An Ensemble Recommender System for e-Commerce
Bj¨orn Brod´en bjorn.broden@apptus.com
Apptus Technologies, Trollebergsv¨agen 5, SE-222 29 Lund, Sweden
Mikael Hammar mikael.hammar@apptus.com
Apptus Technologies, Trollebergsv¨agen 5, SE-222 29 Lund, Sweden
Bengt J. Nilsson bengt.nilsson.TS@mah.se
Dept. of Computer Science, Malm¨o University, SE-205 06 Malm¨o, Sweden
Dimitris Paraschakis dimitris.paraschakis@mah.se
Dept. of Computer Science, Malm¨o University, SE-205 06 Malm¨o, Sweden
Keywords: recommender systems, ensemble learning, thompson sampling, e-commerce, priming
Abstract
In our ongoing work we extend the Thompson Sampling (TS) bandit policy for orchestrat-ing the collection of base recommendation al-gorithms for e-Commerce. We focus on the problem of item-to-item recommendations, for which multiple behavioral and content-based predictors are provided to an ensemble learner. The extended TS-based policy must be able to handle situations when bandit arms are non-stationary and non-answering. Furthermore, we investigate the effects of priming the sampler with pre-set parame-ters of reward distributions by analyzing the product catalog and/or event history, when such information is available. We report our preliminary results based on the analysis of two real-world e-Commerce datasets.
1. Introduction
A typical task in industrial e-Commerce applications is generating top-N item-to-item recommendations in a non-personalized fashion. Such recommendations are useful in “cold-start” situations when user pro-files are very limited or non-existent, for example on landing pages. Even in this case, the cold-start prob-lem manifests itself as a challenge of selecting items that are relevant to a given item. A natural way of
Preliminary work. Under review for Benelearn 2017. Do not distribute.
tackling this issue is by following the “exploration-exploitation” paradigm of multi-arm bandits (MAB). These algorithms use reinforcement learning to opti-mize decision making in the face of uncertainty. An-other established way of addressing the initial lack of data is to utilize content-based filtering, which recom-mends items based on their attributes. The efficacy of these two approaches along with the fact that many real-world recommenders tend to favor simple algorith-mic approaches (Paraschakis et al., 2015), motivates the creation of an ensemble learning scheme consist-ing of a collection of base recommendation components that are orchestrated by a MAB policy. The proposed model has a number of advantages for a prospective vendor: a) it allows to easily plug-in/out recommenda-tion components of any type, without making changes to the main algorithm; b) it is scalable because ban-dit arms represent algorithms and not single items; c) handling context can be shifted to the level of compo-nents, thus eliminating the need for contextual MAB policies. Our approach is detailed in the next section.
2. Approach
The modelling part can be split into two sub-problems: 1. Constructing base recommendation components 2. Choosing a bandit policy for the ensemble learner 2.1. Base recommendation components
We consider two types of components:
An Ensemble Recommender System for e-Commerce
items {y} that share the same attribute value with the premise item x:
x 7−→ {y : attributei(x) = attributei(y)}
For example, return all items of the same color. 2. A collaborative filtering component defines the
set of items {y} that are connected to the premise item x via a certain event type (click, purchase, addition to cart, etc.):
x 7−→ {y : eventi(x)t→ eventi(y)t0>t}
For example, return all items that were bought after the premise item (across all sessions). We note that special-purpose components can also be added by a vendor to handle all sorts of contexts. 2.2. Ensemble learner
The goal of our ensemble learner is to recommend top-N items for the premise item by querying the empir-ically best component(s). We employ the well-known Thompson Sampling (TS) policy (Chapelle & Li, 2011) for several practical reasons: a) its strong theoretical guarantees and excellent empirical performance; b) ab-sence of parameters to tune; c) robustness to obser-vation delays; d) flexibility in re-shaping arm reward distributions (see Section 2.3).
For a K-armed Bernoulli bandit, Thompson Sampling models the expected reward θa of each arm a as
a Beta distribution with prior parameters α and β: θa ∼ Beta(Sa,t+ α, Fa,t+ β). In each round t, an arm
with the highest sample is played. Success and failure counts Sa,t and Fa,t are updated according to the
ob-served reward ra,t.
The blind application of this classical TS model would fail in our case because of its two assumptions:
1. One arm pull per round. Because the selected component may return only few (or even zero!) items for a given query, pulling one arm at a time may not be sufficient to fill in the top-N recom-mendation list.
2. Arms are stationary. Because collaborative filter-ing components improve their performance over time, they have non-stationary rewards.
Therefore, our ongoing work extends Thompson Sam-pling to adapt to the task at hand. To address the first problem, we allow multiple arms to be pulled in each round and adjust the reward system accordingly. The second problem can be solved by dividing each compo-nent in sub-compocompo-nents of relatively stable behavior. 2.3. Priming the sampler
Apart from the proposed modifications of the TS model, we examine the effects of priming the
sam-pler by pre-setting the prior parameters α and β of reward distributions. We consider two realistic scenar-ios where the estimation of these priors can be done:
1. Newly launched website. In this case, the estima-tion of the parameters relies solely on the analysis of the product catalog.
2. Pre-existing website. In this case, the estimation of the parameters can be done by utilizing the event history.
In both scenarios, we must be able to reason about the expected mean µ and variance σ2 of reward
distribu-tions based on the analysis of the available data. We can then compute α and β as follows:
α = −µλ
σ2 β =
(µ − 1)λ
σ2 , λ = σ
2+ µ2− µ (1)
3. Preliminary results and future work
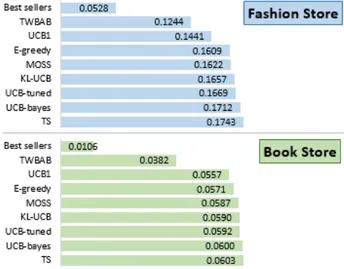
In our preliminary experiments we compare TS to other popular bandit policies for the top-5 recommen-dation task, after making the adjustments proposed in Section 2.2. Two stand-alone recommenders are used as strong baselines: best sellers and co-purchases (“Those-Who-Bought-Also-Bought”). We run the ex-periments on two proprietary e-Commerce datasets of 1 million events each: a book store and a fashion store. The results below show the hit rate of each method. We observe that Thompson Sampling
sig-Figure 1. TS vs. baselines (measured in hit rate)
nificantly outperforms the baselines and consistently outperforms state-of-the-art MAB policies by a small margin, which justifies our choice of method. Future work will demonstrate the predictive superiority of the extended TS in relation to the standard TS policy. Furthermore, we plan to examine what can be gained by priming the sampler and how exactly it can be done.
An Ensemble Recommender System for e-Commerce
Acknowledgments
This research is part of the research projects “Au-tomated System for Objectives Driven Merchandis-ing”, funded by the VINNOVA innovation agency; http://www.vinnova.se/en/, and “Improved Search and Recommendation for e-Commerce”, funded by the Knowledge foundation; http://www.kks.se.
We express our gratitude to Apptus Technologies (http://www.apptus.com) for the provided datasets and computational resources.
References
Chapelle, O., & Li, L. (2011). An empirical evaluation of thompson sampling. Proceedings of the 24th In-ternational Conference on Neural Information Pro-cessing Systems (pp. 2249–2257).
Paraschakis, D., Holl¨ander, J., & Nilsson, B. J. (2015). Comparative evaluation of top-n recommenders in e-commerce : an industrial perspective. Proceedings of the 14th IEEE International Conference on Machine Learning and Applications (pp. 1024–1031).