V¨
aster˚
as, Sweden
DVA331 Thesis for the Degree of Bachelor in Computer Science
CASE REPRESENTATION
METHODOLOGY FOR A SCALABLE
CASE-BASED REASONING
Carl Larsson
cln14008@student.mdh.se
Examiner: Shahina Begum
Supervisor: Shaibal Barua
Abstract
Case-Based Reasoning (CBR) is an Artificial Intelligence (AI) methodology and a growing field of research. CBR uses past experiences to help solve new problems the system faces. To do so CBR is comprised of a few core parts, such as case representation, case library, case retrieval, and case adaptation. This thesis will focus on the case representation aspect of CBR systems and presents a scalable case representation for big data environments. One aspect of focus on big data environments is also the focus of a MapReduce environment. MapReduce is a software framework enabling the use of a Map and Reduce function to be executed over a network cluster.
This thesis conducts a systematic literature review to gain an understanding of the current case representations used in various CBR systems. The systematic literature review presents two major types of case representations, hierarchical and vector-based representations. However, the review also finds that the field of case representation research to be lacking. Most papers were focused on other aspects of CBR systems, mainly case retrieval.
This thesis also proposes the design of a scalable and distributed case representation. The proposed case representation is of a hierarchical nature and is designed in such a way that it can utilize a MapReduce environment for working with the case library in components such as case retrieval. In the proof of concept, part of the case representation was implemented and tested using two data-sets. One data-set contains EEG sensor data measuring sleepiness while the other contains information about employees health and time taken off work. These tests show the case representation adequately representing the respective data-sets.
The strength of the proposed case representation method is further discussed using a cross of papers. These papers cover the use of XML structured data in both CBR and MapReduce showing how this case representation is suitable for both uses. This shows strong capabilities of the case representation being further implemented and the addition of a case retrieval method to utilize it.
Table of Contents
1 Introduction 4 2 Problem Formulation 4 2.1 Research Questions . . . 5 2.2 Motivation . . . 5 2.3 Outcome . . . 5 3 Background 5 3.1 Case-Based Reasoning . . . 5 3.1.1 Case Representation . . . 5 3.1.2 Case Retrieval . . . 6 3.1.3 Case Maintenance . . . 6 3.2 MapReduce . . . 74 Method and Approach 7 4.1 Systematic Literature Review . . . 7
4.1.1 Preparation . . . 7
4.1.2 Search Queries . . . 8
4.1.3 Databases . . . 8
4.1.4 Paper Collection . . . 9
4.1.5 Paper Evaluation . . . 10
4.2 Proposed Case Representation Method . . . 10
5 Results 11 5.1 Systematic Literary Review . . . 11
5.1.1 Hierarchic Representations . . . 12
5.1.2 Vector Representations . . . 13
5.1.3 Case Representation Summary . . . 13
5.1.4 Case Library Structures . . . 14
5.2 Implementation . . . 14 5.2.1 Ethical Considerations . . . 15 6 Discussion 15 7 Conclusions 16 8 Future Work 17 References 21 Appendix A Appendix 22 A.1 Search Queries . . . 22
List of Figures
1 Visual representation of the CBR process. . . 6
2 Visual representation of MapReduce. . . 7
3 Folder Structure. . . 9
4 Visualization of the Case Library. . . 10
5 Example of the XML case file. . . 11
6 Example of a hierarchical case structure . . . 12
7 Example of a vector case representation . . . 13
8 Example of EEG data-set case representation. . . 14
1
Introduction
Big data is an ever-increasing field in multiple research fields that can be used for a multitude of goals. Big Data is the result of how almost all information recorded today is stored digitally. This creates situations where data libraries can be extremely large. The type of data being stored can also be classified into three different categories [1]. Structured data such as a database where all the data is in tables governed by columns and rows. Semi-structured data has some resemblance of structure where the data doesn’t follow strict rules such as HTML pages. Unstructured data is data such as log files or text files such as PDFs or E-Mail. These different types of data each have strength and weaknesses. Structured data, while being very organized, incurs a large overhead maintaining the structure. With unstructured data being the opposite, having potentially lower overhead but is unorganized. Systems can even be mixed with different types of data if it operated based on numerous data sources. What sets apart big data from traditional data libraries is the sheer volume of data. This leads them to be very well suited for parallelization, as traditional methods of traversing data would be too slow [2]. This makes them a great data source to use for cluster computing models that take advantage of dividing the workload.
Artificial intelligences (AI) are very promising technologies that could potentially be efficient at handling these large data-sets. Building AI that can handle this data is a challenge however and there are many different types of AI that all have strengths and weaknesses. This thesis will explore the use of Case-Based Reasoning (CBR) an artificial intelligence methodology that uses past experiences to solve new problems. This resembles how a human would solve problems by using past experiences to help understand new problems. These experiences are stored as cases in CBR systems. How these cases are represented is very important to the efficiency of the system as they must be formatted in such a way that they resemble the problems they will be used to solve. This is one of the major components of creating a reliable and efficient CBR system. The other major components of a CBR system are its case retrieval method and the method of case maintenance. Case retrieval is the process of finding cases within the case library that would be beneficial in the attempt to solve the problem the system is facing. While case maintenance makes sure the case library only contains cases beneficial to the system to ensure only quality cases are stored.
Case representations come in many forms as any way of representing data can be considered a case representation. However, they can be divided into two types of representations based on what type of information is stored in the case. Cases containing information about not only its data but also information about the case library such as similar cases are classified as ontological representations. Meanwhile, if the case is simpler and only contains information about itself it is classified as a traditional representation. These both have their respective strength and weaknesses. Targeting something like heterogeneous-data would be far too ambitious for this thesis. There-fore the choice to selectively limit the thesis scope to numerical attribute-value data was made. Attribute-value was chosen as it is a widely used data model within CBR [3,4,5,6].
This thesis will investigate numerical attribute-value case representation for scalable and dis-tributed CBR systems. This is important because CBR systems often use a consistent data source that is under control. This thesis, however, will investigate case representations for CBR sys-tems where the data comes from multiple sources. These diverse data sources simulate a big data environment where scalability is important. The investigation will be conducted by performing a systematic literature review of case representations. This review is needed as it will provide information about various case representations used in different CBR environments. With the systematic nature of this review more concrete views of the research field can be created. Together with the results of the review, a method for case representation suitable for scalability and dis-tribution will be presented as well as being implemented as a proof of concept in a MapReduce environment. This thesis will explore the design of a scalable and distributed case representation and its role in expanding CBR into a big data environment.
2
Problem Formulation
The goal of this thesis is to investigate how a CBR system potentially can scale to accommodate numerical data using an attribute-value case representation. As well as the evaluation of a chosen
representation using Hadoop MapReduce.
2.1
Research Questions
• What types of case representations are currently prominent in CBR systems?
• How could a chosen method of case representation be adapted for scalability using attribute-value data?
2.2
Motivation
Finding case representations that would allow CBR systems to function in a scalable fashion over a distributed system found in environments to support the 3Vs of big data (volume, variety, and velocity) [7]. This would allow CBR systems to use vast data-sets to create even better cases for solving multiple types of problems.
2.3
Outcome
The goals of this thesis are:
• A systematic literature review of case representations in CBR systems.
• Proof of concept evaluating a chosen case representation method in a MapReduce environ-ment.
3
Background
This section will describe the necessary information about the major components of this thesis.
3.1
Case-Based Reasoning
Case-based reasoning (CBR) is a type of artificial intelligence methodology where knowledge is stored as a case [8]. These cases are usually formed as having a problem and a solution. This allows a CBR system to utilize past experiences to solve a new problem. This mimics the way a human would solve new a problem by remembering old situations and applying that knowledge to help troubleshoot and solve a new problem. This differentiates CBR from other reasoning such as databases and logic as CBR does not lead from a true assumption to a true conclusion. This is because past cases may have been solutions to their problems does not mean they will necessarily be a complete solution to a new problem. For stored cases to be of use they only have to be similar to a new problem to help provide the means to create a new solution. However, not all cases stored in a system must be positive experiences as negative cases create insight into what not to do. This is different from having cases with errors in them as negative experience still holds vital information to solving new problems. The CBR cycle is a way to describe the fundamental steps of a CBR system [9]. This cycle is illustrated in Figure1. When a new problem is received, the information received is used to retrieve cases with similar conditions. With the help of old cases, a solution is presented and evaluated. The result is then either stored as a new case together with the information about the problem that led to it, or an existing case is updated to reflect the new knowledge gained.
In the following subsections the major parts of CBR that relate to this thesis will be described in more detail such as different types of case representation and retrieval methods.
3.1.1 Case Representation
The representation of cases is of high importance as they must be formed in such a way that is suited for the problems the system would be facing. Since not all problems encountered by a CBR system would be exactly the same the system would have to be able to find and compare similar cases. These could then lead to creating a new solution for the problem that was solved.
Cases can be represented in a multitude of ways such as object-oriented representations or tree representations [10]. These are more traditional ways of representation that are based on more known concepts; however, any way that can represent an action and its consequence can be used to define a case. Cases can however be divided into major categorizations, traditional and ontological methods [11]. Where traditional representations lack cohesive information of the case library, ontological representations have ways to relate cases together. Both have their strengths and weaknesses as ontological representations create an overhead in maintaining the relations between cases. This can be for example be that cases include references to similar cases which then can be used to create clusters of similar cases. This creates a problem when say a case is removed or edited and all its references have to be updated. Traditional representations, on the other hand, have very little overhead. Usually, traditional cases will not contain more than information about the case such as variables and the solution. This makes managing the case library simpler yet potentially putting more strain on the retrieval method. Which type of representation is optimal for a system is decided by a combination of the type of retrieval method used and structure/size of the case library.
Figure 1: Visual representation of the CBR process. [9]
3.1.2 Case Retrieval
Case retrieval is the way a CBR system finds cases needed to solve a particle problem [12]. While it may seem similar to the way database queries function they are very much not alike. This is because unlike a database CBR systems usually will not have a case that perfectly matches a given problem. This means that the retrieval method has to find similar cases to the problem it is facing. This introduces some problems however since the information in the query has to somehow match the information in the cases. This shows the complexity and importance of retrieval methods.
While simple methods such as liner searches and filtering do work they however do not scale particularly well with larger case libraries. For example, searching utilizing index’s could introduces problems as it may return no results or too many results. As such, a popular type of method used to retrieve cases is the use of the k-nearest-neighbor algorithm (k-NN) [13]. Other methods include the use of other AIs to find suitable cases, such as genetic algorithms [14].
3.1.3 Case Maintenance
Maintenance of a CBR systems case library is important to keep the system efficient [15]. Retrieval algorithms such as k-NN are sequential in nature and thus become more time-consuming in larger case libraries [16]. This can be alleviated by having the CBR system intelligently managing its case library [17]. Instead of adding new cases for every problem solved, it can instead alter cases
already present in the library. Additionally, the system can combine similar cases into one case to reduce the number of cases in the library. While the maintenance of the case library is important certain structures and case retrieval methods rely on it more than others.
3.2
MapReduce
MapReduce is a software framework meant to enable writing programs that take advantage of large clusters of nodes to processes large amounts of data [18]. MapReduce based on the map and reduce (otherwise known as fold) functions commonly found in functional programming. It works by using a map function to processes a key/value pair which then generates a set of intermediate key/value pairs [19]. These intermediate key/value pairs are then used in a reduce function that merges all the values associated with their key. This is what allows the process to be run in parallel. Each node processes its own part of the map function on the data it receives. The results are then distributed again to apply the reduce (fold) function. This produces the results requested. So as its name implies the Reduce function is always performed after the map function. This process can be seen in Figure2.
Figure 2: Visual representation of MapReduce. [19]
4
Method and Approach
This section will describe both the systematic literature review and the chosen case representation method. Sub-section 4.1 will describe the systematic literature review process and the choices made in data collection. While4.2describes the design of the case representation method.
4.1
Systematic Literature Review
This thesis conducted a systematic literature review following an informational paper by Kitchen-ham and Charters [20]. This papers method was chosen as it was the most thorough explanation of each step of the systematic literature review process. Other papers such as ”Performing Systematic Literature Reviews in Software Engineering” by Budgen and Brereton present the same structure but explain very little about the kind of work done during each step [21]. While still providing somewhat useful information it is not enough to properly perform a systematic literature review. 4.1.1 Preparation
As the name entails systematic literature reviews are a method of systematically reviewing litera-ture in and around a subject to gain insight into the current state of a given field and its potential future. This can bring light to underdeveloped areas of research for possible future research. It can also be used as a tool to detect trends and speculate about the future of a topic. The goal of this review is to create an overview of the current state of case representations in CBR. Hopefully, it will grant insight into scalable case representations in CBR systems and how they function. The method of representation that seems potentially best suited to be scalable and distributed will be selected as a proof of concept that satisfies the 3Vs of big data. In the following paragraphs the systematic approach to assembling research papers will be presented.
Before the process of obtaining papers could begin a set of questions were created to help steer what information is looking to be extracted from the papers. These were questions that help create
a consistent view of the topic designed to keep the review focused. The questions for each paper include:
• What types of data are represented in cases? • How are cases created in different systems? • How are cases stored in different systems?
• Is the case representation traditional or ontological? • Does it support a distributed approach and scalability?
These questions help guide the documentation of the review to keep the findings from the papers consistent. Since papers that do not focus on attribute-value data in cases were also considered it was important to be able to distinguish them, as they may still be useful. The creation of a systems case library is very interesting for this review since the goal is to implement a scalable representation that can be used in a Hadoop MapReduce environment. This means that the case creation process will be parallelized, and the method chosen for the proof of concept will have to work in such an environment.
Together with the questions for individual papers, a set of grander questions for the review can be made. These were questions posed specifically for this review and serve to create results. The main questions posed in the review were:
• What are the commonalities between case representations?
• What case representation could potentially be used in a scalable environment?
They also serve to create an understanding of common case representations and their classifications. This will aid in creating a meaningful overview of the subject of case representation in CBR system. 4.1.2 Search Queries
The next step is to formalize search queries that could be used across all potential databases. These queries were based on a combination of keywords that would hopefully return papers relevant to the topic of case representation. Logical mixes of the keywords were made to form search queries. All the queries were based on the use of ”Case-Based Reasoning”, ”Case Representation” and ”Case Retrieval”, with the abbreviation ”CBR” also being used. These were either used by themselves or paired, often with terms such as ”MapReduce” and ”Big Data”. The list of all queries can be found inA.1.
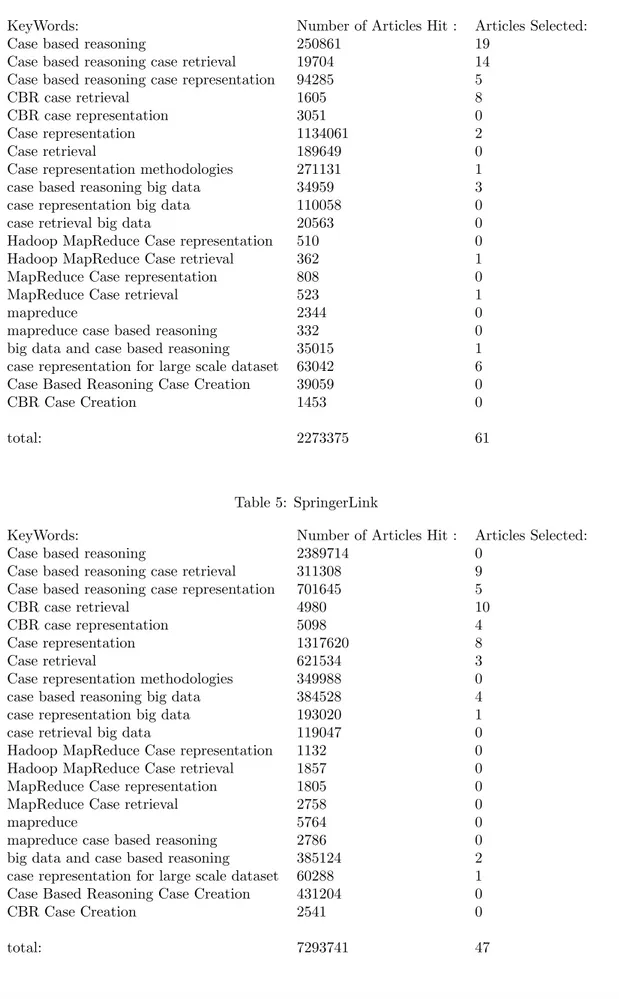
The most beneficial keywords were ”Case Retrieval” providing roughly 44% of papers as seen in A.2. Case retrieval is not the area of CBR being investigated by this thesis, however it is still beneficial. Papers concerning retrieval were considered since they may contain information about their respective case representations. Meanwhile the keywords ”Case Representation” only accounted for roughly 25% of papers as seen in A.2. These stats show where CBR research is focused and the need for more development in the study of case representation.
4.1.3 Databases
The databases selected for this review were chosen because they include papers from journals that focus on large-scale computer science topics such as AI, which this thesis is aimed at. The chosen databases were:
• IEEE Xplorer • SpringerLink • ScienceDirect
Each of the databases had different ways of presenting search results for each of the queries. This resulted in the search for ”Case-Based Reasoning” being the second most beneficial individual search query after ”Case Retrieval” for the number of papers found as can be seen inA.2. The reason seems to be that while the search term was meant to try and find papers that were about CBR but would be excluded from other searches. That was the case in IEEE Xplorer whose search method tries to find exact matches. The search results from IEEE were generally highly specific to the search query with relatively little irrelevant papers. However, ScienceDirect and SpringerLink respective search methods return papers with any possible connection to the search query. This resulted in papers returning multiple times in different search queries, leading to large amounts of overlap in searches. Since papers were saved according to the first query they were returned by, some papers better suited filed under more specific queries were saved as ”Case-Based Reasoning”. This by no means limited the number of papers selected, only that they could not be accurately be categorized. This could be solved by using general search terms such as ”Case-Based Reasoning” last to potentially catch missed papers. However, the categorization of search terms is a not a strict requirement in this review.
4.1.4 Paper Collection
The method to collect papers from each database was created to keep track of each paper and its origin. To do so each database is handled individually. All the search queries were entered sequentially and its results were explored. As mentioned in 4.1.3, the databases search methods returned large amounts of papers with only the first results being relevant to the query. Exploring every page of results for all queries across all databases would take an inefficiently large amount of time. To properly explore each query and collect its relevant papers the search results were explored until the key-words no longer appeared in the papers. For example, papers that include the word ”reasoning” would appear but not be relevant to CBR. This resulted in searches such as ”case based reasoning case representation” on SpringerLink returning over 700,000 papers across 36,000 pages. As such only the first pages of results were often relevant to the search query. This means that the later result pages were not taken into consideration as they were deemed irrelevant to the review. The result is the ability to only include papers with ties to the key-words while excluding the irrelevant papers returned by certain databases search functions.
The inclusion/exclusion criteria for this thesis were based upon answering the review questions posed in4.1.1. The criteria for the selection of papers is as follows:
• The paper must be in English. • Some relation to the subject CBR.
• Area of the papers focus utilizes a case representation.
• Diverse papers about different fields of applications for CBR systems.
The review does not contain a limit on publishing year as older papers may still provide insight into applications of CBR and their case representations. These criteria also ensure that the collection of papers is focused and as such only selects papers that were potentially relevant to the review.
The papers that were selected were saved and placed into a folder hierarchy. This hierarchy is based on the database and query used to select the paper, as can be seen in Figure3. This assists in the organization of the papers as well as providing meaningful documentation of the search query results.
4.1.5 Paper Evaluation
To fully read and comprehend each of the 190 papers found would be wasted effort as not all papers can be expected to contain information relevant to this review. Papers were instead skimmed and special attention was only directed towards papers that seemed to contain beneficial information. The papers were evaluated depending on the review questions discussed in4.1.1. So papers that included information about the structure of its case representation or case library were the target. To document the findings a text file was created broken into the same structure as the one used for the file hierarchy. This document contains the documentation for the review of the papers. When a paper containing information relevant to the review it was summarized in the document. In the end, this document contains a structured overview of all the relevant papers and their contents. From this data, an understanding of the current situation of case representations and the similarities and differences between representation methods can be built. The method that seems most viable will be selected to be implemented in a Hadoop MapReduce environment as a proof of concept. This proof of concept will help solidify the findings of the systematic literature review. The proof of concept will also serve as a base for further development of scalable case representations for CBR systems.
4.2
Proposed Case Representation Method
This section will describe the case representation method created for the proof of concept. Parts of the case library were also created to further support the cases themselves and help showcase the representations strengths.
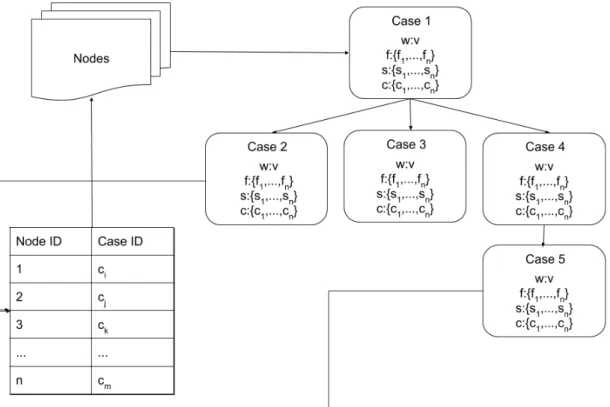
Based partly on the results of the systematic literature review a hierarchical case representation for the proof of concept was chosen to be implemented. This proof of concept had to be able to both contain the necessary information for a CBR system and store cases in such a way that they can work in a MapReduce environment. Figure4shows a visual representation of the case library structure. The design of the case library was inspired by the indexing structure in [22].
Figure 4: Visualization of the Case Library.
These nodes allow the case library to be distributed as the nodes are independent of each other. The nodes act as a container for a set amount of cases. This assist in the distribution of the case library which is further beneficial due to the nature of MapReduce.
The cases themselves within the nodes contains its information as well as a list of references to other similar cases to itself. This similarity is decided by a similarity function created to compare two cases. Case weight (w) is calculated by the number of cases that a given case appears in. The more frequent a case is referenced in other cases it is assigned a greater weight value. Cases that do not appear in other cases are punished with negative values. The similarity between cases depends on the data being represented and how it can be compared.
The cases also contain information about the case it is representing as well which is split into features (f) and solution (s). The features describe the case while the solution contains information about the solution to the problem the case is representing. Lastly, the cases also contain a list of similar cases (c) which contain a select amount of cases that are similar to the given case.
The case library also contains an indexing table that stores information about the location of each case in its corresponding node. This table assists in the retrieval of specific cases when needed. This indexing table can be created using different indexing methods such as similarity join tree (SJT) [23].
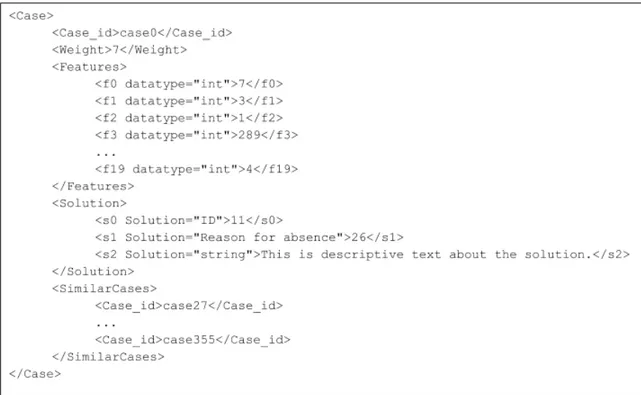
The distributed nature of this case library and the structure of the cases lend themselves well to storing cases in a markup language such as Extensible Markup Language (XML) [24]. An example of the XML case representation can be seen in Figure5. This format can be of assistance as it is human readable.
Figure 5: Example of the XML case file.
5
Results
This section will describe the results of the systematic literature review and the case representations methods found, as well as the proof of concept of the selected case representation method.
5.1
Systematic Literary Review
The papers and their respective case representation methods were selected based on the review questions outlined in4.1.1. Table1contains the total number of papers returned by each keyword. The most observed structuring of case representation methods have been group together. This grouping will assist in creating an understanding of these popular case representation methods and their uses.
Table 1: Total papers returned by each search keyword
Key-Words: Number of Articles Hit : Articles Selected:
Case Based Reasoning 2647532 40
Case Based Reasoning Case Retrieval 331595 43
Case Based Reasoning Case Representation 796628 16
CBR Case Retrieval 6839 26
CBR Case Representation 8270 6
Case Representation 2462991 19
Case Retrieval 816434 13
Case Representation Methodologies 621853 1
Case Based Reasoning Big Data 419570 9
Case Representation Big Data 303192 1
Case Retrieval Big Data 139721 0
Hadoop MapReduce Case Representation 1644 0
Hadoop MapReduce Case Retrieval 2222 2
MapReduce Case Representation 2616 0
MapReduce Case Retrieval 3292 1
MapReduce 11691 0
MapReduce Case Based Reasoning 3127 1
Big Data and Case Based Reasoning 420222 5
Case Representation for Large Scale Data Sets 123347 7
Case Based Reasoning Case Creation 470353 0
CBR Case Creation 4005 0
Total: 9597144 190
5.1.1 Hierarchic Representations
In environments that include a variety of different data that needs to be present in a case, certain similarities could be observed in the case representations. These representations are designed to have multiple layers within them to provide structure of the multitude of data being stored. These representations have different implementations yet can be visualized in a similar manner, as demonstrated in Figure6.
Figure 6: Example of a hierarchical case structure
In the paper [25] such a case representation is used to represent traffic accidents. This shows the representation being three layers deep. The upper two layers are structural and are only the case and the individual section headers. Each section of the case represents the third layer which contains the data.
The paper [26] presents a case representation to store drawings of electrical circuits. The cases uppermost layers are purely structural as they create very specific paths to drawings.
Moving on to the other papers representations becomes more complex. In the paper [27] the representation shifts to a more tree of nodes approach. This representation is presented with
two layers but can scale to accommodate any number of layers beyond that. Each node in the tree either contains data or is a category. As per their example ”Problem Description” points to ”System/processes” which in turn can point to a node like ”Operational or material flow”. This can then further be expanded into ”flow pattern” and ”flow control”, each of which includes their own data or further branches. This example helps to show the versatility of this particular representation.
Similarly, the representation used in the paper [28] is also versatile. This representation breaks down cases to fundamental data to pinpoint important information. These are referred to as com-plex attributes and simple attributes, where comcom-plex attributes are broken down into corresponding simple attributes.
Since the cases being presented are of a hierarchy nature object-oriented cases can be categorized as such as well. In the papers [29] and [30] an object-oriented approach is taken to the respective case representations. These representations practice inheritance for objects in the cases. They do however have similarities to the other representations presented above as the objects created are kept in line by a hierarchy. As for example (from [29]) an object ”Location” can have children such as ”Source” and ”Target” these children are then kept under the section ”Location”. 5.1.2 Vector Representations
These case representations are much simpler in nature than the hierarchic representations described above. Vector representations as can be seen in Figure7, are a flat representation consisting of a pair of vectors. One half contains a vector of data describing the case while the other half is the solution data. This makes the case representation itself very minimal but requires external knowledge of how the data is structured.
C = {x1...xn|y}.
Figure 7: Example of a vector case representation
In the paper [31] a vector is used as a case representation to represent the oxygen volume in basic oxygen furnaces. In this situation, the vector x contains information about the condition of the furnace and y is the volume of oxygen to blow.
The paper [32] uses a similar case representation. This paper presents a near identical case rep-resentation consisting of a vector with x representing a vector of variables describing the condition and y representing a single variable for the solution.
A slightly different use of this type of case representation can be found in the paper [33]. In this paper, the cases represent images using color values retrieved from images. The case representation is a pair of vectors expressed as ”imagecase(I,C)” where I is a vector containing the different color characteristics and C is the conclusions drawn from the data.
5.1.3 Case Representation Summary
In summary hierarchic representations are more robust and can be used in various ways to represent cases. This does however come at the cost of more overhead in maintaining the cases as the ontological nature of these representations contain internal links with the case library.
This does not mean that vector representations are completely without benefit as they excel in smaller focused systems. Since they do not require as much overhead as hierarchic representations they too have their uses. Table 2 shows a brief overview of the features inherent to each case representation methodology and the number of useful papers.
Vector Representations Hierarchic Representations
Simple Variable Complexity
Limited Overhead Multiple Data Types
Traditional Ontological
Number of papers: 3 Number of papers: 7 Table 2: Features of case representation methodologies
5.1.4 Case Library Structures
Throughout the process of reviewing case representations, the case libraries were also studied. The two most common library structures found were a flat library using indexing and a hierarchic library [34, 35]. These do not differ from one and other too much as they both rely on placement of the cases according to some sort of indexing. This indexing can be a solution type or a result of a weighting algorithm. The difference is just that hierarchic libraries as the name implies make use of layers. These methods are used to shorten the case retrieval process while accounting for the size of the case library.
Typical implementations of a hierarchic library used a markup language such as XML to create human-readable library structures [36]. This also allows the cases to be organized after some sort of metric. Contrary to this the flat case library structure was also popular as it is simpler and allows chunks to be loaded more efficiently. Though it does rely on the cases to be sorted by some metric.
Some CBR systems rely on commercial CBR tools that create and maintain a case library automatically for the user [37]. These systems offer the convenience of easily creating a CBR system in exchange for explicit control of the system.
5.2
Implementation
The proposed method was implemented as a proof of concept using different data-sets to show the viability of the case representation. These simple tests show how the case representation can easily represent most data-sets.
The case representation method proposed was tested using two data-sets. The first data-set was provided by the supervisor of this thesis [38]. The data-set contains EEG data from sleepiness tests as well as information about the test group and situation for the test. This data contains 275 features all being either integers or floats, these features represent the sensor data from the EEG recordings. The data-set itself also contains 4 values that are used in the solution portion of the case. As can be seen in the example in Figure8the case representation stores the data adequately.
The second data-set ”Absenteeism at work Data Set” contains data about how much time em-ployees take of work [39]. The data-set contains 20 features describing the persons living situation and health alongside the amount of time they take off. Two values were selected to be included in the solution portion as well. This data-set can also be represented in the case representation as seen in Figure9. As can be seen in both examples the primary sections of the case are its features and solution. The features are the raw data from the data-set while the solution can be either recorded data in the data-set or data created for the case itself. Both of the examples contain both information from the data-set about the case as well as a descriptive text that could have been added for further clarification in case it would be needed.
Figure 9: Example of absenteeism data-set case representation.
5.2.1 Ethical Considerations
The data used in this thesis is anonymous and is in part collected from public data repositories. As such the thesis does not have any ethical concerns regarding the data used.
6
Discussion
The systematic literature review proved to not yield much with regards to case representation methods in general. As was shown in Table1, there was a significant amount of papers returned by the search keywords used. This is mostly due to how the databases serve their respective query results, often finding some minimal way to relate a keyword to a paper. This is how some keywords would return a large number of papers with none of them being relevant. However, given the number of papers collected very little valuable information could be gained on the design of case representations themselves. Most of the papers collected were more focused on the retrieval aspect of CBR even the papers containing representation in their subject matter. This in conjunction with the few number of papers involving CBR and big data applications made it hard to narrow down case representation methods, especially for this topic. Case representation, while important, seems to not be a major focus in research as the CBR systems themselves were highly specialized with a narrow data-set. Most papers focused more on the retrieval method while barely stating
anything about their method of case representation. This thesis was focused on establishing a case representation that could accommodate a multitude of data-sets into one system operating in a big data environment. This does show that there is a vacant space for more research within the topic of more generalized CBR systems.
While the results may have been lacking to find existing case representation methods to select, the information that could be collected was useful in the creation of the case representation. The major problem faced was creating a representation that could both be used in a CBR system while also being stored in such a way that it would lend itself well to a MapReduce environment. The decentralized nature of the node based structure of the case library aids greatly in this. Since the goal is for the case representation to be usable by MapReduce the cases needed to be able to be distributed without disturbing the system.
While it would have been beneficial to test the case representation together with a retrieval method utilizing MapReduce one such method has not been implemented. Instead, the viability of the case representation can be shown using papers utilizing XML as data storage for both CBR and MapReduce. These papers [40, 41, 42, 43, 44, 45, 46] show CBR systems utilizing XML as their case representation and/or case library. These papers include CBR systems from fields such as finance, engineering and medical. However, these CBR implementations are highly specific to their use case. The case representation method proposed in this thesis could potentially extend the usability of these systems by providing the ability to work with multiple data sources. Furthermore, the use of XML as a data source for MapReduce procedures can be found in [47] [48]. Combining the use fullness of XML in CBR systems and its use fullness in MapReduce operations shows a clear use case for the proposed case representation.
The proposed case representation methods’ major strength is with its distributed nature. This would allow it to utilize MapReduce functionality for case retrieval potentially making the retrieval process much faster when working with large case libraries. The distributed nature also brings with it the ability to scale, as the library grows so could the network used for the system. This would potentially allow the system to keep its performance while still handling a growing case library. However, this is also a weakness as the maintenance of the case library can become complex because of the cases being distributed. Some method of case maintenance utilizing the retrieval method could be created to keep the library under control. The proposed method of using defined similarity functions to compare cases from different data-sets would allow the system to solve ever more complex problems. Being able to utilize many different data sources to create a single case library could show to be highly beneficial in complex environments.
7
Conclusions
In this thesis, a systematic literature review was performed to create a view of the current state of case representations and what they are capable of. The results of this review were used to create a proof of concept for a potentially distributed case representation for use in a MapReduce environment. While the systematic literature review failed to provide a satisfactory number of current case representations it did assist in the creation of our case representation method. The resulting proof of concept based on the case representation method could not be thoroughly tested as implementing a retrieval method to do so was outside of the scope of this thesis. The proof of concept does; however, show promise as the evaluation based on papers concerning the use of XML formatted cases in CBR and the use of XML as a data type for MapReduce was positive.
This thesis aimed to answer two research questions with the first being what types of case representations are currently prominent in CBR systems. The answer to this question was the result of the systematic literature review which showed that the two most prominent case representations were hierarchical and vector-based representations. While representations differed from one and another the general designs of these two types of case representations were the most common. Some other case representations did arise, however they were highly specific to their respective domains. Between the two representations hierarchical case representations were the most prominent. This shows that while an important part of CBR the case representations are often not the central point of research.
adapted for scalability using attribute-value data? Based on the proof of concept of the proposed case representation method the two selected data-sets could be adapted to the representation with ease. Even with these two different attribute-value data-sets the case representation could house the data. The case representation also shows promising results in the future based on the evaluation of its potential use in a CBR system and as input data in a MapReduce environment. The proposed case representation does have some limitations such as the lack of a full system for the case representation to reside within. This lead to the case representation not being tested with a full-fledged retrieval method. The cases themselves are also limited as only attribute-value data representation was testing, with other types of data not used due to the scope of the thesis. Much of the limitations to the case representation were due to the narrow scope of the thesis.
8
Future Work
Future work on this topic would be the implementation and testing of the case representation together with a case retrieval method. One such retrieval method is proposed in this paper [49] written in part by the thesis supervisor. The retrieval method works by utilizing the node structure of the case library to select the most relevant cases from the library. It takes into account the time and space complexity of the operations as to viable in a big data environment. This retrieval method utilizes MapReduce and its distributed nature allowing the process to be divided into clusters.
As brought up in the discussion a case library maintenance method would be highly beneficial to create as to make sure the case library keeps its efficacy when growing. This could be done by potentially using the case retrieval method to instead consolidate cases together.
In the end, this could lead to a full implementation of a CBR system that can utilize multiple data sources for the creation of its case library.
References
[1] S. Murugesan and I. Bojanova, An Introduction to Big Data. Wiley-IEEE Press, 2016, pp. 539–550. [Online]. Available: http://ieeexplore.ieee.org.ep.bib.mdh.se/xpl/articleDetails.jsp? arnumber=7493860
[2] D. Luo, C. Ding, and H. Huang, “Parallelization with multiplicative algorithms for big data mining,” in 2012 IEEE 12th International Conference on Data Mining, Dec 2012, pp. 489–498. [3] C. Lovis, A. Lamb, R. Baud, A.-M. Rassinoux, P. Fabry, and A. Geissbhler, “Clinical doc-uments: Attribute-values entity representation, context, page layout and communication,” AMIA Annual Symposium Proceedings, pp. 396–400, 2003.
[4] J. Lang and P. Skowron, “Multi-attribute proportional representation,” Artificial Intelligence, vol. 263, pp. 74–106, 2018.
[5] M. Maher and A. Gomez de Silva Garza, “Developing case-based reasoning for structural design,” IEEE Expert, vol. 11, no. 3, pp. 42–52, 1996.
[6] N. Stphane, R. Hector, and L. L. J. Marc, “Effective retrieval and new indexing method for case based reasoning: Application in chemical process design,” Engineering Applications of Artificial Intelligence, vol. 23, no. 6, pp. 880–894, 2010.
[7] J. Fan, F. Han, and H. Liu, “Challenges of big data analysis,” National Science Review, vol. 1, no. 2, pp. 293–314, 2014. [Online]. Available: http://dx.doi.org/10.1093/nsr/nwt032
[8] M. M. Richter and R. O. Weber, ”Introduction” in Case-Based Reasoning: A Textbook. Springer Berlin, 2013, pp. 3–15.
[9] A. Aamodt and E. Plaza, “Case-based reasoning: Foundational issues, methodological vari-ations, and system approaches,” Artificial Intelligence Communicvari-ations, vol. 7, pp. 39–59, 1994.
[10] M. M. Richter and R. O. Weber, ”Case Representations” in Case-Based Reasoning: A Text-book. Springer Berlin, 2013, pp. 87–111.
[11] S. H. and M. Elmogy, “Case based reasoning: Case representation methodologies,” Interna-tional Journal of Advanced Computer Science and Applications, vol. 6, no. 11, 2015.
[12] M. M. Richter and R. O. Weber, ”Retrieval” in Case-Based Reasoning: A Textbook. Springer Berlin, 2013, pp. 167–186.
[13] R. Mntaras, D. Bridge, and D. Mcsherry, “Retrieval in case-based reasoning: An overview,” 05 2018.
[14] J. Jarmulak, S. Craw, and R. Rowe, “Self-optimising cbr retrieval,” Proceedings 12th IEEE Internationals Conference on Tools with Artificial Intelligence. ICTAI 2000, 2000.
[15] M. M. Richter and R. O. Weber, ”Development and Maintenance” in Case-Based Reasoning: A Textbook. Springer Berlin, 2013, pp. 247–272.
[16] S. Zhong, X. Xie, and L. Lin, “Two-layer random forests model for case reuse in case-based reasoning,” Expert Systems with Applications, vol. 42, no. 24, pp. 9412 – 9425, 2015. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0957417415005448
[17] M. Salam and M. Lpez-Snchez, “Adaptive case-based reasoning using retention and forgetting strategies,” Knowledge-Based Systems, vol. 24, no. 2, pp. 230 – 247, 2011. [Online]. Available:
http://www.sciencedirect.com/science/article/pii/S0950705110001322
[18] J. Dean and S. Ghemawat, “Mapreduce,” Communications of the ACM, vol. 51, no. 1, p. 107, 2008.
[19] K. G. Srinivasa and A. K. Muppalla, Getting Started with Hadoop. Cham: Springer International Publishing, 2015, pp. 46–49. [Online]. Available: https://doi.org/10.1007/ 978-3-319-13497-0 2
[20] B. Kitchenham and S. Charters, “Guidelines for performing systematic literature reviews in software engineering,” 2007.
[21] D. Budgen and P. Brereton, “Performing systematic literature reviews in software engineering,” in Proceedings of the 28th International Conference on Software Engineering, ser. ICSE ’06. New York, NY, USA: ACM, 2006, pp. 1051–1052. [Online]. Available:
http://doi.acm.org.ep.bib.mdh.se/10.1145/1134285.1134500
[22] A. Rheinl¨ander and U. Leser, “Scalable sequence similarity search and join in main memory on multi-cores,” in Euro-Par 2011: Parallel Processing Workshops, M. Alexander, P. D’Ambra, A. Belloum, G. Bosilca, M. Cannataro, M. Danelutto, B. Di Martino, M. Gerndt, E. Jeannot, R. Namyst, J. Roman, S. L. Scott, J. L. Traff, G. Vall´ee, and J. Weidendorfer, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 13–22.
[23] W. Liu, Y. Shen, and P. Wang, “An efficient mapreduce algorithm for similarity join in metric spaces,” The Journal of Supercomputing, vol. 72, no. 3, pp. 1179–1200, Mar 2016. [Online]. Available: https://doi.org/10.1007/s11227-016-1651-9
[24] E. Asemota, S. Gallagher, G. Mcrobbie, and S. Cochran, “Defining case based reasoning cases with xml,” 07 2018.
[25] H. Zhang and G. Dai, “Research on traffic decision making method based on image analysis case based reasoning,” Optik, vol. 158, pp. 908 – 914, 2018. [Online]. Available:
http://www.sciencedirect.com/science/article/pii/S003040261830007X
[26] L. Lifeng, Z. Zhe, G. Zhongde, Y. Qixun, and L. Baizhen, “Research on case representation of case-based reasoning approaches for electric power engineering design,” in Power System Technology, 1998. Proceedings. POWERCON ’98. 1998 International Conference on, vol. 2, Aug 1998, pp. 968–970 vol.2.
[27] M. Zhou, Z. Chen, W. He, and X. Chen, “Representing and matching simulation cases: A case-based reasoning approach,” Computers & Industrial Engineering, vol. 59, no. 1, pp. 115 – 125, 2010. [Online]. Available: http://www.sciencedirect.com/science/article/pii/ S0360835210000793
[28] A. Abou Assali, D. Lenne, and B. Debray, “Case retrieval in ontology-based cbr systems,” in KI 2009: Advances in Artificial Intelligence, B. Mertsching, M. Hund, and Z. Aziz, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 564–571.
[29] R. Bergmann and A. Stahl, “Similarity measures for object-oriented case representations,” in Advances in Case-Based Reasoning, B. Smyth and P. Cunningham, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1998, pp. 25–36.
[30] Q. Quan, Z. Rui, and C. Hong-Yi, “Object-oriented case representation and its application in ids,” in 2009 Eighth IEEE/ACIS International Conference on Computer and Information Science, June 2009, pp. 301–306.
[31] X. Wang and J. Dong, “Fuzzy based similarity adjustment of case retrieval process in cbr system for bof oxygen volume control,” in 2013 Sixth International Conference on Advanced Computational Intelligence (ICACI), Oct 2013, pp. 130–134.
[32] S. Guo, T. Li, and K. Zhou, “An improved case retrieval method for the production manu-facturing process of aluminum electrolysis,” in 2017 International Conference on Industrial Informatics - Computing Technology, Intelligent Technology, Industrial Information Integra-tion (ICIICII), Dec 2017, pp. 16–20.
[33] L. Hongru, H. Xiaochen, and Z. Yubin, “Research on case representation method based on image information,” in 2013 Sixth International Symposium on Computational Intelligence and Design, vol. 1, Oct 2013, pp. 128–131.
[34] C. Kwong, G. Smith, and W. Lau, “Application of case based reasoning injection moulding,” Journal of Materials Processing Technology, vol. 63, no. 1, pp. 463 – 467, 1997. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0924013696026659
[35] F. Shang, G. Chen, J. Wang, and X. Wang, “Research on scalable case representation and its retrieval based on description logic,” in 2009 Second International Symposium on Knowledge Acquisition and Modeling, vol. 1, Nov 2009, pp. 316–318.
[36] I. Y. Lodhi, K. Hasan, U. Hasan, N. Mahmood, T. Yoshida, and M. A. Anwar, “Optimizing retrieval process and using neural networks for adaptation process in case based reasoning systems,” in 7th International Multi Topic Conference, 2003. INMIC 2003., Dec 2003, pp. 354–360.
[37] N. Dendani-hadiby and M. T. Khadir, “Comparative analysis of case retrieval implementation for knowledge intensive cbr application,” in 2014 International Conference on Multimedia Computing and Systems (ICMCS), April 2014, pp. 1107–1114.
[38] S. Barua, M. U. Ahmed, C. Ahlstrm, and S. Begum, “Automatic driver sleepiness detection using eeg, eog and contextual information,” Expert Systems with Applications, vol. 115, pp. 121 – 135, 2019. [Online]. Available: http://www.sciencedirect.com/science/article/pii/ S0957417418304792
[39] A. Martiniano, R. P. Ferreira, R. J. Sassi, and C. Affonso, “Application of a neuro fuzzy network in prediction of absenteeism at work,” in 7th Iberian Conference on Information Systems and Technologies (CISTI 2012), June 2012, pp. 1–4.
[40] T. Mao and B. Ma, “Case based reasoning applied in personal financing: Representing cases based on xml,” in 2010 International Conference on Product Service and E-Entertainment, Nov 2010, pp. 1–3.
[41] S. Guo, W. Zhou, and K. Li, “Multi-layer case-based reasoning approach of complex product system,” in 2012 Third World Congress on Software Engineering, Nov 2012, pp. 107–110. [42] H. Chorfi and M. Jemni, “Xml based cbr for adaptive educational hypermedia,” in Sixth
IEEE International Conference on Advanced Learning Technologies (ICALT’06), July 2006, pp. 1092–1096.
[43] F. Sartori, A. Mazzucchelli, and A. D. Gregorio, “Bankruptcy forecasting using case-based reasoning: The creperie approach,” Expert Systems with Applications, vol. 64, pp. 400 – 411, 2016. [Online]. Available: http://www.sciencedirect.com/science/article/pii/ S0957417416303803
[44] C. Hayes and P. Cunningham, “Shaping a cbr view with xml,” in Case-Based Reasoning Research and Development, K.-D. Althoff, R. Bergmann, and L. Branting, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1999, pp. 468–481.
[45] H. Shimazu, “A textual case-based reasoning system using xml on the world-wide web,” in Advances in Case-Based Reasoning, B. Smyth and P. Cunningham, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1998, pp. 274–285.
[46] F. Zhang and Z. M. Ma, “Representing and reasoning about xml with ontologies,” Applied Intelligence, vol. 40, no. 1, pp. 74–106, Jan 2014. [Online]. Available:
https://doi.org/10.1007/s10489-013-0446-4
[47] M. Zhou, H. Hu, and M. Zhou, “Searching xml data by slca on a mapreduce cluster,” in 2010 4th International Universal Communication Symposium, Oct 2010, pp. 84–89.
[48] K. Song, H. Lu, and X. Qin, “An efficient parallel approach of parsing and indexing for large-scale xml datasets,” in 2016 IEEE 22nd International Conference on Parallel and Distributed Systems (ICPADS), Dec 2016, pp. 184–191.
[49] S. Barua, S. Begum, and M. Uddin Ahmed, “Towards distributed k-nn similarity for scal-able case retrieval,” ICCBR 2018 26TH International Conference on Case-Based Reasoning, vol. 26, 2018.
A
Appendix
A.1
Search Queries
• Case Based Reasoning
• Case Based Reasoning Case Retrieval • Case Based Reasoning Case
Representa-tion
• Case Based Reasoning Big Data • Case Based Reasoning Case Creation • CBR Case Retrieval
• CBR Case Representation • CBR Case Creation • Case Representation • Case Retrieval
• Case Representation Methodologies
• Case Representation Big Data • Case Retrieval Big Data
• Hadoop MapReduce Case Representation • Hadoop MapReduce Case Retrieval • MapReduce Case Representation • MapReduce Case Retrieval • MapReduce
• MapReduce Case Based Reasoning • Big Data and Case Based Reasoning • Case Representation for Large Scale
Datasets
A.2
Papers Returned by Query
Table 3: IEEE Xplorer
KeyWords: Number of Articles Hit : Articles Selected:
Case based reasoning 6957 21
Case based reasoning case retrieval 583 20
Case based reasoning case representation 698 6
CBR case retrieval 254 8
CBR case representation 121 2
Case representation 11310 9
Case retrieval 5251 10
Case representation methodologies 734 0
case based reasoning big data 83 2
case representation big data 114 0
case retrieval big data 111 0
Hadoop MapReduce Case representation 2 0
Hadoop MapReduce Case retrieval 3 1
MapReduce Case representation 3 0
MapReduce Case retrieval 11 0
mapreduce 3583 0
mapreduce case based reasoning 9 1
big data and case based reasoning 83 2
case representation for large scale dataset 17 0
Case Based Reasoning Case Creation 90 0
CBR Case Creation 11 0
Table 4: ScienceDirect
KeyWords: Number of Articles Hit : Articles Selected:
Case based reasoning 250861 19
Case based reasoning case retrieval 19704 14 Case based reasoning case representation 94285 5
CBR case retrieval 1605 8
CBR case representation 3051 0
Case representation 1134061 2
Case retrieval 189649 0
Case representation methodologies 271131 1
case based reasoning big data 34959 3
case representation big data 110058 0
case retrieval big data 20563 0
Hadoop MapReduce Case representation 510 0
Hadoop MapReduce Case retrieval 362 1
MapReduce Case representation 808 0
MapReduce Case retrieval 523 1
mapreduce 2344 0
mapreduce case based reasoning 332 0
big data and case based reasoning 35015 1
case representation for large scale dataset 63042 6
Case Based Reasoning Case Creation 39059 0
CBR Case Creation 1453 0
total: 2273375 61
Table 5: SpringerLink
KeyWords: Number of Articles Hit : Articles Selected:
Case based reasoning 2389714 0
Case based reasoning case retrieval 311308 9 Case based reasoning case representation 701645 5
CBR case retrieval 4980 10
CBR case representation 5098 4
Case representation 1317620 8
Case retrieval 621534 3
Case representation methodologies 349988 0
case based reasoning big data 384528 4
case representation big data 193020 1
case retrieval big data 119047 0
Hadoop MapReduce Case representation 1132 0
Hadoop MapReduce Case retrieval 1857 0
MapReduce Case representation 1805 0
MapReduce Case retrieval 2758 0
mapreduce 5764 0
mapreduce case based reasoning 2786 0
big data and case based reasoning 385124 2
case representation for large scale dataset 60288 1 Case Based Reasoning Case Creation 431204 0
CBR Case Creation 2541 0
![Figure 1: Visual representation of the CBR process. [9]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4796763.128671/7.892.255.635.410.707/figure-visual-representation-cbr-process.webp)
![Figure 2: Visual representation of MapReduce. [19]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4796763.128671/8.892.138.754.429.559/figure-visual-representation-of-mapreduce.webp)