Teknik och samhälle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Analys av prediktiv precision av maskininlärningsalgoritmer
Analysis of predictive precision of Machine Learning algorithms
Jonas Remgård
Examen: kandidatexamen 180 hp Huvudområde: datavetenskap Program: Applikationsutveckling Datum för slutseminarium: 2017-05-30
Handledare: Ivan Kruzela Examinator: Johan Holmgren
Sammanfattning
Maskininlärning (eng: Machine Learning) har på senare tid blivit ett populärt ämne. En fråga som många användare ställer sig är hur mycket data det behövs för att få ett så kor-rekt svar som möjligt. Detta arbete undersöker relationen mellan inlärningsdata, mängd såväl som struktur, och hur väl algoritmen presterar. Fyra olika typer av datamängder (Iris, Digits, Symmetriskt och Dubbelsymetriskt) studerades med hjälp av tre olika algoritmer (Support Vector Classifier, K-Nearest Neighbor och Decision Tree Classifier). Arbetet fast-ställer att alla tre algoritmers prestation förbättras vid större mängd inlärningsdata upp till en viss gräns, men att denna gräns är olika för varje algoritm. Datainstansernas struk-tur påverkar också algoritmernas prestation där dubbelsymmetri ger starkare prestation än enkelsymmetri.
Abstract
In recent years Machine Learning has become a popular subject. A challange that ma-ny users face is choosing the correct amount of training data. This study researches the relationship between the amount and structure of training data and the accuracy of the al-gorithm. Four different datasets (Iris, Digits, Symmetry and Double symmetry) were used with three different algorithms (Support Vector Classifier, K-Nearest Neighbor and Deci-sion Tree Classifier). This study concludes that all algorithms perform better with more training data up to a certain limit, which is different for each algorithm. The structure of the dataset also affects the performance, where double symmetry gives greater performance than simple symmetry.
Innehåll
1 Inledning 1
1.1 Bakgrund . . . 1
1.2 Maskininlärning . . . 1
1.2.1 Övervakad och Oövervakad inlärning . . . 1
1.2.2 Utvärdering av Algoritmernas Prestation . . . 1
1.3 Syfte . . . 2 1.4 Frågeställning . . . 2 1.5 Avgränsning . . . 2 1.6 Tidigare forskning . . . 2 2 Metod 3 2.1 Metodbeskrivning . . . 3 2.2 Litteraturstudie . . . 4 2.2.1 Nyckelord . . . 4 2.2.2 Val av artiklar . . . 5
2.2.3 Fastställande av komplett litteraturlista samt kvalitet av artiklar . . 5
2.3 Scikit Learn . . . 8
2.4 Algoritmer . . . 8
2.4.1 Support Vector Classifier . . . 8
2.4.2 K-Nearest Neighbor . . . 9
2.4.3 Decision Tree Classifier . . . 10
2.5 Datamängder . . . 11 2.5.1 Iris . . . 11 2.5.2 Digits . . . 12 2.5.3 Symmetri . . . 13 2.5.4 Dubbelsymmetri . . . 13 2.6 Utvärdering . . . 14 2.6.1 Cross-validation . . . 14 2.6.2 Confusion Matrix . . . 15 2.6.3 ROC . . . 15 2.6.4 Skew . . . 17 2.7 Experiment . . . 17 2.8 Metoddiskussion . . . 18 3 Resultat 18 3.1 Symmetriskt datamängd . . . 19 3.2 Dubbelsymmetriskt datamängd . . . 20 3.3 Iris datamängd . . . 22 3.4 Digits datamängd . . . 23 4 Analys 24 4.1 Mängden inlärningsdata . . . 24
4.1.1 Symmetri och Dubbelsymmetri . . . 24
4.1.2 Iris . . . 25
4.2 Datamängdens struktur . . . 26
5 Diskussion 26 5.1 Support Vector Classifier . . . 26
5.2 K-Nearest Neighbor . . . 26
5.3 Decision Tree Classifier . . . 27
5.4 Tidigare forskning . . . 27
6 Slutsatser och vidare forskning 27
Referenser 30
A Bilaga, Skapandet av dataset 32
1
Inledning
1.1 BakgrundMänniskan har sedan länge haft drömmar om maskiner med intelligens. Bland annat skrev Mary Shelly redan i början av 1800-talet om en tillverkad människoliknande varelse som hade en viss form av intelligens i boken Frankenstein. Vidare skrev Karel Čapek pjä-sen R.U.R (Rossum Universal Robots) som hade premiär redan 1920. Detta kan ha varit grunden till forskningens försök till att skapa Artificiell Intelligens. Forskningsområdet Ar-tificiell Intelligens skapades under en konferens som kom till att kallas “The Dartmouth Artificial Intelligence Conference“[15]. Därefter påbörjades en del forskning kring Artifi-ceill Inteligens och maskininlärning, bland annat skrev Jaime G. Carbonell, Ryszard S. Michalski och Tom M. Mitchell tillsammans med flertalet författare ett arbete redan 1983, ”An overview of Machine Learning”, som skulle ha stor betydelse för utvecklingen av ämnet maskininlärning.
1.2 Maskininlärning
Lärandet har många delar. Själva processen inkluderar bland annat intaget av ny kunskap, utvecklingen av motorik och kognitivt beteende och upptäckten av ny fakta genom bland annat observationer. Man har sedan den första datorn strävat efter att göra det möjligt för maskiner att uppnå denna förmåga. Att implementera detta har dock visat sig vara utmanande. Detta område inom datavetenskap har kommit att kallas maskininlärning och är ett långsiktigt mål för Artificiell Intelligens[3]. För maskininlärning är nyckelkonceptet att lära sig från data, vilket kan liknas med människans inlärning från erfarenheter. För att hantera detta på maskinell nivå går det att dela in problemet i tre delar; att komma ihåg, att anpassa sig och att generalisera[14]. Maskininlärning är ett på senare tid särskilt uppmärksammat ämne[10].
1.2.1 Övervakad och Oövervakad inlärning
Den vanligaste formen av inlärning inom maskininlärning är en övervakad inlärning. Ett typiskt scenario inom maskininlärning är ett klassificeringsproblem. Utifrån ett visst antal variabler klassificeras en datainstans att tillhöra någon av (N) grupper. Detta baseras på den tidigare datan som algoritmen fått i inlärningsprocessen. För övervakad inlärning krävs det en datamängd för träning av algoritmen. I denna datamängd finns det dels input data som är de vanliga variabler som utger de olika datamängdernas struktur. Därefter finns det även en så kallad target input som visar på vad för klassificering den givna datan representerar[14]. På så sätt övervakas vilken inlärningsdata som algoritmen får från datamängden. En annan form av inlärning, som syftar till att gruppera liknande element, är den oövervakade vilket är inlärning av en datamängd som inte innehåller ett targetattribut. Detta leder till att algoritmen inte vet vad den korrekta klassificeringen är och kan därför inte veta om den gjort rätt eller fel[14].
1.2.2 Utvärdering av Algoritmernas Prestation
En viktig del inom maskininlärning är att utvärdera hur bra algoritmen presterar efter inlärningsprocessen. Detta för att slippa sätta en algoritm i produktion som inte presterar
som den ska. Det finns flera olika metoder för att mäta prestationen av en algoritm. En algoritm kan ge bra resultat på ett mätsätt medan det ger dåliga resultat på ett annat. De olika mätsätten ger alltså olika bilder av hur väl algoritmen faktiskt presterar med den givna inlärningsdatan[4]. Under senare tid har ROC grafen, se 2.6.3, blivit allt mer populär bland forskare och fått fler efterföljare mycket på grund av insikten att vanliga enklare mättekniker inte ger en rättvis bild vid mätning av prestationen[20].
1.3 Syfte
Det finns över 10.000 olika algoritmer i området maskininlärning, många av dessa är väldigt lika varandra i sitt utförande[14]. Detta arbete fokuserar på att jämföra tre olika algorit-mer, Support Vector Classifier, K-Nearest Neighbor och Decision Tree Classifier. Jag har valt att hålla mig till klassificeringsalgoritmer på grund av de datamängder som använts, nämligen Iris, Digits, Symmetri och Dubbelsymmetri. De tre algoritmerna valdes ut på grund av dess olikheter i klassificeringsstadiet, men även på grund av deras popularitet inom forskarvärlden[5][19][21]. Jag vill se hur mängden inlärningsdata påverkar algorit-mens prestation att klassificera nya datainstanser rätt. Jag vill även se om datamängdens struktur så som skillnaden på symmetri och dubbellsymmetri spelar roll.
1.4 Frågeställning
För maskininlärningsalgoritmerna K-Nearest Neighbor, Support Vector Classifier och De-cision Tree Classifier ställdes följande frågor:
• Hur påverkar mängden inlärningsdata algoritmens prediktiva precision? • Hur påverkar strukturen av inlärningsdata algoritmens prediktiva precision?
1.5 Avgränsning
Inriktningen för studien är binär klassificering. Jag fokuserar på tre olika algoritmer och sex olika datamängder som ger en god överblick av resultatet. Testerna ger endast en indikation för algoritmernas egenskaper, och inte några definitiva svar. För att utföra en fullständigare men också mer tidskrävande utvärdering bör metoder som ROC kurvor och AUC användas vilket möjligen kan ge mer definitiva svar[26][7].
1.6 Tidigare forskning
Det som går att finna i litteraturen om tidigare forskning i ämnet för min studie är av mycket olika karaktär. Däremot är det lättare att finna forskning som tar upp grunderna för mitt arbete så som analyser av existerande mätmetoder och algoritmer samt forskning om inlärningskurvor. Det arbete som främst relaterar till de metoder som är relevanta för min forskning är Louis Yelle som forskat om inlärningkurvor[31]. Det han tar upp i sitt arbete är hur mängden inlärningsdata förhåller sig till algoritmers prestation, men studien är relativt gammal och fokuserar på litteratur om inlärningskurvor från andra världskri-get fram till 1979. Vidare redovisar Gong Huang ett arbete om inlärningskurvor[12]. Han beskriver i sin forskning hur företag skall gå till väga för att skapa bra applikationer. Nå-got annat arbete som tidigare använt sig av struktur och symmetri på det sättet som jag
använder mig av kunde inte hittas. Det närmaste jag kunde komma var ett arbete som försökte hitta symmetri i mänskliga ansikten[30]. Ännu ett annat arbete som kunde kopp-las till min forskning var en studie av Defeng Wang som gjort ett arbete om att välja rätt inlärningsdata för SVMs med hjälp av en analys av strukturen. I sitt arbete beskriver han hur han utvecklat en algoritm som skall förenkla valet av datainstanser för inlärning. Algoritmen han utvecklat kallar han för ”SR-DSA” vilket är en förkortning av ”Sample Reduction by Data Structure Analysis”[29]. Vidare finns ett arbete av Greg Schohn och David Cohn som även de går igenom SVMs[22]. De beskriver ett sätt att välja inlärnings-data för en algoritm genom heuristik. Detta är en metod för att välja ut inlärninginlärnings-data utan att använda sig av information om datan. Författarna kommer i sin forskning fram till att med rätt teknik kan man minimera mängden inlärningsdata och få ut bättre precision än om man använder mer eller hela datamängden. De visar även på att precisionen faktiskt kan bli sämre vid en inlärning av hela datamängden istället för en utvald del. Detta är även någonting som Shai Shalev-Shwartz och Nathan Srebro visar på i sin forskning[24], precisionen på en SVM minskar i takt med att inlärningsmängden ökar. Vidare utför även George Forman och Ira Cohen liknande tester där de analyserar fyra algoritmer, SVM, Logic Regresion, Naive Bayes och Multinomial Naive Bayes, med olika verklighetstrogna scenarion[8]. Även de kommer fram till att precisionen för en SVM faktiskt är bättre med ett fåtal inlärningsdata medans detta inte är fallet för de resterande algoritmer som de tes-tar. Någonting som även är användbart för min forskning är analysen och utvärderingen av mätverktyget ROC, se 2.6.3. Den forskning som gjorts inom detta område är Tom Fawcett som gjort en tidigare forskning i hur ROC kurvor används och hur de ska skapas för bästa resultat[6]. Ett annat arbete inom ämnet är skrivet av James A. Hanley och Barbara J. McNeil som arbetat fram meningen med arean under en ROC kurva, även kallat AUC[11]. Andra intressanta områden för mitt arbete innefattar även Cross-validation vilket Sylvain Arlot har arbetat med. Arlot redovisar hur en Cross-validation metod skall väljas för ett givet problem[1].
2
Metod
2.1 Metodbeskrivning
För att hantera forskningsfrågan utför jag flertalet experiment där jag analyserar preci-sionen av de olika algoritmerna vid olika mängder inlärningsdata. Flera olika typer av inlärningsdata används för att ge en rättvis bild av algoritmernas prestation. Dessa data-mängder är Iris, se 2.5.1, vilket är en välkänd datamängd inom maskininlärning, Digits, se 2.5.2, även det en välkänd datamängd, samt några egenskapade datamängder baserade på symmetri, se 2.5.3 och 2.5.4. De utvalda algoritmerna lärdes upp med olika mängder datainstanser från datamängderna varefter omfattande tester utfördes på de upplärda algo-ritmerna. Mängden datainstanser ökades stegvis och algoritmens prestation testades med resterande mängd. Resultatet av experimenten är analyserade med hjälp av olika metoder som återfinns i litteraturen.
2.2 Litteraturstudie
En litteraturstudie genomfördes för att förstå vad tidigare forskning inom maskininlärning och utvärdering av maskininlärningsalgoritmer visar. De vanligaste databaser och sökmo-torer att använda sig av inom detta ämne är ACM Digital Library, IEEE Xplore Digital Library, SpringerLink och Google Scholar. Detta gör att jag har utgått ifrån dessa när jag utfört min litteraturstudie. I början av min litteraturstudie använde jag mig av ACM, IEEE samt Springer som är mer specifika för datavetenskap. Där skapade jag mig en för-ståelse av vilka artiklar som var av vetenskapligt värde och tyngd. Med dessa artiklar som bas kunde jag sedan använda mig av Google Scholar för att täcka ett bredare område och därigenom säkerställa att jag inte missat viktig litteratur. Som kan ses i Tabell 1 på rad 4 så söker jag efter ”Machine Learning” AND ”scikit” AND ”evaluating” och får då 1 träff på IEEE. På nästa rad lägger jag till ett sökord , ”score” och får då 1,637 resultat på IEEE. Vid dessa tillfällen har jag valt att använda mig av den sökmotor som givit mest regelbun-det resultat av mina sökningar, vilket i regelbun-detta fallet varit Google Scholar. Litteraturstudien fortlöpte under forskningsstudien då nya problem och aspekter uppenbarades.
2.2.1 Nyckelord
För att göra informationssökningen effektiv lades ett antal nyckelord fram som riktlinjer vid sökningar. Dessa nyckelord användes både tillsammans och var för sig för att finna tillförlitliga resultat i givna databaser. Se Tabell 1 för att få en överblick av de olika sökningar som gjordes. Nyckelorden som användes vid varje sökning var två fundamentala ord för mitt forskningsområde som filtrerar bort största delen av det som inte var relevant för min forskning. Dessa två ord var ”Machine” och ”Learning” som kombinerat blir en fras att använda i min systematiska litteratursökning. ”Machine Learning” kan ses i Tabell 1 resulterar i ca 2,180,000 träffar på Google Scholar och tusentals träffar i resterande databaser, men det ger trots allt en tydlig avgränsning av mitt område som var nödvändigt att göras vid mitt sökande. Därför gjorde jag valet att använda ”Machine Learning” i samtliga sökningar följt av nyckelord från följande lista baserad på frågeställningen.
• Evaluation • Score • Performance • Accuracy • Comparison • Learning Curve • Structure • Symmetry • Size • Dataset
Dessa nyckelord användes vid sökande av relaterad forskning. Vidare användes även andra nyckelord för att finna information om metodval och liknande. Dessa nyckelord var:
• ROC Space • Cross Validation • Confusion Matrix • Scikit
2.2.2 Val av artiklar
Vid varje sökning gick jag igenom de första 100 resultaten för att analysera titel samt nyckelord. Om dessa var intressanta för studien sparades artikeln ned för en vidare analys av informationen. Efter första genomgången av titlar läste jag sammanfattningen vilket avgör om texten innehåller relevant information så som titeln antytt. Om innehållet i sammanfattningen var relevant sparade jag undan artikeln för ytterligare bedömning och analys. Uppfyllde artikeln kraven fram till denna punkt läste jag artikeln i sin helhet och fattade ett slutgiltigt beslut om artikelns innehåll var relevant information för forskningen, och sparades då undan för användning. Ett resultat av sökningarna kan ses i Tabell 2.
2.2.3 Fastställande av komplett litteraturlista samt kvalitet av artiklar
Om artikeln nådde det stadiet att jag läste sammanfattningen så gick jag oavsett resultat också igenom referenslistan. Detta för att finna andra möjliga källor samt att värdesätta artikelns vetenskapliga kvalitet och relevans, men också för att säkerställa att min littera-turlista var komplett. Fann jag referenser som är relevanta i denna genomgång så skedde ytterligare sökningar med dessa referenser som nyckelord.
Tabell 1: Använda sökord samt antal resultat för de använda sökmotorerna.
Sökord GOOGLE ACM SPRINGER IEEE Artikel
”Machine Learning” 2,180,000 25,581 18,639 40,972
-”Machine Learning” AND ”scikit”
9,320 5 163,864 8 [17]
”Machine Learning” AND ”Empirical Comparison”
1,240,000 3,668 53,497 164 [4]
”Machine Learning” AND ”scikit” AND ”evaluating”
3,100 0 163,864 1 [17]
”Machine Learning” AND ”scikit” AND ”evaluating” AND ”score”
2,040 0 163,864 1,637 [17]
”Machine Learning” AND ”evaluating” AND ”score”
251,000 659 55,918 315 [2][9]
”Machine Learning” AND ”evaluating” AND ”ROC”
”Machine Learning” AND
”evaluating” AND ”ROC
space”
55,300 88 7,013 11 [6][11]
”Machine Learning” AND
”accuracy” AND ”ROC
space” AND ”evaluating”
45,000 4 5,679 3,978 [6][7][11]
”Machine Learning” AND ”performance”
3,260,000 15,443 222,283 17,498 [3][10][15]
”Machine Learning” AND ”performance” AND ”com-parison”
2,680,000 856 132,862 1,378 [16][18]
”Machine Learning” AND ”performance” AND ”com-parison” AND ”classifica-tion”
2,410,000 181 70,317 699 [4]
”Machine Learning” AND
”performance” AND
”confusion-matrix”
42,100 599 6,108 31 [16][6]
”Machine Learning” AND ”iris dataset”
28,000 64 3,489 47 [17]
”Machine Learning” AND ”digits dataset”
41,300 3,484 4,067 62 [17]
”Machine Learning” AND ”symmetry”
141,000 87 19,943 111 [10][11]
”Machine Learning” AND ”KNN”
55,000 113 7,147 546 [17][11]
”Machine Learning” AND ”K-Nearest Neighbor”
84,300 2,080 13,688 1,000 [17][19]
”Machine Learning” AND ”Support Vector Machine”
1,700,000 11,398 99,663 14,939 [5]
”Machine Learning” AND ”Support Vector Classifier”
733,000 11,398 42,412 4,770 [5][17]
”Machine Learning” AND ”Decision Tree Classifier”
256,000 7,442 23,163 791 [21]
”Machine Learning” AND ”Imbalanced Data”
62,900 129 4,063 440 [20]
”machine learning” AND
”roc” AND ”auc”
37,900 35 4,926 108 [11]
”Machine Learning” AND ”cross-validation”
689,000 7,018 929 165,068 [1][25][13]
”Machine Learning” AND ”Learning Curve”
”Machine Learning” AND
”training” AND ”dataset
structure”
236,000 1,559 33,709 219 [29] [27]
”Machine Learning” AND ”Symmetry”
152,000 87 20,162 114 [30]
”Machine Learning” AND ”data set” AND ”size”
1,060,000 103,002 56,349 216 [22][8][24]
Tabell 2: Resultatet av litteraturstudien med titlar och dess referensnummer.
Titel Referensnummer
A survey of cross-validation procedures for model selection. [1]
Pattern Recognition [2]
An overview of Machine Learning. [3]
An empirical comparison of supervised Learning algorithms. [4]
LIBSVM: a library for support vector Machines. [5]
An introduction to ROC analysis. [6]
Learning decision trees using the area under the ROC curve. [7]
Learning from Little: Comparison of Classifiers Given Little Training [8]
The predictive sample reuse method with applications [9]
Genetic algorithms and Machine Learning. [10]
The meaning and use of the area under a receiver operating characteristic (ROC) curve.
[11]
Learning curve: principle, application and limitation. [12]
The art of forecasting–an analysis of predictive precision of Machine Learning models..
[13] A proposal for the dartmouth summer research project on artificial in-telligence, august 31, 1955.
[15]
Data analysis, including statistics. [16]
Scikit-learn: Machine Learning in Python. [17]
Tree induction vs. logistic regression: A Learning-curve analysis. [18]
K-nearest neighbor. [19]
Machine Learning from imbalanced data sets 101. [20]
CLOUDS: A decision Tree classifier for large datasets. [21]
Less is More: Active Learning with Support Vector Machines [22]
SVM optimization: inverse dependence on training set size. [24]
Cross-validatory choice and assessment of statistical predictions. [25]
A comparison of machine learning algorithms applied to hand gesture recognition.
[27]
Selecting valuable training samples for SVMs via datastructure analysis. [29]
Learning to compute the plane of symmetry for human faces. [30]
2.3 Scikit Learn
Python har under senare tid blivit allt mer använt inom den vetenskapliga sektorn på grund av sitt allt växande ekosystem av vetenskapliga bibliotek. Detta har gjort att ett välkänt ramverk inom maskininlärning har skapats just i Python. Ramverket kallas Scikit Learn och tillhandahåller implementeringar av många välkända och använda algoritmer för maskininlärning samtidigt som det behåller användarvänligheten av Python[17]. An-vändandet av Scikit Learn ger mig en snabb och enkel åtkomst till både Iris och Digits datamängd som finns packeterade med Scikit Learn, liksom ett effektivt ramverk för åt-komst av flera olika maskininlärningsalgoritmer. De tre algoritmer jag valt att arbeta med finns alla implementerade i Scikit Learn. Utöver de algoritmer och datamängder som till-handahålls fick jag via Scikit Learn även tillgång till ett flertal olika mätinstrument för att utvärdera de olika algoritmernas prestation. De mätinstrument som jag använde mig av var Cross-validation samt Confusion Matrix.
2.4 Algoritmer
För att utvärdera min frågeställning använde jag tre algoritmer baserade på olika inlär-ningsmetoder för att få ett tillräckligt omfångsrikt resultat. Samtliga algoritmer finns im-plementerade i Scikit Learn. Nedan beskrivs varje algoritm mer utförligt samt vilka para-metrar jag använt mig av vid implementationen.
2.4.1 Support Vector Classifier
Support Vector Machine eller SVM är en av de mest populära algoritmer använda vid ma-skininlärning. Den introducerades av Vapnik 1992 och och är en flexibel algoritm vilket gör den möjlig att använda till både klassificering, regression och andra inlärningsuppgifter[14][5]. Den ger ofta en bättre klassificeringsprestation än andra algoritmer på de flesta datamäng-der, däremot inte på större datamängder då den använder sig av en ”data matrix invertion” vilket kräver hög processorkraft. Att implementera en egen Support Vector Machine är myc-ket komplicerat och kräver djupare kunskap och tid än vad detta arbete omfattar[14]. Jag använde mig därför av en redan implementerad version av en Support Vector Machine som finns tillgänglig i Scikit Learn som tillät mig att manipulera de parametrar jag önskade. Support Vector Classifier eller SVC är den typ av Support Vector Machine som används vid klassificering. För den Support Vector Classifier som ingår i detta arbete användes en Linjär kärna vilket resulterar i en Linear Support Vector Classifier. Jag använde följande rad för att anropa den aktuella Support Vector Classifier algoritmen:
svc = SVC(kernel=’linear’, C=1.0)
Vilket resulterar i en Support Vector Classifier med följande egenskaper: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=’auto’, kernel=’linear’, max_iter=-1, probability=False,
Figur 1: Demonstration av en SVM[14]
En SVM försöker manipulera datan så att den enklare kan separeras i klasser. För att åstadkomma den bästa möjliga separationen mäter algoritmen upp en s.k. ”Margin”, se Figur 1, för att enklare kunna hitta en rak linje mellan de olika klasserna med en marginal mellan linjen och de närmaste datainstanserna. Algoritmen försöker skapa en marginal som är så stor som möjligt utan att någon av datainstanserna hamnar innanför[14].
2.4.2 K-Nearest Neighbor
K-Nearest Neighbor eller KNN är en algoritm som är utvecklad för användning vid bå-de övervakad och oövervakad maskininlärning[19]. I en K-Nearest Neighbor klassificeras datainstansen beroende på de N-närmaste grannar av den tidigare inlärda datan. Detta kräver att avstånden till alla olika datainstanser kalkyleras i minnet vilket är relativt kost-samt i processorkraft[14]. Detta gör en K-Nearest Neighbor algoritm effektiv och användbar för mindre datamängder, och mindre värdefull för större datamängder. Mängden grannar definieras för algoritmen genom variabeln K. Användes en K=1 kollar algoritmen på den datainstansen som är närmast, eller mest lik, för att sedan klassificera den givna datain-stansen. I detta arbete användes en K=5 och algoritmen klassificerar därför datan utifrån klasserna av de fem närmaste datainstanserna som finns i inlärningsdatan. Anpassningen av K är viktig. Anges ett K-värde som är för litet blir algoritmen känslig för utstickande data i datamängden. Anges däremot ett för högt värde på K blir träffsäkerheten lägre då al-goritmen tar hänsyn till datainstanser som ligger för långt borta för att vara relevanta[14]. Jag använde följande rad för att anropa K-Nearest Neighbor algoritmen:
Vilket ger mig en K-Nearest Neighbor med följande egenskaper: KNeighborsClassifier(algorithm=’auto’, leaf_size=30,
metric=’minkowski’, metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights=’uniform’)
Figur 2: Demonstration av en KNN med K=5[19]
Antag att K-Nearest Neighbor algoritmen lärs upp med datainstanser av två olika klasser och ger den sedan en ny okänd datainstans att klassificera. Har en K=5 angivits kommer algoritmen att titta på de 5 närmaste grannarnas klasser för att avgöra datain-stansens klass, se Figur 2. Algoritmen ser här att två av de närmsta grannarna är av den röda klassen medan tre av de närmaste grannarna är av den blå klassen, vilket resulterar i att den nya datainstansen klassificeras till blå[14].
2.4.3 Decision Tree Classifier
Binära träd är vanligt inom datavetenskapen för att skapa en enkel datastruktur att traver-sera genom. Skapandet och användningen av ett binärt träd är kostnadseffektivt vilket gör det mycket användbart i en implementering av maskininlärning[14][21]. Andra egenskaper som gjort att algoritmer som använder binära träd har blivit populära inom maskinin-lärning är att de är enkla att förstå till skillnad från andra komplexa algoritmer som till exempel neurala nätverk[14]. Inom maskininlärning kallas en sådan implementering för Decision Tree, och i detta fall för Decision Tree Classifier. En Decision Tree Classifier bry-ter ned varje egenskap hos datainstansen till en mängd olika val med sin början i roten, eller root, och traverserar sedan genom trädet till klassificeringen i löven, eller leaf[14]. Jag använde mig av en Decision Tree Classifier som finns tillgänglig i ramverket Scikit Learn. Denna algoritm användes tillsammans med Gini impurity för att mäta kvaliteten av en
delning. En Gini impurity innebär att algoritmen försöker skapa en Decision Tree Classi-fier där varje löv representerar en mängd av datainstanser av samma klass. Detta för att inte skapa några missanpassningar[14]. För att anropa Decision Tree Classifier algoritmen användes följande rad:
dtc = DecisionTreeClassifier(criterion=’gini’)
Vilket resulterar i en Decision Tree Classifier med följande egenskaper: DecisionTreeClassifier(class_weight=None, criterion=’gini’,
max_depth=None,max_features=None, max_leaf_nodes=None, min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter=’best’)
Figur 3: Demonstration av en Decision Tree Classifier[21]
Om målet med ett Decision Tree skulle vara att bestämma vilken skola en person skulle gå på, se Figur 3, kan en möjlig början vara att kontrollera åldern. Är personen över 30 år? Om detta är fallet avgörs om personen redan har en utbildning och bestämmer skola utefter det. Är personen istället under 30 år, kontrolleras kanske någon annan egenskap som kön och bestämmer skola utefter det.
2.5 Datamängder
Jag använde mig av flertalet olika datamängder för att få ut en bred och tillförlitlig data, vilka är beskrivna i följande avsnitt.
2.5.1 Iris
En datamängd av olika sorters blommor av arten Iris. Datamängden skapades av R.A. Fisher 1932 och består av tre klasser med 50 datainstanser av varje klass. Varje datainstans består av fyra värden i form av dimensioner i cm som representerar kronbladens (petal) längd samt bredd och foderbladens (sepal) längd samt bredd, samt ett heltal mellan 0 och 2 för klassificering. Klassen 0, Iris Setosa, är linjärt separerbar från de andra två klasserna, medan klass 1 och 2, Iris Versicolor och Iris Virginica, inte är linjärt separerbara. Då jag
valt att göra en binär klassificering av datan innebär detta att i implementeringen har alla datainstanser med klassificering 0 tagits bort då denna klass är linjärt separerbar från de andra klasserna och därmed enklare att känna igen[28].
Figur 4: Exempel av Iris datamängd[28]. Här ses nio datainstanser av klass 2, Iris Virginica.
2.5.2 Digits
En datamängd med handskrivna siffror. Består av 10 klasser med 250 handskrivna siffror från 44 olika personer. Ur denna kollektion har Scikit Learn valt ut 1797 datainstanser och skapat en egen datamängd speciellt utvecklat för testning av maskininlärning[23]. Varje datainstans består av en 8x8 matris med värden från 0.0 till 16.0 som representerar en gråskala. Detta resulterar i 64 attribut för varje datainstans samt ett värde för kategorise-ringen. I min implementation har jag valt att slå samman klasserna 0-4 samt klasserna 5-9 för att skapa ett scenario där algoritmen får bestämma om den givna datainstansen tillhör siffrorna 0-4 eller 5-9. På så sätt kunde jag skapa ett liknande scenario som i Iris, se 2.5.1, och mina egna symmetriska och dubbelsymmetriska datamängder, se 2.5.3 och 2.5.4, där jag använde mig av en binär klassificering.
Figur 5: Exempel av Digits datamängd[23]. Här ses fyra exempel av datainstanser i Digits datamängd.
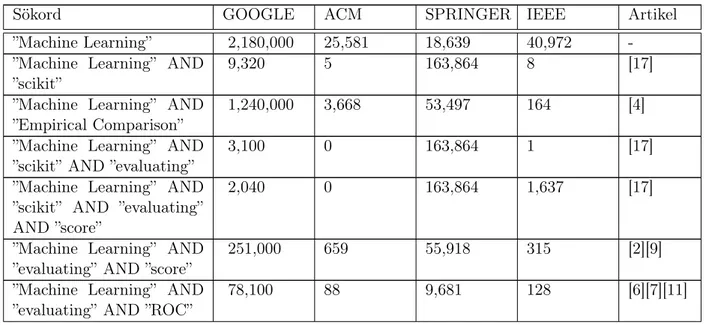
2.5.3 Symmetri
För att utvärdera algoritmerna jag valt ut har jag skapat ett antal datamängder som bygger på symmetri och dubbelsymmetri, se 2.5.4. Den första datamängden består av 1000 symmetriska och 1000 asymmetriska bilder i storleken 6x6 pixlar. Varje datainstans innehåller 36 värden av antingen 0 eller 1, ett värde för varje pixel som bilden består av. I denna datamängd innebär symmetri att den högra halvan av bilden är en spegelbild av den vänstra, se Figur 6. Då det finns 236, alltså 68.719.476.736, möjliga datainstanser av vilka
218, alltså 262.144, är symmetriska valde jag endast ut 1000 slumpmässiga datainstanser
från varje kategori. Jag använde mig även av liknande datamängder som istället består av datainstanser med måtten 8x8 pixlar. Här har jag precis som i det tidigare datamängder använt mig av 1000 symmetriska och 1000 asymetriska bilder. Dessa är symmetriska på samma sätt, nämligen att högra sidan är en spegelbild av den vänstra.
Figur 6: Exempel på en symmetrisk datainstans av formen 8x8
Skapandet av denna datamängd har gjorts programatiskt med Python och koden för detta finns att tillgå i Bilaga A.
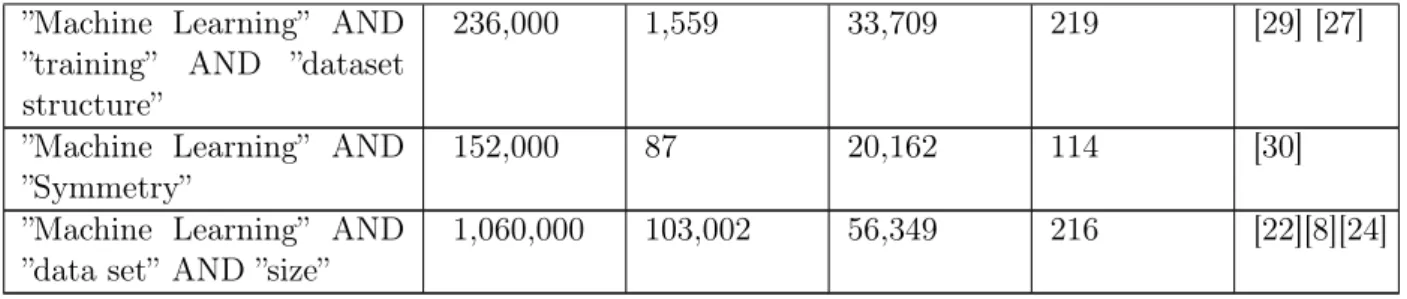
2.5.4 Dubbelsymmetri
Den andra datamängd som jag har skapat är en dubbelsymmetriskt datamängd. Det är precis som tidigare en datamängd bestående av bilder i storleken 6x6 med värden mellan 0 och 1 för varje pixel. I en dubbelsymmetrisk datainstans är den högra sidan en spegelbild av den vänstra samt den undre sidan är en spegelbild av den övre, se Figur 7. Detta ger fortfarande en möjlighet av 236, alltså 68.719.476.736, olika datainstanser, men endast 29, alltså 512, dubbelsymmetriska datainstanser. Detta innebar att jag endast kunde skapa en datamängd med 512 datainstanser i varje klass. Jag har även här gjort en 8x8 variation av datamängden, men i detta fallet med 1000 datainstanser i varje klass då jag här har 218, alltså 262.144, olika möjligheter för dubbelsymmetriska datainstanser.
Figur 7: Exempel på en dubbelsymmetrisk datainstans av formen 8x8
2.6 Utvärdering
2.6.1 Cross-validation
Att träna en algoritm och testa den med samma data ger ett felaktigt prestationsresultat. Detta kan motverkas genom Cross-Validation då detta tränar algoritmen med en viss data och testar den med en annan[16][9][25]. I de flesta scenarion finns det endast ett begränsat antal data att tillgå. Därför delas datan upp i delar, en del för inlärning och resterande för test, se exemplet i Figur 8. På så sätt kan testdatan ses som ”ny data”. Endast en delning skapar en ”validation estimation”, medan fler delningar ger en ”Cross-Validation estimate”[1].
En delning En Hold-out, eller simple validation", består av endast en delning[1]. Som
exempel kan ges en delning av Iris datamängd. Iris består av 150 datainstanser vilket i en Hold-out situation delas i två delar på 75 datainstanser vardera. En del används till inlärning och den andra till test eller validering av algoritmen för att ge en bild av hur bra algoritmen kan identifiera kategorier. Som motsats till detta kan istället algoritmen läras med alla 150 datainstanser utan att veta hur bra algoritmen sedan presterar på vidare datainstanser.
N-delningar En Cross-validation består av fler än en delning av datamängden. Till
skillnad från Hold-out delas datamängden i N delar och och använder sedan en del för testning och resten för inlärning enligt principen LOO (Leave One Out)[1]. Låt oss säga att vi har 100 datainstanser och vill uppskatta träffsäkerheten med hjälp av Cross-Validation med 5 delningar med 20 datainstanser var, se Figur 8. I den första iterationen tränas algoritmen med S2, S3, S4 och S5och testas med S1. Vi får då en träffsäkerhet på 11/20. I
nästa iteration tränas istället algoritmen med S1, S3, S4 och S5 och testas med S2. Detta ger istället en träffsäkerhet på 17/20. På samma sätt utförs testen på varje delning för att få ett sammanställt värde av alla delningar.
Figur 8: Demonstration av Cross-validation[25]
2.6.2 Confusion Matrix
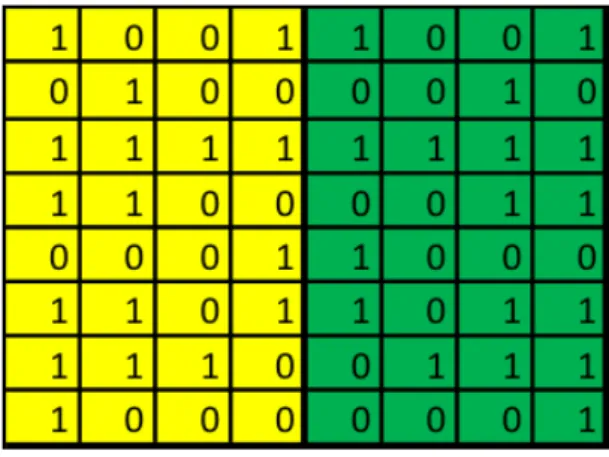
För att räkna ut ROC space, se 2.6.3, använde jag mig av en Confusion Matrix. Vid skapandet av de Confusion Matrix som ingår i detta arbete användes följande metod. Givet en algoritm och en datainstans finns det fyra möjliga resultat, se Figur 9. Om datainstansen är positiv och algoritmen klassificerar den som positiv kallas det för en ”True Positive”, om den däremot blir klassificerad som negativ kallas det en ”False Negative”. Vidare om datainstansen är negativ och algoritmen klassificeras som negativ kallas detta för en ”True Negative” samt om den klassificeras som positiv kallas det för ”False Positive”. Vidare givet en full datamängd kan en två gånger två matris skapas med resultatet av varje datainstans värde och klassifisering där varje instans blir placerad i respektive ruta i matrisen[6].
Figur 9: Definition av Confusion Matrix[6]
2.6.3 ROC
Jag använde mig av metoden Receiver Operating Characteristic space, förkortat ROC spa-ce, för att göra resultaten tydligare. ROC uppstod i samband med analysen av radarbilder
och är en del av ”Signal Detection Theory” som utvecklades under andra världskriget[11]. En ROC space visar hur bra en algoritm presterar tillammans med en visst datamängd. ROC har blivit ett populärt sätt att mäta prestationen på algoritmer inom maskininlär-ning, mycket på grund av den enkelheten att avläsa prestationen visuellt, se Figur 10[6]. För att skapa en ROC space användes en Confusion Matrix, se 2.6.2, för att ta reda på algoritmens True Positive Rate samt False Positive Rate. För att räkna ut dess värden använde jag mig av följande formel:
True Positive Rate = T P
actual pos =
T P T P + F N
False Positive Rate = F P
actual neg =
F P T N + F P
accuracy = T P + T N
T P + F P + F N + T N
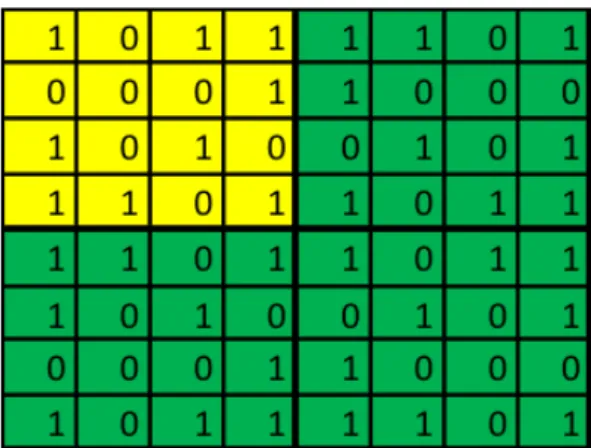
Då ROC ger ett intressantare visuellt resultat än endast accuracy använde jag mig av ett ROC space. För att skapa ett ROC space skapas en graf där True Positive Rate plottas på Y-axeln och False Positive Rate plottas på X-axeln. På demonstrationsbilden, se Figur 10, ses fem punkter markerade. Dessa punkter, A till E, representerar ett resultat av en körning av en lärd algoritm. Det strävas efter ett så lågt False Positive Rate som möjligt, samtidigt som ett så högt True Positive Rate som möjligt. Detta innebär att om ett värde på 0 samt 1, vilket representeras av punkt D i figuren, representerar en perfekt klassifi-cering av alla datainstanser. Detta till skillnad från ett värde på 0,5 samt 0,5 som är ett värde mitt i grafen vilket är en algoritm som endast gissar. Det kan även ses en diagonal streckad linje genom grafen. Den linjen visar var gränsen går för en värdelös algoritm. Ett värde som är enligt E i figuren presterar alltså sämre än en algoritm som väljer kategori slumpmässigt, men detta kan inverteras och göras till det bättre genom att vända på alla svar från algoritmen. Punkten E är i själva verket en spegelbild av punkt B vilket gör dem precis lika effektiva[6].
Figur 10: Demonstration av ROC space[6].
2.6.4 Skew
En utmaning som många utövare av maskininlärning stöter på är att hantera skewed klas-ser i klassificeringsproblem. En skewed klass är en klass som är överrepresenterad i en datamängd[20]. I vårt fall är det en symmetridatamängd där den asymmetriska klassen är överrepresenterad i form av 236 alltså 68.719.476.736 olika möjligheter. Detta mot 218
alltså 262.144 möjligheter för symmetrisk samt 29 alltså 512 möjligheter för
dubbelsym-metrisk när det gäller vår 6x6 datamängd. Detta gör att algoritmen kan gissa på att en ny datainstans är asymmetrisk och nästan alltid ha rätt. Detta problemet löste jag genom att begränsa den specifika klassens representation i datamängden. Skapas en datamängd med lika stor representation bland de olika klasserna kommer algoritmen inte favorisera någon klass och problemet kringgås[20].
2.7 Experiment
För att utvärdera algoritmernas prestationer med de givna datamängderna utfördes flerta-let experiment med hjälp av metoderna beskrivna i föregående avsnitt. Dessa experiment är program skrivna i Python med ramverket Scikit Learn och ett exempel på program som genererats finns att tillgå i Bilaga B. För att göra utvärdering av de olika algoritmernas prestation så kan i Bilaga B ses att en datamängd importerades och sedan delades upp i olika stora delar för att testas mot diverse olika algoritmer. Tio tester kördes för varje algo-ritm respektive datamängd och det genomsnittliga resultatet av dessa körningar utformade den slutgiltiga Confusion Matrix som användes för skapandet av ROC-space diagrammet som återfinns i resultatet.
2.8 Metoddiskussion
Valet att skapa datamängder som bygger på symmetri är ett ytterst personligt val. Sym-metri är ett naturligt förekommande fenomen som finns runt omkring oss i vårt dagliga liv, inte minst i växt och djurriket. Symmetri tilltalar oss människor då detta är någonting som ligger i vår natur. Någonting som är intressant för mig är om detta fenomen är lika enkelt för en maskininlärningsalgoritm att upptäcka som för en människa. Därför skapades en datamängd som bygger på symmetri, men även en datamängd som bygger på dubbel-symmetri för att identifiera om detta har någon påverkan på inlärningsförmågan. Det kan inte lika enkelt ses hur strukturen påverkar inlärningsförmågan i datamängderna Iris och Digits då de är så olika varandra i struktur. Därför skapades det symmetriska och dubbel-symmetriska datamängderna för att underlätta undersökningen av strukturens påverkan. Dessa två datamängder kommer att ge en bild av hur strukturen påverkar inlärningen och därmed den prediktiva precisionen. I litteraturstudien kunde jag inte finna någon referens som använde sig av symmetri för att utvärdera skillnader i den prediktiva precisionen be-roende på datamängdernas struktur. Detta gör att jag inte kan sätta resultaten av min studie i relation till någon tidigare forskning. Den valda metoden att öka inlärningsmäng-den successivt och köra experiment på dessa visade sig vara mycket effektivt. Från början hade jag ingen uppfattning om vad resultatet av min studie skulle bli. Att sammanfatta resultaten i CM och analysera dem senare med grafer av ROC-space var mycket praktiskt och visade sig ge väldigt tydliga resultat. Jag prövade mig fram med olika träningsmäng-der, algoritmer och datamängder innan jag kunde fastställa vilken metod som skulle passa mig bäst. En alternativ metod hade kunnat vara att använda sig av andra algoritmer och andra datamängder. Med tanke på den tidigare forskning om hur mängden inlärningsdata påverkar algoritmens prestation hade ett alternativ varit att använda sig av ännu större datamängder för ett generaliserbart resultat av större datamängder. Det kanske även ger ytterligare insikter i hur inlärningsmängden påverkar algoritmens effektivitet.
3
Resultat
Resultatet sammanställdes i en Confusion Matrix varpå det fördes in i en ROC space. Ett exempel på en Confusion Matrix som användes kan ses i Figur 11. Figuren visar resultatet av experimenten på 6x6 symmetriska datamängd med algoritmen K-Nearest Neighbor.
Figur 11: Confusion Matrix av resultatet för K-Nearest Neighbor på 6x6 symmetri data-mängd och input data till ROC space.
3.1 Symmetriskt datamängd
Resultaten av försöken på de två symmetriska datamängderna presenteras i två grafer med ROC space, se Figur 12 och 13. Algoritmerna K-Nearest Neighbor, gul markering, Decision Tree Classifier, röd markering samt Support Vector Classification, blå markering. Siffrorna 50 respektive 500 visar mängden inlärningsdata för de givna resultaten.
Figur 12: ROC space på 6x6 symmetriskt datamängd
Resultatet av experimenten med det 6x6 symmetriska datamängden illustreras i Figur 12. Vi kan konstatera att Support Vector Classifier med endast 50 inlärningsinstanser ger ett resultat av 0.50 i True Positive Rate samt 0.50 i False Positive Rate. Vi kan också se att vid 500 inlärningsinstanser så ökar True Positive Rate drastiskt till 1.0 och False Positive Rate sjunker något till 0.42. Skillnaden i precisionen mellan 50 och 500 inlärningsinstanser är betydligt större för Support Vector Classifier jämfört med de andra algoritmerna. För K-Nearest Neighbor och Decision Tree Classifier är skillnaden mellan de två inlärnings-mängderna inte lika stor men resulterar däremot i högre True Positive Rates och lägre False Positive Rates. Den algoritm som resulterar i högst True Positive Rate respektive lägst False Positive Rate är Decision Tree Classifier med 500 inlärningsinstanser.
Figur 13: ROC space på 8x8 symmetriskt datamängd
I Figur 13 ser vi resultatet av experiment utförda på det 8x8 symmetriska datamängden. Resultatet visar är att en inlärningsmängd på 50 för Support Vector Classifier ger en True Positive Rate på 0.51 och en False Positive Rate på 0.50. Skillnaden är inte särskilt stor för 500 inlärningsinstanser där vi kan se ett resultat på 0.69 i True Positive Rate och 0.45 i False Positive Rate. Vidare är skillnaden mellan inlärningsmängderna betydligt större för de två andra algoritmer med det högsta True Positive Rate respektive det lägsta False Positive Rate för Decision Tree Classifier med 500 inlärningsinstanser.
3.2 Dubbelsymmetriskt datamängd
Experimenten på de symmetriska datamängderna upprepades på de två dubbelsymmetriska datamängderna och resultaten är sammanställda i två grafer med ROC space, se Figur 14 och 15. För de dubbelsymmetriska datamängderna representeras algoritmerna K-Nearest Neighbor av gul markering, Decision Tree Classifier av röd markering samt Support Vector Classification av blå markering. Siffrorna 25 och 256 respektive 50 och 500 visar mängden inlärningsdata för de givna resultaten.
Figur 14: ROC space på 6x6 dubbelsymmetriskt datamängd
Resultatet av experimentet på det 6x6 dubbelsymmetriska datamängden är samman-ställt i Figur 14. Det som ska noteras här är att till skillnad från Figur 12, 13 och 15 som har inlärningsmängder på 50 och 500 så är inlärningsmängder här istället 25 och 256, se avsnitt 2.5.4 för förklaring. Det vi kan se är att Support Vector Classifier med 25 inlärnings-instanser ligger vid 0.52 i True Positive Rate samt 0.49 i False Positive Rate. Decision Tree Classifier samt K-Nearest Neighbor ligger aningen högre i True Positive Rate på 0.65 och 0.75 samt lägre i False Positive Rate på 0.33 och 0.41. Vidare kan vi se att alla algoritmer sänker False Positive Rate vid 256 inlärningsinstanser samt höjer True Positive Rate till 1.00.
I Figur 15 presenteras resultatet av experiment på det 8x8 dubbelsymmetriskt data-mängden. Resultatet för Support Vector Classifier vid 50 inlärningsinstanser ligger på 0.51 i True Positive Rate och 0.49 i False Positive Rate, medan K-Nearest Neighbor ligger på 0.90 och 0.38 samt Decision Tree Classifier ligger på 0.66 och 0.20. Vidare ses att med ökad inlärningsmängd till 500 stiger även True Positive Rate på samtliga algoritmer till 1.00 medan False Positive Rate sjunker en aning.
3.3 Iris datamängd
Den kända Iris datamängd av R.A. Fisher finns tillgängligt i Scikit Learn och är en av de datamängder som ingår i denna studie. Jag tog bort klass 0 (Iris Setosa) då denna klass är linjärt separerbar från de andra två, se 2.5.1, och använde mig enbart av klass 1 och 2 (Iris versicolor samt Iris Virginica). Resultaten av experimenten sammanställdes i en graf med ROC space, se Figur 16. För Iris datamängd representeras algoritmerna K-Nearest Neighbor av gul markering, Decision Tree Classifier av röd markering samt Support Vector Classification av blå markering. Siffrorna 5, 10 samt 20 visar mängden inlärningsdata som använts för det givna resultatet.
Figur 16: ROC space på Iris datamängd
Resultaten av experimenten gjorda på Iris datamängd presenteras i Figur 16. Här kan vi observera en punkt långt ifrån de andra nämligen K-Nearest Neighbor med en inlärning på 5 instanser. Den ligger på 0.00 i True Positive Rate och 0.51 i False Positive Rate. De andra punkterna för K-Nearest Neighbor ligger på 0.88 och 0.28 för 10 inlärningsinstanser samt 0.97 och 0.10 för 20 inlärningsinstanser. För Support Vector Classifier ligger resultaten av 5 inlärningsinstanser på 0.87 och 0.34. Vidare ligger punkten för 10 inlärningsinstanser på 0.95 och 0.15 samt för 20 inlärningsinstanser på 0.96 och 0.05. För Decision Tree Classifier ligger resultaten av 5 inlärningsinstanser på 0.76 i True Positive Rate och 0.34 i False Positive Rate. Vidare ligger punkten för 10 inlärningsinstanser på 0.93 och 0.13 samt för 20 instanser på 0.97 och 0.11.
3.4 Digits datamängd
Resultaten från experimenten utförda på Digits datamängd demonstreras i grafer med ROC space, se Figur 17, samt en kurva som visar hur True Positive Rate relaterar till False Positive Rate beroende på inlärningsmängd, se Figur 18. Siffrorna 18 till 900 visar de steg av inlärningsmängd som använts för att få det givna resultatet.
Figur 17: ROC space på Digits datamängd
I Figur 17 kan vi se att Decision Tree Classifier med 18 inlärningsinstanser ligger på 0.55 True Positive Rate samt 0.44 False Positive Rate. Vidare för 900 inlärningsinstanser ligger resultatet för True Positive Rate på 0.99 och False Positive Rate på 0.11. För K-Nearest Neighbor ligger resultatet av 18 inlärningsinstanser på 0.56 i True Positive Rate samt 0.38 i Flase Positive Rate. För 900 i mängden inlärningsinstanser ligger True Posi-tive Rate på 0.99 och False PosiPosi-tive Rate på 0.02. Support Vector Classifier ligger för 18 inlärningsinstanser på 0.72 i True Positive Rate samt 0.26 i False Positive Rate, medan för 900 inlärningsinstanser ligger True Positive Rate på 0.99 och False Positive Rate på 0.01.
Figur 18: Graf över TPR och FPR beroende på mängden inlärningsdata
Det vi kan se i Figur 18 är en annan typ av graf för resultaten av experimenten av datamängden Digits. Det kan ses i denna grafen är mängden inlärningsinstanser på X-axeln samt ett värde 0-1 på Y-X-axeln som representerar värdet givet av True Positive Rate samt False Positive Rate. Vid 18 inlärningsinstanser ligger Decision Tree Classifier på 0.55 i True Positive Rate och 0.44 i False Positive Rate, vilket ses öka respektive sjunka i värde beroende på antalet inlärningsinstanser. Detta är gemensamt för samtliga algoritmer.
4
Analys
4.1 Mängden inlärningsdata
Man kan tydligt se på resultaten att mängden inlärningsdata har stor betydelse för al-goritmens prestation i att kategorisera nya datainstanser. I det här avsnittet analyserar jag de olika resultaten jag fått på mina egengjorda symmetriska och dubbelsymmetriska datamängder, min binära implementation av Iris datamängden, samt min implementation av Digits datamängd och jämför mina resultat med de från tidigare forskning.
4.1.1 Symmetri och Dubbelsymmetri
De fyra grafer som formar resultaten av mina experiment visar att mängden inlärningsdata definitivt påverkar prestationen av algoritmen. Den första grafen, se Figur 12, visar att alla tre algoritmer får ett bättre resultat vid den högre inlärningsmängden. K-Nearest Neighbor samt Decision Tree Classifier visar båda en kraftig ökning i True Positive Rate samt en minskning i False Positive Rate vilket resulterar i en bättre position i ROC space. Support Vector Classifier är extremt dålig vid endast 50 datainstanser av inlärning, men däremot vid 500 datainstanser inlärning ses tydlig förbättring och prestationen har ökat till en perfekt True Positive Rate samt minskat sin False Positive Rate något.
Liknande resultat ses i nästa graf, se Figur 13. Här lär sig K-Nearest Neighbor och Decision Tree Classifier bättre vid den högre inlärningsmängden. Det som är intressant att se här är att Support Vector Classifier inte presterar lika bra vid 500 datainstanser inlärning som vid vår tidigare datamängd på 6x6. Här förbättras endast True Positive Rate en aning till skillnad från tidigare.
Vidare i den första grafen av den dubbelsymmetriska datamängden, se Figur 14, ses lik-som tidigare en dålig prestation av Support Vector Classifier, och lite bättre av K-Nearest Neighbor och Decision Tree Classifier vid 25 datainstanser inlärning. Den dubbelsymmet-riska datan ger däremot ett väldigt bra resultat vid inlärning av 256 datainstanser då alla algoritmer får en mycket bra True Positive Rate. Risken att detta beror på den lilla mängd av 6x6 dubbelsymmetriska möjligheter som finns och att algoritmen enkelt kan gissa sig fram till rätt svar har jag eliminerat genom skewed, se 2.6.4. Dessutom ses samma re-sultat i nästkommande graf, se Figur 15. Där ses liknande rere-sultat vid inlärning av 500 datainstanser, och i det 8x8 datamängden finns det 216möjligheter till dubbelsymmetriska datainstanser.
4.1.2 Iris
Iris-datamängden visar tydligt hur inlärningsmängd påverkar en prestationen av en algo-ritm, se Figur 16. Samtliga algoritmer får en högre True Positive Rate samt en lägre False Positive Rate vid ökad inlärningsmängd. Det kan bland annat ses att K-Nearest Neighbor inte klarade av ett enda ”True Positive” vid endast 5 i inlärningsmängd. Däremot klarar Support Vector Classifier och Decision Tree Classifier jobbet oväntat bra på endast 5 da-tainstanser av inlärning. Överlag presterar alla algoritmer bättre ju fler inlärningsdata de får.
4.1.3 Digits
Där det tydligast kan ses hur inlärningsmängd påverkar prestationen av en algoritm är i resultaten från Digits datset, se Figur 17. Här har jag gjort omfattande tester och kört experiment med 10 olika mängder inlärningsdata. Det kan tydligt ses att alla algoritmer ökar i prestation beroende på mängden inlärningsdata.
Vidare kan ses i Figur 18 en graf över hur False Positive Rate, blå markering för Support Vector Classifier, orange markering för K-Nearest Neighbor samt gul markering för Decision Tree Classifier, samt True Positive Rate, grön markering för Support Vector Classifier, grå markering för K-Nearest Neighbor samt röd markering för Decision Tree Classifier, påverkas av inlärningsmängden. Ju fler datainstanser inlärningsalgoritmen får desto bättre presterar den i True Positive Rate samt False Positive Rate. Den här grafen visar även att mängden inlärningsdata spelar roll upp till ca 360 datainstanser för Support Vector Classifier samt K-Nearest Neighbor. Decision Tree Classifier fortsätter förbättra sin prestation ända upp till sista steget av 900 datainstanser inlärning. De två andra algoritmerna visar på att fler än 360 datainstanser som inlärning inte påverkar algoritmens prestation avsevärt. Vad vi inte kan se i den här grafen är hur algoritmerna hade presterat vid ännu högra inlärningsmängder, det vill säga vid 900+ datainstanser. Det som kan ses i tidigare forskning är att SVM tenderar till att prestera sämre vid större mängder inlärningsdata[8][22][24]. Detta har jag ännu inte uppnått i de här experimenten, vilket
kan bero på de i relation små datamängder som använts där tidigare forskning använt större datamängder än de 2000 jag använt mig av.
4.2 Datamängdens struktur
Samtliga algoritmer presterade bättre när de lärdes upp med en dubbelsymetriskt data-mängd jämfört med en symetriskt datadata-mängd. Jämförs resultatet från den dubbelsym-metriska datan, se Figur 15, med resultatet från den symdubbelsym-metriska datan, se Figur 13, blir det tydligt att alla algoritmer presterar bättre överlag på den dubbelsymmetriska datan då alla punkter i grafen ligger längre åt det vänstra övre hörnet. Det kan även ses att strukturen på datan spelar roll när inlärningsmängden av 500 datainstanser jämförs för de båda datamängderna. Den dubbelsymmetriska datan resulterar i väldigt bra träffsäkerhet samtidigt som den symmetriska presterar bra, men inte lika bra som den dubbelsymmet-riska. Detta bekräftas i de två andra graferna, se Figur 14 och 12, där samma mönster ses trots att inlärningen på vår 6x6 dubbelsymmetriska datamängd endast är 25 respektive 256 datainstanser jämfört med 50 samt 500 på det symmetriska.
5
Diskussion
Som beskrivet i Analysen, se avsnitt 4, presterar algoritmerna olika bra beroende på typ av datamängd och inlärningsmängder. Detta grundar sig i algoritmernas uppbyggnad och funktion, som beskrivs i Metoddelen, se avsnitt 2, och diskuteras ytterligare i detta avsnitt.
5.1 Support Vector Classifier
Vid analysen av det symmetriska 6x6 datamängden framgår att Support Vector Classifi-er är extremt dålig vid endast 50 datainstansClassifi-er av inlärning, vilket troligen bClassifi-eror på att algoritmen inte har hittat en korrekt linje att gå efter, se 2.4.1. Detta mönster uppre-pas i resultaten av alla de symmetriska och dubbelsymmetriska datamängderna. Detta är någonting som är specifikt för en Support Vector Classifier då den måste hitta en korrekt delning av klasserna för att kunna göra en korrekt klassificering av nya datainstanser. Har algoritmen träffat fel i sin initiala delning av klasserna kommer klassificeringen inte att fungera som det är tänkt. Detta är en tydlig demonstration av för lite inlärningsdata att skapa avgränsning på.
5.2 K-Nearest Neighbor
Inlärningsmängden påverkade speciellt K-Nearest Neighbor prestation när den skulle arbe-ta med daarbe-tamängden Iris, se 16. När algoritmen endast fick 5 daarbe-tainsarbe-tanser att lära sig med samtidigt som en K=5 användes gjorde detta att algoritmen kollade på all den inlärnings-datan som den fått när den skulle klassificera varje ny datainstans, se 2.4.2. Detta i sin tur ledde till en felaktig klassificering av alla datan. Algoritmen valde att alltid klassificera en ny datainstans av samma kategori då de fem närmaste grannarna var överrepresente-rade av just den kategorin. Som exempel kan vi säga att algoritmen fick två datainstanser av kategorin 0 och tre datainstanser av kategorin 1 som inlärning. När det kom en ny datainstans för klassificering analyserades alla de inlärda datainstanserna och algoritmen
såg hela tiden att tre av de fem närmaste grannarna var av kategori 1 och antog därför hela tiden att den nya datan var av den kategorin. Lösningen för detta är att tillföra fler inlärningsdata eller sänka antalet grannar som algoritmen tittar på.
5.3 Decision Tree Classifier
Algoritmen som klart presterade bäst vid de symmetriska och dubbelsymmetriska data-mängderna är Decision Tree Classifier. Anledningen till detta är troligen strukturen på datamängderna och hur Decision Tree Classifier algoritmen fungerar. En Decision Tree Classifier bryter ned varje egenskap i datainstansen till en mängd olika val och traverserar igenom dessa när en ny instans ges, se 2.4.3. Att se hur algoritmen har utfört varje klassi-ficering och skapat sitt träd är utom detta arbete, men ett antagande som kan göras är att algoritmen för varje egenskap i datainstansen studerat de efterföljande egenskaperna och på så sätt haft enklare att finna det symmetriska mönstret i datamängden. Som exempel kan ges första egenskapen hos en datainstans. Om egenskapen är en etta, är nästkomman-de tre egenskaper också ettor? Om så är fallet är möjligheten större att nästkomman-det inte är en asymetrisk datainstans och vidare traversering utförs.
5.4 Tidigare forskning
Enligt den tidigare forskning som tagits upp i avsnitt 1.6 visar flera studier på att precisio-nen för en SVM sjunker i takt med att inlärningsmängden ökar. Detta är någonting som inte kunnat återskapas för detta arbete, vilket kan bero på att den mängd inlärningsdata som krävs inte kunnat uppnås. Vad man istället kan jämföra är algoritmernas stigning i prestation upp till den största datamängd som användes i detta arbete vilket var 2000 datainstanser. Det vi bland annat kan se är för Schohn och Cohn där deras resultat för ”earn” och ”acquisitions” märkta datainstanser efter 2000 inlärningsdata börjar ge sämre resultat[22]. Det vi kan se i våra resultat i Figur 18 är att en mycket högre precision nås vid våra tester än vad Schohn och Cohn fått ur sina försök med de datainstanserna. Re-sultaten de får för de markerade med ”baseball” och ”cryptography” är lika bra som de resultat som visats i detta arbete, men har inte lika många inlärningsdata som de tidigare nämnda markeringar.
6
Slutsatser och vidare forskning
Denna studie visar tydligt att mängden inlärningsdata markant påverkar algoritmernas prestation. Ju mer inlärningsdata desto bättre prestation av samtliga algoritmer upp till en viss mängd. Det som bör hållas i åtanke är att mina tester endast utförts på data-mängder mindre än 2000 datainstanser vilket gör att slutsatsen inte är generaliserbar för större mängder. Däremot visar resultaten att alla algoritmer presterade liknande resultat för de datamängder som givits vilket gör slutsatsen generaliserbar för andra algoritmer med samma datamängder. Studien visar också att strukturen på datainstanserna påverkar inlärningsförmågan för samtliga algoritmer, där de alla presterar bättre med en dubbel-symmetriskt datamängd jämfört med en dubbel-symmetriskt datamängd.
I resultaten ser man att algoritmerna är olika bra på olika datamängder. Detta gör att det inte enkelt går att avgöra vilken algoritm som ska användas vid en ny datamängd.
Man bör därför vid en implementering av en Maskininlärningsapplikation först testa olika algoritmer med förslagsvis Scikit Learn och mäta inlärningsförmågan med en ROC space. Vidare forskning kan göras på var dessa mängdgränser går och om strukturen på datan påverkar dessa gränser. Det kan också vara intressant att undersöka om resultaten av andra algoritmer är de samma som för dessa algoritmer samt utföra ytterligare tester med andra datamängder som finns tillgängliga. Det kan även vara av intresse att utföra samma eller liknande tester med andra mätinstrument så som ROC kurvor och AUC för att se om dessa mätinstrument ger annorlunda resultat.
Slutligen vill jag återge några av mina erfarenheter kring Scikit Learn. Detta bibliotek har underlättat forskningen avsevärt. Det är relativt enkelt att använda och kräver inte särskilt mycket förkunskaper inom Python, men grundläggande kunskaper krävs. Inför vidare forskning inom området rekommenderar jag att använda detta bibliotek då det är anpassningsbart för olika angreppsmetoder som kan tänkas användas i forskningen.
Figurer
1 Demonstration av en SVM[14] . . . 9
2 Demonstration av en KNN med K=5[19] . . . 10
3 Demonstration av en Decision Tree Classifier[21] . . . 11
4 Exempel av Iris datamängd[28]. Här ses nio datainstanser av klass 2, Iris Virginica. . . 12
5 Exempel av Digits datamängd[23]. Här ses fyra exempel av datainstanser i Digits datamängd. . . 12
6 Exempel på en symmetrisk datainstans av formen 8x8 . . . 13
7 Exempel på en dubbelsymmetrisk datainstans av formen 8x8 . . . 14
8 Demonstration av Cross-validation[25] . . . 15
9 Definition av Confusion Matrix[6] . . . 15
10 Demonstration av ROC space[6]. . . 17
11 Confusion Matrix av resultatet för K-Nearest Neighbor på 6x6 symmetri datamängd och input data till ROC space. . . 18
12 ROC space på 6x6 symmetriskt datamängd . . . 19
13 ROC space på 8x8 symmetriskt datamängd . . . 20
14 ROC space på 6x6 dubbelsymmetriskt datamängd . . . 21
15 ROC space på 8x8 dubbelsymmetriskt datamängd . . . 21
16 ROC space på Iris datamängd . . . 22
17 ROC space på Digits datamängd . . . 23
Referenser
[1] Arlot, Sylvain, and Alain Celisse. ”A survey of cross-validation procedures for model selection.” Statistics surveys 4 (2010): 40-79.
[2] Bishop, Christopher M. Pattern recognition. Machine Learning 128 (2006): 1-58. [3] Carbonell, Jaime G., Ryszard S. Michalski, and Tom M. Mitchell. ”An overview of
Machine Learning.” Machine Learning. Springer Berlin Heidelberg, 1983. 3-23. [4] Caruana, Rich, and Alexandru Niculescu-Mizil. An empirical comparison of
supervi-sed Learning algorithms. Proceedings of the 23rd international conference on Machine Learning. ACM, 2006.
[5] Chang, Chih-Chung, and Chih-Jen Lin. ”LIBSVM: a library for support vector Machi-nes.” ACM Transactions on Intelligent Systems and Technology (TIST) 2.3 (2011): 27.
[6] Fawcett, Tom. ”An introduction to ROC analysis.” Pattern recognition letters 27.8 (2006): 861-874.
[7] Ferri, César, Peter Flach, and José Hernández-Orallo. ”Learning decision trees using the area under the ROC curve.” ICML. Vol. 2. 2002.
[8] Forman, George, and Ira Cohen. ”Learning from little: Comparison of classifiers given little training.” Knowledge Discovery in Databases: PKDD 2004 (2004): 161-172. [9] Geisser, Seymour. ”The predictive sample reuse method with applications.” Journal
of the American Statistical Association 70.350 (1975): 320-328.
[10] GOLDBERG, David E.; HOLLAND, John H. Genetic algorithms and Machine Le-arning. Machine Learning, 1988, 3.2: 95-99.
[11] Hanley, James A., and Barbara J. McNeil. ”The meaning and use of the area under a receiver operating characteristic (ROC) curve.” Radiology 143.1 (1982): 29-36. [12] Huang, Gong, and Wang Man. ”Learning curve: principle, application and limitation.”
E-Business and E-Government (ICEE), 2010 International Conference on. IEEE, 2010.
[13] Kalmár, Marcus, and Joel Nilsson. ”The art of forecasting–an analysis of predictive precision of Machine Learning models.” (2016).
[14] Marsland, Stephen. Machine Learning: an algorithmic perspective. CRC press, 2015. [15] McCarthy, John, et al. ”A proposal for the dartmouth summer research project on
artificial intelligence, august 31, 1955.” AI magazine 27.4 (2006): 12.
[16] Mosteller, Frederick, and John W. Tukey. ”Data analysis, including statistics.” Hand-book of social psychology 2 (1968): 80-203.
[17] Pedregosa, Fabian, et al. Scikit-learn: Machine Learning in Python. Journal of Machi-ne Learning Research, 12.Oct (2011): 2825-2830.
[18] Perlich, Claudia, Foster Provost, and Jeffrey S. Simonoff. Tree induction vs. logistic regression: A Learning-curve analysis. Journal of Machine Learning Research 4.Jun (2003): 211-255.
[19] Peterson, Leif E. ”K-nearest neighbor.” Scholarpedia 4.2 (2009): 1883.
[20] Provost, Foster. ”Machine Learning from imbalanced data sets 101.” Proceedings of the AAAI’2000 workshop on imbalanced data sets. 2000.
[21] Ranka, Sanjay, and V. Singh. ”CLOUDS: A decision Tree classifier for large datasets.” Proceedings of the 4th Knowledge Discovery and Data Mining Conference. 1998. [22] Schohn, Greg, and David Cohn. ”Less is more: Active learning with support vector
machines.” ICML. 2000.
[23] Scikit Learn. ”The Digit Dataset”. scikit-learn.org. [Online]. Tillgänglig:
http://scikit-learn.org/stable/auto_examples/datasets/plot_digits_last_image.html [Hämtad 2017-03-25].
[24] Shalev-Shwartz, Shai, and Nathan Srebro. ”SVM optimization: inverse dependence on training set size.” Proceedings of the 25th international conference on Machine learning. ACM, 2008.
[25] Stone, Mervyn. ”Cross-validatory choice and assessment of statistical predictions.” Journal of the royal statistical society. Series B (Methodological) (1974): 111-147. [26] Thomas G. Tape, MD. ”The area under an ROC curve”. gim.unmc.edu. [Online].
Tillgänglig:
http://gim.unmc.edu/dxtests/ROC3.htm [Hämtad 2017-04-04].
[27] Trigueiros, Paulo, Fernando Ribeiro, and Luis Paulo Reis. ”A comparison of machine learning algorithms applied to hand gesture recognition.” Information Systems and Technologies (CISTI), 2012 7th Iberian Conference on. IEEE, 2012.
[28] UCI Machine Learning Repository. ”Iris Data Set”. archive.ics.uci.edu. [Online]. Till-gänglig:
https://archive.ics.uci.edu/ml/datasets/Iris [Hämtad 2017-03-15].
[29] Wang, Defeng, and Lin Shi. ”Selecting valuable training samples for SVMs via data structure analysis.” Neurocomputing 71.13 (2008): 2772-2781.
[30] Wu, Jia, et al. ”Learning to compute the plane of symmetry for human faces.” Pro-ceedings of the 2nd ACM Conference on Bioinformatics, Computational Biology and Biomedicine. ACM, 2011.
[31] Yelle, Louis E. ”The learning curve: Historical review and comprehensive survey.” Decision sciences 10.2 (1979): 302-328.
A
Bilaga, Skapandet av dataset
1 i m p o r t c s v 2 i m p o r t numpy a s np 3 i m p o r t i t e r t o o l s 4 i m p o r t random 5 6 d a t a = " " 7 s e q = i t e r t o o l s . p r o d u c t (" 01 ", r e p e a t =16) 8 f = open(’ dubblesym8x8 . c s v ’, ’w ’) 9 10 s t r i n g s a r r = [ ] 11 c o u n t e r = 0 12 f o r i i n s e q : 13 a r r = np . f r o m i t e r ( i , np . i n t 8 ) . r e s h a p e ( 4 , 4 ) 14 s t r i n g s = " " 15 one = random . g e t r a n d b i t s ( 1 ) 16 two = random . g e t r a n d b i t s ( 1 ) 17 t h r e e = random . g e t r a n d b i t s ( 1 ) 18 f o u r = random . g e t r a n d b i t s ( 1 ) 19 f i v e = random . g e t r a n d b i t s ( 1 ) 20 s i x = random . g e t r a n d b i t s ( 1 ) 21 s e v e n = random . g e t r a n d b i t s ( 1 ) 22 e i g h t = random . g e t r a n d b i t s ( 1 ) 23 n i n e = random . g e t r a n d b i t s ( 1 ) 24 t e n = random . g e t r a n d b i t s ( 1 ) 25 e l e v e n = random . g e t r a n d b i t s ( 1 ) 26 t w e l v e = random . g e t r a n d b i t s ( 1 ) 27 t h i r t e e n = random . g e t r a n d b i t s ( 1 ) 28 f o u r t e e n = random . g e t r a n d b i t s ( 1 ) 29 f i f t h e e n = random . g e t r a n d b i t s ( 1 ) 30 s i x t e e n = random . g e t r a n d b i t s ( 1 ) 31 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( one , two , t h r e e , f o u r , f o u r , t h r e e , two , one ) 32 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( f i v e , s i x , s e v e n , e i g h t , e i g h t , s e v e n , s i x , f i v e ) 33 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( n i n e , ten , e l e v e n , t w e l v e , t w e l v e , e l e v e n , ten , n i n e ) 34 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( t h i r t e e n , f o u r t e e n , f i f t h e e n , s i x t e e n , s i x t e e n , f i f t h e e n , f o u r t e e n , t h i r t e e n ) 35 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( t h i r t e e n , f o u r t e e n , f i f t h e e n , s i x t e e n , s i x t e e n , f i f t h e e n , f o u r t e e n , t h i r t e e n ) 36 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( n i n e , ten , e l e v e n , t w e l v e , t w e l v e , e l e v e n , ten , n i n e ) 37 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( f i v e , s i x , s e v e n , e i g h t , e i g h t , s e v e n , s i x , f i v e ) 38 s t r i n g s += "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % ( one , two , t h r e e , f o u r , f o u r , t h r e e , two , one ) 39 s t r i n g s += " 1 " 40 s t r i n g s a r r . append ( s t r i n g s ) 41 c o u n t e r += 1 42 i f c o u n t e r == 1 0 0 0 : 43 b r e a k 44 random . s h u f f l e ( s t r i n g s a r r ) 45 f o r i i n s t r i n g s a r r : 46 f . w r i t e ( i + " \n")47 48 s e q 2 = i t e r t o o l s . p r o d u c t (" 01 ", r e p e a t =32) 49 c = 0 50 f o r i i n s e q 2 : 51 a r r = np . f r o m i t e r ( i , np . i n t 8 ) . r e s h a p e ( 8 , 4 ) 52 s t r i n g s = " " 53 f o r j i n a r r : 54 one = random . g e t r a n d b i t s ( 1 ) 55 two = random . g e t r a n d b i t s ( 1 ) 56 t h r e e = random . g e t r a n d b i t s ( 1 ) 57 f o u r = random . g e t r a n d b i t s ( 1 ) 58 f i v e = random . g e t r a n d b i t s ( 1 ) 59 s i x = random . g e t r a n d b i t s ( 1 ) 60 s e v e n = random . g e t r a n d b i t s ( 1 ) 61 e i g h t = random . g e t r a n d b i t s ( 1 )
62 temp = "%s ,% s ,% s ,% s ,% s ,% s ,% s ,% s , " % (s t r( one ) , s t r( two ) , s t r( t h r e e ) ,
s t r( f o u r ) , s t r( f i v e ) , s t r( s i x ) , s t r( s e v e n ) , s t r( e i g h t ) ) 63 s t r i n g s += temp 64 temp = " " 65 s t r i n g s += " 0 " 66 f . w r i t e ( s t r i n g s + " \n") 67 c += 1 68 i f c == 1 0 0 0 : 69 b r e a k 70 f . c l o s e ( )
![Figur 1: Demonstration av en SVM[14]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/17.892.195.703.206.613/figur-demonstration-av-en-svm.webp)
![Figur 2: Demonstration av en KNN med K=5[19]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/18.892.245.646.356.673/figur-demonstration-av-en-knn-med-k.webp)
![Figur 3: Demonstration av en Decision Tree Classifier[21]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/19.892.261.640.510.705/figur-demonstration-av-en-decision-tree-classifier.webp)
![Figur 5: Exempel av Digits datamängd[23]. Här ses fyra exempel av datainstanser i Digits datamängd.](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/20.892.260.643.931.1041/figur-exempel-digits-datamängd-exempel-datainstanser-digits-datamängd.webp)
![Figur 8: Demonstration av Cross-validation[25] 2.6.2 Confusion Matrix](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/23.892.166.718.222.423/figur-demonstration-av-cross-validation-confusion-matrix.webp)
![Figur 10: Demonstration av ROC space[6]. 2.6.4 Skew](https://thumb-eu.123doks.com/thumbv2/5dokorg/4000612.80100/25.892.291.602.217.530/figur-demonstration-av-roc-space-skew.webp)
