kedjereaktion av funktioner som anropas i ordning - först längst upp
2.6
REST API
REST står för REpresentational State Transfer, definierat av mjukvaruarkitekten Roy Fi-elding, och är ett sätt att strukturera gränssnitt för att underlätta datahämtning via HTTP [20]. API står för Application Programming Interface, eller applikationsprogramme-ringsgränssnitt och är en generell benämning på gränssnitt som är främst framtaget för annan mjukvara att interagera mot, snarare än ett gränssnitt som är ämnat för människor.
Gränssnittet som är framtaget för den här undersökningen är väldigt simpel och är ut-vecklat med enbart READ-funktionaliteten av C.R.U.D., Create, Read, Update, Delete, som är vanligt förekommande i utvecklingen av REST API [21].
2.7
Databas
En databas är till grund en samling av lagrad data som vanligtvis är åtkomligt från ett datorsystem. En databas används till att lagra, sortera, hämta och manipulera data. In-formationen i databasen är bestående. Datan försvinner alltså inte ifall maskinen stängs ner. Oftast organiseras datan i tabeller innehållandes rader och kolonner.
2.8
Caching
Cachning är en term inom datateknik som innebär att system eller processer kan ta av-bilder, kopior, av data och mellanlagra detta i ett snabbt minne för att återanvända datan i framtiden. Det används frekvent vid hämtning av data från internet, för att undvika upprepad hämtning av samma data flera gånger. Exempelvis så kan en webbläsare spara ner det senaste HTTP-svaret i en lokal cache. Om samma resurs senare blir anropad igen kommer webbläsaren kontrollera om samma resurs finns i cachen och är aktuell innan det görs en helt ny förfrågan till servern.
2.9
Kompression
Datakomprimering innebär att data omkodas på ett sätt så att färre informationsbärande enheter behöver användas. Det är väldigt populärt att skicka komprimerad data över internet för att snabba upp hämtningar och utsändning av data.
3
Metod och genomförande
Kapitlet ger en översiktlig beskrivning av studiens arbetsprocess. Vidare beskrivs studi-ens ansats och design. Därtill beskrivs studistudi-ens datainsamling och dataanalys. Kapitlet avslutas med en diskussion kring studiens trovärdighet.
3.1
Koppling mellan frågeställningar och metod
Studien kräver en kvantitativ, experimentell ansats för att kunna utvärdera och jämföra fördröjningstiden för två HTTP-klienter. Experimentet efterföljs av en kvalitativ littera-turstudie där skillnaden mellan klienterna undersöks. Litteralittera-turstudien kommer att ut-föras med stöd av tidigare forskning på HTTP-klienter samt officiella dokumentationer tillhörande Flurl respektive RestSharp.
I undersökningen behandlas tre frågeställningar som behandlar och jämför två HTTP-klienters användbarhet och prestanda. För att besvara forskningsfrågorna, samt ge en forskningsbaserad rekommendation vid valet av HTTP-klient, krävs en kvantitativ, ex-perimentell ansats. Detta i syfte att utvärdera och jämföra fördröjningstiden för dem två HTTP-klienterna, som gjordes genom att utveckla en mjukvarulösning innehållandes klientprogram, ett REST API och en databas.
För utförandet av experimentet utvecklades webbapplikationen i ASP.NET Core som en konsolapplikation i en minimalistisk design. ASP.NET Core är Microsofts omdesig-nade och förbättrade version av ASP.NET, enligt Microsoft [22]. Se implementationen under kapitlet 3.3.3 Implementation. Under webapplikationens körtid kunde användaren ställa in hur många anrop som skulle köras samtidigt, asynkront och hur många poster som skulle hämtas från databasen samt vilken av klienterna som skulle användas vid hämtning. Med hjälp av dessa tre alternativ kunde experimentens resultat presenteras tydligt.
• För att besvara studiens första frågeställning har webbapplikationen utformats på ett sådant sätt att det går testa klienternas förmåga under dessa omständigheter. • För att besvara studiens andra frågeställning görs en djupgående litteraturstudie
• För att besvara studiens tredje frågeställning utförs en analys av experimentens resultat bland annat med hjälp av T-test.
3.2
Hypotes
Hypotesen H0ligger till underlag för studien och lyder enligt följande:
Vårt antagande är att RestSharp och Flurl kommer ge jämlika resultat i fördröjningstid under experimentet
Författarna har denna hypoteseftersom RestSharp använder sig av klassen HttpWebRe-quest för att konsumera HTTP förfrågningar [23] [16]. Flurl använder klassen HttpCli-ent som i sin tur ärver funktionalitet från HttpWebRequest [24]. I och med att båda biblioteken ursprungligen har funktionalitet från samma basklass är antagandet att de-ras prestanda är detsamma. Detta är vår hypotes för den första frågeställningen.
3.3
Arbetsprocessen
I studiens tidiga stadie inleddes en litteraturöversikt av tidigare forskning inom HTTP, C# och .NET i övergripande mån. Med hjälp av handledare, tidigare forskning och upp-dragsgivaren Consid kunde författarna formulera forskningsfrågor, hypotes och fråge-ställningar. Den ena klienten är den mest nedladdade HTTP-klienten på marknaden, och den andra klienten är den senaste aktuella klienten avsett på antalet nedladdningar per dag [25] [26]. Det valdes att genomföra en jämförande studie där ett antal experiment utfördes för att kunna besvara frågeställningarna.
3.3.1 Utvecklingsmiljöer
Konsolapplikationen har utvecklats i ramverket ASP.NET Core 3.1.101, som är an-passat för utveckling till flera plattformar, endast innehållandes grundpaket och de två HTTP-klienternas bibliotek. Det REST API som används är utvecklat i webbramverket ASP.NET v 4.8. Databasen använder sig av databashanteraren MySQL och är konstru-erad i MySQL Workbench v 8.0.18. REST API samt databasen är utvecklade på en PC
med Windows 10 i programutvecklingsmiljön Microsoft Visual Studio 2019. Webbap-plikationen utvecklades på en Mac OS Mojave 10.14.5 med open-source programmet Visual studio code v 1.36.1 som textredigerare.
3.3.2 Enhet
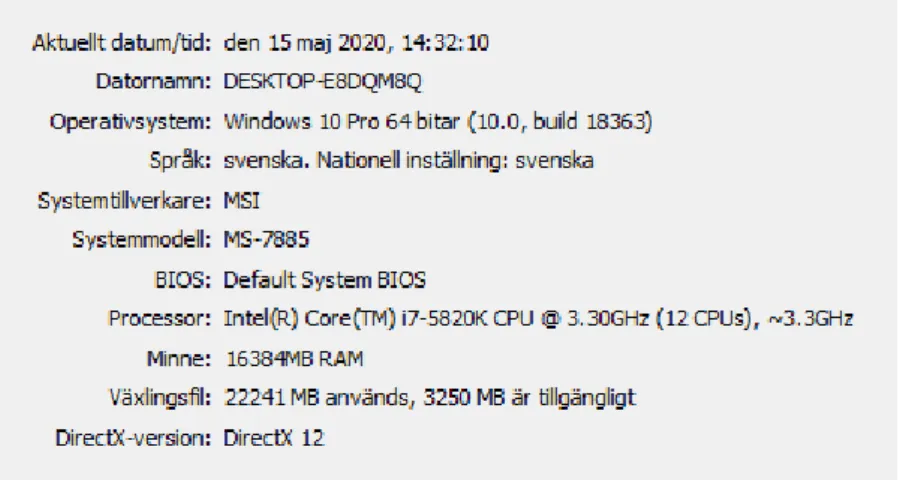
Experimentet har utförts på en PC med operativsystemet Windows 10 installerat. Se figur 5 för detaljerad information om systemet.
Figur 5.Specifikationer för Windows-enheten som experimentet utförts på
3.3.3 Implementation
Följande tre delkapitel beskriver hur författarna implementerade de tre huvudkompo-nenterna som experimentet använder sig av. Dessa är en webbapplikation, ett REST API och en databas.
För att bedriva experimentet kommer en servermiljö sättas upp på en maskin som kör Windows 10, där både ett REST API och en databas körs. Även klienten kommer köras från samma maskin som servern ligger på. Databasen består av en tabell innehållandes sex stycken kolonner, populerad med slumpade data för att undvika eventuell datakom-pression. Webbapplikationen kommer ha funktionalitet för att göra HTTP-anrop via dem två olika biblioteken, RestSharp & Flurl, med stöd för funktionalitet så att man kan skicka flera anrop parallellt via asynkrona metoder. I webbapplikationen kan man även spåra tiden det tar för varje HTTP-anrop att färdas mellan webbapplikationen och webbservern.
Databasen och API:en ligger på ett lokalt nätverk som klienten har tillgång till off-line, detta gör att vi kan eliminera externa faktorer och på så sätt gå in på djupet på prestandan på klienten i sig. Att kunna bortse från faktorer såsom internethastighet, täckning och andra störningar främjar forskningens tillförlitlighet.
Figur 6.Ansatsen för experimentet
I ansatsen enligt figur 6 skapas ett REST API tillsammans med en databas, och experi-menten utförs på dessa. Mjukvaran för ansatsen utvecklas, lagras och körs på ett lokalt nätverk för att exkludera externa faktorer i experimentet. Experimentet utförs med föl-jande parametrar:
• Tre mängder data enligt [0.1 MB, 1 MB, 2.5 MB]
• Tre antal med parallella anrop enligt [1 st, 50 st, 199 st], som kommer anropas via asynkrona funktioner
Mängderna med data var begränsade då datorn som användes som server hade begränsad tillgång till hårdvaruresurser. Likaså antalet parallella anrop, där en maxgräns på 200 samtidiga anslutningar kunde göras. Dessa tre datamängder, samt mängden parallella anrop, räckte för att kunna utvinna konkreta resultat ur empirin.
Varje mängd data anropas därefter i kombinationer för varje set med asynkrona anrop, se figur 7. Detta kommer att ge en övergripande bild och utförliga tidsvärden till den slutgiltiga statistiken, som kommer sammanfattas i form av grafer och tabeller. Experi-mentet innehåller tre variabler, α (oberoende), β (oberoende) och γ (beroende). Under experimentet tog författarna den oberoende variabeln α och körde i alla möjliga uppsätt-ningar av β , för att få ut ett resultat γ. Detta utövades 90 ∗ 2 gånger per HTTP-klient för
att täcka både scenario med datahämtning från cache och inte cache, förklarat närmre i kapitel 3.5 Datainsamling.
Figur 7.Flödesschemat för experimentet
Webbapplikation
RestSharp och Flurl är inte uppbyggda på exakt samma sätt. Författarna implemente-rar båda biblioteken så likt varandra som möjligt för att ge dem lika förutsättningar. För att experimenten mellan Flurl och RestSharp skall vara rättvisa startar författarna ett tidtagarur när begäran av data sker, med hjälp av funktionen RSFetchAsync som illustreras i kodavsnitt 1. All uppbyggnad och initiering av bibliotekens objekt sker ut-anför tidtagarurens ramar, för att ej påverka körtidens resultat. Strängen typeO f Client är vilken HTTP-klient webbapplikationen skall exekvera inom. AmountO f DataPerCall strängen bestämmer hur mycket data som skall förfrågas från webbtjänsten. Vidare be-tyder heltalet amountO f Calls hur många anrop som skall göras näst-intill samtidigt till webbservern. Eftersom hårdvaran som webbapplikationen besitter inte kan starta 199
trådar samtidigt, hanteras detta bakom skynket via .NET’s Thread Pool-hanterare. Som i sin tur hanterar ett viss spann med förfrågningar samtidigt, i ett kö-liknande system, och därmed inte alla på samma gång [27].
I kodavsnitt 1 visas koden från webbapplikationen som används för HTTP-klienten RestSharp. Motsvarande kod för HTTP-klienten Flurl finns i länken i bilaga A.
Kodavsnitt 1. Kodsnutt för att begära data via HTTP-klienten RestSharp
s t r i n g t y p e O f C l i e n t ;
s t r i n g a m o u n t O f D a t a P e r C a l l ; i n t a m o u n t O f C a l l s ;
L i s t < Task > a l l D o w n l o a d s = new L i s t < Task > { } ;
L i s t < R e s t R e q u e s t > r e s t R e q u e s t s L i s t = new L i s t < R e s t R e q u e s t > { } ; v a r r e s t C l i e n t = new R e s t C l i e n t ( " h t t p s : / / l o c a l h o s t : 4 4 3 7 1 / " ) ; S t o p w a t c h s t o p w a t c h = new S t o p w a t c h ( ) ; i f ( t y p e O f C l i e n t == " R e s t s h a r p " ) { f o r ( i n t i = 0 ; i < a m o u n t O f C a l l s ; i ++) { v a r g e t R e q u e s t = new R e s t R e q u e s t ( $ " e m p l o y e e s / { a m o u n t O f D a t a P e r C a l l } " ) ; r e s t R e q u e s t s L i s t . Add ( g e t R e q u e s t ) ; } T h r e a d . S l e e p ( 2 0 0 0 ) ; s t o p w a t c h . S t a r t ( ) ; f o r e a c h ( v a r r e q u e s t i n r e s t R e q u e s t s L i s t ) { a l l D o w n l o a d s . Add ( R S F e t c h A s y n c ( r e s t C l i e n t , r e q u e s t ) ) ; } a w a i t T a s k . WhenAll ( a l l D o w n l o a d s ) ; s t o p w a t c h . S t o p ( ) ; } p r i v a t e a s y n c s t a t i c T a s k R S F e t c h A s y n c ( R e s t C l i e n t c l i e n t , R e s t R e q u e s t g e t R e q u e s t )
{
v a r r e s p o n s e = a w a i t c l i e n t . E x e c u t e A s y n c ( g e t R e q u e s t ) ; }
Enligt Microsofts dokumentation för klassen HttpClient bör man nyttja klassen i mån om att skapa dataströmmar snarare än att göra datahämtningar, om datan överstiger 50 MB i storlek [15]. Därav lades fokus på mindre mängder med data, just för att ej störa klassens uppbyggnad. Valet föll på att implementera en HTTP-klient som lever kvar så länge som möjligt i processen. En instans av HttpClient skall leva kvar så länge som möjligt under körningstiden, vilket togs till hänsyn under utvecklingen [28].
REST API
Det REST API (gränssnittet) som användes till forskningen utvecklades i mån om att hålla experimentet på ett realistiskt plan. Möjligheten att ha all data lokalt som till ex-empel i en textfil fanns, men med ett REST API och en databas lyckades författarna simulera en realistisk miljö. Formatet på data som returneras illustreras i figur 8.
Figur 8.Exempel på data som returneras från REST API
Gränssnittet implementerades med enbart de mest essentiella funktionaliteterna och konfigurationsfilerna. Eftersom processeringstiden för gränssnittet och databasen inte räknades med under experimentet, kunde implementationen och designen för dessa vara helt upp till författarnas preferenser. I gränssnittet tog en övergripande gränssnittskon-troller emot anrop för den enda Uniform Resource Identifier (URI) som fanns i gräns-snittet, "/employees". Kontrollern, som var i en klass i sig, innehöll även klassen Result, se kodavsnitt 2, som utformades som en modell för att kunna lagra och hantera datan som hämtades från databasen.
Kodavsnitt 2. Kod för klassen Result, från applikationsprogrammeringsgränssnittet p u b l i c c l a s s R e s u l t { p u b l i c s t r i n g name { g e t ; s e t ; } p u b l i c s t r i n g d e p a r t m e n t { g e t ; s e t ; } p u b l i c s t r i n g a d d r e s s { g e t ; s e t ; } p u b l i c s t r i n g number { g e t ; s e t ; } p u b l i c s t r i n g t i t l e { g e t ; s e t ; } p u b l i c s t r i n g s u r n a m e { g e t ; s e t ; } p u b l i c s t r i n g e m p l o y e e N r { g e t ; s e t ; } p u b l i c s t r i n g c o u n t r y { g e t ; s e t ; } p u b l i c R e s u l t ( s t r i n g name , s t r i n g sur name , s t r i n g d e p a r t m e n t , s t r i n g a d d r e s s , s t r i n g number , s t r i n g t i t l e , s t r i n g employeeNr , s t r i n g c o u n t r y ) { t h i s . name = name ; t h i s . d e p a r t m e n t = d e p a r t m e n t ; t h i s . a d d r e s s = a d d r e s s ; t h i s . number = number ; t h i s . s u r n a m e = s u r n a m e ; t h i s . t i t l e = t i t l e ; t h i s . e m p l o y e e N r = e m p l o y e e N r ; t h i s . c o u n t r y = c o u n t r y ; } }
Gränssnittskontrollern var aktiv på datorns egen loopback-enhet, localhost, där den lyss-nade på anrop som gick till porten 44371. Kontrollern gavs enbart möjligheten att ta emot GET-förfrågningar, där användaren fick specificera antalet uppslag från databasen som skulle hämtas. Detta specificierades genom URI:n, se kodavsnitt 3.
Kodavsnitt 3. Exempel på URI för GET-förfrågning " / e m p l o y e e s / 3 0 0 "
Databas
Databasen implementerades med målet att simulera ett verkligt scenario. Författarna valde att låta databasen ha resursen "Employees", vilket var en tabell bestående av åtta stycken kolonner plus ett id. Dessa åtta kolonner fylldes med slumpade data av tio tec-ken, a-z, 0-9. Valet att slumpa datan gjordes i mån om att utesluta kompression som en bidragande faktor till fördröjningstiden. Vid utvecklingen av databasen utökade förfat-tarna successivt från fem kolonner till åtta för att uppnå önskad mängd data i databasen. Likaså expanderade cellerna från sex karaktärer värt av data till tio karaktärer.
Databasen skapades via MySQL:s egna installationsguide, och anpassades för att köras som en dedikerad serverdator. Det innebär att databasen fick större tillgång till datorns egna resurser än om man skulle gjort en annan konfigurering. MySQL använder sig av motorn InnoDB, och kördes med MySQL version 8.0.19.
Databasen arbetade med trådar [29], där databasen tilläts använda 15 trådar samtidigt. Varje tråd hade en databuffert på 256KB var, vilket tillsammans med stor mängd RAM-minne underlättar vid experimentets asynkrona anrop. Totalt kunde upp till 1024 använ-dare ansluta till databasen samtidigt och begära data, vilket är en mängd som experi-mentet inte uppnådde.
3.4
Design
Experimentet inleds med en litteraturstudie på tidigare relaterat arbete. Målet med litte-raturstudien var att finna vilken data som var relevant att undersöka vidare och vad som var mest optimalt för denna studie, samt hur man får fram empirin. Litteraturstudien inkluderar forskning med liknande experiment, det vill säga experiment för att evaluera prestanda med avseende på datastorlek och latens.
Därefter genomförs ett förexperiement i syfte att få fram preliminära värden, men även för att se om det var möjligt att koppla bort externa faktorer för att få fram kritiska värden att jämföra.
3.5
Datainsamling
Datainsamlingen började med en insamling av teoretisk data genom litteraturstudier på tillhörande områden och fortskred sedan med insamling av empirisk data från experi-mentet. Dock gjordes ingen närmare undersökning om vart cachningen sker. Detta på grund av cachningens komplicerade natur, samt att det ej är en del av studiens omfång. Under studiens gång gick författarna vid ett antal tillfällen tillbaka till litteraturstudien för att klargöra vissa moment samt för att fylla i kunskapsluckor. Experimenten som utfördes gav kvantitativ data i form av tidsmätning, se figur 9. Mätningen av tiden ut-fördes med hjälp av inbyggda tidtagarur som visade den totala körtiden för klienterna i millisekunder.
Figur 9.Bild från webbapplikationen som användes under experimentet
3.5.1 Förexperiment
Genom förexperimentet fick författarna se hur cachning fungerar i praktiken och tog ställning till hur dessa faktorer skulle hanteras till det skarpa experimentet. Att en-bart hantera värden som kommer från datahämtning från datorns egna cache speglar ej verkligheten, och författarna tog beslutet att köra på två scenarion. Detta på grund av svårighetsgraden med att lokalisera vart cachningen sker. Det skarpa experimentet om-formades på det vis att datainsamlingen sker från både datorns lokala cache, men även från nätverket. Två stycken separata t-test utfördes för att inspektera signifikansnivån bland körtiderna för de båda scenarion. Under det riktiga experimentet gjordes två styc-ken separata datainsamlingar och analyser. Under ena insamlingen skedde en omstart av systemet mellan varje körning för att negera influens av datorns lokala cache.
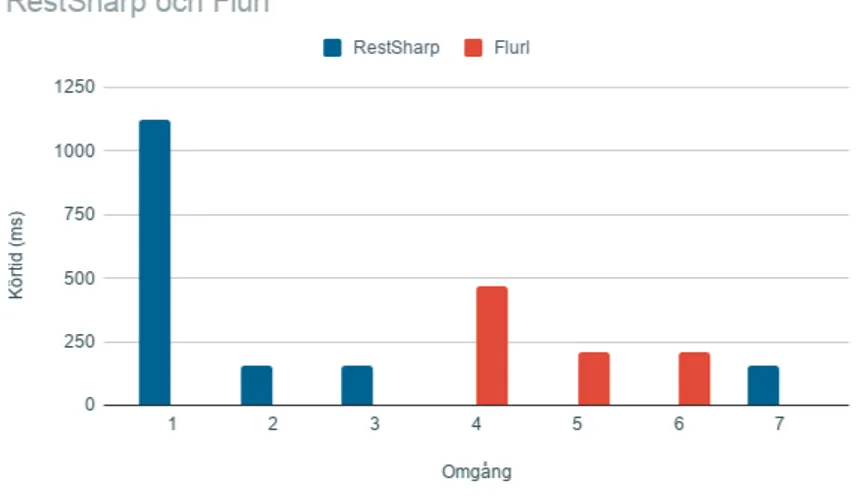
Figur 10.Graf som symboliserar effekten av cachning
Figur 10 visar de externa faktorerna som påverkar resultaten då cachning sker. Rest-Sharp kör ocacheat första omgången och därmed får en längre fördröjningstid, men datorn arbetar sedan mot sin lokala cache följande körningar.
Grafen visar även att det inte är helt cacheat även när man går från en klient till den andra under samma session. Detta kan ses i grafen mellan omgång tre och fyra. Flurl får en längre körtid i omgång fyra men inte lika lång om man jämför med omgång ett från Restsharp. Dessa mönster upprepades även i omvänd ordning av HTTP-klienterna.
3.6
Dataanalys
En signifikansanalys utförs för att stärka reliabiliteten och validiteten av experimenten. Analysen förtydligar skillnaderna mellan de två HTTP-klienternas prestanda där bland annat ett T-test ingår, som visar sannolikheten att resultaten hände av slump där ett p-värde på mindre än 5% (0.05) räknas som giltigt [30].
Då data extraherats från experimenten under två olika omständigheter, behövdes två se-parata analyser genomföras, för att sedan kopplas ihop till en gemensam slutsats. Ana-lysen använder medelvärde som centralmått och standardavvikelse som spridningsmått.
3.6.1 Standardavvikelse
Standardavvikelse är ett spridningsmått på hur mycket de olika värdena från en popula-tion avviker från medelvärdet. Ju större spridning på värdena, desto större standardav-vikelse har skett, och kan då uttryckas som att spridningen kring medelvärdet är stor. Standardavvikelsen beräknas enligt ekvation 1:
s= s 1 n n
∑
i=1 (xi− m)2 (1) då m= 1 n n∑
i=1 xi (2)n= storleken på urvalet, xi= varje värde i urvalet
3.6.2 Signifikansanalys
En signifikansanalys är en metod inom matematisk statistik som används för att se om en viss skillnad mellan två datagrupper beror enbart av slumpen. Om skillnaden är fri från slump kallar man det att skillnaden är signifikant. Signifikans är ett begrepp som används för att ange att ett värde som är framställt ur experimentet avviker från ett jämförelsevärde, såsom ett framtaget, hypotetiskt värde. Man kan då observera om av-vikelsen sannolikt inte beror på slumpen, det vill säga statistisk osäkerhet.
Då undersökningen fokuserar på två olika scenarion, där värden kommer från två olika populationer, som beskrivet under kapitel 3.5 Datainsamling, krävdes även två separata analyser. För den ena analysen formulerades följande hypoteser, båda med avseende på HTTP-klienterna:
• Nollhypotes: Det finns ingen systematisk skillnad mellan populationerna enligt ekvation 3
kr= kf (3)
• Mothypotes: Det finns en systematisk skillnad mellan populationerna enligt ekva-tion 4
k= Körtid, f = Flurl, r = RestSharp
De två scenarion var följande, enligt kapitel 3.5 Datainsamling:
• Scenario 1: Värden extraherades när applikationen hämtade data från datorns egna lokala cache och förutsätts vara normalfördelade, vilket krävs för ett optimalt t-test [31]. T-t-testet kunde då appliceras på medelvärden från populationerna, enligt ekvation 5: t=|mqr− mf| s2 r+s2f 9 (5)
m = medelvärdet för populationen enligt ekvation 2, s = standardavvikelsen för populationen enligt ekvation 1, r = RestSharp, f = Flurl
Det värdet som man får ut från t-testet kallas för ett p-värde, som är en ratio baserad på skillnaden mellan de två populationerna. P-värdet som, under förut-sättningarna att nollhypotesen är sann, används för att tala om hur sannolikt det är att observera en skillnad som är minst så stor som den observerats. Ett lågt p-värde talar för att nollhypotesen kan förkastas och den alternativa hypotesen kan då anses vara mest trolig. Vid ett p-värde på < 0.05 sägs resultatet vara signifi-kant. Det är vanligt förekommande att signifikansnivån sätts till p = 0.05, vilket skulle innebära att risken för att mothypotesen är falsk är < 5%. Om p < 0.05 anses det generellt sett vara en statistisk signifikant effekt. Men gränsen 0.05 är inte svartvit, utan skillnaden mellan p-värden på 0.06 eller 0.04 inte är stor. • Scenario 2: Värden extraherades när applikationen hämtade data från nätverket,
och förutsätts vara ej normaliserade. Ej normaliserade värden från populationer medför att ett t-test ej blir optimalt. Däremot så kunde en trend observeras med de utvunna värdena, vilket diskuteras i kapitel 5.1.2 Analys av experiment utan cache
3.7
Analys av vardera kodbaser
Detta kapitel beskriver hur författarna analyserar RestSharps och Flurls bibliotek. Bib-lioteken är öppna källor (engelska: open source) som finns på
versionhanteringsplatt-formen GitHub [32]. För att besvara varför fördröjningstiden på vardera HTTP-Klient ser ut som den gör utformas en jämförelse mellan dem. Eftersom HTTP-klienterna an-vänder samma databas, REST API och konsolapplikation i experimenten återstår bara koden i HTTP-klienterna som det kan skiljas åt i prestanda. Jämförelsen innehåller kri-terier såsom antal kodrader och vilken kodkvalité biblioteken besitter. Vid framtagandet av kriterierna tog författarna inspiration från studier där man jämfört programmerings-språk [33]. Denna studie, samt liknande studier, jämförde dock faktorer såsom använ-darvänlighet och effektiv tid för att skriva kod, vilka inte är aktuella för denna analys. Det enda kriteriet som togs efter var en granskning av antal logiska kodrader. Däref-ter evalueras deras funktioner sinsemellan. KriDäref-terierna och metoden är inspirerad från artiklar som jämför programmeringsspråk, ramverk och modeller [34] [33] [35]. Kodbasanalysen består av att undersöka nedanstående kriterier för att kunna diskutera varför fördröjningstiden ser ut som de gör:
• Antal kodrader Vad är storleken av källkoden, mätt i antal kodrader (engelska: Lines of Code, LOC) [36] av HTTP-klientens relevanta funktioner*?
• Kodkvalité Vilken kodkvalité har de enligt en analys utövat av tredjepart?
* De relevanta funktionerna är de som körs när konsolapplikationen anropar bibliotekens metoder Execu-teAsync(r) respektive GetStringAsync().
Kriterierna jämförs och slutsatser finns under kapitel 5 Analys. Utöver kriterierna jäm-förs dataflödet i vardera bibliotek. Dessa bryts ner till funktioner som evalueras med hjälp av Microsofts dokumentation om vilken som ger högre prestanda.
Antal kodrader är beräknat som antalet logiska kodrader i denna analysen. Logiska kod-rader mäter de totala antalet av källkodsuttryck (engelska: source statements) som också är de block av kod som exekveras i programmets körning [37]. Genom att räkna logis-ka kodrader elimineras kodkommentarer, format och programmeringsstilar som logis-kan ge olika antal fysiska kodrader men samma exekveringstid. Författarna beräknar de logis-ka kodrader som avslutas med ett semikolon och räknar detta för hand då de relevanta funktionerna är små nog att det är möjligt. Författarna kan jämföra bibliotekens rele-vanta funktioner med hjälp av antalet kodrader eftersom biblioteken är skrivet i samma språk och använder samma kodstandard [36].
Kodkvalitén tyder på hur optimerad koden är i jämförelse med en mängd andra pro-jekt som är av samma storlek och skrivet i samma språk. Tredjeparten Lumnify jämför
enstaka funktioner med andra projekts funktioner [38]. Exempelvis kan den jämföra funktionen getString() med 100 andra projekts getString() och utvärderar vilken funk-tion som är mest effektiv och optimerad. Under uträkningen ges ett värde mellan ett till fem, där fem innebär mest optimerad kod. Placeringen bestäms alltså i proportion med andra projekt.
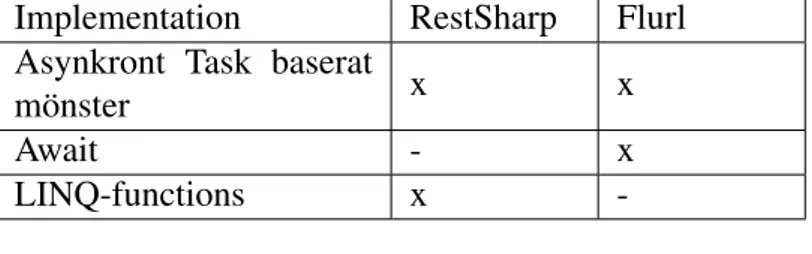
Tabell 3 visar en jämförelse med de olika tekniker vardera bibliotek använder sig av i de relevanta funktionerna. Genom en litteraturstudie fick författarna förståelse för de olika teknikerna. Nedan förklaras vad som skiljer teknikerna åt, och om prestandan kan påverkas av dessa.
Implementation RestSharp Flurl
Asynkront Task baserat
mönster x x
Await - x
LINQ-functions x
-Tabell 3
Notering ’x’ innebär att biblioteket använder sig av den tekniken.
Som tabell 3 visar är bägge bibliotekens implementation uppbyggda asynkront. Funk-tioner returnerar Tasks som representerar arbetet för en viss process som körs [18]. Detta ger fördel över synkron programmering då applikationen kan fortsätta med andra processer samtidigt. Applikationen behöver inte invänta att webbresursen skall hämtas. Webbresurser kan vara väldigt stora och hämtningen av dessa medför fördröjningstid. Await / Async är en teknik som hanterar asynkrona anrop och tillkom när .NET-ramverket 4.5 lanserades. Enligt RestSharps kodbas används inte denna teknik utan istället utnytt-jar de callbacks för att returnera Tasks. RestSharp använder nyckelordet ContinueWith() för att exekvera kod efter att en särskild Task har avslutats. Författarna ifrågasätter om detta kan ha en betydelse gällande prestanda mellan de två HTTP-klienterna. Det visar sig att det skiljer mellan de två teknikerna men inte gällande specifikt prestandan. Bara mellan hur användarvänligheten är, hur de hanterar felhantering och presentation av sta-tus på Tasks [39]. Genom Microsofts dokumentation beskrivs det också att nyckelordet Await faktiskt installerar en callback på Tasken även ifall vi som programmerare inte kan se det [18].
En ytterligare skillnad mellan bibliotekens implementation är att RestSharp använder sig av Language Integrated Query (LINQ) funktioner [40] medan Flurl utnyttjar
tradi-tionella kodningstekniker. LINQ erbjuder en syntax för att manipulera objekt, dataset och datastrukturer på ett sätt som påminner om Structured Query Language (SQL). Detta lanserades till .NET platformen 3.5. På samma sätt här ifrågasätter författarna om detta påverkar prestandan på något vis mellan RestSharp och Flurl. Enligt en veten-skaplig benchmark som experimenterade med 416 objekt som blev manipulerad av en LINQ-funktion, respektive en traditionell ekvivalent funktion visar det sig att det inte är någon skillnad i prestanda i denna kategori heller [41].
3.8
Validitet och reliabilitet
Studien avser att göra utvärderingsprov på två olika bibliotek inom samma språk och ramverk avsedda för datahämtning över HTTP. Utvärderingen omfattar tidsåtgång vid förbestämda mängder data och förbestämda antal parallella anrop, för vardera klient skapade från biblioteken. Vid utförandet av experimentet togs nödvändiga åtgärder för att avskärma externa faktorer, och på så sätt förstärka validiteten. Mätningarna utfördes upprepade gånger på ett lokalt nätverk på en dator som ej var ansluten till internet, med övervakning på datorns egna prestanda- och processorkraft.
De två klienterna har lika förutsättningar både i implementation, men även under ex-ekvering och vid utförandet av experimentet. Webbapplikationen innehåller bägge kli-enter vars implementationen rent kodmässigt är anpassad för att klikli-enterna ska ha lika förutsättningar. Bakgrundsapplikationer var avstängda, flygplansläge var aktiverat och datorn startades om mellan varje moment av experimentet. Detta för att undvika even-tuella felvärden eller resultat som uppstått av slumpmässiga händelser.
Då cachning spelar en stor roll vid hämtning av data från internet, tog författarna hänsyn till detta. Experimentet utformades på ett sådant sätt att en evaluering kunde göras vid datahämtning från datorns lokala cache, och från det lokala nätverket. Cachningen togs till hänsyn under analyserna men även vid uppvisade resultat och vid diskussionen. Validiteten stärks ytterligare då standardavvikelse har räknats ut för vardera klients re-sultat. Resultaten som visas i denna studie är reproducerbara under förutsättningarna att de olika komponenterna är framtagna på samma sätt som under studien. Validite-ten stärks genom att mätningarna under experimentets gång uppförts och utförts på ett strukturerat sätt.
4
Empiri
Kapitlet ger en översiktlig beskrivning av den empiriska domän som ligger till grund för denna studie. Vidare beskrivs empirin som samlats in för att ge svar på studiens frågeställningar.
Nedan beskrivs empirin som samlats in från experimenten med cache och utan cache inblandat.
4.1
Empiri från experiment med cache
Den första empirin som redovisas är från experimentet där cache-hanteringen ej togs hänsyn till. Omstart skedde ej mellan varje körning av experimentet, vilket medförde att data som hämtades kom från datorns lokala cache, istället för från nätverket. Alla hämt-ningar skedde med ett antal parallella anrop enligt kapitel 3.3.3 Implementation. Figurer 11, 12 och 13 visar jämförelsen mellan medelvärden från experimentet vid körning av RestSharp och Flurl mot datorns lokala cache.
Tabeller 4 och 5 visar den genomsnittliga standardavvikelsen och medelvärdet för varje dataset som utgör nödvändig data för att utföra t-testet, enligt kapitel 3.6.2 Signifikan-sanalys.
Figur 11. Mätvärden på RestSharps och Flurls prestanda med cacheade värden, data-mängd 0,1 MB
Figur 12. Mätvärden på RestSharps och Flurls prestanda med cacheade värden, data-mängd 1 MB
Figur 13. Mätvärden på RestSharps och Flurls prestanda med cacheade värden, data-mängd 2,5 MB
RestSharp Standardavvikelse (ms) Medelvärde (ms) SET 0,1 0,1 - 1 5,645931563 301,1111111 0,1 - 50 52,81156813 501,7777778 0,1 - 199 21,21553123 843,8888889 SET 1 1 - 1 7,333333333 341,3333333 1 - 50 23,95726648 923,7777778 1 - 199 77,683117 2639,333333 SET 2,5 2,5 - 1 11,87901979 435,3333333 2,5 - 50 65,77477471 1796,111111 2,5 - 199 157,0873784 6129,333333 Tabell 4
Resultat från experiment på lokal cache för RestSharp
Flurl Standardavvikelse (ms) Medelvärde (ms)
SET 0,1 0,1 - 1 3,80058475 276,6666667 0,1 - 50 17,15362683 457,5555556 0,1 - 199 17,21182482 786,4444444 SET 1 1 - 1 6,590303389 317,1111111 1 - 50 23,06030741 890,6666667 1 - 199 122,1020621 2590,555556 SET 2,5 2,5 - 1 16,55592841 384,1111111 2,5 - 50 134,0404398 1847,222222 2,5 - 199 145,0149418 6057 Tabell 5
4.2
Empiri från experiment utan cache
Den andra empirin som redovisas är från det andra experimentet, där cache-hantering togs hänsyn till. Omstart skedde mellan varje körning av experimentet, vilket ledde till en rensning av datorns lokala cache, och alla körtider är opåverkade av datorns cache. Figurer 14, 15 och 16 visar jämförelsen mellan medelvärden från experimentet vid kör-ning av RestSharp och Flurl mot det lokala nätverket.
Tabeller 6 och 7 visar den genomsnittliga standardavvikelsen och medelvärdet för varje dataset som utgör nödvändig data för att utföra t-testet, enligt kapitel 3.6.2 Signifikan-sanalys.
Figur 14. Mätvärden på RestSharps och Flurls prestanda med icke cacheade värden, datamängd 0,1 MB
Figur 15. Mätvärden på RestSharps och Flurls prestanda med icke cacheade värden, datamängd 1 MB
Figur 16. Mätvärden på RestSharps och Flurls prestanda med icke cacheade värden, datamängd 2,5 MB
I detta experiment visar sig båda biblioteken vara likvärdiga i körtid, förutom en påbör-jad trend som visar sig i en kombination av större datamängd och samtidiga, parallella anrop. RestSharp visar sig bli något långsammare än vad Flurl är, även om skillnaden är liten, så går det urskilja att trenden är relevant för studien.
RestSharp Standardavvikelse (ms) Medelvärde (ms) SET 0,1 0,1 - 1 119,9612437 1014,2 0,1 - 50 34,8898266 2009,4 0,1 - 199 98,81700259 2106,6 SET 1 1 - 1 35,33411949 1127 1 - 50 201,5296504 2385,2 1 - 199 38,66264347 4063,4 SET 2,5 2,5 - 1 16,96466917 1231,4 2,5 - 50 108,0946602 3329,3 2,5 - 199 51,50070118 7615,9 Tabell 6
Resultat från experiment utan lokal cache RestSharp
Flurl Standardavvikelse (ms) Medelvärde (ms)
SET 0,1 0,1 - 1 56,9122131 1046 0,1 - 50 59,70175877 2057,6 0,1 - 199 32,01562119 2177 SET 1 1 - 1 30,80097401 1154,2 1 - 50 190,7611071 2121,6 1 - 199 161,4481341 4023 SET 2,5 2,5 - 1 59,50630219 1211 2,5 - 50 56,49149395 3165,2 2,5 - 199 100,7510132 7118,1 Tabell 7
5
Analys
Kapitlet ger svar på studiens frågeställningar och hypoteser genom att behandla insam-lad empiri och teoretiskt ramverk.
5.1
Frågeställning 1
För att besvara frågeställning nummer 1 utfördes experiment på de två biblioteken för att mäta tidsåtgången vid hämtning av olika mängder av data i olika antal parallella, asynkrona anrop. Efter litteraturstudie och granskning av kodbaser formulerades följan-de hypotes: RestSharp och Flurl är jämnlika i prestanda vid hämtning av data.
För att bestämma om det finns en distinkt, signifikant skillnad mellan ramverken gjordes en signifikansanalys på resultaten. Signifikanalysen bestämmer även om nollhypotesen, kR= kF, som beskrivs i kapitel 3.6.2 Signifikansanalys, skall förskastas eller ej.
Nollhy-potesen kontrollerades genom ett “Students t-test”, där ett p-värde togs fram och använ-des som gränsvärde. Då experimentet avser två olika scenarion behövanvän-des två separata analyser genomföras.
När studiens hypotes sammanställdes visste författarna inte att det skulle krävas två se-parata datainsamlingar, då den nya kunskapen om cachning kom med studiens gång. Författarna visste ej vart någonstans cachningen skedde, och därför togs de två experi-menten fram. Experiexperi-menten speglar verkliga scenarion på olika sätt eftersom cachning av data även sker i verkliga datorsystem.
Empirin insamlad till frågeställning nummer ett gör att författarna med säkerhet kan förkasta studiens hypotes H0, som hittas under kapitel 3.2 Hypotes. Författarna finner
att båda analyserna visar en tendens till att det är skillnad på klienternas prestanda, då Flurl visar sig ha en marginellt lägre fördröjningstid.
5.1.1 Analys av experiment med cache
Experimentet som utfördes vid datahämtning från datorns lokala cache resulterade i värden enligt tabell 5 under kapitel 4.1 Empiri från experiment med cache. Då värdena från experimentet var normalfördelade kunde t-testet utföras, och uppgav ett p-värde på p= 0.02100305045. Ett p-värde som är lägre än < 0.05 uppvisar en signifikant skillnad
och medför att vi med säkerhet kan säga att nollhypotesen förkastas. Det resulterar i att pr 6= pf, p = prestanda, r = RestSharp, f = Flurl, och visar på att RestSharp blir
långsammare än vad Flurl är, när mängden data och antalet anrop ökar.
5.1.2 Analys av experiment utan cache
Då data som utvunnits ur experimentet ej var normalfördelade kunde ett “Student’s t-test“ ej genomföras. Dock så kan man, med hjälp av mätvärden och grafer, urskilja en påbörjad trend hos HTTP-klienterna. Som figur 17 visar så ökar differensen mellan HTTP-klienterna i takt med mängden data och antal anrop. Differensen är framtagen enligt ekvation 6 och sker i fördel till Flurl, då RestSharp får en längre fördröjningstid. Medan RestSharp presterar marginellt snabbare i tidigare dataset.
D(d) = Mrd− Mf d (6)
D= differens, d = dataset, M = medelvärden, r = RestSharp, f = Flurl
5.2
Frågeställning 2
För att besvara frågeställning nummer 2 utförs en kodbasanalys av de bägge biblioteken. Eftersom HTTP-klienterna körs i samma webbapplikation och mot samma REST API och databas är det HTTP-klienterna själva som kan ha olika prestanda. Tabell 8 visar resultat från kodbasanalysen enligt de kriterier som beskrivs i kapitel 3.7 Analys av vardera kodbaser.
Kategori RestSharp Flurl
Task-baserat mönster Inget övertag Inget övertag
Await Inget övertag Inget övertag
LINQ-functions Inget övertag Inget övertag
Antal logiska kodrader 16 43
Kodens kvalité 1 4
Tabell 8
Kodbasernas kategorier och dess resultat
Flurls kodkvalité är bättre än RestSharps enligt tredjeparten Lumnify. Men eftersom författarna inte har tillgång till tredjepartens algoritmer som räknar ut kvalitén kan inte heller någon giltig slutsats ges. Det skiljer bara 27 stycken kodrader mellan HTTP-klienterna, och det är inte tillräckligt för att säga varför Flurl har lägre fördröjningstid än RestSharp. En liten differens i antal kodrader utgör endast nanosekunder i skillnad, och är ett för vagt kriterie för att dra slutsatser från [42]. Övriga kategorier ger inte någon HTTP-klient fördel över den andra när det gäller tidsfördröjningen och kan heller inte förklara varför den ena är snabbare än den andra.
Skillnaden i fördröjningstiden ligger inte hos HTTP-klienterna RestSharp och Flurl ut-an hos de klasser de ärver funktionalitet från. Som visat i de bägge kodbasernas ked-jereaktion av funktioner som anropas, kapitel 3.7 Analys av vardera kodbaser, anropar Flurl metoder med hjälp av HttpClient-instansen i slutet, medan RestSharp använder HttpWebRequest-instansen. Microsoft rekommenderar att man nu använder HttpClient-klassen för att konsumera HTTP-förfrågningar [16]. Eftersom våra resultat från expe-rimenten pekar på att Flurl har en lägre fördröjningstid med fler parallella anrop, har författarna antagit att detta beror på att biblioteket använder HttpClient-klassen, vil-ket RestSharp inte gör. Alltså krävs det vidare forskning på ursprungsklasserna för att validera antagandet att HttpClient, som är den mer sofistikerade dataklassen, är den bakomliggande orsaken till skillnaden i fördröjningstid.
På grund av denna studiens begränsade omfattning och tidsram har inte en analys gjorts på klasserna HttpClient och HttpWebRequest. Enligt flera artiklar nämns det att HttpCli-ent har funktionalitet som inte HttpWebRequest har. Bland annat kan man skicka obe-gränsat antal förfrågningar genom en enda instans av HttpClient vilket lägger sig i en så kallad anslutningskö (engelska: connection pool) [43] [44] [45]. HttpClient-klassen etablerar en kö av anslutningar till vald webbserver och skickar förfrågningar från denna kö. Efter varje avslutad förfrågan läggs anslutningen in i kön igen för att invänta att nya förfrågningar skall inkomma. RestSharp använder inte denna teknik och det kan vara svaret på varför Flurl har en marginell lägre fördröjningstid.
5.3
Frågeställning 3
För att besvara frågeställning nummer 3 rekommenderar vi att använda Flurl före Rest-Sharp, men bara om man endast bryr sig om prestandan. Skillnaden i prestandan är marginell och andra faktorer såsom användarvänlighet eller vilken .NET-plattform som används vägs in mer. Används .NET-plattformen 4.5 eller lägre är RestSharp det enda alternativet. Optimering skall alltid prioriteras, men om det tillför att utvecklare måste göra drastiska omställningar, så som att lära sig nya bibliotek, är det inte värt vinsten, då det enbart ger mikrodelar av sekunder i prestandaökning. Som matematikern och da-talogen Donald Knuth sade 1974, “We should forget about small efficiencies, say about 97% of the time: pre- mature optimization is the root of all evil” [46].
Efter utförd studie kan vi rekommendera användningen av Flurl vid större mängder data och vid flera parallella anrop. Vidare rekommenderar vi att använda RestSharp om da-torsystemet hanterar små mängder data och få klienter. Det behövs dock fler experiment och mer forskning kring klienterna för att ge starka rekommendationer.
6
Diskussion och slutsatser
Kapitlet inleds med en kort diskussion, sedan ges en sammanfattande beskrivning av studiens resultat. Vidare beskrivs studiens implikationer och begränsningar. Dessutom beskrivs studiens slutsatser och rekommendationer. Kapitlet avslutas med förslag på vidare forskning.
6.1
Diskussion kring analys av kodbas
En uträkning av kodbasernas vardera tidskomplexitet skulle ge oss en uppfattning om hur tiden ökar i takt med mängden inskickad data [47]. Detta skulle ge svar på varför för-dröjnigstiden hos Flurl är lägre än RestSharp. Men eftersom funktionerna som används i biblioteken bara accepterar en typ av inskickad data, och inte heller mer data, kommer tidskomplexitet alltid förbli konstant, Ordo(1). Ordo används inom datavetenskap för att beskriva algoritmers effektivitet [48]. Enda stället där tidskomplexitet förekommer är i vår egna webbapplikation och där är tidskomplexiteten detsamma för båda bibliotek, nämligen Ordo(n). Därav är en uträkning av tidskomplexitet inte relevant för att mäta varför den ena HTTP-klienten har en lägre fördröjningstid ju mer data vi vill hämta i experimentens försök.
6.2
Resultat
Frågeställning 1 - Är det någon skillnad mellan RestSharp och Flurl i fördröjningstid när det gäller att hämta data via HTTP med avseende på olika stora datamängder och antal anrop som sker parallellt?
Resultaten från experimenten med cache inblandat visar signifkansanalysen att klienterna skiljer sig i tidsfördröjning, där Flurl är den marginellt snabbare HTTP-klienten. Vidare visar resultaten från experimenten som utformades utan cache att Flurl får en lägre fördröjningstid ju mer data som anropas parallellt. Detta visas i kapitel 4 Empiri.
Frågeställning 2 - Oavsett om det är en substantiell skillnad eller ej i fördrjöningstiden, vill vi ta reda på varför, genom att utföra en litteraturstudie på de två olika HTTP-klienterna.
Utifrån kodbasanalysen av de bägge biblioteken har Flurl en lägre fördröjningstid då biblioteket använder klassen HttpClient som kärnan av all funktionalitet, vilket analy-seras i kapitel 5 Analys.
Frågeställning 3 - Finns det tillämpningar där man skulle kunna rekommendera Rest-Sharp framför Flurl, och vice versa?
Enligt resultaten från experimenten är Flurl det alternativ som får din applikation att uppnå lägsta fördröjningstid när det gäller att konsumera data via HTTP med många parallella anrop och mycket data. Om datamängden är lägre än 0,1 megabyte rekom-menderas RestSharp.
6.3
Implikationer
Studien fyller ett kunskapshål om vilken HTTP-klient som presterar bäst. Resultaten bidrar med underlag för att underlätta vid valet av HTTP-klient för Consid, men även andra IT-företag. Dessutom har studien bidragit till en allmänt bredare kunskap inom HTTP-klienter och deras prestanda, som även kan användas i vidare forskning.
6.4
Begränsningar
Det fanns inte tillräckligt med tid att analysera Native klasserna i .NET som behövs för att svara mer utförligt på frågeställning två. Vi hade ej möjlighet att isolera miljön ytterligare för experimentet helt på grund av tillgängliga resurser. Detta försämrade ex-perimentet då vi kanske hade fått normalfördelade värden på experiment 5.1.2 Analys av experiment utan cacheom vi hade kunnat isolera miljön. Då hade vi kunnat utföra ett till t-test och på så sätt kunnat generalisera våra rekommendationer.
Då tidsspannet har varit begränsat kunde vi inte göra det antalet iterationer i experimen-tet som vi hade velat göra. Ett mer optimalt antal iterationer hade varit upp mot 500 stycken, detta för att fasa ur så många externa faktorer som möjligt. Till exempel hade effekten av eventuella störningar försummats. Experimentet hade kunnat utökas för att ta hänsyn till större mängder data. Överlag kunde ingen generalisering göras till andra HTTP-klienter. Hade experimentet körts på fler enheter och olika datorer hade vi fått mer allmänna och realistiska värden. Experimentet hade även kunnat utökas till andra språk, som till exempel F#, för att generalisera till en större del av .NET-ramverket.
6.5
Slutsatser och rekommendationer
Föreliggande studie visar att HTTP-klienten Flurl har en marginellt lägre fördröjningstid än RestSharp. När det väl kommer till valet för HTTP-klient rekommenderar vi att an-vända biblioteket Flurl. Men eftersom skillnaden i prestanda är så pass marginell skall denna rekommendation tas med omtanke. Valet av klient borde styras av faktorer där bland annat vilken .NET-plattform utvecklaren använder, användarvänlighet och andra villkor som har betydelse för just utvecklarens omständigheter.
6.6
Vidare forskning
Denna studie var genomförd på experiment som skedde i en isolerad miljö. I framtida studier skulle man kunna utföra dessa experiment även i en verklighetsbaserad miljö. Med andra ord låta HTTP-förfrågningarna skickas till en webbserver som ligger i ett nätverk utanför webbapplikationens egna nätverk. Validiteten av studien skulle stärkas då många verkliga system även kommunicerar utanför sitt egna nätverk. Till följd av att studien är en högskoleingenjörsuppsats och att tidsramen är begränsad utfördes aldrig detta.
Framtida studier skulle också kunna inkludera implementation av en egen HTTP-klient från grunden och enbart fokusera på prestanda och inget annat. Vidare jämföra den egenbyggda HTTP-klienten med de befintliga för att se om det är möjligt att utveckla ett bibliotek som tillför en lägre fördröjningstid. Å ena sidan om prestandan blir bättre, kan man föreslå detta bibliotek till IT företagen istället. Å andra sidan om prestandan blir likvärdig, kan man undersöka om det är HTTP-klienten i sig som är flaskhalsen av fördröjningstiden eller inte.
Vidare rekommenderar vi att man gör en studie med fler parallella anrop och större mängder data för att fortsätta analysera den trenden vi upptäckt i kapitel 4.2 Empiri från experiment utan cache. Det kan visa sig att differensen går stadigt uppåt och bekräftar skillnaden på prestanda mellan klienterna.
Referenser
[1] Scott Hanselman. Comparison of Flurl and HttpClient. 2018-06-23.URL: https:
//www.hanselman.com/blog/UsingFlurlToEasilyBuildURLsAndMakeTestableHttpClientCallsInNET .aspx (hämtad 2020-01-18).
[2] Microsoft. .NET Documentation. URL: https : / / docs .microsoft .com / en -us/dotnet/ (hämtad 2020-01-18).
[3] Stack Overflow. Stack Overflow survey 2019 development. 2019. URL: https:
//insights.stackoverflow.com/survey/2019 (hämtad 2020-05-21). [4] Mattias Cederlund. Performance of frameworks for declarative data fetching An
evaluation of Falcor and Relay+GraphQL. Tekn. rapport. 2016.
[5] Arnar Freyr Helgason. “Performance analysis of Web Services: Comparison between RESTful & GraphQL web services”. I: (2017), s. 1–66.
[6] Fiach Reid. Network programming in. NET: with C# and Visual Basic. NET. El-sevier, 2004, s. 6.
[7] Richard Blum. C# network programming. John Wiley & Sons, 2006, s. 522–528. [8] NuGet. RestSharp statistics on NuGet. 2020. URL: https://www.nuget.org/
packages/RestSharp (hämtad 2020-05-22).
[9] NuGet. Flurl statistics on NuGet. 2020. URL: https : / / www .nuget .org / packages/Flurl/3.0.0-pre3 (hämtad 2020-05-22).
[10] Sarah Ishida Preston Gralla. How the Internet works. Indianapolis, IN, 1998, s. 41.
[11] Mark Masse. REST API Design Rulebook: Designing Consistent RESTful Web Service Interfaces. Ö’Reilly Media, Inc.", 2011.
[12] Joel L. Fernandes m. fl. “Performance evaluation of RESTful web services and AMQP protocol”. I: International Conference on Ubiquitous and Future Networks, ICUFN (2013), s. 810–815. ISSN: 21658528. DOI: 10 .1109 / ICUFN .2013
.6614932.
[13] Dave Evans. The Internet of Things. 2011-04-010. URL: https://www .cisco .com/c/dam/en_us/about/ac79/docs/innov/IoT_IBSG_0411FINAL.pdf (hämtad 2020-03-17).
[14] Oleg Kalnichevski, Jonathan Moore och Jilles van Gurp. HttpClient Tutorial. 2009.