Horst Löfgren
STRUCTURAL EQUATION
MODELING
En kraftfull analysmetod för undersökning av kvaliteten
i kvantitativa mätinstrument och för att pröva teoretiska
kausala modeller
2 © Horst Löfgren
© Horst Löfgren 3
Förord
Inom svensk beteendevetenskaplig forskning, och kanske även inom andra områden, synes den metodologiska kompetensen inom det kvantitativa området inte alls följt med i den internationella utvecklingen. Inom vissa discipliner har den till och med försämrats över åren. Av många forsk-ningspublikationer framgår att författaren haft svårt att välja lämpligt stickprov för att kunna generalisera sina resultat till den många gånger odefinierade populationen, svårt att välja lämplig analysmetod och svårt för att skilja på signifikans och storlek. Även om urvalsenheten är någon form av grupp, t.ex. klass eller skola i pedagogiska undersökningar, utgår man tydligen ifrån att man har oberoende observationer. Signifikanta skill-nader har lyfts fram som slutresultat utan kommentarer till stickprovsstor-lek och effektstorstickprovsstor-lek. Den statistiska analysen har varit alltför signifikans-inriktad som om en högst säkerställd skillnad närmast har varit synonym med en stor skillnad. Inferensstatistik används, trots att man inte har repre-sentativa urval ur någon definierad population.
Det är självfallet bra att metodarsenalen utökats med vad som benämns kvalitativa data och kvalitativa analysmetoder, men det är olyckligt om man bygger konstgjorda murar genom att använda benämningar som kvali-tativ forskning och kvantikvali-tativ forskning. Det är mera sällan att något är strikt kvalitativt eller kvantitativt. Val av metod bör inte styras av att man endast är kunnig inom ett område utan naturligtvis av själva forsknings-problemet och den teoretiska utgångspunkten.
För ett antal decennier sedan ingick inom beteendevetenskaperna en nybörjarkurs i statistik på den första grundnivån följd av en fortsättnings-kurs på det som idag kallas 21-40 poängsnivån. Visserligen var dessa kur-ser en stötesten för många, i synnerhet för dem som hade en negativ för-handsinställning. Möjligen lärde sig många att lösa de statistiska uppgif-terna korrekt utan att egentligen förstå. Men eftersom datorer inte fanns på den tiden, och det därför inte räckte med att trycka på rätt knapp för att exempelvis få ett mått på reliabiliteten för ett mätinstrument, lärde man sig
4 © Horst Löfgren
förstå vad en reliabilitet är genom att räkna för hand. Idag är det många studerande, som visserligen vet att reliabilitet är ett ord för mätsäkerhet, och man kanske också känner till att det finns något som kallas ’Cronbach’s alpha’ och ’split-half’, men hur dessa beräknas har man ingen klar uppfattning om. Studeranden på högre nivåer blir säkerligen ytligt bekanta med program för statistisk dataanalys (t.ex. SPSS) och man lär sig att trycka på rätt knappar på datorn, men varför man väljer viss metod och hur man ska tolka resultatutskriften är svårt för många. Det finns en up-penbar risk att forskarstuderande väljer bort kvantitativa data och kvantita-tiva analyser för att man inte behärskar metoden, kanske inte heller deras handledare. Väldigt ofta kräver valda forskningsproblem att man behärskar olika metoder, och för att läsa om forskningsrön i facktidskrifter krävs också att man har en bred kompetens.
I föreliggande häfte försöker jag visa utvecklingen inom en del av den kvantitativa metodarsenalen. Även om utvecklingen gått mycket snabbt under de senaste decennierna, har man i mer än 80 år arbetat med att ut-veckla metoder för analys av det man kallar kausala modeller för deskrip-tiva data. Många parametriska analystekniker bygger på en statistisk teori om en generell linjär modell (GLM) och syftet med dessa analysmetoder är att bestämma relationen mellan de oberoende variablerna och de beroende. Structural Equation Modeling (SEM) är den mest flexibla statistiska ana-lysmetoden som använder GLM, och den kan samtidigt hantera många oberoende och beroende variabler, både kategoridata och kontinuerliga variabler. För att förstå denna framställning är det en klar fördel om man kan grundläggande statistik. Tidigare har jag publicerat boken ”Grundläg-gande statistiska metoder för analys av kvantitativa data: Med övningar för programpaketet SPSS”, som ger en god grund för att förstå denna intro-duktion till Structural Equation Modeling. För att själv kunna utföra SEM-analyser rekommenderas någon lämplig specialkurs på forskarutbildnings-nivå, om inte programmanualerna och den litteratur som finns är tillräck-liga. För dem som önskar ytterligare information eller önskar erhålla data-filer för de uppgifter som finns i kompendiet och som kan användas för att pröva nya modeller kan kontakta undertecknad på följande e-post-adress: ’horst.lofgren@mah.se’.
Barsebäck i januari 2014 Horst Löfgren
© Horst Löfgren 5
Innehåll
1 Inledning ... 71.1 Utvecklingen av kausala modeller ... 9
1.2 Från korrelationer till path-koefficienter ... 14
1.3 Fortsatt utveckling av kausala modeller ... 16
1.4 Vad är ’Structural Equation Modeling’? ... 17
2 Analys av mätmodell... 18
2.1 Begreppsvaliditet ... 20
2.2 Reliabilitet – en kort repetition ... 22
2.3 Utforskande respektive bekräftande faktor-analys ... 24
2.4 Exempel på analys av mätmodell med SEM ... 25
3 Analys av strukturmodell ... 30
3.1 SEM-modellering – en metod för att bygga upp nya hypoteser ... 32
3.2 Illustrerande exempel på hur man arbetar med STREAMS ... 35
4 Analyser på flera nivåer samtidigt ... 49
4.1 Ett exempel på tvånivåsanalys ... 50
5 Avslutande reflektioner ... 55
Referenser ... 57
Bilagor ... 59
Bilaga 1a: Regressionsanalys ... 60
Bilaga 1b: Path-analys... 62
Bilaga 2: Brandexempel ... 64
6 © Horst Löfgren
Bilaga 3b: Mätmodell med två latenta variabler ... 70
Bilaga 3c: Mätmodell med en latent variabel ... 73
Bilaga 4: Modell med 11 variabler; tre latenta och en kvalitativ variabel (kön) ... 76
Bilaga 5: Modell med tre korrelerade exogena latenta variabler och en endogen latent variabel ... 80
Bilaga 6: Illustrerande exempel ... 86
Bilaga 7a: Tvånivåsanalys: inomgruppsanalys ... 93
Bilaga 7b: Tvånivåsanalys: både inom och mellan grupper... 99
© Horst Löfgren 7
1
Inledning
Människan har alltid försökt finna kausala förklaringar till vad som händer i världen. Inom utbildningsområdet söker vi förklaringar till den variation som finns, t.ex. mellan pojkars och flickors skolprestationer, skillnader mellan skolor, klasser, etc. Vad är exempelvis orsaken till att svenska ele-ver presterar sämre än eleele-ver i Finland, Singapore och Taiwan? På många områden är det omöjligt att genomföra s.k. sanna experiment för att kunna påvisa orsakssammanhang. För att kunna göra experiment måste man ar-beta med randomisera grupper, dvs. slumpmässigt kunna tilldela den indi-vider den oberoende variabeln. I flesta fall får man inom samhällsveten-skaperna nöja sig med icke-experimentella undersökningsuppläggningar, men trots detta vill man gärna söka kausala förklaringar till sina resultat. Man skulle kunna uttrycka detta i följande punkter:
Kausala förklaringar är den mest fundamentala förklaringen till proces-ser som studeras.
Det är mer intressant att veta att x orsakar y än att veta att x och y har samband med varandra.
Om teorier utvecklas i former av kausala relationer kan många andra relationer härledas.
Utifrån filosofisk grund kan man aldrig bevisa kausala relationer, man kan endast visa att två händelser hänger ihop eller att de följer varandra. Man kan inte bevisa att en teori är sann, många alternativa teorier kan förklara ett och samma skeende. Frågan är emellertid om en teori kan få empiriskt stöd eller om den måste förkastas till följd av de data som valts att pröva teorin. Kausala modeller går sålunda ej att bevisa, för bevis krävs, som ovan nämnts, strikta experiment. Eftersom det inom det beteendeveten-skapliga fältet är mycket svårt att genomföra experiment (bl.a. beroende på etiska och andra svårigheter att slumpmässigt tilldela individer
grupptillhö-8 © Horst Löfgren
righet), måste vi försöka vidareutveckla deskriptiva studier på ett sådant sätt att vi når fram till förklaringar. Åtminstone måste vi utveckla förkla-ringsmodeller till deskriptiva data. Idag finns det möjligheter att visa på en sannolik kausal tolkning, även om andra tolkningar också är möjliga. Kau-salitet måste bygga på saklogisk teori, dvs. teoretiska modeller måste ha någon rimlighetsförankring. Longitudinella undersökningar möjliggör kausala förhållanden. Vad som har inträffat tidigare kan påverka senare händelser men inte tvärtom.
Det är sålunda mycket svårt att genomföra sanna experiment. Kvasiex-perimentella uppläggningar, där man inte använder sig av slumpmässig tilldelning av den oberoende variabeln, har sina brister att ge säkra förkla-ringar. Alltför många andra oberoende variabler, som man inte har under kontroll kan vara orsaker till eventuella effekter. Dock kan man nå långt i sin förståelse för hur fenomen hänger samman, även om man endast har tillgång till deskriptiva data.
Eftersom man inom flera discipliner, i synnerhet inom beteendeveten-skaperna, inte kan observera sina mest intressanta begrepp direkt utan end-ast via indikatorer, måste forskaren lägga ner stor möda på att definiera och förankra sina teoretiska begrepp, så att dessa kan förstås på ett otvety-digt sätt. Efter att ha definierat sina begrepp, dvs. den faktor eller de fak-torer man egentligen vill observera, måste man på ett logiskt och stringent sätt konstruera eller välja observerbara indikatorer på dessa begrepp. I det förberedande arbetet inför en datainsamling måste man således börja med att definiera de begrepp som ska användas i den kommande studien. I detta arbete är det angeläget att dra nytta av tidigare studier och relatera sina begrepp till den kunskap (teori) som finns. Vid konstruktionen av indikatorerna måste man noga överväga vad man kan förvänta sig att fånga in, och se till att de indikatorer som till slut väljs verkligen kan för-väntas vara bra indikatorer. Detta förberedande arbete är således ett teore-tiskt arbete. En pilotstudie rekommenderas för att pröva hållbarheten i det teoretiska arbetet, dvs. studera om indikatorerna ger hög kvalitet i data, dvs. hög relevans och tillförlitlighet visavi de faktorer man vill studera. Om man använder sig av redan insamlade data, måste ett kritiskt resone-mang föras, om data verkligen kan användas i det nya sammanhanget. Först när man har en solid grund för sina vetenskapliga frågeställningar, kan man gå vidare och redovisa resultat och analys.
© Horst Löfgren 9
1.1
Utvecklingen av kausala modeller
För omkring nittio år sedan publicerade genetikern Sewell Wright artiklar som sedermera utvecklades till en metod som benäms ’path analysis’. I sin forskning försökte Wright skatta effekterna från respektive förälder på deras barn genom att lösa ekvationer som ställts upp på basis av korrelat-ioner mellan studerade variabler (Wright, 1921). Eftersom bl.a. föräldrar-nas gener var orsak till barnets förmågor uppstår en s.k. rekursiv orsaks-modell, dvs. den kausala relationen kan endast gå i en riktning – från för-äldrar till barn. Detta resonemang ledde så småningom fram till en modell, som metodologiskt fick benämningen ’path analysis’ eller som den ofta på svenska kallas ’stig-analys’. Wright utvecklade denna metod för att studera direkta och indirekta effekter av variabler som betraktades som orsaksvari-abler på dem som betraktades som effektvariorsaksvari-abler (Wright, 1934). Det är väsentligt att förstå att path-analys inte är en metod att finna orsaker utan en metod som appliceras på en kausal modell, som utvecklats på basis av kunskap och teoretiska överväganden.
… the method of path coefficients is not intended to accomplish the impossible task of deducing causal relations from the value of a correlation coefficient. It is intended to combine the quantitative information given by the correlations with such qualitative infor-mation as may be at hand on causal relations to give a quantita-tive interpretation (Wright, 1934, p. 193).
In cases in which the causal relations are uncertain, the method can be used to find the logical consequences of any particular hy-pothesis in regard to them (Wright, 1921, p. 557).
Path-analys är således en statistisk teknik som använder multipel regress-ion för att pröva kausala relatregress-ioner mellan variabler. Det är en användbar metod för att pröva en teori men sämre för att generera en teori.
Om man har den kvalitativa informationen, som i Wright’s fall, att re-lationen endast kan gå i en riktning, dvs. från föräldrar till barn, kan man bestämma den kausala relationen, även om vi endast har tillgång till
sam-10 © Horst Löfgren
bandsmått. Det är detta resonemang som utgjorde grunden för den metodo-logi som så småningom växte fram, nämligen att finna konsekvenser för hypotetiska strukturer. Empiriskt borde man således kunna pröva om en hypotetisk kausal struktur är förenlig med sambandsbeskrivningar av data. Om modellen ganska väl stämmer med empiriska data erhålls ett stöd för att teorin håller, om inte, måste den kausala teorin förkastas.
Många år senare kom ’path analysis’ att bli en ofta använd metod inom samhällsvetenskaplig forskning (Blalock, 1964; Duncan, 1966, 1975). Inom sociologisk forskning kunde det exempelvis handla om hur social bakgrund, skolframgång och socialt stöd kunde predicera framgång i yr-keslivet. De statistiska metoder som användes i dessa sammanhang var regressionsanalys och path-analys.
Regressionsanalys är en multivariat teknik för att bestämma sambandet mellan en kriterievariabel och två eller flera prediktorvariabler. Denna har blivit en av de mest använda statistiska analysteknikerna inforskning på många områden. Regressionstekniken kan användas på intervall-, ordinal- och kategoridata.
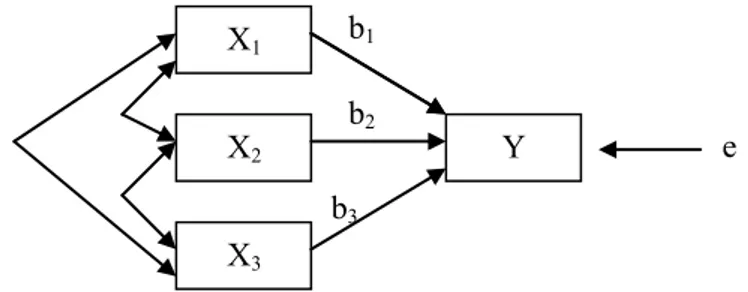
Yest = b1x1 + b2x2 + b3x3 + … + bnxn + A
Det predicerade värdet på Y (Yest) skiljer från kriteriet Y beroende på att
x:en inte är perfekta prediktorer.
Varje b-värde är en regressionskoefficient som visar hur mycket den beroende variabeln förändras, om värdet på respektive föregående variabel ökar ett steg. A är en konstant (jfr den räta linjens ekvation y= a + bx) och visar var regressionslinjen skär y-axeln. Dessa b-värden visar hur stor in-verkan respektive prediktor har.
I regressionsanalys är man således intresserad att studera hur mycket av den beroende variabeln, dvs. hur stor varians i utfallsvariabeln som kan prediceras utifrån valda prediktorvariabler. Resultatet kan uttryckas i andel förklarad varians i den beroende variabeln. Ofta är man kanske mer intres-serad att få en förklaring av vilka prediktorvariabler som bäst kan predi-cera den beroende variabeln. Om prediktorerna är ortogonala, dvs. icke-korrelerade, är det enkelt för då kan man studera korrelationerna mellan de enskilda prediktorerna och kriteriet (den beroende variabeln). Emellertid är det nästan alltid så att prediktorerna sinsemellan är korrelerade, och de kan dessutom vara olika skalerade. Då beräknas i stället de standardiserade viktkoefficienterna (benämns ”beta” i SPSS). Dessa beta-värden kan
vari-© Horst Löfgren 11
era mellan -1,00 och +1,00. Eftersom vikterna bestäms så, att man får maximal prediktion av kriteriet, bör man ha minst 10 gånger så många observationer som antalet variabler, eftersom hela variansen i prediktorer-na viktas in, dvs. även mätfel. Om man har alltför många prediktorer i förhållande till antalet observationer kommer man att erhålla en felaktigt hög skattning av Y. Den delen av variansen i kriteriet som inte kan predi-ceras utifrån valda prediktorer kallas residual, dvs. skillnaden mellan Yest
och Y.
Figur 1.1. Regressionsmodell med tre prediktorvariabler (bi =
standardi-serade viktkoefficienter; e = residual)
De dubbelriktade pilarna mellan prediktorvariablerna indikerar att det kan finnas samband mellan dem.
Multipla regressionsanalyser kan göras med olika statistiska program-varor, t.ex. SPSS. Sådana analyser kan också göras med de program som är utvecklade för SEM-analyser och som används i kommande avsnitt. En path-analys visar en orsaksrelationer mellan en eller flera exogena variabler och en eller flera endogena variabler. Termerna exogena och endogena variabler används i sådana här sammanhang och är liktydiga med oberoende och beroende variabler. Dessa termer kommer från grekis-kans exo och endos, dvs. det finns externa, utifrån komna variabler och interna variabler inne i modellen. De endogena variablerna förklaras av de exogena variablerna, medan eventuella orsaker till de exogena variablerna ligger utanför modellen. Ej heller studeras orsaksrelationerna mellan de
X1 X2 Y X3 e b1 b2 b3
12 © Horst Löfgren
exogena variablerna men däremot sambanden dem emellan. En kausal relation symboliseras med en enkelriktad pil, medan en korrelation symbo-liseras med en dubbelriktad pil (oftast böjd linje).
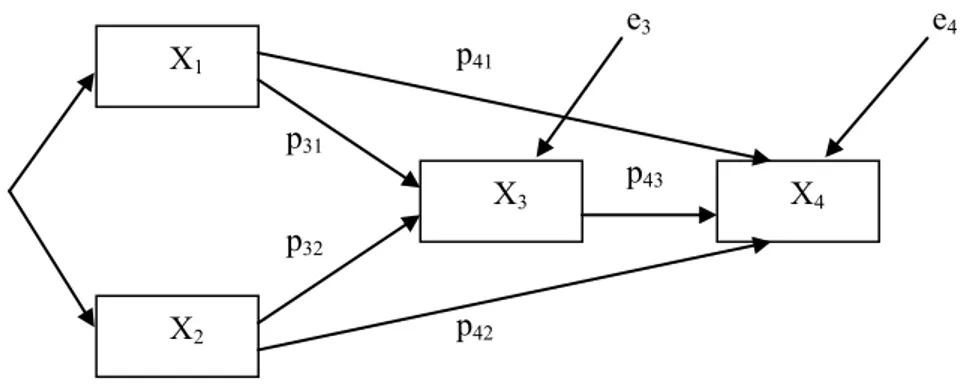
Figur 1.2. Pathmodell (p = pathkoefficienter; e = residual)
Nedan följer några belysande exempel med data hämtade från det svenska stickprovet ur en internationell undersökning ’IEA-written composition’ (Gorman, Purves, & Degenhart, 1988). De variabler som är valda här är kön, attityder till skrivning, en summavariabel kallad ’hemkultur’ (bildad av sex frågor om hur ofta man samtalar eller diskuterar olika ting hemma inom familjen) samt erhållet betyg i uppsatsskrivning.
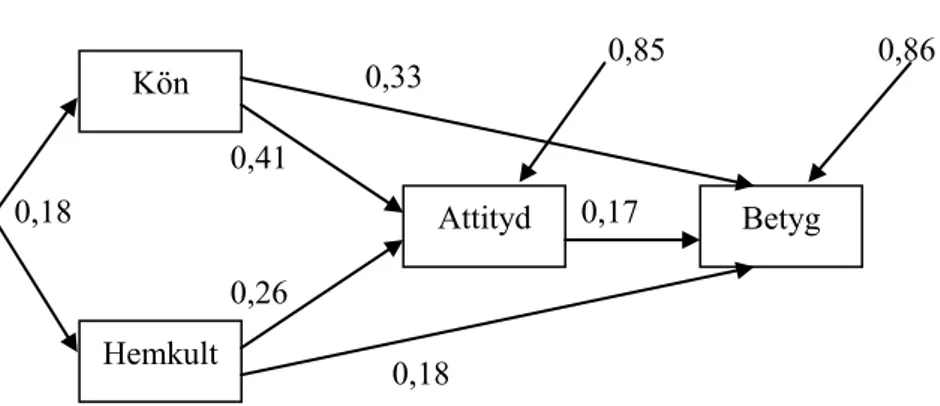
I regressionsanalysen studeras hur mycket varians i betygvariabeln som kan prediceras utifrån de övriga tre variablerna och i path-analysen betrak-tas kön och hemkultur som bakgrundsvariabler som enligt modellen anbetrak-tas påverka betygsresultatet både direkt och indirekt via variabeln attityd till skrivning. I figurerna nedan är resultatet av analyserna inskrivna, dvs. betavikterna i regressionsanalysen och koefficienterna i path-analysen. Båda analyserna visas i sin helhet i Bilaga 1.
Både regressionsmodellen och path-analysmodellen ger självfallet samma andel förklarad varians i betygsvariabeln, 27 %. Likheterna mellan de två metoderna framgår av resultatfigurerna. Den extra information som erhålls av path-analysen är att man får ett mått på de indirekta relationerna från kön och hemkultur via attityd till betyg. Ofta är det intressant att få ett mått på både den direkta relationen och en eller flera indirekta relationer.
X1
X2
X3
X4 p43 p42 p31 p32 p41 e3 e4
© Horst Löfgren 13
Multipel korrelation = 0,52; Förklarad varians i Betyg = 27 % Figur 1.3. Resultat av regressionsanalys
Figur 1.4. Resultat av path-analys
Betyg Kön Hemkultur Attityd 0,33 0,86 0,18 0,17 Kön Hemkult Attityd 0,17 Betyg 0,18 0,41 1 0,26 0,33 p41 0,85 0,86 0,18
14 © Horst Löfgren
1.2
Från korrelationer till path-koefficienter
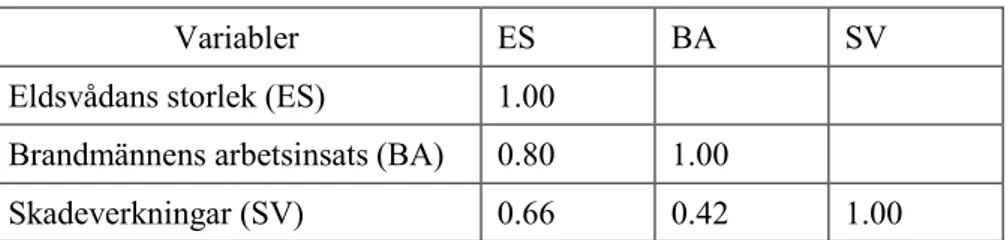
För att förklara hur Sewell Wright kunde beräkna sina path-koefficienter utifrån korrelationerna mellan variablerna i analysen ges här ett konstruerat exempel. Vi tänker oss att man samlat data från ett stort antal eldsvådor och därvid observerat eldsvådans storlek, brandmännens arbetsinsats och skadeverkningar av branden. Eldsvådans storlek är kanske lite svårare att skatta, men arbetsinsatsen kan t.ex. räknas i antal mantimmar och skade-verkningar i form av kostnader för försäkringsbolaget.
Tabell 1.1 Korrelationsmatris
Variabler ES BA SV
Eldsvådans storlek (ES) 1.00
Brandmännens arbetsinsats (BA) 0.80 1.00
Skadeverkningar (SV) 0.66 0.42 1.00 Om man är ovetande om att korrelationer inte kan tolkas kausalt, hade man nog undrat över att sambandet mellan brandmännens arbetsinsats och ska-deverkningar är positivt. En feltolkning är således att ju mer brandmännen arbetar desto större skadeverkningar blir det. Kan man möjligen lösa för-klaringen genom att pröva en kausal modell som säger att eldsvådans stor-lek direkt påverkar skadeverkningarna och att eldsvådans storstor-lek påverkar brandmännens arbetsinsats, som i sin tur påverkar skadeverkningarna? Den sistnämnda orsaksrelationen blir rimligtvis negativ, dvs. ju fler brandmän som jobbar desto mindre skadeverkningar i förhållande till eldsvådans storlek. Resultatet av path-analysen visas i Figur 1.5.
Om modellen är perfekt ska man kunna reproducera korrelationsmatri-sen. För att kontrollera att så är fallet måste man känna till ’Wright’s rules’ som säger: Sambandet mellan två variabler i path-diagrammet kan uttryck-as som summan av alla stigar (paths) som förbinder dessa två punkter men under betingelserna a) ingen slinga, b) inte gå framåt och sedan bakåt och c) högst en dubbelriktad pil per stig. Om vi applicerar dessa regler på exemplet ovan erhålls följande:
© Horst Löfgren 15
Sambandet mellan eldsvådans storlek och skadeverkningar (rSVES) =
0,90 – 0,30x0,80 = 0,66; sambandet mellan eldsvådans storlek och brand-männens arbetsinsats (rSVBA) = -.30 + 0,90x0,80 = 0,42. Sambandet mellan
eldsvådans storlek och brandmännens arbetsinsats = 0,80 (enligt reglerna får man inte gå framåt och sedan bakåt). Utifrån modellen har vi således reproducerat korrelationsmatrisen.
Figur 1.5. Erhållna path-koefficienter enligt den teoretiska modellen
Om man skriver in korrelationsmatrisen från brandexemplet ovan i STREAMS1 och låter LISREL skatta path-koefficienterna (se avsnitt 1.3)
erhålls nedanstående resultat (här har angetts att matrisen baserar sig på många observationer). Hela resultatutskriften finns i Bilaga 2.
Model Building Language Statements
**************************************************** * TI Pathanalys med variablerna ES, BA och SV
* MO PR=Eldex NAME=model1
* MO Create instructions for: LISREL Y-model Matrix: KM
* MO Means not included in model One-group model * MO LISREL DOS/Extender 8.50
* OP OU ME=ML AD=OFF MI SS SC
* DAT FOLDER=NewFold DATLAB=NewData2 * MVR ES BA SV
1 STREAMS är en programvara som förenklar användningen av LISREL.
SV ES BA 0,90 -0,30 0,80
16 © Horst Löfgren
* REL ES -> BA SV
* REL BA -> SV
**************************************************** Estimates have been computed with LISREL8.50 DOS Ex-tender
Message from LISREL:
Number of Iterations = 0 Standardized estimates:
BA = +0.80*ES +0.60*BA&
SV = +0.90*ES -0.30*BA +0.73*SV&
1.3
Fortsatt utveckling av kausala modeller
Nästa steg i utvecklingen av kausala modeller innebar att man kunde han-tera mätfel och även använda flerriktad orsaksverkan (återkopplingar), s.k. icke-rekursiva modeller. Det utvecklades generella linjära modeller och program som kunde hantera olika typer av modeller; t.ex. LISREL (Jöre-skog & Sörbom, 1993), AMOS (Arbuckle, 1997) och Mplus (Muthén & Muthén, 2005). Eftersom dessa analyser innebär komplicerade beräkningar och skattningar av parametrar utifrån lösningar ur ett antal ekvationer, blev dessa metoder först användbara för forskare utan statistisk specialistkom-petens när persondatorernas prestanda ökade, så att dessa på rimlig tid kunde lösa avancerade ekvationssystem. För inte så länge sedan fick man skriva omfattande instruktioner för att datorn skulle kunna utföra en öns-kad analys. Det hände ofta att datorn efter många timmars arbete medde-lade att analysen hade misslyckats. Med kraftfullare datorer och med de program som idag finns och som förenklar instruktionerna till exempelvis en LISREL-analys gör att man snabbt får fram ett resultat av analysen. Ett sådant hjälpprogram är STREAMS (Structural equation modeling made simple) (Gustafsson & Stahl, 2005). Intressant att notera är att många svenska forskare inom det statistiska området har medverkat vid utveckl-ingen av dagens kraftfulla analysmetoder.
Den tidigare flitigt använda path-analysmetoden är idag mera sällan förekommande. Som framgått av figurerna har i exemplen ovan endast använts manifesta, dvs. observerade variabler. I de fall där det funnits flera
© Horst Löfgren 17
indikatorer har dessa slagits samman till en summavariabel. Ett stort pro-blem med de manifesta variabler som används inom samhällsvetenskaper-na (och även inom andra discipliner) är att de är valda indikatorer, som antas mäta svårdefinierade begrepp. Får man god information om det man vill mäta med de valda indikatorerna (validitet), och får man en hög mät-säkerhet, när man använder de valda indikatorerna (reliabilitet)? Hur man kan kontrollera kvaliteten i sina data tas upp i kommande kapitel.
1.4
Vad är ’Structural Equation Modeling’?
Strukturekvationsmodellering (SEM) är statistisk metod som kan användas av forskare inom många olika discipliner, speciellt sådana som vid sina observationer och mätningar använder indikatorer på de konstruerade be-grepp som är fokus för forskningen. Inom många områden kan man inte använda en direkt mätning som t.ex. vid fysiska mått som längd och vikt utan måste finna indikatorer som mer eller mindre bra fångar in det man vill studera, t.ex. trivsel, välbefinnande, attityder, motivation, kunskaper, professionalitet, flexibilitet, social kompetens, etc. etc.
Problemet är att tillräckligt väl definiera sina begrepp och finna lämp-liga indikatorer. I tidigare forskning fick man acceptera att det i alla obser-vationer (mätningar) finns mätfel. Visserligen kunde man skatta storleken på dessa mätfel, men den stora skillnaden mellan tidigare metoder och metoder inom Structural Equation Modeling är att det nu går att hantera dessa mätfel. I regressionsmodeller måste man ha många observationer och relativt få variabler för att inte mätfelen skulle få för stort inflytande. Helst behövde man korsvalidera sina resultat i nya studier. I path-analys används också manifesta variabler (indikatorer) som alla innehåller mätfel. Om man i stället kunde använda latenta variabler, dvs. icke-direkt obser-verbara begrepp, som kunde förklara utfallen i ett antal observerade (mani-festa) variabler kunde man kunna lösa problemet med mätfel. Med hjälp av faktoranalys skulle man kunna göra en s.k. begreppsvalidering, dvs. kunna bestämma i vilken grad ett mätinstrument verkligen mäter det begrepp man avser att mäta. I nästa kapitel ska vi se närmare på validitet och reliabilitet.
18 © Horst Löfgren
2
Analys av mätmodell
Det är nog ingen överdrift att påstå, att man ofta i olika undersökningar utgår ifrån att man har hög kvalitet i sina data utan att tillräckligt noga ha studerat om så är fallet. Åtminstone inom samhällsvetenskaplig forskning är man ofta intresserad att studera faktorer, som inte går att observera på ett direkt sätt. Det handlar om skapade begrepp, som endast kan observeras eller mätas via indikatorer. Man kan ha stora svårigheter att definiera sina begrepp (konstruktioner), eftersom dessa ofta är breda och diffusa. Det blir då viktigt att studera om indikatorerna är väl valda och verkligen kan ge den information som eftersöks. I kvantitativa data är det ganska enkelt att studera hur de observationer, som antas mäta det man avser att mäta är relaterade till varandra och om de mäter en och samma sak, samt om man har tillräckligt mätsäkra data på det man vill studera. Det finns olika sätt att skatta både validiteten och reliabiliteten (se t.ex. Löfgren, 2006). SEM erbjuder ett utmärkt alternativ för att studera begreppsvaliditet och mätsä-kerhet.
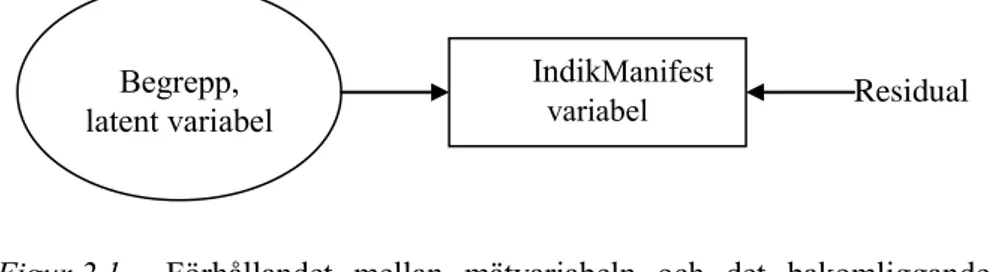
Residual
Figur 2.1. Förhållandet mellan mätvariabeln och det bakomliggande begrepp som mätvariabeln avser att mäta
Om man endast har en indikator för det begrepp man vill mäta finns ingen möjlighet att med hjälp av statistiska analyser bestämma vare sig validitet eller reliabilitet. Det är därför nödvändigt att ha mer än en indikator, helst flera, för att kunna studera kvaliteten i data.
Alltför ofta brister det teoretiska förarbetet. De begrepp (latenta variab-ler) som används är kan vara dåligt definierade och indikatorerna
(mani-Begrepp, latent variabel IndikManifest variabel MV3 le1 Manivv
variabel
LV
V1© Horst Löfgren 19
festa variabler) inte tillräckligt välmotiverade. Mätmodeller prövas, dvs. om en viss bakomliggande latent variabel kan anses vara orsak till utfallet i de manifesta variablerna. De latenta variablerna benämns, och i den fort-satta diskussionen får dessa namngivna begrepp sin innehållsförståelse mera av etiketten än de använda manifesta variablerna. Ofta används de latenta variablerna därefter för att bygga upp en strukturmodell, dvs. en modell på relationer mellan de latenta variablerna (begreppen), ofta av kausal natur. Om nu indikatorerna inte är särskilt bra för att distinkt kunna beskriva de begrepp som används, kan den statistiska analysen bli missle-dande.
Detta förberedande arbete är således ett teoretiskt arbete. En pilotstudie rekommenderas för att pröva hållbarheten i det teoretiska arbetet, dvs. studera om indikatorerna ger hög kvalitet i data, dvs. hög relevans och tillförlitlighet visavi de faktorer man vill studera. Om man använder sig av redan insamlade data, måste ett kritiskt resonemang föras, om data verkli-gen kan användas i det nya sammanhanget. Först när man har en solid grund för sina vetenskapliga frågeställningar, kan man gå vidare och redo-visa analys och resultat.
Förutom ett teoretiskt underlag för använda begrepp och indikatorer måste forskaren också ha ett teoretiskt underlag för de relationer mellan använda begrepp, som eventuellt ska prövas. Man måste med andra ord ha en hållbar teori för både sina mätmodeller och strukturmodeller. Alldeles för ofta nöjer man sig med att ta vad man har utan att ha ett kritiskt för-hållningssätt till data och de analysresultat som blir resultatet av den stat-istiska teknik som används. Om man i en strukturmodell vill pröva kausala relationer, måste de kausala relationerna vara teoretiskt motiverade. Sam-las alla data in vid ett och samma tillfälle kan det vara svårt att veta vad som är orsak och verkan. Vid longitudinella studier kan det vara enklare att argumentera för en kausal relation.
20 © Horst Löfgren
2.1
Begreppsvaliditet
Det finns olika sätt att studera validiteten i data, dvs. om man verkligen mäter det man vill mäta. Det är emellertid vanskligt att få ett mått på vali-ditet, om man har skapat ett begrepp som endast kan mätas via ett antal indikatorer. Tidigare användes en indelning av begreppet validitet i bety-delsen innehållsvaliditet, samtidig validitet, prognostisk validitet och be-greppsvaliditet. Den förstnämnda innebar en bedömning av hur väl mät-ningen överensstämde med det man ville ha information om. Samtidig och prognostisk validitet kunde korrelationskoefficienter ge information om. Om man t.ex. använder sig av s.k. samtidig validitet beräknar man korre-lationen mellan sina egna mått på det man vill studera och ett lämpligt kriterium, dvs. ett annat mått på samma sak. Om kriteriet inte mäter det man vill studera särskilt bra, kan man knappast tolka en hög korrelation som ett tecken på god validitet.
Ett betydligt bättre sätt att få information om validiteten i en mätning är att använda en form av begreppsvaliditet. Detta begrepp har under senare år fått en vidgad betydelse än det ursprungliga. Den nuvarande definition-en inkluderar ävdefinition-en värderingar som kan relateras till mätningdefinition-en och de tolkningar och konsekvenser som mätningen kan resultera i. Den utvid-gade begreppsvaliditeten kan tillämpas i olika typer av forskningsansatser, såväl kvantitativa som kvalitativa.
Med hjälp av faktoranalys kan man studera hur bra ett antal mått är för fånga in det begrepp man vill studera. Jämförelse görs då inte med resultat från andra mätningar utan med antagandet att ett antal valda indikatorer har en gemensam varians som är ett mått på det begrepp man vill studera. Begreppet är då en latent variabel, som antas förklara utfallet i ett antal manifesta variabler.
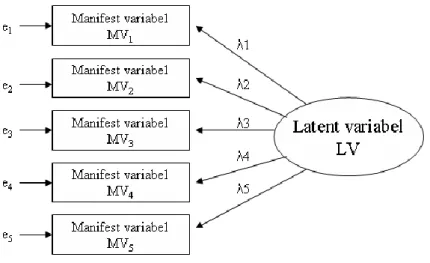
Enligt Figur 2.1 har man en latent variabel, ett begrepp som skapats och som inte kan mätas direkt utan via, i det här fallet fem indikatorer. Begrep-pet (LV) kan ses som den bakomliggande orsaken till utfallet i de fem observerade variablerna. Den latenta variabeln kan inte förklara hela vari-ansen i den manifesta variabeln. Den del som orsakas av mätfel och den del som är unikt för den observerade variabeln kallas residual och är den del som inte kan förklaras av den latenta variabeln. Här betecknas denna residual med ”e” (error). Den unika delen, dvs. den del som denna variabel inte har gemensamt med någon annan av de observerade variabler,
betrak-© Horst Löfgren 21
tas således här som en del av mätfelet. Eftersom de manifesta variablerna är valda som indikatorer på det bakomliggande begrepp man vill komma åt, är det rimligt att endast använda den gemensamma variansen, dvs. del del som två eller flera av de manifesta variablerna har gemensamt. Lamb-davärdena (λ) är faktorladdningar och kvadraten på dessa säger hur mycket av variansen i de manifesta variablerna, som kan förklaras av den latenta variabeln.
Figur 2.1. Faktoranalysmodell
Hur man benämner den latenta variabeln, dvs. det begrepp man vill stu-dera, blir väsentligt. Man måste kunna argumentera för att de valda indika-torerna är rimliga för det begrepp man definierat och benämnt. Detta är ett teoretiskt arbete som även inkluderar värderingar och sociala konsekvenser av mätningen. Ett exempel på hur man går tillväga med hjälp av SEM ges i kommande avsnitt. Redan nu kan vi emellertid ställa upp ett antal ekvat-ioner som specificerar modellen i Figur 2.1 och som visar hur de de mani-festa variablerna förklaras av den latenta variabeln (faktorladdningar) och residualerna. De fem ekvationer som kan skrivas utifrån modellen är föl-jande:
22 © Horst Löfgren MV1 = λ1LV + e1 MV2 = λ2LV + e2 MV3 = λ3LV + e3 MV4 = λ4LV + e4 MV5 = λ5LV + e5
2.2
Reliabilitet – en kort repetition
Om jag ställer mig på en gammal våg för att kontrollera min vikt, kan den kanske visa något olika värden vid olika mättillfällen, trots att jag väger mig med bara minuters mellanrum. Om vägningarna är gjorda inom en så kort tidsperiod att jag inte ändrat vikt, skulle man kunna anta att medelvär-det av de olika mätningarna är en bra skattning av min sanna vikt. Detta gäller dock endast om det inte finns systematiska fel vid vägningen, t.ex. att vågen på grund av feljustering hela tiden visar ett kilo för mycket. Det systematiska felet benämns även med de engelska termerna ’bias’ och ’accuracy’. Den skillnad som finns mellan vikten vid ett mättillfälle och medelvärdet för viktmätningarna är storleken av mätfelet vid detta mättill-fälle.
Låt oss nu anta att jag väger mig ett antal gånger på en annan och kanske modernare våg och att spridningen av mätvärden nu är betydligt mindre än vid den gamla vågen. Detta innebär då att den nya vågen är mera mätsäker, dvs. har högre reliabilitet.
Om vi nu går över till att mäta andra ting än sådana relativt enkla saker som att mäta vikt, kan det bli mer problematiskt att konstruera mätsäkra skalor. Via olika test eller enkäter försöker vi mäta människors förmågor, attityder eller andra ting, där vi inte har så välutvecklade instrument. I ett frågeformulär om stress ställs ett antal frågor, som kanske kan summeras till ett hyggligt mått på stress. Förutom att ställa frågor om frågornas vali-ditet, dvs. om de verkligen mäter det vi har definierat som stress, bör vi också ställa frågan om hur säkert vi mäter stress. Validitetsproblematiken kan vi, som ovan nämnts, studera med hjälp av faktoranalys. För att uttala oss om mätsäkerheten måste vi finna ett sätt att skatta denna.
© Horst Löfgren 23
Utgångspunkten för nästan alla reliabilitetsteorier är att erhållet värde på ett test (t) är lika med det sanna värdet (T) plus ett mätfel (e).
t = T + e (test score = True score + error)
Om man har perfekt reliabilitet, dvs. inga mätfel, blir således t = T. Mät-felen kan självfallet anta både positiva och negativa värden och i regel antas att medelvärdet för mätfelen är noll. Reliabiliteten kan definieras som den kvadrerade korrelationen mellan t och T. Om denna korrelation är lika med 1,0 innebär detta en perfekt reliabilitet. Skulle korrelationen vara noll är mätningen helt slumpmässig.
För att bestämma reliabiliteten måste vi korrelera t med T, trots att vi endast har tillgång till t-värden. Man skulle kunna skatta korrelationen om man har tillräckligt mycket information om relationen mellan ett antal observerade variabler (testresultat eller testuppgifter). Ur detta resonemang har utvecklats olika reliabilitetsteorier och olika sätt att skatta reliabilitet-en.
I klassisk reliabilitetsteori utgår man ifrån begreppet ”parallella mätin-strument”, dvs. instrument som mäter samma egenskap på samma sätt. Sådana instrument är således utbytbara och ska ge samma resultat. För att instrument ska kunna betraktas som parallella måste flera antaganden gälla. Mätfelen för alla mätobjekt med samma T-värde ska i genomsnitt vara noll, mätfelen ska vara lika över hela skalan, mätinstrumentet ska ge mätfel som är oberoende av varandra och mätinstrumentet ska mäta samma egenskap. Under dessa förutsättningar kan man beräkna mätsäker-heten.
Om man har tillgång till två parallella mätinstrument, kan man använda mätresultat från dessa för att skatta reliabiliteten. Korrelationen mellan mätresultaten blir då ett mått på mätsäkerheten. Emellertid kan det vara svårt att konstruera två parallella test och därför väljer man vanligtvis an-nan metod. Självfallet skulle det vara enklare, om man kunde skatta relia-biliteten utifrån ett mättillfälle med ett enda mätinstrument.
Den s.k. ”split-half-metoden” är ett sätt, där man använder ett enda mätinstrument. Genom att dela upp mätinstrumentet slumpmässigt i två
24 © Horst Löfgren
delar, kan man med hjälp av sambandet mellan dessa två delar och Spe-arman-Brown’s formel (se Löfgren, 2006: 58) skatta reliabiliteten för hela testet.
En metod som numera ofta används är att beräkna homogenitetskoeffi-cient, den s.k. alpha-koefficienten. Denna koefficient går under namnet Kuder-Richardson’s formel om uppgifter utvärderas binärt (t.ex. rätt – fel). Av olika reliabilitetsskattningsmetoder är Cronbach’s alpha, som den också kallas, att föredra. Den innebär att man ställer variansen för de en-skilda uppgifterna i relation till totalvariansen för testet. Om man försöker mäta ett och samma område (begrepp, dimension) med flera testuppgifter (frågor, påståenden) är denna metod lämplig. Skulle man emellertid mäta flera olika dimensioner med ett antal testuppgifter kan alpha-koefficienten indikera en lägre mätsäkerhet. Metoden bygger på att uppgifterna hänger ihop, dvs. mäter en och samma dimension, om än till viss del olika delar av denna dimension.
2.3
Utforskande respektive bekräftande
faktor-analys
Utforskande faktoranalys ’Exploratory factor analysis (EFA)’ används för att bestämma hur många kontinuerliga latenta variabler som behövs för att förklara korrelationerna mellan ett antal manifesta (observerade) variabler. I en sådan utforskande faktoranalys kan man använda olika typer av vari-abler som binära, ordinalskalerade, kontinuerliga och kombinationer av dessa. Man använder EFA då man inte riktigt vet hur ett antal indikatorer hänger ihop och vad de kan tänkas vara mått på för bakomliggande be-grepp. Även om man exempelvis har en enkät på låt oss säga 50 frågor för att studera hur anställda upplever sin arbetsmiljö, kan det i ett sådant material finnas olika aspekter av arbetsmiljön som den totala arbetsmiljö-enkäten fångar in. Det hade nog varit klokare att först fundera över olika aspekter i arbetsmiljön som kan vara värda att studera och vilka indikatorer man då skulle välja för att just få ett mått på dessa delaspekter. Om man emellertid inte har särskilt väl utvecklade mätinstrument kan EFA vara en metod för att utveckla ett bra instrument för framtida studier.
© Horst Löfgren 25
Om man emellertid vet vad man är ute efter för delaspekter kan man i stället använda det man kallar bekräftande faktoranalys ’Confirmative factor analysis (CFA)’ för att kontrollera att mätinstrumentet fungerat på det sätt som avsikten var.
Båda dessa olika typer av faktoranalys kan enkelt utföras med de ana-lysprogram, som används i den följande texten.
2.4
Exempel på analys av mätmodell med SEM
I föreliggande exempel ska vi analysera samma mätinstrument som använ-des i det tidigare nämnda IEA-projektet. Eleverna i det svenska stickprovet (N=487) hade fått svara på följande frågor:
Fråga 4-9 Hur ofta gör barn och vuxna i din familj följande saker tillsammans?
Högst en Flera En eller En eller Varje
eller två gånger två gånger två gånger eller
gånger om om i månaden i veckan nästan
året året varje dag
4. Talar tillsammans om
vad som händer på ( ) ( ) ( ) ( ) ( )
arbetet och i skolan
5. Talar tillsammans om familjeangelägenheter,
t.ex. om hushållet, ( ) ( ) ( ) ( ) ( )
släkten, ekonomin
6. Gör upp planer till- sammans, t.ex. för vecko-
helg eller semester, ( ) ( ) ( ) ( ) ( )
och diskuterar olika alternativ
7. Diskuterar allmänna
angelägenheter, ( ) ( ) ( ) ( ) ( )
t.ex. moral, religion religion, politik
26 © Horst Löfgren
8. Diskuterar en bok som ( ) ( ) ( ) ( ) ( )
någon av er har läst
9. Diskuterar TV- eller ( ) ( ) ( ) ( ) ( )
radioprogram
Man kan diskutera vad man ska benämna den latenta variabel som svaren på de sex frågorna ovan. I det här fallet har den benämnts Hemkultur. Av-sikten i undersökningen var att få något mått på hemmiljön som eventuellt kunde påverka attityder till skrivning och betyg i uppsatsskrivning. I SEM-analysen startar vi att pröva om en modell med en latent variabel kan vara rimlig. Utifrån den hypotetiska modellen estimeras kovariansmatrisen för de sex manifesta variablerna. Därefter jämförs den utifrån empiriska data erhållna kovariansmatrisen med den utifrån modellen estimerade. Om skillnaden mellan dessa två matriser är stor enligt vissa kriterier måste modellen förkastas; om den är liten verkar det rimligt att de sex frågorna mäter en och samma bakomliggande dimension. En reliabilitetsskattning görs också i samma analys. Om inte modellen med en latent variabel tycks gälla får man i programmet antydningar till hur en bättre modell kan se ut som s.a.s. kan återskapa data. Man kan alltid anpassa en modell till data, men om markanta förändringar görs i den hypotetiska modellen bör man samla in nya data för att kontrollera att den reviderade modellen håller. Den LISREL-analys som presenteras nedan har utförts med hjälppro-grammet STREAMS.
Resultat hämtade ur utskriften från STREAMS. Hela filen finns i Bi-laga 3a. Modell: MVR V4 V5 V6 V7 V8 V9 LVR G REL G -> V4 V5 V6 V7 V8 V9 Resultat:
Goodness of Fit Test:
Chi-square = 50.60, df = 9, p < .00, RMSEA = .102 Maximum Modification Index is 25.3 for:
© Horst Löfgren 27
Kovariansmatrisen för observerade data jämförs med kovariansmatrisen som genereras från den hypotetiska modellen. Chi-kvadrat-testet används för att jämföra dessa två matriser. Önskvärt är självfallet att inte testet visar signifikant avvikelse mellan de båda matriserna. Emellertid blir Chi-kvadrat-värdet snabbt signifikant, om man har relativt många observation-er. Därför använder man i stället kvoten mellan Chi-kvadratvärdet och antalet frihetsgrader som ett rimligare mått på anpassning. Om denna kvot är under 2 anses avvikelsen mellan de två matriserna vara högst rimlig. Dessutom används RMSEA-värdet som ett anpassningsindex. Om detta värde, som tar hänsyn till antalet skattade parametrar, är < 0,05 kan mo-dellen betraktas som god för att beskriva data. Den här erhållna momo-dellen är således inte helt bra. Modifikationsindexet säger att det kan finnas kor-relerade fel (residualer) i fråga 8 och 9. Det kan också vara så att Fråga 8 och 9 kan vara en specifik faktor. De har ju också lägre laddningar i den generella faktorn. Eftersom det visar sig i den fullständiga LISREL-analysen att Fråga 7, 8 och 9 har korrelerade mätfel är det antagligen så, att man borde införa en specifik faktor som riktar sig mot dessa tre frågor. En ny analys genomförs med följande instruktion:
MVR V4 V5 V6 V7 V8 V9 LVR G Dis
REL G -> V4 V5 V6 V7 V8 V9 REL Dis -> V7 V8 V9
Här antas modellen ha en generell faktor och en specifik som riktar sig mot Fråga 7, 8 och 9. Resultatet av denna analys visar:
Goodness of Fit Test:
Chi-square = 7.12, df = 6, p < .31, RMSEA = .021 Estimated reliability: 0.78
28 © Horst Löfgren Standardized estimates: V4 = +0.71*G +0.71*V4& V5 = +0.80*G +0.60*V5& V6 = +0.64*G +0.77*V6& V7 = +0.57*G +0.26*Dis +0.78*V7& V8 = +0.44*G +0.58*Dis +0.69*V8& V9 = +0.46*G +0.38*Dis +0.80*V9&
Denna analys visar således att denna modell stämmer betydligt bättre med data (jfr Bilaga 3b) . Om man än en gång läser frågorna som eleverna skulle svara på, ser man att de tre sista frågorna handlar om hur ofta man diskuterar dessa frågor och de tre första om samtal. Man kunde kanske då ana att en modell med två faktorer, en för varje frågetyp, skulle vara bättre. Dock visar det sig att så inte är fallet. Reliabilitetsskattningen visar 0,82, vilket är en helt godtagbar mätsäkerhet.
En alternativ modell som vore värd att pröva mot bakgrund av korrele-rade fel och att Fråga 8 ger en mycket sned frekvensfördelning är en mo-dell med de fem övriga variablerna. Uppenbarligen är det så, att det är mycket sällan förekommande att diskutera en bok som någon i familjen har läst. Modell och resultatet av denna analys ger följande (hela utskriften model i Bilaga 3c):
MVR V4 V5 V6 V7 V9 LVR G
REL G -> V4 V5 V6 V7 V9 Goodness of Fit Test:
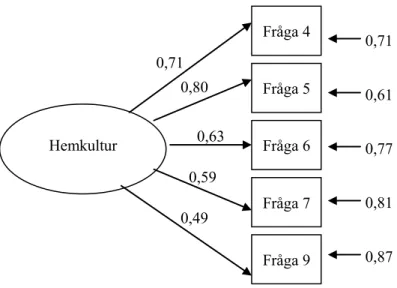
Chi-square = 7.12, df = 6, p < .31, RMSEA = .021 Estimated reliability: 0.78 Standardized estimates: V4 = +0.71*G +0.71*V4& V5 = +0.80*G +0.61*V5& V6 = +0.63*G +0.77*V6& V7 = +0.59*G +0.81*V7& V9 = +0.49*G +0.87*V9&
© Horst Löfgren 29
Denna alternativa modell passar data utmärkt, även om reliabiliteten har gått ner en aning. Det är oftast så att reliabiliteten sjunker om man har färre variabler som mäter det man är ute efter. I enlighet med Figur 2.1 kan re-sultatet beskrivas som i Figur 2.2. Den latenta variabeln förklarar Fråga 5 bäst (talar tillsammans om familjeangelägenheter) och Fråga 9 sämst (dis-kuterar TV- eller radioprogram).
Med den här typen av mätmodellanalys (kan också kallas ”begrepps-validering”) får man en god uppfattning om kvaliteten i data och en god grund för en eventuell revidering av mätvariablerna, om man vill göra en ny datainsamling. Analysen kan också ligga till grund för en bättre definit-ion och benämning av den latenta variabeln.
Figur 2.2. Resultat av LISREL-analys av mätmodell (Chi-square = 7.12, df = 6, p < .31, RMSEA = .021)
I exemplet ovan kan vi påstå att en konfimatorisk faktoranalys har använts, även om resultatet har lett till en viss justering av mätinstrumentet.
Hemkultur Fråga 6 Fråga 7 Fråga 9 Fråga 4 Fråga 5 0,71 0,87 0,63 0,59 0,49 0,80 0,81 0,77 0,61 0,71
30 © Horst Löfgren
3
Analys av strukturmodell
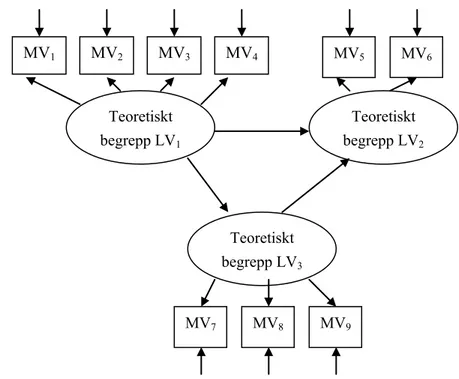
En mätmodell visar relationerna mellan den latenta variabeln och de mani-festa variablerna och en strukturmodell visar relationerna mellan de latenta variablerna. Den modell som visas i Figur 3.1 är en LISREL-modell, som både innehåller mätmodeller och strukturmodell.
Figur 3.1. LISREL-modell med tre latenta variabler med respektive fyra, två och tre manifesta variabler
Som exempel på en sådan analys ska vi än en gång använda samma data som låg till grund för några av de tidigare analyserna. I exemplet har vi byggt upp en kausal modell som innebär att de två bakgrundsvariablerna
MV2 MV7 MV8 MV9 MV6 MV5 Teoretiskt begrepp LV3 Teoretiskt begrepp LV1 Teoretiskt begrepp LV2 MV1 MV3 MV4
© Horst Löfgren 31
Kön (V1) och Hemkultur antas påverka Betyg i uppsatsskrivning direkt och även indirekt via Attityder. I den modell som prövas låter vi de båda bakgrundsfaktorerna korrelera. Man kan inte tänka sig ett kausalt samband dem emellan, även om det kan finnas skillnader mellan hur ofta pojkar och flickor samtalar om olika saker i hemmiljön. I IEA-studien finns det få manifesta variabler som är bra mått på attityder. Det finns dock två som är användbara, nämligen om vad man tycker om att skriva (en femgradig skala) och om man skriver berättelser för sitt nöjes skull (tyvärr endast ja/nej fråga). Kön är självfallet en manifest variabel.
Modellspecifikation, dvs. instruktionerna i STREAMS för denna analys blir följande:
* MVR V1 V4 V5 V6 V7 V9 V16 V17 V22 V24 V25 * LVR Hem Att Bet
* REL Hem -> V4 V5 V6 V7 V9 * REL Att -> V16 V17
* REL Bet -> V22 V24 V25 * REL Hem -> Att Bet * REL V1 -> Att Bet * REL Att -> Bet * COV Hem V1
**************************************************** Resultatet av LISREL-analysen visar att modellen fungerar utmärkt för de data som insamlats. Skillnaden mellan den reproducerade matrisen och den matris som erhålls av data skiljer sig inte signifikant åt (p>0,05) och RMSEA är utmärkt lågt. Hela utskriften återfinns i Bilaga 4.
Estimates have been computed with LISREL8.50 DOS Ex-tender
Message from LISREL:
Number of Iterations = 27
Goodness of Fit Test:
Chi-square = 42.59, df = 39, p < .32, RMSEA = .015 Maximum Modification Index is 8.9 for:
32 © Horst Löfgren
Standardized estimates:
Att = +0.31*Hem +0.45*V1 +0.81*Att&
Bet = +0.22*Hem +0.22*Att +0.28*V1 +0.84*Bet& V4 = +0.71*Hem +0.71*V4& V5 = +0.62*Hem +0.79*V6& V7 = +0.61*Hem +0.80*V7& V9 = +0.51*Hem +0.86*V9& V16 = +0.85*Att +0.53*V16& V17 = +0.33*Att +0.94*V17& V22 = +0.96*Bet +0.28*V22& V24 = +0.90*Bet +0.44*V24& V25 = +0.91*Bet +0.41*V25& Cov(V1,Hem) = 0.16
3.1
SEM-modellering – en metod för att bygga
upp nya hypoteser
När man prövar en hypotetisk modell kanske de anpassningsindex som finns att tillgå indikerar, att modellen inte är tillräckligt bra för att accepte-ras. Av resultatutskriften framgår hur man skulle kunna förändra den teore-tiska modellen så att den bättre speglar de data som samlats in. Smärre förändringar, som kan anses vara logiska, kan accepteras, men att stegvis korrigera modellen så att den till slut stämmer med data är inte acceptabelt. Däremot kan en korrigerad modell fungera som en hypotetisk modell som skulle kunna prövas vid en ny datainsamling. Som ett exempel används här en delmängd av data från en tidigare rapporterad undersökning (Malm & Löfgren, 2006).
I en studie var man intresserad att studera ungdomars strategier vid konflikthantering i relation till lärarkompetens, skolattityder och självför-troende. Flera olika datainsamlingar har gjorts, den här använda kommer från drygt 550 elever i årskurs 8. I exemplet nedan används sju manifesta lärarkompetensvariabler, fyra attitydvariabler, fyra variabler på självför-troende och tre summavariabler som mått på aggression. De latenta variab-lerna benämns lärarkompetens (Tcomp), skolattityder (Atti), självförtro-ende (Self) och aggression (Agg). Datafilen innehåller svar från 271 pojkar
© Horst Löfgren 33
och 280 flickor från 26 olika klasser. För att förstå resultatet av analysen måste man veta att de tre aggressionsvariablerna mäter olika aspekter av aggression; fysisk aggression, verbal aggression resp. aggressionsfrustrat-ion. Den sistnämnda vänder inte direkt mot person utan mot andra saker (skriker ut sin ilska, kastar saker, smäller igen dörrar etc.). Den självförtro-endevariabel som benämns S30 är hur man ställer sig till påståendet ”Jag har ett gott självförtroende”.
Eftersom vi tidigare visat hur man i en figur kan presentera sin teore-tiska modell får läsaren själv som övning illustrera modellen utifrån föl-jande modellspecifikation:
* MVR A25 A31 A33 A34 AGGFYS AGGPSY AGGFRU TDISC TSOCC TTEACH TINDI TPOSS TFAIR TKNOW S21 S23 S29 S30
* LVR Tcomp Atti Agg Self
* REL Tcomp -> TDISC TSOCC TTEACH TINDI TPOSS TFAIR TKNOW
* REL Atti -> A25 A31 A33 A34 * REL Self -> S21 S23 S29 S30 * REL Agg -> AGGFYS AGGPSY AGGFRU * REL Tcomp Atti Self -> Agg * COV Tcomp Atti Self
De manifesta variablerna är således fyra attitydvariabler, tre aggress-ionsvariabler, sju lärarkompetensvariabler och fyra självförtroendevariab-ler. Det finns fyra latenta variabler; Tcomp, Atti, Agg och Self. Enligt mo-dellen påverkar Tcomp, Atti och Self utfallsvariabeln Agg. Eftersom det i modellen inte angivits någon kausal relation mellan Tcomp, Atti och Self visar den sista raden ovan att de endast korrelerar med varandra.
Resultatet av denna körning visar att modellen kan förbättras. Förslag ges hur den kan förbättras och efter några körningar och ytterligare förbätt-ringar har relationerna utökats med följande:
* REL Self -> AGGFRU * REL Agg -> S30
Dessutom blev modellen något lite bättre om man tillät att några residualer fick korrelera.
34 © Horst Löfgren
* COV TKNOW& TDISC&
* COV A33& TTEACH& * COV TTEACH& TINDI& * COV A33& TINDI&
Efter dessa korrigeringar erhölls följande goda slutresultat (jfr Bilaga 5): Message from LISREL:
Number of Iterations = 56 Goodness of Fit Test:
Chi-square = 165.03, df = 123, p < .01, RMSEA = .026 Standardized estimates:
Agg = -0.19*Tcomp -0.30*Atti +0.17*Self +0.92*Agg&
A25 = +0.83*Atti +0.56*A25&
A31 = +0.77*Atti +0.64*A31&
A33 = +0.70*Atti +0.71*A33&
A34 = +0.76*Atti +0.66*A34&
AGGFYS = +0.87*Agg +0.49*AGGFYS&
AGGPSY = +0.60*Agg +0.80*AGGPSY&
AGGFRU = +0.52*Agg -0.22*Self +0.81*AGGFRU&
TDISC = +0.59*Tcomp +0.81*TDISC&
TSOCC = +0.86*Tcomp +0.50*TSOCC&
TTEACH = +0.74*Tcomp +0.67*TTEACH&
TINDI = +0.70*Tcomp +0.72*TINDI&
TPOSS = +0.80*Tcomp +0.60*TPOSS&
TFAIR = +0.78*Tcomp +0.62*TFAIR&
TKNOW = +0.66*Tcomp +0.75*TKNOW&
S21 = +0.65*Self +0.76*S21&
S23 = +0.86*Self +0.51*S23&
S29 = +0.85*Self +0.52*S29&
S30 = +0.17*Agg +0.78*Self +0.61*S30&
Cov(Atti,Tcomp) = 0.75 Cov(Self,Tcomp) = 0.43 Cov(Self,Atti) = 0.56 Cov(TTEACH&,A33&) = 0.13 Cov(TINDI&,A33&) = 0.09 Cov(TINDI&,TTEACH&) = 0.12 Cov(TKNOW&,TDISC&) = 0.18
© Horst Löfgren 35
Nu kommer frågan om dessa förändringar kan anses vara logiska och där-med tillåtna eller om ändringarna bör fungera som hypotes för en ny stu-die? De två väsentliga förändringarna är att LISREL önskar en relation från den latenta variabeln självförtroende till den manifesta variabeln aggressionsfrustration och en relation från den latenta variabeln aggression till den manifesta variabeln S30, dvs. till påståendet ”Jag har ett gott själv-förtroende”. Kan det vara så att om man har lågt självförtroende så vågar man inte använda fysiskt och verbalt våld utan ger sig på annat i stället? Kan det vara så att man bygger upp sitt självförtroende genom att vara aggressiv? Det finns enligt modellen en positiv relation mellan självförtro-ende och aggressivitet om än svag. Men om man har högre självförtrosjälvförtro-ende använder man sig mera sällan av frustrationsaggression. De föreslagna relationerna verkar högst rimliga. Analysen har så att säga gett ett extra bidrag som vore värt att fundera vidare på. Samtidigt är det fascinerande att dessa SEM-analyser kan upptäcka dessa speciella relationer, om det nu inte bara är en för långt driven modellanpassning till data. Hela utskriften återfinns i Bilaga 5.
3.2
Illustrerande exempel på hur man arbetar
med STREAMS
Ett ytterligare exempel från den undersökningen som användes i avsnitt 3.1 ges nedan. I detta exempel har ytterligare en exogen variabel tagits med, nämligen kön samt ytterligare en endogen latent variabel som be-nämns ”Komp” och som står för ett mer kompromiss- och förhandlingsin-riktat reaktionssätt. Ett sådant reaktionssätt är självfallet negativt relaterat till ett aggressivt reaktionssätt i konfliktsituationer.
Man kunde också ha gjort en modell för pojkar och flickor separat i samma analys för att studera eventuella skillnader. Dock har vi här valt att använda könsvariabeln som en manifest variabel i modellen. I detta exem-pel visas steg för steg hur man i Streams bygger upp den modell som ska analyseras.
36 © Horst Löfgren
STREAMS utvecklades för Windows XP och finns ännu inte (våren 2014) för direkt användning i Windows 7. Dock finns i senare versioner av Windows 7 en kompabilitetsfunktion som gör att programmet kan köras precis som under Windows XP. Man installerar STREAMS som vanligt, men innan man börjar köra går man till STREAMS-mappen och högerk-lickar på ikonen för STREAMS-programmet (dvs. filen Streams.exe) och väljer ”Egenskaper”. Här väljer man fliken Kompabilitet, där man marke-rar rutan märkt ”Kör detta program i kompabilitetsläge för Windows XP (Servicepack 3)”. Därefter trycker man OK, och sedan går det att köra STREAMS som vanligt.
Starta genom att öppna programmet Streams. Ta bort den senast ge-nomförda analysen som automatiskt kommer upp och öppna ett nytt pro-jekt! Klicka på New!
Då öppnar sig nedanstående bild och man ger projektet ett namn och skriver in en beskrivning av vad projektet innehåller.
© Horst Löfgren 37
Därefter anges om man importerar en extern matris, importerar rådata eller be-räknar och importerar matriser.
38 © Horst Löfgren
Efter att ha klickat ’Next’ väljer man vilken matris som ska beräknas.
Efter ’Next’ ges förslag till namn på mapp och namn på data som ska analyse-ras. Det går bra att använda dessa förslag eller skriva in egna beteckningar.
© Horst Löfgren 39
I detta fall används en SPSS-fil med 26 variabler med beteckningen ’drac8streams.sav’. Spara gärna datafiler direkt under mappen ’Streams’.
40 © Horst Löfgren
Efter att ha klickat ’Next’ igen, ska man välja vilka variabler som ska ingå i analysen. Markera och för över variablerna till höger.
Innan man beräknar matrisen måste man acceptera förslaget att använda sig av en komplett datamatris (Listwise deletion) eller om man vill skatta bortfallsvär-den. Bäst är alltid om man har kompletta data.
© Horst Löfgren 41
Efter att ha tryckt ’Finish’ beräknas den matris som ska analyseras. Efter en kort stund är matrisen beräknas och en bild öppnar sig. Nu ska man välja en tidigare modell eller bygga upp en ny modell. Klicka på ’Models’ och därefter ’New model’.
På den bild som nu visas klickar man ’Model’ och den modell som ska byggas upp specificeras. Allteftersom man anger modellen byggs den upp på nedanstå-ende grund. Observera att här ska data analyseras med LISREL. Om man öns-kar andra program för analysen, kan man välja den metod man vill använda.
Observera att man måste etablera kontakt mellan STREAMS och det ana-lysprogram som ska användas. Anaana-lysprogrammet måste självfallet vara instal-lerat på datorn. Om man klickar i rutan under Run så öppnar sig olika möjlig-heter att välja analysprogram. Man väljer det analysprogram som finns installe-rat och klickar för dess exe-fil (t.ex. lisrel85.exe). Nu öppnas kontakten med analysprogrammet och man kan gå vidare.
42 © Horst Löfgren
Man benämner modellen, t.ex. model1 och gör en kort beskrivning.
Nu anges modelltyp, i det här fallet ’One-group model’ eller om det ska vara en tvånivås-analys. Om det är en engruppsmodell är allt redan förmarkerat.
© Horst Löfgren 43
I vissa fall anges startvärden från tidigare modeller. Matristyp är redan angiven som kovariansmatris (andra alternativ finns). Om man vill jämföra med en tidigare modell anges denna. Efter att ha klickat OK byggs mo-dellen upp steg för steg. Förinställt är skattningsmetoden ’Maximum likeli-hood’, men det går bra att använda annan skattningsmetod.
44 © Horst Löfgren
Nu klickas ’Options’ och man väljer vad man vill ha i sin LISREL-utskrift.
Nu ska data anges. Klicka på ’NewData’ och för över till höger.
I nästa bild som kommer upp ska de variabler som ska analyseras markeras och föras över. I detta exempel används samtliga variabler.
© Horst Löfgren 45
Nu byggs modellen vidare med att ange de latenta variablerna. Därefter klickas ’Rel’ och relationerna mellan de latenta variablerna och de manifesta, dvs. vilka manifesta variabler som förklaras av de latenta.
46 © Horst Löfgren
Efter att ha angett alla relationer, även mellan de latenta variablerna erhålls nedanstående modell. Den ska kompletteras med att de tre latenta exogena variablerna är korrelerade och likaså de två latenta endogena.
Nu är det dags att klicka Run för att utföra analysen. Efter några sekunder erhålls resultatet i form av olika utskriftsfiler.
Med några ytterligare några smärre justeringar blir modellen följande: Model Building Language Statements
**************************************************** * TI Draconmodell
* MO PR=Nytt NAME=model1
* MO Create instructions for: LISREL Y-model Ma-trix: CM
* MO Means included in model One-group model * MO LISREL DOS/Extender 8.50
* OP OU ME=ML AD=OFF MI
* DAT FOLDER=NewFold DATLAB=NewData
* MVR GENDER TDISC TSOCC TTEACH TINDI TPOSS TFAIR TKNOW S21 S23 S29 S30 A25 A31 A33 A34 AGGFYS AGGPSY AGGFRU KOMP1 KOMP2
* LVR Tcomp Self Atti Agg Komp
* REL Tcomp -> TDISC TSOCC TTEACH TINDI TPOSS TFAIR TKNOW
* REL Self -> S21 S23 S29 S30 * REL Atti -> A25 A31 A33 A34 * REL Agg -> AGGFYS AGGPSY AGGFRU * REL Komp -> KOMP1 KOMP2
© Horst Löfgren 47 * REL Tcomp Atti -> Agg
* REL Tcomp Self -> Komp * REL GENDER -> Agg Komp Self * REL GENDER -> AGGFRU
* REL Agg -> S30 * COV Tcomp Self Atti * COV Agg Komp
* COV TKNOW& TDISC&
Efter att ha kört denna modell erhålls följande meddelande från LISREL:
Message from LISREL:
Number of Iterations = 22 Goodness of Fit Test:
Chi-square = 317.56, df = 176, p < .00, RMSEA = .040 Den erhållna modellen stämmer således väl med data. Utskriften återfinns i sin helhet i Bilaga 6.
Figur 3.2 Resultat av LISREL-analys (N=551; Chi-kvadrat=317,56; RMSEA=0,04)
48 © Horst Löfgren
Som framgår av resultatet finns det påtagliga skillnader mellan pojkar och flickor hur de reagerar i konfliktsituationer. Pojkar reagerar mer aggressivt vid konflikter, medan flickor är mer benägna att använda kompromiss- och förhandlingslösningar. Om flickor reagerar aggressivt, är det i form av frustration, dvs. ett aggressivt beteende som inte direkt är i form av våld mot person. Pojkar uppger sig ha högre självförtroende i jämförelse med flickor, vilket är ett vanligt resultat.
Ju mer kompetent läraren är enligt eleverna desto färre aggressiva re-aktioner och desto oftare används kompromiss- och förhandlingslösningar. Positiva attityder till skolan och skolarbetet leder till färre aggressiva re-aktioner, och ju högre självförtroende eleverna har desto mera av kom-promiss- och förhandlingslösningar. Den orsaksrelation som finns mellan den latenta variabeln Aggression och den manifesta variabeln S30 (som lyder ”Jag har ett gott självförtroende”) antyder, att elever kan bygga upp sitt självförtroende genom att reagera aggressivt i konfliktsituationer. Den totala effekten från Lärarkompetens till Aggression blir -0,28 och till Kompromiss/förhandlingsinriktad 0,39, dvs. ganska påtagliga effekter. Kön visar än mer markanta effekter, nämligen 0,53 respektive 0.43. Från Självförtroende är den totala effekten 0,24 på det mer positiva sättet att reagera i konfliktsituationer, dvs. kompromiss och förhandlingsinriktat. De totala effekterna erhålls direkt i utskriften från LISREL.