Institutionen för datavetenskap
Department of Computer and Information Science
Examensarbete
Identifiering av anomalier i COSMIC genom
analys av loggar
av
Muntaher Al-egli & Adham Zeidan Nasser
LIU-IDA/LITH-EX-G--15/028--SE
2015-10-27
Linköpings universitet SE-581 83 Linköping, Sweden
Linköpings universitet 581 83 Linköping
Linköpings universitet
Institutionen för datavetenskap
Identifiering av anomalier i COSMIC genom analys av loggar
av
Muntaher Al-egli & Adham Zeidan Nasser
2015-10-27
LIU-IDA/LITH-EX-G--15/028--SE
Handledare: Mattias Pettersson, Cambio AB Examinator: David Byers, Linköpings universitet
Datum Date 2015-10-27 ISBN _____________________________________________________ ISRN LIU-IDA/LITH-EX-G--15/028--SE _____________________________________
Serietitel och serienummer ISSN
Title of series, numbering ____________________________________
Rapporttyp Report category Licentiatavhandling Examensarbete C-uppsats D-uppsats Övrig rapport _ ________________
Titel: Identifiering av anomalier i COSMIC genom analys av loggar
Title: Identification of anomalies in COSMIC through log analysis
Författare: Muntaher Al-egli, Adham Zeidan Nasser
Author: Muntaher Al-egli, Adham Zeidan Nasser
Språk
Language
Svenska/Swedish Engelska/English
_ ________________
URL för elektronisk version
Sammanfattning
Loggar är en viktig del av alla system, det ger en inblick i vad som sker. Att analysera loggar och extrahera väsentlig information är en av de största trenderna nu inom IT-branchen. Informationen i loggar är värdefulla resurser som kan användas för att upptäcka anomalier och hantera dessa innan det drabbar användaren.
I detta examensarbete dyker vi in i grunderna för informationssökning och analysera undantagsutskrifter i loggar från COSMIC för att undersöka om det är möjligt att upptäcka anomalier med hjälp av retrospektivdata. Detta examensarbete ger även en inblick i möjligheten att visualisera data från loggar och erbjuda en kraftfull sökmotor. Därför kommer vi att fördjupa oss i de tre välkända program som adresserar frågorna i centraliserad loggning: Elasticsearch, Logstash och Kibana.
Sammanfattningsvis visar resultatet att det är möjligt att upptäckta anomalier genom att tillämpa statistiska metoder både på retrospektiv- och realtidsdata.
Abstract
Logs are an important part of any system; it provides an insight into what is happening. One of the biggest trends in the IT industry is analyzing logs and extracting essential information. The information in the logs are valuable resources that can be used to detect anomalies and manage them before it affects the user.
In this thesis we will dive into the basics of the information retrieval and analyze exceptions in the logs from COSMIC to investigate whether it is feasible to detect anomalies using retrospective data. This thesis also gives an insight into whether it’s possible to visualize data from logs and offer a powerful search engine. Therefore we will dive into the three well known applications that addresses the issues in centralized logging: Elasticsearch, Logstash and Kibana.
In summary, our results shows that it’s possible to detected anomalies by applying statistical methods on both in retrospective and real time data.
Nyckelord
Informationssökning, logghantering,realtidsövervakning, klassificering, normalisering, aggregering, korrelation, vektorrumsmodell, boolesk hämtningsmodell, Lucene, Elasticserach, Logstash, Kibana, databaser, COSMIC, Cambio, LIPS
Keywords
Information retrieval, log management,real-time monitoring, classification, normalization, aggregation, correlation, vector space model, Boolean retrieval, Lucene, Elasticsearch, Logstash, Kibana, database, COSMIC, Cambio, LIPS
Institutionen för datavetenskap
Förord
Examensarbete är utfört vid Linköpings universitet och i samarbete med Cambio AB i Linköping. Omfattningen av examensarbetet motsvarar 16 högskolepoäng som ingår i programmet för högskoleingenjör i datateknik, 180 högskolepoäng.
Arbetet har gett god insikt i den problematik som uppstår med logghantering i stora system.
Vi vill tacka alla på Cambio Healthcare Systems AB och framförallt vår handledare Mattias Pettersson för stöd, idéer och tankar kring arbetet. Vi vill även rikta ett speciellt tack till vår handledare och examinator vid Linköpings universitet, David Byers, för hans stöd och engagemang i detta examensarbete samt för god vägledning under arbetets gång.
Innehållsförteckning
1 Inledning ... 1 1.1 Bakgrund ... 1 1.1.1 Företagsbeskrivning ... 1 1.2 Uppgiftsbeskrivning ... 2 1.3 Cambio COSMIC ... 2 1.4 Frågeställningar ... 3 1.5 Rapportens uppbyggnad ... 3 1.6 Avgränsningar ... 32 Metod och genomförande ... 4
2.1 Arbetssätt ... 4
2.2 Konkretisering av arbetssätt ... 4
2.3 Enkätundersökning och urval av respondenter ... 5
2.3.1 Genomförande av enkätundersökningar... 5 2.3.2 Enkätfrågor ... 5 2.3.3 Sammanfattning av enkätundersökning ... 5 3 Teoretisk referensram ... 8 3.1 Insamling av data ... 8 3.1.1 Lösningar ... 9 3.1.1.1 Logstash ... 9 3.1.1.2 Fluentd ... 10 3.2 Systemdesign ... 10 3.3 Informationssökning... 12 3.3.1 Booleskhämtningsmodell ... 12
3.3.2 Stoppord och normalisering ... 15
3.3.4 Exempel ... 18 3.3.5 Lucene ... 22 3.3.6 Elasticsearch ... 23 3.3.6.1 Tillstånd ... 25 3.3.7 Presentation av data ... 25 3.4 Övervakning ... 26 3.4.1 Statistiska metoder ... 26 3.4.1.1 Statisk referenslinje ... 28 3.4.1.2 Dynamisk referenslinje ... 31 3.4.1.3 Korrelation ... 32
4 Analys och Resultat ... 34
4.1 Lärdata ... 34 4.1.1 Slutsatser ... 37 4.2 Utvärderingsdata ... 38 4.2.1 Slutsatser ... 42 4.3 Identifiering i realtid ... 44 5 Diskussion ... 47 6 Referenser ... 48 7 Appendix ... 50 7.1 Appendix 1 Dokumentsamling ... 50 7.2 Appendix 2 Enkätfrågor ... 51
1
1 Inledning
1.1 Bakgrund
När företag växer brukar vanligtvis deras system växa. I och med att systemen växer och blir allt mer komplicerade, blir det allt mer svårare att underhålla. Administratörer och utvecklare använder sig av loggutskrifter för att underhålla system. Loggutskrifter är händelser som har utförts i systemet som sparas ner till fil eller databas. Vare sig om det är ett stort eller litet system så använts loggutskrifter. Loggutskrifter kan ses som en detaljerad dagbok för ett system där varje ändring eller utförd handling registrerats [1].
När systemen expanderas förvandlas loggutskrifterna, som redan är svårlästa, till oumbärliga texter i stora proportioner. För att kunna förstå, underhålla och dessutom förbättra systemet krävs det att man analyserar dessa loggutskrifter. Ett system kan skriva i flera megabyte i sekunden, där ingen enskild individ klarar av att analysera under en rimlig tid.
Att använda sig av ett sofistikerat verktyg som filtrerar bort irrelevant data, sparar det inte bara tid utan även möjliggör för användaren att hitta mönster och relationer, som annars skulle vara nästintill omöjligt att finna.
1.1.1 Företagsbeskrivning
Cambio Healthcare Systems AB är Skandinaviens ledande företag av vårdadministrativt system. Cambio leverera vårdsystemet COSMIC, ett lättanvänt och en helhetslösning som omfattar journalföring, läkemedelsförskrivning, remisshantering samt patientadministration för ett flertal verksamhetsgrenar [2].
Det två nyutexaminerade grundarna, Håkan Mattson och Tomas »Mora« Morrison fick år 1993 uppdraget att utveckla ett vårdadministrativt system för specialenheten Sergelkliniken i Stockholm. Direkt så insåg de att de måste arbeta närmre vårdens utövare, för att kunna utveckla ett bra IT-stöd för sjukvården. Mattson och Morrison tog reda på vilka krav och önskemål vårdpersonalen hade istället för att utgå från de naturliga hos en ingenjör. De grundande Cambio Healthcare Systems AB med ett tydligt mål, att aktivt bidra till att utveckla sjukvårdens informationsflöden. Med 370 anställda utsprida i Linköping, Stockholm, Århus, Reading och Colombo har
2 Cambio vuxit till att idag bli en av den största leverantören i Norden av e-hälsa och en växande spelare på den europeiska marknaden [2].
Nu arbetar det för att hjälpa vården att arbeta både effektivare och mer humant, med patientens säkerhet och integritet fokus [2].
1.2 Uppgiftsbeskrivning
Vår uppgift för detta examensarbete fokuserar sig på att undersöka, med hjälp av statiska metoder, möjligheten att använda loggutskrifter för att upptäcka anomalier innan det drabbar användaren eller företaget. Dessutom fokuseras det även på inläsning utav loggutskrifter på ett strukturerat format samt se till att sökning och filtreringen av loggutskrifter blir effektivare och enklare. Vidare ska detta presenteras på ett visuellt och pedagogiskt sätt för att underlätta felsökningen för användaren.
1.3 Cambio COSMIC
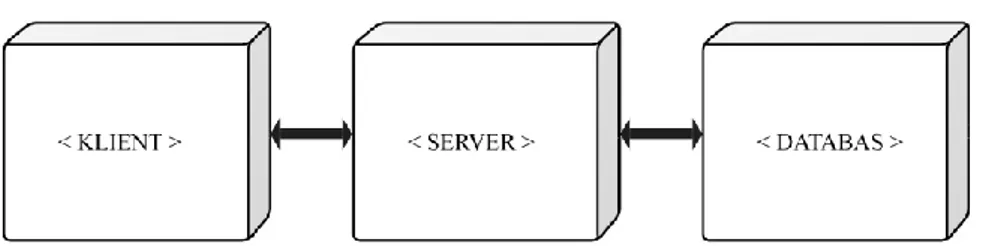
Cambio COSMIC:s arkitektur är en klassisk trelagersarkitektur; användaren integrerar med en klient som i sin tur har kommunikation med en server. Servern agerar som en medlare mellan klienten och databasen, Figur 1 ger en förenklad överblick hur det är uppbyggt.
Figur 1: Cambio COSMIC uppbyggnad.
Alla delar i systemet ger ifrån sig loggar av något slag, men vår uppgift består av att endast fokusera på två loggutskrifter som finns i servrarna. Dessa två kallas Server och Spider. Server delen tillhandahåller loggningen för JBoss och COSMIC:s serverhantering. I Spider loggas alla ändringar eller utförda handlingar mellan klienten och COSMIC:s moduler. Något som bör uppmärksammas är att det sker betydligt mer loggutskrifter i Spider än Server.
Loggutskrift är den information som skrivs till fil som beskriver vad som har skett i systemet. Detta underlättar när man till exempel behöver undersöka hur ett fel har uppstått. En enklare loggutskrift består av två delar: en tidstämpel som indikerar när
3 de har skett och data som beskriver vad som har skett. I Figur 2 visas ett exempel på en loggutskrift.
[2014-05-21 22:39:56] [ERROR: Client denied by server]
Figur 2: Loggutskrift/händelse.
I rapporten kommer en loggutskrift även kallas för en händelse.
1.4 Frågeställningar
För att kunna hitta en bra lösning har vi delat upp problemet i fyra frågor med respektive under frågor:
1. Vad är relevant data för att upptäcka fel? 2. Finns det några färdiga lösningar?
o Vad är för - och nackdelarna med dessa lösningar?
3. Är det möjligt att upptäcka anomalier med historisk och i realtids loggutskrifter?
4. Är det möjligt att upptäcka anomalier innan de drabbar användaren genom att utnyttja loggutskrifter?
1.5 Rapportens uppbyggnad
Rapporten förutsätter att läsaren har grundläggande eftergymnasiala kunskaper om teknik och matematik.
1.6 Avgränsningar
Målet med denna studie är inte att framställa en färdig produkt utan undersöka möjligheten att upptäcka fel med hjälp av loggutskrifter och leverera en prototyp. I och med att alla delar i systemet belastas olika kommer vi lägga större tonvikt på den delen där utskrifter sker mest.
4
2 Metod och genomförande
2.1 Arbetssätt
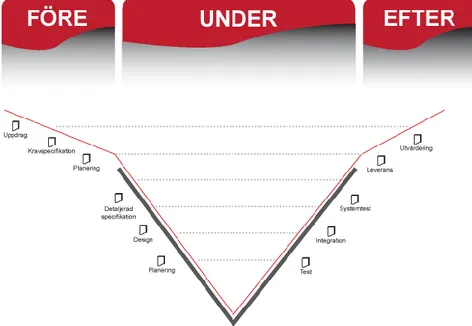
För att uppnå ett bra system krävs det en bra process. Våra steg i arbetet kommer att vara baserat på LIPS-modellen, se Figur 3. Modellen är uppdelad i tre faser: före, under och efter [3].
I fas ett, sker en analys av de tilldelade uppdragen. Detta för att identifiera grenarna i en kravspecifikation som kommer att klargöra vad systemet i slutändan kommer att innehålla. Därefter sker en planering för fas två. Fas två, under-fasen, kommer systemet att börja utvecklas. I denna fas utförs detaljerade specifikationer och en design av systemet. Vid varje steg, aktivitet, som utförs kommer det att dokumenteras och testas. När ett fel upptäcks vid ett test gör vi ett steg tillbaka till motsvarande aktivitet och reparerar felet. I sista fasen, efter-fasen, dokumenteras en utvärdering av processen och systemet [3].
Figur 3: Bild på LIPS-modellen.
2.2 Konkretisering av arbetssätt
Inledningsvis bekantade vi oss med verksamheten, COSMIC och uppdraget, som även innefattade en introduktionskurs i hur COSMIC fungerar. Utifrån detta fick vi en första kravställning, som senare resulterade i en alfaversion av vårt system. Med en alfaversion tillgodo kunde vi utföra en enkätundersökning som gav oss en bild om det
5 förväntade systemet, se kapitel 2.3. Därefter genomfördes det en undersökning om hur man automatiserar övervakning av data. Det i sin tur är uppdelat i flera steg: val av metod, hypoteser kring data, lösning och sist utvärdering av lösning.
2.3 Enkätundersökning och urval av respondenter
För att få en djupare förståelse för vad Cambio AB vill ha från systemet genomfördes en enkätundersökning. Undersökningen gjordes för att få en klarare bild av vad som ska göras och vilka delmoment som ska belysas mer än andra. Utifrån resultaten kunde vi ge dem ett skräddarsytt system som tillfredsställer deras behov. Undersökningens syfte var att framhäva medarbetarnas arbetsprocess.
2.3.1 Genomförande av enkätundersökningar
Undersökningen omfattade medarbetarna på Cambio AB:s kontor i Linköping. Den har inte tagit hänsyn till andra kontor på grund av begränsade resurser samt av avståndsmässiga skäl. Antalet respondenter uppgick till fyra vars arbetsuppgifter varierade.
Undersökningen delades upp i tre delar som vi kallade: förfrågor, presentation samt efterfrågor. Förfrågorna gav en inblick hur deras arbetsprocess går till när de arbetar med loggar och vad som är intressant för just dem. Senare presenterades en alfaversion av systemet. Slutligen, efterfrågorna som agerar som återkoppling om vi var på rätt spår. Dessa frågor är utformade så att vi fick svart på vitt om presentationen av loggarna följde World wide web consortium (W3C) normer om hur loggar ska se ut och presenteras [4].
2.3.2 Enkätfrågor
Se Appendix 2 Enkätfrågor.
2.3.3 Sammanfattning av enkätundersökning
Oavsett vilken arbetsroll medarbetarna har på Cambio är procedurerna nästintill identiska. De kan sammanfattas:
6 1. Ett ärende kommer in från kund innehållande komprimerande loggar från Spider, Server och klientloggar. Majoriteten av fallen, vet kunden inte var felet uppstår och även inte när det inträffade. Det leder till att loggarna kommer i stora mängder. 2. Mottagaren på Cambio analyserar kundens felbeskrivning och
söker sedan i klientloggen för att samla ihop nödvändig information till sökning i Server- respektive Spiderloggarna.
3. I de flesta fallen, identifieras vad problemet är och återkopplar till kunden, annars ber man kunden om fler loggar och repeterar proceduren.
Respondenterna sållar ut informationen i loggarna manuellt, genom att öppna loggarna i en textredigerare och med simpla kommandon söka efter relevant information. Det bör även påpekas att alla respondenter tyckte att det var problematiskt att framhäva väsentlig data som tillhör problemet. Alla respondenter har stött på flera typer av fel och undantag, vissa i större utsträckning. Vissa typer av undantag inträffar oftare än andra, ett exempel är Null pointer exception.
Alla respondenter har stött på stack trace, se Figur 4, men de hanterade det på olika sätt. En del letar upp information i tekniska dokument som beskriver felen. Andra ansåg att man sparade tid på att själv analysera stack trace istället för att slå upp det. Anledningarna är:
Svårt att hitta dokument
Dokumenten är eventuellt inte uppdaterat
Dokumentation finns ej
I frågan »om all data är intressant« var det ett enhetligt nej. Däremot kan man inte dra slutsatsen att all data inte är relevant. Beroende på vilket problemen som ska lösas skiljer sig vilken data som ska användas.
Oavsett respondent var de enade om att det saknades information för specifika utskrifter. Informationen för anrop mellan moduler var en tydlig brist. I systemet sker det anrop mellan modulerna, men för nuvarande registreras det inte vilken modul som anropar vilken, utan endast att modul A har blivit anropad. Det saknades en modulanropshierarki.
En del fel som inträffar behöver tydligare felbeskrivning och relevanta in- och ut-parametrar bör ingå i händelsen. Vid Null pointer exception brister det information helt.
7 Utöver det bristande information i händelser saknades det en standard över hur en händelse bör skrivas.
8
3 Teoretisk referensram
I det här kapitlet behandlas de grundläggande kunskaper som detta examensarbete omfattar. Inledningsvis tas det upp vilka system som finns för insamling av data, deras för- och- nackdelar tas även upp.
Därefter förklaras de mest använda metoderna för informationssökning. I mitten av kapitlet visas ett exempel på hur alla dessa metoder fungerar i verkligheten. Sedan beskrivs det hur databasen Elasticsearch:s arkitektur är uppbyggt och hur noderna i klustret kommunicerar med varandra. Avslutningsvis förklaras de metoder som ska användas för att analysera loggutskrifter.
3.1 Insamling av data
Det första steget för inläsning är att förstå loggutskrifterna. Vissa applikationer och system har någon form av standardisering i strukturen, andra inte. Det finns även fall där det inträffar utskrifter som inte har hanterats av applikationen, vilket leder till ostrukturerade utskrifter.
Olika applikationer har olika lagringsformat. Majoriteten av applikationer använder rent textbaserade filer för att lagra händelser, med någon form av tidsbestämd rotation för att undvika stora filer och ge en bättre struktur [5].
De olika lagringsformaten ställer höga krav på inläsning av data och filtrering. Det finns aspekter som bör observeras vid inläsning av loggfiler, exempelvis att en del loggmeddelande består av flera rader. Dessa rader bör inte hanteras som separata händelser, utan bör sammanfogas till en händelse, ett typiskt exempel är stack trace, se Figur 4.
2014-03-02 | 09:11:42 | se.cambiosys.spider.messenger.util|2|XXXX1|Messenger(0): java.rmi.AccessException: SecurityException; nested exception is: javax.security.auth.login.FailedLoginException: Login denied at se.cambiosys.spider.StructureService.ExceptionToolkit.convert(ExceptionToolkit.java:37) at se.cambiosys.spider.MessengerModuleInternal.MessengerLockToolkit.getToolkit(MessengerLockToolkit.java:186) at se.cambiosys.spider.MessengerModuleInternal.MessengerLockToolkit.lock(MessengerLockToolkit.java:72) at se.cambiosys.spider.MessengerModuleInternal.ScheduledMailTimerTask.doTask(ScheduledMailTimerTask.java:44) at se.cambiosys.spider.MessengerModuleInternal.SendLaterTimerTask.run(SendLaterTimerTask.java:14) at java.util.TimerThread.mainLoop(Timer.java:512) at java.util.TimerThread.run(Timer.java:462)
Figur 4: En stack trace händelse.
Strukturen på en händelse ställer även krav på hur den kommer filtreras och indexeras. En generell händelse består av en tidstämpel och ett meddelande, där meddelandet har någon form av information som beskriver händelsen. Dock följer inte meddelandet någon specifik struktur, vilket gör det svårare att identifiera relevant data. Motsvarande
9 gäller även för tidstämplar. Många loggutskrifter använder inte ett enhetligt tidsformat, utan ett med bara ett datum och ett klockslag till sekundnivå. I en applikation som hanterar fler trådar sker det kontinuerligt utskrifter till loggarna från olika trådar. Att försöka identifiera vilken loggutskriftskrift som inträffat först med ett tidsformat på sekundnivå, Figur 5 kan vara svårare och mer tidskrävande än tidsformat med tusendelar [5].
2014-01-08 | 15:12:58 | se.cambiosys.spider.UserService|1|XXX1|XXX1 Logout
Figur 5: En händelse med sekundformat.
3.1.1 Lösningar
Det finns många verktyg som adresserar problemet för inläsning av data. Det flesta kommersiella lösningarna hanterar inläsning, indexering och lagring i ett heltäckande system, vilket kan ge mindre frihet för modifiering.
Fluentd och Logstash är två av det öppen källkod (eng. Open source) projekt som adresserar problemet insamling och transport av loggdata i centraliserad loggning. Dessa två är de mest mogna och kraftfulla projekt. Lösningarna har sina likheter och skillnader, men deras arkitektur påminner om varandra.
3.1.1.1
Logstash
Logstash är implementerad i JRuby och körs på Java Virtual Machine (JVM), vilket ger friheten till val av operativsystem, med andra ord stöd för Windows, OS X och Linux [5].
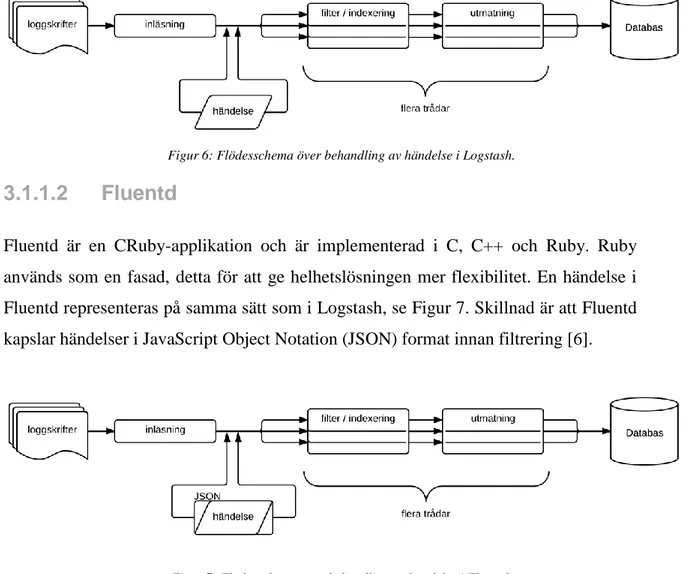
Varje händelse i Logstash har en tidsstämpel, loggmeddelande och märke för att klassa händelse för senare dirigering. En händelse genomgår tre bearbetningsstadier; inläsning, filtrering och transport. Inläsningen skiljer sig beroende på vilket format utskrifterna har lagrats i. Vid filtrerings stadium, normaliseras loggutskrifterna. Det kan ske i flera steg. När filtreringen är klar är händelsen redo och skickas till mottagare för vidare hantering. I Figur 6 illustreras processen för en händelse [5].
10
Figur 6: Flödesschema över behandling av händelse i Logstash.
3.1.1.2
Fluentd
Fluentd är en CRuby-applikation och är implementerad i C, C++ och Ruby. Ruby används som en fasad, detta för att ge helhetslösningen mer flexibilitet. En händelse i Fluentd representeras på samma sätt som i Logstash, se Figur 7. Skillnad är att Fluentd kapslar händelser i JavaScript Object Notation (JSON) format innan filtrering [6].
Figur 7: Flödesschema över behandling av händelse i Fluentd.
En begränsning som Fluentd har att den endast stödjer Linux och OS X för tillfället [6].
3.2 Systemdesign
Ett av kraven som ställdes är att prototypen ska vara kompatibel med Windows 7. Majoriteten av de lösningar som fanns tillgängliga var dessvärre inte det. Det leder till en lösning med de tre omtalade applikationerna; Logstash, Elasticsearch och Kibana. Elasticsearch är en flexibel och kraftfull databas. Den är en av de mest omtalade NoSQL-databaser och är skalbar. För att indexera data i Elasticsearch används Logstash, som är ett verktyg för att filtrera och indexera händelser.
För att kunna presentera data på ett pedagogiskt sätt används Kibana som är ett verktyg för Elasticsearch. Alla applikationer är installerade på en och samma server och
11 använder statiska loggutskrifter som inmatning. Figur 8 nedan visar en överblick över prototypens konstruktion.
Figur 8: En översiktlig bild på prototypens konstruktion.
För att åstadkomma en centraliserad loggning föreslås följande design i Figur 9. Det är ett vanligt sätt att bygga sin arkitektur, för att maximera prestanda och undvika dataförlust. Transportören är en applikation som är ansvarig för transporten av loggmeddelanden över nätverket till bufferten i huvudservern. Indexeraren är en normal instans av Logstash.
12
3.3 Informationssökning
Innebörden av begreppet informationssökning kan vara mycket brett. Bara att få ut ett kreditkort ur plånboken för att uppge ett kortnummer är en form av informationssökning. En informationssökningsprocess startar när till exempel en användare skickar förfrågning, en begäran av information, till ett system. Ett typiskt exempel på detta är att uppge en söksträng till en sökmotor. Informationssökning är att hitta information i form av objekt i en ostrukturerad samling av data. Data som uppfyller ett informationsbehov, vars förfrågningar inte är bundna till ett enda objekt, istället kan flera objekt matcha förfrågningen, med olika grader av relevans [7].
Elasticsearch är ett verktyg som riktar sig mot informationssökning och erbjuder möjligheten till att utföra förfrågningar med vissa egenskaper på ett sofistikerat sätt. Elasticsearch bygger på Apaches öppna informationssökningsbibliotek Lucene. Lucene använder en kombination av Vector Space Model (VSM) och booleskhämtningsmodell för att avgöra hur relevant ett dokument är för användares förfrågning [7][8][9].
VSM kan delas in i tre faser. Där första fasen är hämtning och indexering av dokument, där termer plockas ut ur respektive dokument. Den andra fasen är att kalkylera ut relevansen för en indexerad term i ett dokument. Den sista fasen är rankningen av dokument med avseende på förfrågan i enlighet med ett likhetsmått [7].
Vi kommer i detta kapitel gå igenom de grundläggande metoder för informationssökning som Lucene bygger på. Vi börjar med att förklara hur booleskhämtningsmodell fungerar och sedan går vi in djupare i VSM.
3.3.1
Booleskhämtningsmodell
Linjärsökning, även kallad grepping efter Unix-kommandot grep, kan vara ett tillfredsställande och effektivt sätt att söka igenom mindre samlingar. Tack vare att dagens datorer är tillräckligt snabba och att man kan använda reguljära uttryck (eng. Regular Expression) i sin sökning. I många fall är detta fullt tillräckligt, men i andra fall så vill man prestera bättre:
1. När kollektionen växer ökar även söktiden och i värsta fall kommer det vara i O(n), där n är antalet termer i kollektionen. Vi behöver kunna använda metoder som fungerar lika bra på en liten kollektion med några tusen termer, men även kollektioner som innehåller miljarder, upp till triljoner [10].
13 2. Genom att tillgodose sökningen med ett rankat resultat. I många fall vill man ha
det bästa svaret först bland en massa potentiella svar [7].
Booleskhämtning är en metod för att hämta en uppsättning av dokument som matchar en boolesk förfrågning, till exempel förfrågan »Dwalin« som definierar mängden av alla dokument som är indexerade med begreppet »Dwalin«. Dokumenten i exemplet nedan återfinns i Appendix 1 Dokumentsamling.
doc0 doc1 doc2 doc3 doc4 doc5 ...
balin 0 0 1 1 1 1 bilbo 1 0 1 0 1 1 dwalin 0 0 1 1 1 1 fili 0 0 1 0 0 0 gandalf 0 1 0 0 0 0 kili 0 0 1 1 0 0 ...
Figur 10: En anslutningsmatris för term-dokument. Matriselement (t,d): om t = 1 i kolumnen d, återfinns termen i dokumentet.
För att undvika linjärsökning i texterna är dokumenten indexerade på förhand. I Figur 10 visas en anslutningsmatris för term-dokument, där varje rad motsvarar en vektor. Låt oss säga att vi ska utföra en förfrågning:
Balin AND Dwalin NOT Bilbo
Svaret till förfrågningen lyder att vi tar vektorerna, raderna i matrisen, för Balin, Dwalin och Bilbo och transponerar dem. Eftersom vi inte ska ha Bilbo med i svaret tas komplementet till vektorn och gör en bitvis AND, vilket blir:
001111 AND 001111 AND 010100 ≡ 000100
Resultaten visar att endast doc3 innehåller termerna Balin och Dawlin men inte Bilbo.
Den observanta ser att matrisen kommer innehålla fler nollor än ettor. Denna observation leder till en av informationssökningens större koncept, inverterat index.
Inverterat index är en kompakt representation av en matris optimerad för uppslagning av vilka dokument en term förekommer i [7]. Den illustrerade matrisen, se Figur 10, visar vilka termer som förekommer respektive inte förekommer i de olika
14 dokumenten. Att skapa en sådan matris där vi lagrar 0 och 1 för varje term i varje dokument är alltför stor för att lagras i datorns minne. För att spara minne används inverterat index, där varje term är kopplat till en lista över vilka dokument det förekommer i. I Figur 11 belyser vi hur ett inverterat index ser ut. De kan ske flera åtkomster i O(1) till ett pris av betydligt längre tid att utföra en uppdatering, i värsta fall O(n), där n är antalet termer i inverterade indexet [10].
Term Pekare Lista
balin → 2 3 4 5 bilbo → 0 2 4 5 dwalin → 2 3 4 5
… → …
Figur 11: Inverterat index.
Den vänstra spalten, ordboken, innehåller alla termer som förekommer i alla dokument. Den är oftast implementerad som en hash-tabell och lagrad i minnet. Varje term är länkad till en egen sorterad lista (eng. Posting) som innehåller id-nummer för varje dokument som den förekommer i, typiskt implementerad som en länkad lista och lagrad på disk. För att få prestanda till en av fördelarna med inverterat index måste dokumenten indexeras i förväg. Huvudstegen för att konstruera ett inverterat index är: insamling av dokument, uppfångning av termerna från dokumenten och normalisering av termerna.
När dokument har samlats in och termer ur dokumenten har identifierats, kommer en lista med alla unika termer att skapas och sorteras i bokstavsordning. Termer som förekommer i flera dokument identifieras och en lista kommer att skapas. Innan listan skapas sker en normalisering, se kapitel 3.3.2, av termerna i ordboken. I Figur 12 ser vi en lista med termer som har identifierats från de inlästa dokumenten och Figur 13 visar listan efter sortering och normalisering. Efter normaliseringen skapas ett inverterat index, se Figur 14.
15 Term docid Balin 3 balins 4 balin 5 bilbos 2 Bilbo 0 bilbo 4 bilbo 5 … …
Figur 12: Lista över termer från ett dokument, direkt efter inläsning. Term docid balin 3 balin 4 balin 5 bilbo 0 bilbo 2 bilbo 4 bilbo 5 … …
Figur 13: Lista över termer från ett dokument, efter normalisering och hantering av stoppord.
Term Pekare Lista
balin → 3 4 5 bilbo → 0 2 4 5
Figur 14: Inverterat index efter inläsning, normalisering och hantering av stoppord.
3.3.2
Stoppord och normalisering
Det finns många fall då flera termer inte riktigt är lika, men bör matcha samma sökbegrepp. Till exempel ska förfrågan »USA« även matcha dokument som innehåller termen »U.S.A« [7].
Termnormalisering är en process för att standardisera termer, så att termer matchar trots ytliga skillnader i teckensekvenserna i termerna. Det finns flera metoder för att normalisera termer. Den mest vanliga metoden är att skapa ekvivalensklasser som namnges efter en medlem av termerna. Till exempel placeras termerna »USA« och »U.S.A« under termen »USA«, både i dokumenten och i förfrågningar. En förfrågning på en av termerna kommer att matcha dokument som innehåller någon av ekvivalenstermerna. Ett annat sätt att förbättra matchningen är att reducera alla bokstäver till gemener. Det tillåter förfrågningen »USA« att matcha termer med olika konstellationer, såsom »USA, Usa, usa«. Det finns även synonymer som bör matchas vid en förfrågning, t.ex. »arg« och »ilsken«. Ett alternativ till att skapa ekvivalensklasser är att upprätthålla relationer mellan normaliserade termer. En metod för detta är att utöka ekvivalensklasser med synonymer till termen, se Tabell 1 [7][11]. Ord som ofta förekommer i texter såsom »till, från, på, i« kallas stoppord. Dessa ord fyller ingen funktion i förfrågningen. Den allmänna strategin för att bestämma en
16 stopplista är att sortera termer efter insamlingsfrekvens och därefter välja ut de vanligaste förekommande termer. En annan metod är att manuellt filtrera termerna efter deras semantiska innehåll i förhållande till dokumenttyp [7].
bil automobil, fordon, motorfordon hus byggnad, villa, bostad
Tabell 1: Två ekvivalensklasser som upprätthåller en relation mellan termer.
3.3.3 Likhetsmått
VSM är en algebraisk modell för att representera textdokument som vektorer. I VSM är en vektor begreppsmässigt representerat av termer som förekommer i ett dokument eller frågan. Figur 15 visar hur ett dokument representeras i en vektor. Varje term har en tillhörande vikt som representerar hur betydelsefull termen är i dokumentet och inom hela dokumentsamlingen. Likaså för en förfrågning, där en lista av termer modelleras med en tillhörande vikt som representerar hur betydelsefull termen är i förfrågningen [7].
𝑑𝑗
⃗⃗⃗ = {𝑤1,𝑗, 𝑤1,𝑗, 𝑤1,𝑗, . . . , 𝑤𝑡,𝑗}
Figur 15: Exempel på en dokumentvektor.
Vikten för en term i ett dokument kan beräknas på många sätt. En allmän strategi är den så kallade Tf-idf viktning. Denna metod baserar vikten av en term på två faktorer: hur ofta termen t förekommer i dokumentet d (termfrekvens tfd,t) och hur ofta t förekommer i hela dokumentsamlingen (dokumentfrekvensen dft). Beräkning av vikten sker genom att använda Formel 1 [7][12].
𝑡𝑓 − 𝑖𝑑𝑓𝑑,𝑡 = 𝑡𝑓𝑑,𝑡 × 𝑖𝑑𝑓𝑡= 𝑡𝑓𝑑,𝑡 × log 𝑁 𝑑𝑓𝑡
Formel 1: td-idf viktning.
I Formel 1 är N antalet dokument i dokumentsamlingen och idft är den inverterade dokumentfrekvensen.
Om en term förekommer mer frekvent i ett dokument bör vikten av dokument vara högre än de dokument som termen förekommer mindre i. Om ett dokument d är
17 viktad enligt ovan, tar den inte hänsyn till hur ordföljden är i dokumentet. Det väsentliga är enbart frekvensen av termerna. Man går ifrån att tala om set om ord till säck om ord. Nackdelen med denna metod är att dokument som inte är identiska men beter sig identiskt i samband med en förfrågning, exempelvis dokumentet »Adham hoppar högre än Muntaher« är exakt identisk med »Muntaher hoppar högre än Adham« [7].
För att mäta likvärdigheten mellan en förfrågning och ett dokument används ett likhetsmått, känd som cosinuslikhet (eng. Cosine similarity). Den beräknar vinkeln mellan dokumentvektorerna och frågevektorn när de är representerade i en 3-dimensionell euklidiskrymd. Mer specifikt fås vinkeln genom att använda Formel 2, där 𝑣
⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑) är skalärprodukten av de viktade vektorerna och |𝑣 ⃗⃗⃗ (𝑓)||𝑣 ⃗⃗⃗ (𝑑)| är Euklidisk norm. Effekten av nämnaren är att normalisera vektorerna 𝑣 ⃗⃗⃗ (𝑓) och 𝑣 ⃗⃗⃗ (𝑑) till enhetsvektorer [7][12].
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑓, 𝑑) = cos 𝜃 = 𝑣 ⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑) |𝑣 ⃗⃗⃗ (𝑓)||𝑣 ⃗⃗⃗ (𝑑)|
Formel 2: Cosinuslikhet.
Dokument rangordnas efter minskande cosinusvärde. Om f = d är cosinusvärdet av vinkeln 1, likaså ges 0 när vektorerna f och d inte delar några gemensamma termer.
18 I Figur 16 visas ett exempel på hur likheten mellan ett dokument och en förfrågning bestäms. Förfrågningsvektorn (f) har större likhet med dokument a (doc a) jämfört med dokument b (doc b), eftersom vinkeln mellan f och doc a är mindre än vinkeln mellan f och doc b.
3.3.4 Exempel
Vi kommer nu med ett förenklat exempel försöka ge en bild över hur det olika delarna hänger ihop i VSM.
Vi tänker oss en mycket liten kollektion av dokument, där varje dokument består av en händelse, se Figur 17:
doc0 ”2014-05-21 | 11:08 | LoginModule: Adham login denied”
doc1 ”2014-05-21 | 11:09 | LoginModule: Adham login success”
doc2 ”2014-05-21 | 11:09 | svnModule: Muntaher committed repo X”
Figur 17: En kollektion bestånden av tre dokument.
Det första steget är indexeringsfasen. Under den fasen indexeras alla termer i kollektionen med sitt tillhörande dokument-id (docid), se Figur 18. Efter att termerna har indexerats sker termnormalisering. Då kommer versaler att konverteras till gemener och stoppord samt tecken som inte tillför sökning någon nytta att elimineras. När både dessa faser har genomförts skapas ett inverterat index. Figur 19 visar indexet efter sortering och normalisering.
19 Term docid 2014 0 05 0 21 0 11 0 08 0 LoginModule 0 Adham 0 login 0 denied 0 | 0 : 0 2014 1 05 1 21 1 11 1 09 1 LoginModule 1 Adham 1 Login 1 Success 1 : 1 | 1 2014 2 05 2 21 2 11 2 09 2 svnModule 2 Muntaher 2 commited 2 repo 2 X 2
Figur 18: Lista över termerna och deras tillhörande dokument-id. Term docid 05 → 0 1 2 08 → 0 09 → 1 2 11 → 0 1 2 2014 → 0 1 2 21 → 0 1 2 adham → 0 1 commited → 2 denied → 0 login → 0 1 loginmodule → 0 1 muntaher → 2 repo → 2 success → 2 svnmodule → 2 x → 2
Figur 19: Inverterat index med termer och deras tillhörande dokument-id, efter normalisering och
20
För varje term i den inverterade listan beräknas en vikt (tf-idf) som bedömer värdet av hur viktig den termen är med avseende på dokumentet och kollektionen. Nedan visas hur uträkningen för termen »adham« i Doc0 sker, se Formel 3. När värdet för varje term
har beräknats, erhålls en term-dokument matris, se Figur 20.
𝑡𝑓 − 𝑖𝑑𝑓𝑑,𝑡 = 𝑡𝑓𝑑,𝑡 × log 𝑁
𝑑𝑓𝑡 = 1 × log 3
2= 0,584
Formel 3: Viktuträkning för termen »adham« i Doc0. N är antalet dokument i kollektionen, dft är
termfrekvens i kollektionen och dfd,t är termfrekvensen i Doc0.
doc0 doc1 doc2
05 0 0 0 08 1.584 0 0 09 0 0,584 0,584 11 0 0 0 2014 0 0 0 21 0 0 0 adham 0,584 0,584 0 commited 0 0 1.584 denied 1.584 0 0 login 0,584 0,584 0 loginmodule 0,584 0,584 0 muntaher 0 0 1.584 repo 0 0 1.584 success 0 1.584 0 svnmodule 0 0 1.584 x 0 0 1.584
21 Givet förfrågningen f = »adham login denied«, kan vi nu genomföra en sökning. Första steget blir att skapa en vektor av f. Vidare beräknas vikten för varje term i f, se Figur 21. f 05 0 08 0 09 0 11 0 2014 0 21 0 adham 0,584 commited 0 denied 1,584 login 0,584 loginmodule 0 muntaher 0 repo 0 success 0 svnmodule 0 x 0
Figur 21: term-dokument, vektorn f.
Efter att ha beräknat viktningen för varje term i f, erhålls en vektor. Med hjälp av f:s vektor och dokumentens vektorer kan vi beräkna vinkeln mellan respektive kombination. Nedan beräknas vinkeln mellan varje dokument och förfrågning.
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑓, 𝑑𝑜𝑐0) = cos 𝜃 = 𝑣 ⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑) |𝑣 ⃗⃗⃗ (𝑓)||𝑣 ⃗⃗⃗ (𝑑)|= 3,191 1,786 ∗ 2,458= 0,727 𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑓, 𝑑𝑜𝑐1) = cos 𝜃 = 𝑣 ⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑) |𝑣 ⃗⃗⃗ (𝑓)||𝑣 ⃗⃗⃗ (𝑑)|= 0,682 1,786 ∗ 1,968= 0,194 𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑓, 𝑑𝑜𝑐2) = cos 𝜃 = 𝑣 ⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑) |𝑣 ⃗⃗⃗ (𝑓)||𝑣 ⃗⃗⃗ (𝑑)|= 0 1,786 ∗ 3,560= 0
22 Utifrån beräkningarna i Formel 4 finner vi att likheten mellan vår förfrågning f och dokumentet Doc0 är högst, följt av Doc1. Vi kan även utesluta Doc2 ur vårt resultat, ty den inte har någon likhet med vår förfrågning.
3.3.5 Lucene
Lucene är ett kraftfullt informationssökningsbibliotek skriven helt i Java. Lucene kan indexera all textbaserad data med ett oföränderligt gränssnitt oavsett format på data. I Lucene ligger dokument bestående av ostrukturerade samlingar av fält. Varje fält består av två delar, ett namn och data. Utöver det två delarna innehåller ett fält information om hur data är lagrat, till exempel om det är lagrat som rå- eller komprimerad data [9][13].
Figur 22: Representation av ett dokument i ett index i en Lucene instans.
I Lucene:s hjärta ligger ett poängssystem som är en utvecklad variant av Tf-idf-viktning och kallas rankning (eng. scoring). Rankning utvecklar Tf-idf-viktning genom att angripa prestanda problemet i algoritmen och samtidigt uppnå sökkvalitet och användbarhet. Rankningssystemet tillämpas på fält och inte på dokumentet. Den kombinerar resultateten av fälten och sedan återlämnar de som resultatet av ett dokument, se Figur 22. Dokumentets längd representeras av fälten, detta för att två dokument med exakt samma innehåll, där de ena dokumentet lagrar data över två fält och den andra i ett fält, kommer att ge olika poäng på samma förfrågning [9][13].
23 Med ett förenklat antagande, med ett enda fält i ett index, kan vi beskriva Lucene:s rankningsformel följt av en beskrivning på de olika termerna, se Formel 5 [9][14].
𝑠𝑐𝑜𝑟𝑒(𝑓, 𝑑) = 𝑐𝑜𝑜𝑟𝑑𝑓(𝑓, 𝑑) × 𝑞𝑢𝑒𝑟𝑦𝑏(𝑓) ×
𝑣
⃗⃗⃗ (𝑓) ⋅ 𝑣 ⃗⃗⃗ (𝑑)
|𝑣 ⃗⃗⃗ (𝑓)| × 𝑑𝑜𝑐𝑙𝑛(𝑑) × 𝑑𝑜𝑐𝑏(𝑑)
Formel 5: Lucene:s konceptuella rankningsformel.
Normalisering av en dokumentvektor till en enhetsvektor är känt för att vara problematisk. Det leder till att information om dokumentslängd raderas. För att undvika detta problem tillämpas en extra faktor, docln, dokumentvektorer normaliseras till en vektor som är lika med eller större än enhetsvektor [7][14].
Vid indexering finns det möjligheten att specificera ett viktighetsvärde, docb, på dokumentet. Viktighetsvärdet kommer sedan att multipliceras med rankningsvärdet [14].
Vid en förfrågning kan användaren specificera ett viktighetsvärde, queryb, för hela förfrågningen, del-förfrågningen och en specifik term i förfrågningen. Viktighetsvärdet för respektive kommer att multipliceras med rankningsvärde för respektive dokument vid sökningsträff [14].
En förfrågning med flera termer kan matcha ett dokument utan att den innehåller alla termer i den förfrågningen. För att eliminera problemet tillämpas en extra faktor, coordf, som baserar sig på hur många av förfrågningstermerna som förekommer i respektive dokumentet [14].
Den konceptuella rankningsformelen, Formel 5, är en förenkling där termer och dokument är sammanfogade och viktighetsvärdet endast definierat per förfrågningsterm. Lucene:s praktiska rankningsformel är en modifierad och optimerad formel av den konceptuella [14].
3.3.6 Elasticsearch
Elasticsearch är en distribuerad databasserver implementerad i Java, vars uppgift är att bearbeta data och lagra det på ett format optimerat för språkbaserade sökningar [8].
Elasticsearch kapslar in Lucene och erbjuder en distribuerad sökmotor med ett RESTful webbgränssnitt och använder ett HTTP/JSON protokoll som är mer
24 användarvänligt, skalbart och effektivt än Lucene. De faktiska algoritmerna för lagring, optimerad indexering och sökning genomförs i Lucene [15].
Ett Elasticsearch-kluster består av en eller flera noder som arbetar tillsammans för att öka prestandan och förhindra dataförlust. Vid indexering skapar Elasticsearch ett index för inkommande data. Ett index består av en eller flera primära instanser, där varje primärinstans har noll eller flera sekundära instanser. Ett index är en mappning mellan primära och sekundära instanser i en relationsdatabas. En primär- och sekundärinstans är en instans av Lucene [8][16].
Om vi jämför Elasticsearch termer med en MySQL-databas ser liknelsen ut som i Figur 23.
Figur 23: Jämförelse mellan Elasticsearch och MySQL.
Nedan följer en illustration på hur primära respektive sekundära instanser i ett kluster skapas (Figur 24) [8].
Figur 24: Ett kluster bestående av Elasticsearchnoder.
Vid ett haveri av en primärinstans befordras automatiskt den sekundära instansen i andra noden till en primär. Det gäller även vid ett nodhaveri, alla sekundära instanser kommer automatiskt att befordras till primära [8].
Vid ett uppstart av en nod multisänder noden ut identifieringsmeddelande för att upptäcka andra noder inom klustret. Varje nod som befinner sig inom samma kluster identifierar sig och därefter befordras en av noderna till huvudnod. Noderna i klustren
MySQL Databaser Tabeller Kolumner och rader
25 kommunicerar med varandra med en P2P-arkitektur. Huvudnodens uppgift är att hantera klustrets tillstånd i form av utdelning av primära respektive sekundära instanser, utdelning av förfrågningar och återhämtning vid haveri [8].
En förfrågan kan ske direkt till en specifik nod eller till huvudnoden. För att minska svarstiden utdelas förfrågningen till antigen en primär eller sekundär nod [8].
3.3.6.1
Tillstånd
Ett kluster har tre tillstånd, grönt, gult eller rött. När huvudnoden identifierar ett av tillstånden utför den specifika uppgifter [17].
Vid grönt tillstånd tyder det på att alla instanser är allokerade och inga uppgifter behöver utföras. Vid gult tillstånd tyder det på att alla primära instanser är allokerade, men de sekundära instanserna har inte allokerats än. Huvudnoden kommer vid detta tillstånd att söka efter dubbletter och behandla dem som sekundära instanser. Om en primärinstans inte har tillräckligt med sekundära instanser, kommer huvudnoden att skapa ytterligare sekundära instanser bland noderna [17].
När tillståndet är rött tyder det på att en specifik instans i klustret inte har allokerats. Ett rött tillstånd kan även tyda på kommunikationsfel mellan noder i klustret eller andra typer av fel. Vid detta tillstånd försöker huvudnoden att utföra en återhämtningsprocess och vid behov allokeras nya instanser och utdelning av primära och sekundära instanser sker. Övriga fel hanteras manuellt [17].
3.3.7 Presentation av data
För att kunna presentera händelser på ett pedagogiskt sätt krävs ett verktyg som kan hantera daterade händelser. Majoriteten av sådana lösningar har ett beroende mot andra verktyg. Detta beroende ger lösningen mindre flexibilitet.
Kibana är en öppen källkod-projekt som skapades för att möjliggöra visualisering av sökningar i Elasticsearch. Det är implementerat i JavaScript och är en AngularJS applikation som använder AJAX för att kommunicera med Elasticsearch [18].
Kibana har ett användarvänligt gränssnitt med flera moduler som hjälper med visualiseringen av data i olika format, utan att använder behöver komma i närheten av kodning. Kibana är för närvarande de enda alternativ som hanterar visualiseringen på ett effektivt sätt och har support för Elasticsearch [8][18].
26
3.4 Övervakning
Ett av kraven från uppdragsgivaren var att vi skulle undersöka om det går att ha en övervakning över deras system och kunna detektera när systemet beter sig annorlunda. Med det avsågs att det skall larmas när det genereras för många undantag under en viss period.
Det finns ett flertal sätt att angripa detta problem, till exempel använda sig av »data mining« eller »machine learning«. Efter en utvärdering av båda sätten drogs slutsatsen att en sådan lösning inte kunde utformas inom projektets tidsram och därför valdes det att lösa problemet med hjälp av statistiska metoder. Genom att använda dessa metoder på retrospektivdata kan man få en uppfattning om hur systemet genomsnittligt beter sig, och när dessa mått börjar avvika tyder det på att något har inträffat.
Vidare valdes det att använda en referenslinje. Denna referenslinje kommer agera som ett mått till de undantag som genereras i systemet och räknas utifrån föregående veckor. Tesen lyder att retrospektivdata kan användas prospektivt, det vill säga »det genomsnittliga vädret för de veckor som har gått kommer vara likadan i framtiden«. Om värdena från system över eller understiger referenslinjen har något inträffat.
3.4.1 Statistiska metoder
Ett av kriterierna för att kunna använda sig av en referenslinje är att mängden data är tillräckligt stort. Innan beräkningarna påbörjas bör det tas några fundamentala antaganden:
Datamängden ska vara kontinuerlig över den period man utför beräkningarna. Om det inte finns data under ett intervall i datasetet blir resultatet missvisande.
Datasetets händelser får inte orsakas av slumpmässiga anledningar. Med andra ord händelserna måste vara resultat av när en ändring eller dylikt har utförts [1].
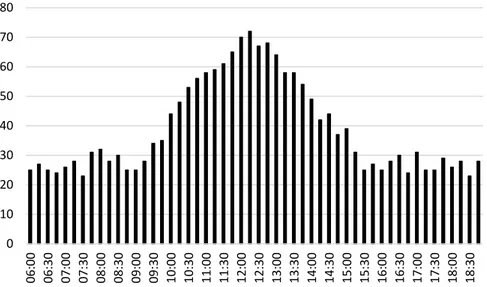
27 Med dessa antaganden kan referenslinjen ge ett bra resultat, men det finns vissa specifika fall som bör tas i åtanke. I Figur 25 finner vi ett exempel på hur många undantag som skrivs ut över en period.
Figur 25: Fiktivt exempel på undantag som skrivs ut över tid.
Den observanta ser att det finns ett avvikande värde i början av stapeldiagrammet. Det avvikande värdet är betydligt större än dess grannar och kommer påverka referenslinjen, det vill säga en aning förhöjd. Men om det kommer flera tillfällen med avvikande värden, resulterar detta i att referenslinjen kommer avvika kraftigt från de faktiska värdena. Detta är viktigt att hantera då vi försöker räkna ut vad som är normalt. Det finns några sätt att hantera detta problem på:
1. Exkludera avvikande värden från beräkningarna. Datasetet får visserligen färre datapunkter att utföra beräkningar på, och om det är fler datapunkter som exkluderas kan det leda till en inverkan på referenslinjen som inte är åtråvärd (M1).
2. Höja, alternativt sänka den till samma nivå som den föregående datapunkten och därefter adderar eller subtraherar med en konstant för att bibehålla egenskapen hos referenslinjen (M2).
3. Medelvärdet tas på ett litet antal grannar runtom det avvikande värdet (M3) I Figur 26 har den andra metoden (M2) använts och vi kommer även att använda metoden i våra beräkningar. Följden av detta blir att resultaten återspeglar verkligheten
0 10 20 30 40 50 60 70 80 06:00 06:30 07:00 07:30 08:00 08:30 09:00 09:30 10:00 10:30 11:00 11:30 12:00 12:30 13:00 13:30 14:00 14:30 15:00 15:30 16:00 16:30 17:00 17:30 18:00 18:30
28 betydligt bättre än om det avvikande värdet exkluderas eller om referenslinjen använder avvikande värdenas faktiska värde.
Figur 26: Avvikande värdet hanterad.
3.4.1.1
Statisk referenslinje
En statisk referenslinje är en linje, se Figur 28, som kommer att gå parallellt med x-axeln. Det negativa med att enbart räkna ut referenslinjen med medelvärde är att den inte beskriver hela sanningen. Nedan belyser vi två exempel där vi beräknar medelvärde på två olika datamängder där båda får medelvärdet 50.
𝑥̅ =∑ 𝑥 𝑛 = 99 + 1 2 = 50 Exempel 1 𝑥̅ =∑ 𝑥 𝑛 = 49 + 51 2 = 50 Exempel 2
Båda datamängderna ger medelvärdet 50 trots att datamängderna har helt olika egenskaper. Med hjälp av standardavvikelsen, se Formel 6, kan vi få en bättre uppfattning av hur datamängden är. Det är ett mått som beskriver hur mycket värdena i datamängden avviker från medelvärdet, med andra ord ett osäkerhetsmått. Standardavvikelserna för Exempel 1 och Exempel 2 blir 69,3 respektive 1,4. Genom detta enkla exempel kan vi dra slutsatsen att enbart medelvärdet inte beskriver data tillräckligt bra. Ett medelvärde med en hög standardavvikelse tyder på att datapunkterna i datamängden är spridda, det vill säga differensen mellan datapunkterna är stor eller enklare sagt de ligger långt ifrån varandra.
0 10 20 30 40 50 60 70 80 06:00 06:30 07:00 07:30 08:00 08:30 09:00 09:30 10:00 10:30 11:00 11:30 12:00 12:30 13:00 13:30 14:00 14:30 15:00 15:30 16:00 16:30 17:00 17:30 18:00 18:30
29 𝜎 = √∑(𝑥−𝑥)2
(𝑛−1)
Formel 6: Standardavvikelse.
Standardfel är ett annat statistiskt säkerhetsmått som kommer användas. Standardavvikelse beskriver, som tidigare nämnt, hur data i datamängden är utspridd medan standardfelet mäter hur noggrant datamaterialet är uträknad. I varje urvalsundersökning eller experiment uppkommer det så kallade slumpfel och i vissa fall även systematiska fel. Standardfel är ett mått som uppskattar dessa. Ju mindre standardfelet är, desto mer representativ är datamängden. Standardfel benämns även som medelfel [19][20].
𝑠 = 𝜎 √𝑛
Formel 7: Standardfel.
Om vi använder datamängderna från Exempel 1 och Exempel 2 vet vi redan att båda mängderna innehåller två tal och avvikelserna var 1,4 respektive 69,3. Formel 7 ger standardfelen: 𝑠̅ = 𝜎 √𝑛= 1,4 √2= 0,99 Exempel 3 𝑠̅ = 𝜎 √𝑛= 69,3 √2 = 49 Exempel 4
I Exempel 3 är standardfelet väldigt lågt jämfört med Exempel 4 och en förklaring till detta är just på grund av att standardavvikelsen i Exempel 2 är väldigt hög och att antalet tal i mängden är litet. Figur 27 visar medelvärdena för varje datamängd med sina standardfel.
30
Figur 27: Datamängderna med standardfelsintervall.
Konfidensintervall används för att eliminera statistiska osäkerheten, d.v.s. slumpen som sker vid ett stickprov. Det menas att det ska producera nästan samma resultat oavsett sampling eller population. I ett konfidensintervall väljs en konfidensgrad och den anges i procent. Konfidensgraden markerar hur sannolikt resultat befinner sig inom konfidensintervallet [21].
Beräkningarna kommer ske på dataset som innehåller undantagsutskrifter som systemet skriver till servrarna. Datasetet är indelat i arbetsveckor, måndag till fredag och varje dag har en tolv timmars period. I Figur 28 visas en arbetsvecka med undantagsutskrifter, med en statisk referenslinje och ett 95 % konfidensintervall.
Figur 28: Arbetsvecka med statiskreferenslinje och konfidensintervall från Landstinget i Uppsala Län.
0 20 40 60 80 100 120 D1 D2 0 10000 20000 30000 40000 50000 60000 70000 80000 8: 00 8: 30 9: 00 9: 30 10 :0 0 10 :30 11 :0 0 11 :3 0 12 :0 0 12 :3 0 13 :0 0 13 :30 14 :0 0 14 :3 0 15 :0 0 15 :3 0 16 :0 0 16 :3 0 17 :0 0 17 :3 0 18 :0 0 18 :3 0 19 :0 0 19 :3 0 20 :00
31 Med hjälp av de statiska metoderna ovan beräknas den statiska referenslinjen som representerar det genomslitliga normala under förgående och applicerats på pågående arbetsvecka. Konfidensintervallet användes som ett undre och över tröskelvärde och illustreras i Figur 28.
3.4.1.2
Dynamisk referenslinje
Den statiska referenslinjen tar inte hänsyn till att antalet undantagsutskrifter varierar beroende på vilken tidpunkt på dygnet det är. Om vi tar Figur 28 som ett exempel, sker det fler undantagsutskrifter runt klockan 13:00 än 14:00, men referenslinjen är densamma. Slutsatsen som inte får tas är att det är fler fel vid klockan 13:00 än vid 14:00. Den statiska referenslinjen visar medelvärdet av alla undantagsutskrifter på en vecka. Det vore bättre om referenslinjen tog tiden i beaktande och följde med utskrifterna under dagen. Med detta i åtanke leder det till den andra metoden att beräkna referenslinjen och som vi har valt att kalla »dynamisk referenslinje«.
Figur 29: Dynamisk referenslinje, Landstinget i Uppsala Län.
0 10000 20000 30000 40000 50000 60000 70000 80000 8: 00 8: 30 9: 00 9: 30 10 :00 10 :3 0 11 :0 0 11 :3 0 12 :00 12 :3 0 13 :0 0 13 :3 0 14 :0 0 14 :3 0 15 :0 0 15 :3 0 16 :0 0 16 :3 0 17 :0 0 17 :3 0 18 :0 0 18 :3 0 19 :0 0 19 :3 0 20 :0 0
32 I Figur 29 visas den dynamiska referenslinjen för samma arbetsvecka som tidigare. Istället för att beräkna referenslinjen på hela datamaterialet beräknas den i 30-minutersintervall från 8:00 till 20:00. Tabell 2 visar intervallen och deras datapunkter.
Tid Mån Tis Ons Tors Fre Dyn.ref
8:00 5504 6189 6163 6590 9802 6849,6 8:30 8521 10012 11361 9552 13969 10683 9:00 16673 19446 15481 12771 24215 17717,2 9:30 28583 30376 23914 24285 37409 28913,4 10:00 38125 45556 34640 34068 55097 41497,2 10:30 49583 52776 46741 47579 63788 52093,4 11:00 45580 49282 45419 43662 58608 48510,2 11:30 49279 50323 41631 39795 57534 47712,4 12:00 50550 53270 47459 47973 63467 52543,8 12:30 53317 60917 50937 53066 71007 57848,8 13:00 55170 54943 47341 51219 68935 55521,6 13:30 53367 49917 44207 43307 61578 50475,2 14:00 30606 28001 31109 30062 44336 32822,8 14:30 31241 33447 28633 34475 43230 34205,2 15:00 49926 48620 52036 46521 63553 52131,2 15:30 53397 56385 55606 52148 66979 56903 16:00 49250 59363 55392 53611 64071 56337,4 16:30 52474 51292 45255 43388 55749 49631,6 17:00 45777 46020 40296 50623 52465 47036,2 17:30 45497 47822 45253 50426 47274 47254,4 18:00 39441 44652 38115 43669 38389 40853,2 18:30 29293 30541 26416 28531 33455 29647,2 19:00 15988 17637 18295 16323 20151 17678,8 19:30 11176 12212 11698 11939 14489 12302,8 20:00 10528 10314 10443 813 13230 9065,6
Tabell 2: Data från en arbetsvecka, Landstinget i Uppsala Län.
3.4.1.3
Korrelation
Korrelation är en statistisk term som beskriver samverkan emellan två stokastiska variabler. Korrelation uttrycks mellan -1 till 1, där 1 är tyder på en stark positiv och -1 starkt negativt. En korrelation som blir 0 eller nära 0 tyder det på att det inte finns något linjärt samband mellan de båda stokastiska variablerna. I Formel 8 visas Pearsons Korrelations som användes för att beräkna korrelationen mellan dataseten [20][22].
33 𝜌𝑥,𝑦 = ∑(𝑥 − 𝑥̅)(𝑦 − 𝑦̅)
∑(𝑥 − 𝑥̅)2(𝑦 − 𝑦̅)2
Formel 8: Pearsons Korrelation.
För att säkerställa att korrelationen, genomförs ett så kallat statistisk test, även kallad signifikanstest. Denna metod uttrycks i ett värde mellan 0 och 1 och kallas för p-värde. I förväg anges ett signifikansvärde och det är vanligt att välja antingen en 5 % eller 1 % signifikansnivå [20]. Ett 5 % signifikansnivå medför att om p-värdet överstiger 0,05 är hypotesen inte signifikant och hypotesen förkastas [20][23][24].
Korrelation kommer att användas för att bevisa samband mellan loggutskrifter och upptäcka anomalier.
34
4 Analys och Resultat
I detta avsnitt skall de metoder som tidigare nämnt, se kapitel 3.4, sättas i praktik. Data från Landstinget i Uppsala kommer användas och benämnas som lärdata. På lärdata tillämpas metoderna och sedan utvärderas på data från Landstinget i Östergötland. Data från Landstinget i Östergötland kommer benämnas som utvärderingsdata.
4.1 Lärdata
Ur dessa lärdata testas de statistiska metoder som tidigare nämnts i kapitel Metod och genomförande. I Figur 30 och Figur 31 syns antalet händelser respektive undantag som skrivs ut under en vecka. Genom att enbart studera dessa tabeller visas att händelserna kommer i cykler och det är lätt att urskilja dag från natt.
Figur 30: Totala händelser under en arbetsvecka, Lul. 0 10000 20000 30000 40000 50000 60000 70000 80000 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30
35
Figur 31: Totala undantag under en arbetsvecka, Lul.
En förklaring till att det skrivs ut fler händelser eller undantag under dagarna är att det är betydligt fler som arbetar dagtid än nattetid. Om fokus läggs enbart på Figur 31, tydliggörs det hur många undantag som skrivs under en arbetsvecka. Observera att under nattetid sker det en dramatisk skillnad. Antalet undantagsutskrifter pendlar mellan noll och tolv om inget extraordinärt inträffat. På grund av denna iakttagelse görs beräkningarna gällande lärdata endast på en tolvtimmars period från klockan 08:00 till 20:00. Anledningen till denna åtgärd är att det är för få undantag som inträffar för att beräkna en referenslinje. I Figur 32 visas hur den nya arbetsveckan för undantag ser ut.
0 2000 4000 6000 8000 10000 12000 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30 00:30 04:30 08:30 12:30 16:30 20:30
36
Figur 32: Undantag under alla tolvtimmarsperioder på en arbetsvecka – Lul.
Beräkningar för den statiska referenslinjen visas nedan i Tabell 3 och i Figur 28. De höga värdena på standardavvikelsen och standardfelet visar att det är en stor variation i utskrifter. Resultat Medelvärde 2578 Standardavvikelse 2014 Standardfel 184 Statisk Referenslinje 2938
Tabell 3: Statisk referenslinje.
I Tabell 4 visas korrelationen mellan de totala undantag och händelser var dag för sig. Resultatet visar att händelser och undantag är stark positivt korrelerande med varandra. Dessutom visas det att signifikansen är väldigt låg, vilket tyder på att beräkningar är trovärdiga. Beräkningen utfördes med ett 95-procentigt konfidensintervall. Det som bör påpekas är att korrelation säger inget om kausalitet. Det går därmed inte att dra slutsatsen »så fort man använder systemet skrivs det ut undantag«. Jämför man Figur 30 och Figur 31 visas det att undantag är en bråkdel av vad som skrivs ut, men de har samma mönster. 0 2000 4000 6000 8000 10000 12000 08:00 10:00 12:00 14:00 16:00 18:00 20:00 09:30 11:30 13:30 15:30 17:30 19:30 09:00 11:00 13:00 15:00 17:00 19:00 08:30 10:30 12:30 14:30 16:30 18:30 08:00 10:00 12:00 14:00 16:00 18:00 20:00
37 Korrelation Signifikans Måndag 0,93 p < 0,001 Tisdag 0,85 p < 0,001 Onsdag 0,89 p < 0,001 Torsdag 0,91 p < 0,001 Fredag 0,95 p < 0,001
Tabell 4: Korrelation totala händelser med totala undantag per dag.
Eftersom utskrifterna kommer ut i liknande cykler togs korrelation mellan arbetsdagarna var för sig. Tabell 5 visar korrelation och signifikans mellan varje par av dagar. Resultatet visar en stark positiv korrelation mellan varje par av dagar, vilket tyder på att antalet undantag för varje dag är likt varandra under en arbetsvecka.
Måndag Tisdag Onsdag Torsdag Tisdag 0,74 p < 0,001 Onsdag 0,67 0,69 p < 0,001 p < 0,001 Torsdag 0,87 0,62 0,70 p < 0,001 p < 0,001 p < 0,001 Fredag 0,84 0,77 0,79 0,85 p < 0,001 p < 0,001 p < 0,001 p < 0,001
Tabell 5: Korrelation mellan undantag för en arbetsvecka. Beräknat med ett 95-procentigt konfidensintervall.
4.1.1
Slutsatser
Det framstår tydligt att loggutskrifter kommer i cykler och man kan urskilja dag från natt och veckodag från helgdag. Dock så har vi inte tillräckligt med statistiska belägg för att bevisa att detta är sant, utan det är något man intuitivt ser. En trolig förklaring till detta är att det är betydligt fler som arbetar dagtid än nattetid och veckodagar än helgdagar.
I och med att utskrifterna kommer i cykler och systemet belastas olika, beroende på vilken tidpunkt det är, beskriver inte en statisk referenslinje hela sanningen. Därmed
38 är en statisk referenslinje inte en bra kandidat för att representera vad som är normalt eller inte. Denna iakttagelse leder oss till att undersöka om dynamisk referenslinje är ett bättre alternativ. Den dynamiska referenslinjen tar hänsyn till att systemet blir olikt belastat beroende på vilken tid det är på dygnet.
Undantagsutskrifterna har en tendens att följa de vanliga händelseutskrifter och de är starkt positiv korrelerande med varandra. Eftersom lärdatamaterialet är beräknat på en begränsad tidsperiod kan man inte verifiera om detta samband beror på slumpen eller inte. Detta ska undersökas om det stämmer överens med datamaterialet från utvärderingsdata, då datamaterialet återfinns i större kvantitet.
Det har även påvisats att frekvensen av undantagsutskrifterna under en given tidpunkt är starkt positivt korrelerande med varandra.
4.2 Utvärderingsdata
Utvärderingsdata skiljer sig från lärdata. Lärdata omfattade data från alla servrar men under en kort period.
Utvärderingsdata innefattar data från tre servrar under en period av 12 veckor, från december till mitten utav mars. Under denna period infaller två stora högtider, jul och nyår, då systemet används i mycket mindre utsträckning än övrig tid. Följden av detta blir att systemet hos Landstinget i Östergötland inte är lika belastat. Om dessa veckor skulle tas in i beräkningar skulle det medföra att referenslinjen blir missvisande.
Skillnaden med detta datamaterial är att en arbetsdag startar klockan 07:30 och slutar 19:30. Anledningen till att arbetsdagen börjar 30 minuter tidigare är att personalen i Landstinget i Östergötland tycks ha en benägenhet att logga in på systemet lite tidigare än personalen i Landstinget i Uppsala län.
På utvärderingsdata användes en dynamisk referenslinje istället för en statisk. Denna linje beräknas på de fyra arbetsveckor innan den femte och sedan appliceras på den femte. Med andra ord tillämpas glidande medelvärde för att beräkna den dynamiska referenslinjen. Skälet till att den dynamiska referenslinjen beräknas på fyra veckor är att om det sker ovanligt mycket utskrifter på en arbetsvecka ska det inte ge för stort utslag på resultatet.
När utvärderingsdata hade lästs in till systemet uppmärksammades att händelserna inte följde samma mönster som det gjorde i lärdata. Det går inte att urskilja dag från natt eller om det är veckodag eller helgdag. Genom att undersöka utskrifterna