Fakulteten för teknik och samhäle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
En Undersökning Av Vardagsanvändares Preferenser För
Självloggningsverktyg
A Study On Everyday Users’ Preferences For Self-Tracking Tools
Dennis Johansson
Examen: Kandidatexamen 180 hp
Huvudområde: Data och informationsvetenskap
Handledare: Carl Magnus Olsson Andrabedömare: Jeanette Eriksson
Sammanfattning
Allt eftersom självloggning ökar i popularitet börjar även vardagsanvändarna bli en be-tydande del av marknaden. Denna ökning gör att deras behov behöver undersökas mer djupgående. Tidigare har den typen av användare som beskrivits som extremanvändare utgjort hela den användartyp som kallas nyckelanvändare. Till följd av detta har deras be-hov dominerat studier såväl som återkoppling för hur verktyg för självloggning utformas. För att adressera denna obalans rapporterar denna studie skillnader mellan extremanvän-dare och vardagsanvänextremanvän-dare, samt diskuterar möjliga lösningar för hur vardagsanvänextremanvän-dare kan övervinna barriärer i sitt användande av självloggningsverktyg. Denna studie lämnar ett bidrag genom att såväl identifiera skillnader som argumenterar för behov att vidga användargrupper som studeras inom självloggning, samt de forskningsmöjligheter som är relaterade till detta.
Nyckelord: Självloggningsverktyg, nyckelanvändare, vardagsanvändare
Abstract
As self-tracking has increased in popularity the everyday user has become an important part of the market. Due to this increase the needs of these users requires further exploration. Previously the type of user know as lead users have consisted of what has been referred to as extreme users. Because of this the needs of this particular group of users has dominated studies as well as the feedback for how self-tracking tools are designed. To address this imbalance this study will report on the differences between extreme users and everyday users. It will also discuss possible solutions for how the everyday users can overcome barriers in their use of self-tracking tools. This study leaves a contribution through the identification of differences that argues for the need to expand the groups of users that are being studied within the field of self-tracking as well as the research possibilities related to this.
Innehåll
1 Inledning 1
1.1 Bakgrund . . . 1
1.2 Frågeställning . . . 2
1.3 Tidigare forskning . . . 2
1.3.1 Extremanvändare och deras motivation . . . 2
1.3.2 Olika typer av spårning . . . 4
1.3.3 Stadier och barriärer . . . 5
1.3.4 Nyckelanvändare och extremanvändare . . . 6
1.3.5 Visualisering och redigering av data . . . 6
2 Metod 7 2.1 Enkätstudier . . . 7 2.2 Datainsamling . . . 8 2.3 Dataanalys . . . 9 3 Resultat 10 3.1 Saknad funktionalitet . . . 10 3.2 Motivation . . . 10 3.3 Externa faktorer . . . 12 4 Diskussion 12 4.1 Saknad funktionalitet . . . 12 4.1.1 Visualisering . . . 12 4.1.2 Integrering . . . 13
4.1.3 Hantering av ofullständig data . . . 13
4.2 Mönster i användandet . . . 13
4.3 Jämförelse av motivering . . . 15
4.4 Möjliga lösningar . . . 15
4.5 Utökad användargrupp . . . 16
1
Inledning
1.1 BakgrundI dagens samhälle har vi tillgång till verktyg för att förändra våra vanor och förbättra oss själva. Ett sätt att uppnå sådana mål är genom användandet av självloggningsverk-tyg[12]. Exempel på verktyg är papper och penna samt applikationer för kalkylblad som låter användare samla in de flesta typer av data, även om de inte alltid är ämnade att samla in den typ av data användaren intresserar sig för. Det kan också vara betydligt mer anpassningsbara verktyg som användare designat för att vara skräddarsydda efter deras behov. Mer förfinade självloggningsverktyg kan vara applikationer[15] för insamlandet av data om hur långt och länge en användare har sprungit, smartklockor[6] som känner av och loggar användarens puls för att kunna identifiera olika händelser relaterade till förändring av pulsen eller en smartvåg[7] som spårar viktförändringar.
När flera självloggningsverktyg samverkar sömlöst blir de delar av vad som kallas ”the Internet of Things”[12]. Ett exempel på sömlös samverkan är när en användare brukar ett verktyg för att spåra data om kost och sömn i kombination med sitt självloggnings-verktyg för träning i ett försök att finna mönster som berättar om hur dessa parametrar påverkar återhämtningsförmågan hos användaren. Tidigare forskning[17] har haft fokus på extremanvändare. Denna grupp av användare utmärker sig genom större kompetens inom dataanalys och större teknisk kunskap än en vardagsanvändare besitter. Att undersöka dessa användare har skänkt kunskap om användarnas beteende och problemen de stött på. Samtidigt som de undersökta användarna kunnat kategoriseras som extremanvändare har de också varit den typ av användare Von Hippel[16] benämner som ”lead users”. Denna artikel har valt att översätta detta begrepp till nyckelanvändare. Sådana användare ut-märker sig genom att vara kapabla till innovation eftersom de befinner sig före den plats där marknaden för tillfället befinner sig. Deras motivation till att innovera beror på höga förväntningar om lönsamhet som resultat av uppfinningsrikedom.
Begreppet nyckelanvändare[16] kräver inte att användarna ska besitta tillräckligt med teknisk kunskap för att själva arbeta sig runt eventuella hinder. Därför kan vardagsanvän-dare räknas till denna gruppering. Vardagsanvändarna har blivit intressanta att undersöka allt eftersom utbudet[13] av självloggningsverktyg ökat. Inkludering av både vardagsanvän-dare och extremanvänvardagsanvän-dare som nyckelanvänvardagsanvän-dare ger ny insikt i hur marknaden utvecklats sedan den förstnämnda typen av användare blivit en allt större del av marknaden. Den-na artikel kommer därför att presentera en representativ bild av hur användarbehoven ser ut efter att vardagsanvändare blivit verksamma inom området självloggning. Studien kommer mer specifikt att undersöka upplevda brister i självloggningsverktyg. Bristerna kommer att kategoriseras efter vilken problemtyp de tillhör. Dessa typer grundas på ka-tegorier som tagits fram för denna studie. Validering av insamlad data kommer att göras genom jämförelser med tidigare studier och de mönster som hittats i dem. Resultatet från denna undersökning har potential att gynna framtida utveckling av självloggningsverktyg så väl som vidare forskning genom att finna nya områden att studera som är viktiga för att vardagsanvändare ska kunna ta del av samma möjligheter till förbättring som varit förbehållen extremanvändare.
Forskning av denna art faller inom området ”personal informatics”. Begreppet översätts enklast till personlig databehandling. Vad som menas med personlig data är data insamlad
med hjälp av självloggningsverktyg[11]. Personlig databehandling är ett område där tidiga-re forskning har haft exttidiga-rema användatidiga-re som målgrupp för sina studier eftersom dessa har varit lättare att få tag på genom forum, konferenser och så kallade ”meet-ups”. Vi använ-der samma definition som Choe[2] har använt i sin studie för att definiera vad en extrem användare är. Definitionen kommer att presenteras under rubriken Tidigare forskning.
Vardagsanvändare definierar vi som personer med mindre erfarenhet av databehandling och därför förlitar de sig på att deras valda verktyg ska göra allt arbete. De har inte lika stor kompetens för att arbeta sig runt eventuella problem. De har dessutom inte lika bra koll på vilka alternativ marknaden erbjuder.
Ett problem som kan uppstå om vardagsanvändare inte inkluderas i studier är att verktyg enbart riktar sig till användare med kompetens i att modifiera sina verktyg vid behov. Detta exkluderar vardagsanvändare som exempelvis är intresserade av att undersöka hur deras vanor påverkar fysisk hälsa, mental hälsa eller deras ekonomi. Till följd av detta kan även en klyfta komma att skapas mellan de olika typerna av användare. Framtida forskning står att vinna en mer utförlig förståelse för behoven hos de olika typerna av användare om vardagsanvändare inkluderas i gruppen nyckelanvändare.
1.2 Frågeställning
Denna artikel kommer svara på hur behovet förändrats från tidigare studier där nyckelan-vändare främst varit expert- och extremannyckelan-vändare till idag då även vardagsannyckelan-vändare till viss mån kan inkluderas i denna grupp av användare. Mer specifikt kommer det undersökas vilka funktioner som användarna upplever att de saknar. Studien kommer även att jämföra om mönster kring användande kvarstår. Exempel på detta är om samma typer av spårning och motivation återfinns även när nyckelanvändare består av ännu en typ av användare. Artikeln kommer också att diskutera lösningar på de problem som användare stöter på och hur de kan angripas för att öppna upp självloggning för en större mängd vardagsanvändare.
1.3 Tidigare forskning
I denna sektion av artikeln presenteras arbeten som har analyserat användares motivation för att spåra data och typerna av data som de har spårat. Detta kommer att presenteras i en tabell(tabell. 1) som återskapats från en tidigare studie för att sedan jämföras med kategorier som tagits fram i undersökningen som gjorts för denna artikel. Med samma syfte presenterar vår studie även olika typer av spårning som identifierats bland användare i andra studier. Begreppet extremanvändare kommer att definieras eftersom det kommer användas för att beskriva den typ av användare som har undersökts av tidigare studier.
Von Hippels[16] definition av begreppet nyckelanvändare presenteras för att förklara varför karaktärsdragen hos dessa användare gör dem lämpade för marknadsundersökningar. Definitionen bidrar dessutom med en förklaring till varför den typen av användare är viktig att undersöka.
1.3.1 Extremanvändare och deras motivation
I en studie[2] som genomfördes 2014 studerades en grupp av användare som beskrevs som extrema användare. Användarna klassificerades som extrema eftersom deras historier om misslyckanden och framgångar kanske inte är applicerbara för vardagsanvändare. Extrema
Tabell 1: Varför användare spårar data och vilken data som spåras[2].
Motivations Sub-categories Tracking example
To improve health
To cure or manage a condition Track blood glucose to hit the target range To achieve a goal Track weight to get back to the ideal weight
To find triggers Log triggers that cause atrial fibrillation
To answer a specific question
Track niacin intake dosage and sleep toidentify how much niacin to take for treatingsymptoms
To identify relationships
Track exercise, weight, muscle mass and bodyfat to see relationships
among the factors
To execute a treatment plan Log food, exercise and panic as a recoveryplan for panic attack
To make better health decisions
Record ideas of things that thought were healthy and unhealthy to
make better decisions
To find balance Log sleep, exercise and time to get back fromerratic lifestyle To improve other
aspects of life
To maximize performance Track time to know the current use of tim eand ways to be more efficient To be mindful Take a self-portrait shot everyday for
365days to capture each day’s state of mind
To find new life experiences
To satisfy curiosity and have fun
Log the frequency of punsto see how often these puns happened and what triggered them
To explore new things Track every street walked in Manhattan to explore as much of the city as possible To learn something interesting Track heart rate for as long as possible
and see what can be learned from it
användare har använt existerande självloggningsverktyg och lagt ner åtskilliga timmar av sin fritid på att hitta lösningar på problem som har uppkommit vid användande av verktygen. Denna grupp kan också kallas ”quantified- selfers” ’ och är personer som ägnar sig åt det som översatts till personlig databehandling i denna studie. Den studie som genomfördes har ställt följande tre huvudfrågor: Vad gjorde du, hur gjorde du det och vad lärde du dig.
Med hjälp av dessa frågor har studien identifierat tre större huvudgrupper för vad som motiverar användare, vilka underkategorier det går att dela in dessa i och olika exempel på vad det är för någon data som har samlats in. Denna indelning presenterades i form av en tabell(tabell. 1) som återskapats för inkludering i denna artikel.
Efter att ha frågat personerna om hur de gick till väga för att spåra och samla in sin data framgick det att 21%(elva personer)hade byggt sina egna verktyg för anpassning efter deras specifika behov. Detta visar på en god teknisk kompetens och kunskap om dataanalys bland personerna som har studerats. För att tydligare fastställa att så är fallet följer här en kort redogörelse för yrkena som de studerade är verksamma inom. Av personerna som studerades arbetade 40% hos ett ”start-up”-företag, 37% som mjukvaruingenjörer eller programmerare, 13% arbetade med dataanalys och 8% var elektroingenjörer. De övriga var verksamma under följande titlar: ”creative director”, psykolog, designer, produktchef,
student, ”operations analyst”, professor och professionell atlet.
Ett vanligt misstag personerna i studien begick var att samla in många olika typer av data istället för att enbart intressera sig för den data de behövde. Detta ledde ofta till att personerna slutade att spåra sin data helt eller misslyckades med att analysera insamlad data. Ett annat misstag som identifierades var att användarna inte spårade var förändring-arna i deras data kom från. Det vill säga att användförändring-arna kollade efter förändringar i sin data men inte vad som utlöst förändringarna eller i vilket sammanhang
1.3.2 Olika typer av spårning
I en annan studie[14] undersöktes vad som motiverade användare till att börja spåra sin personliga data med hjälp av självloggningsverktyg. Anledningarna kunde delas in i fem olika typer av spårning, även om dessa var överlappande för många användare. Många av användarna i studien drevs av olika mål. Dessa var oftast relaterade till träning och kost. Den typ av spårning fick namnet direktivspårning.
Spårning med anledning att dokumentera var vanligt i studien. Den dokumentära spår-ningen definierades som fall där användarna varit mer intresserade av att studera insamlad data istället för att försöka ändra sina vanor. Vissa av användarna som medverkade i stu-dien föll inom denna kategori till viss mån i början av stustu-dien men valde sedan att satsa på direktivspårning. Diagnostiserande spårning var inte lika vanlig i studien men ändå tillräck-ligt specifik för att bilda en egen kategori. Diagnostiserande spårning syftar till spårning där användare vill lösa problem genom att undersöka korrelationer mellan olika händelser i sin insamlade data. De exempel som togs upp var båda två relaterade till hälsoproblem. Be-lönande spårning var många gånger sammankopplad med dokumentär spårning eftersom en del användare satte upp egna mål. I studien nämndes det att en av personerna som medverkat försökte uppnå en högre topphastighet under en specifik sträcka. Målet styrdes inte av verktyget utan av användaren själv. Det finns också verktyg som ger användaren belöningar om de uppnår vissa mål och sådana verktyg räknas också till belönande spår-ning. Den sista typen av spårning som kunde identifieras var en där själva insamlandet av data var målet. Användarna intresserade sig inte för att undersöka sin data utan bara för att samla in den eller för att de gillade verktyget.
Den diagnostiserande spårningen Rooksby[14] beskriver kan stöta på problem i form av användarens tolkning av insamlad data. Hur detta sker beskrivs av Calvo och Peters[3] i The Irony and Re-interpretation of Our Quantified self. Där beskrivs tre olika sätt proble-men kan uppstå: Användaren bortser från insamlad data, användaren omtolkar insamlad data eller att insamlad data blir externt omtolkad. Användaren kan komma att bortse från sin insamlade data eftersom den inte anses vara användbar eller felaktig. Det kan leda i sin tur till att verktyget som använts för insamlandet överges eller att det anses opålitligt, icke-representativt eller oärligt. Omtolkad data uppstår när en användare återbesöker tidigare insamlad data. Då kan slutsatserna som dras vara felaktiga på grund av att användaren satt sin data i ett sammanhang som inte stämmer överens med verkligheten. När data blivit externt omtolkad menar Calvo och Peters att exempelvis användarens social krets kan påverka hur insamlad data tolkas. Omtolkningen kan ske på ett sätt som liknar det sätt då användaren själv omtolkar sin data. Den sätts återigen i ett sammanhang som inte stämmer överens med verkligheten. En sådan omtolkning kan också ske genom verktyget som används. De tre nämnda sätten kommer i diskussionsdelen användas för att reda ut
vilka problem som kan uppstå för vardagsanvändare vid diagnostiserande spårning. 1.3.3 Stadier och barriärer
Detta leder till de olika stadier som användare genomgår vid användandet av självlogg-ningsverktyg. En användare behöver inte gå igenom samtliga stadier utan kan mycket väl stanna vid ett som det går att se att flera personer i Rooksbys[14] studie har gjort. Dessa stadier presenterades i en artikel med titeln A Stage-Based Model of Personal Informa-tics Systems från 2010 där Li[10] skriver om en modell för självloggningssystem bestående av fem olika stadier. Dessa fem stadier är följande: 1. Förberedelsestadiet, där folk avgör vilken information de vill logga och hur de vill logga informationen; 2. Insamlingsstadiet, där själva insamlandet av vald data sker; 3. Integrationsstadiet, där folk ska förbereda, kombinera och transformera sin insamlade data; 4. Reflektionsstadiet, där folk kan reflek-tera över, utforska och inreflek-teragera med sin insamlade data; 5. Agerandestadiet, där folk kan välja vad de ska göra med hjälp av kunskapen de vunnit.
För varje stadie identifierade Li[10] upplevda barriärer. I förberedelsestadiet återfanns barriärer i form av vilken information som skulle samlas in och vilket verktyg som skulle användas. Studien noterade att vissa användare helt enkelt råkade på ett verktyg och sen började samla in utan tanke på om verktyget i sig kunde tillfredsställa deras informations-behov. Detta kunde få dem att överge sina verktyg och där med överge sin insamlade data eftersom de flesta system inte stödjer export av data till en annan plattform. I de fall där data kan exporteras till en annan plattform är det inte säkert att formaten är detsamma i verktygen. Brist på tid, brist på motivation eller glömska var flera av barriärerna för användarna under insamlingsstadiet. Andra barriärer visade sig i sättet data hanterades. Det kunde vara att insamlandet krävde subjektiv uppskattning(t.ex. hur många kalorier som förbrändes vid tyngdlyftning), subjektiv bedömning(t.ex. hur nöjd användaren är) eller att data var svår att hitta. Integrationsbarriärerna visade sig i att användare hade svårt att övergå från insamlande till reflektion över sin data. Anledningen till barriären var att användarna samlade in data från flera källor och formatet för insamlad data skiljde sig från formatet som var nödvändigt för reflektion. Reflektionsstadiet blev lidande när användare inte kunde ta sig förbi barriärerna som uppstod vid problem med hämtning av data, utforskande av data och förståelse av information. Användarna stötte på problem i agerandestadiet när verktyget inte föreslog hur de skulle gå vidare med informationen.
Li et al[10] drog slutsatsen att barriärer som inte övervinns i de tidigaste stadierna kan orsaka problem när användarna inser att de inte samlat in rätt data eller använt fel verktyg. Sådana misstag kan göra insamlad data nästintill, om inte fullständigt, värdelös. Problem, så som splittrad visualisering, i integrationsstadiet kan försvåra reflektionen för användaren. Reflektionsstadiet blir på så sätt också lidande vilket leder till att agerandestadiet blir svårt eller omöjligt att övergå till.
Barriärerna som Li[10] identifierat kommer att användas för återkoppla till de problem som användarna i vår studie stött på. Vår studie går bortom dessa stadier och skulle kunna läggas till som ett stadie där användarna reflekterar över förberedelsestadiet. Studien kommer mer specifikt att reflektera över hur användarna valde att samla in vald data.
1.3.4 Nyckelanvändare och extremanvändare
I sin bok The Sources of Innovation[16] beskrev Von Hippel en grupp av användare som benämndes som ”lead users”, vilket översatts till nyckelanvändare i denna studie. Dessa användare besitter karaktärsdrag som gör dem mer lämpade för marknadsundersökningar. Den främsta anledningen att de är lämpade för detta syfte är att de stöter på nya behov månader eller år tidigare än vanliga användare. Utöver det så står de att vinna mycket på att behoven tillgodoses. Det som kommer att undersökas är om behoven för så kallade nyckelanvändare har förändrats när vardagsanvändare kan inkluderas i denna grupp. An-ledningen till att de kan kategoriseras som sådana användare är att självloggningsverktyg börjar nå ut till massorna[17] men ännu inte slagit igenom till den grad att det kan an-ses vara en aktivitet som är en del av normen. De står dessutom att vinna mycket från framsteg och lösningar inom området som kan gynna deras behov.
Tidigare forskning[2][10] har undersökt varför användare slutar att använda självlogg-ningsverktyg, vad som motiverar dem och vilka typer av spårning som kunnat identifieras. Dessa studier har dock mestadels undersökt extrema användare som Choe[2] uttrycker det. Alltså användare som är mer engagerade i personlig databehandling som rörelse. Det är användare som läser om personlig databehandling samt går på träffar där de diskuterar si-na framgångar, misslyckanden och experiment. För att bidra med en bättre representation av hur användarbasen för självloggningsverktyg ser ut i dagens läge kommer denna artikel att undersöka vilka problem nyckelanvändare stöter på när vardagsanvändare är en del av denna användartyp. Diskussionsdelen av artikeln kommer att undersöka hur problemen kan lösas utifrån förutsättningen att det är användare med mindre teknisk kompetens. 1.3.5 Visualisering och redigering av data
År 2014 utforskade Epstein et al[5] visualisering av personlig data för att utveckla menings-fulla stycken som kan presenteras för användaren. Varje stycke visade ett mönster eller en avvikelse i användandet för att visa korrelationer. Detta kunde vara information i form av att på tisdagar cyklade användaren i regel mindre i jämförelse med andra veckodagar. Sådan information kan i sin tur leda till nya upptäcker som förbättrar användarens rutiner. Ett av fynden som gjordes var att de stycken som ansågs vara värdefulla av använ-daren inte uppvisade någon korrelation med deras uppsatta mål. Det föreslås därför att användarna kan ha intresserat sig för dessa stycken av information eftersom de erbjöd in-sikter de inte förutsett skulle vara värdefulla. Det i sin tur antyder att verktyget behöver göra mer än reagera på de mål som satts upp av användare eftersom värdefulla upptäckter annars kan gå förlorade. Deltagarna i den studien angav att de föredrog att få stycken av information i form av tabeller och diagram där varje stycke summerades i format som lätt kunde konsumeras.
Epstein et al[5] föreslår att visualiseringar som sammanfattar en månads insamlande av data inte leder till förändringar i rutiner. Istället föreslås det att meddelanden bör dyka upp i rätt sammanhang. Om användaren har en vana att inte uppnå sitt dagliga mål när resan hem från jobbet sker senare än vanligt så kan användaren uppmuntras att ta en promenad för att ändra på mönstret. Denna studie kommer användas som referens i diskussionsdelen där lösningar på bristande visualisering tas upp. Den är viktig för att förstå hur en användare kan interagera med sin data och hur interaktionen ibland behöver gå bortom användarens önskemål för att uppnå vissa förändringar.
I en studie[11] om klassificering av självloggningsverktyg undersöktes 71 olika själv-loggningsverktyg. I denna studie beskrivs det hur verktyg förhåller sig till insamlandet av data. Författarna beskriver fyra typer av timlighet vid insamlandet av data: kontinuerlig, sessionsbaserad, enstaka noteringar och post hoc-redigering. Som exempel på kontinuerligt insamlande tar de upp självloggningsverktyg som alltid är på och där med alltid samlar in data. Sessionsbaserat insamlande beskrivs som data som samlats in under en specifik peri-od. Runkeeper tas upp som exempel på detta eftersom användaren då startar insamlandet när träningen påbörjas och avslutar insamlandet när träningspasset är färdigt. Insamling i form av enstaka noteringar är när användaren vid specifika tillfällen gör noteringar om en specifik typ av data. Noteringarna kan vara i form av undersökningar som en applikation gör. Post hoc-redigering görs, till skillnad från de andra typerna av insamling, i efterhand eftersom det rör sig om redigering av befintlig data. Med hjälp av de olika typerna av insamling som Ohlin et al[11] beskriver kommer vår studie att undersöka hur existeran-de verktyg kan möta existeran-de krav vardagsanvändare ställer på sina verktyg vid hantering av ofullständig data.
2
Metod
I denna del presenteras det tillvägagångssätt som valts för att samla in den data som vi vill analysera. Detta innebär en redogörelse för metodvalet, hur andra studier med samma metodval har gått till väga samt hur vi har valt att fortskrida.
2.1 Enkätstudier
Boken Enkäten i praktiken[4] har använts som grund för hur enkäten för denna studie utformats. Vid en sökning, med verktyget Google Scholar, efter andra studier där denna bok refererats till kunde 1485 resultat uppbringas. Detta indikerar att boken utgör en stadig grund för hur en enkätstudie skall utformas.
I Enkäten i praktiken[4] rekommenderas det att avgränsa de områden som är aktuella för undersökningen. Detta har vi gjort genom att ställa frågor om antalet verktyg som användarna brukar, hur länge de har brukat dem och vilken funktionalitet som de upplever att verktygen saknar. Fortsatt uppmuntrar Ejlertsson[3] till att undersöka bakgrundsfak-torer så som ålder, kön och yrke för att ha möjlighet att urskilja eventuell snedvinkling i undersökningen.
Sedan bör man avgränsa vilket område som ska undersökas[4]. Detta görs genom att först välja ett huvudområde. I denna studie är det ”personal informatics” och bakgrunds-faktorer. Området skall sedan brytas ner till de olika delar undersökningen intresserar sig för. För ”personal informatics” skapas följande områden: namnet på verktyget, hur länge en användare använt verktyget, hur länge de använt självloggningsverktyg, anledningen till valet av verktyg, saknad funktionalitet och om de flyttat till verktyget från ett annat verk-tyg. För bakgrundsfaktorer skapas följande områden: ålder, kön, utbildning och erfarenhet av dataanalys. Dessa områden bryts sedan ner till de frågor som deltagarna svarat på.
Frågorna i enkäten uppmuntras att vara entydiga[4]. Detta har respekterats i alla frågor utom den om funktionalitet där studien står att vinna mycket på den tolkning användaren gör av frågan. Resultatet av svaren på den frågan presenteras i resultatdelen av studien. Angående svarsfrekvensen förklarar Ejlertsson att antalet deltagare oftast är lågt vid en
webbaserad enkätundersökning. Därför får 30 deltagare anses vara ett högt antal eftersom enkäten riktar sig till en väldigt specifik grupp.
I kapitlet Före Enkäten[4] förklaras det att motivation för att svara på en enkät kan delas upp i två typer. Dessa typer är den inre motivationen samt den yttre motivationen. Inre motivation beskrivs som den starkaste drivkraften för att delta i en undersökning. Intresse för enkäten och ämnet den behandlar samt deltagarens egna vilja spelar en stor roll för om en intressent ska välja att delta. Därför måste deltagaren känna att den egna insatsen hjälper till att uppnå något. Den inre motivationen för att delta i denna undersökning har varit undersökningen själv eftersom den kan ge användare ett sätt att påverka den framtida utvecklingen inom området. Yttre motivation kan vara i form av en belöning för deltagandet. Det kan också vara känslan av att ha gjort en insats. Den yttre motivationen liknar därför den inre motivationen för denna studie eftersom den också riktar sig till deltagare som vill göra en insats i form av att tillhandahålla tankar om den funktionalitet som erbjuds i deltagarens verktyg. Belöningen kan komma i form av förbättringar till diverse verktyg.
2.2 Datainsamling
Undersökningen som denna artikel är baserad på har genomförts med hjälp av en webba-serad enkät som är skapad med hjälp av verktyget Google Forms. Med syfte att få ett högt deltagande från vardagsanvändare men också för att få tag på användare som har lite mer kompetens i användandet av självloggning men som ändå inte kan räknas till extreman-vändare så publicerades en länk till enkäten på författarens privata Facebooksida, på en privat Facebooksida tillhörande en vän till författaren som studerar med inriktning maski-ningenjör, på Twitterkontot för en lärare vid Fakulteten för teknik och samhälle på Malmö Högskola, i en Facebookgrupp som riktar sig till programmerare och i en Facebookgrupp som riktar sig till studenter på Malmö Högskola.
Som underlag för hur enkäten utformades användes Enkäten i praktiken - En handbok i enkätmetodik[4]. Valet av en webbaserad enkät gjordes eftersom målgruppen är lättare att finna samt nå ut till via internet. Det har även underlättat processen eftersom det på så satt möjliggjort skapandet av nya iterationer av enkäten fortare och samtliga svar har kunnat exporteras med hjälp av ett tillägg for Google Forms som skapar ett kalkylblad i Google Sheets for all insamlad data. Med målet att insamlad data ska vara hanterbar har antalet verktyg som det går att fylla i information om begränsats till fem stycken. För att lättare identifiera vardagsanvändare och expert eller extremanvändare, har deltagarna tillfrågats om deras högskoleutbildning och om de har läst en eller flera kurser där analys av data har varit en del av det primära läromålet. Frågor om ålder och kön har också ställts för att möjliggöra identifiering av eventuella snedvinklingar.
Enkäten har följande introduktionstext för att förklara för deltagarna vad som menas med självloggningsverktyg:
Självloggningsverktyg är en försvenskning av begreppet ”personal informatics” och syftar till verktyg med vars hjälp data kan samlas in under en period för att sedan analyseras. Det kan till exempel vara ett smartband som håller reda på din puls under olika aktiviteter, en applikation som spårar dina framsteg när du tränar eller en som hjälper dig att hålla koll på dina kostvanor. Den här enkäten har som mål att undersöka vad som motiverar olika typer av användare och vad som kan få dessa användare att byta verktyg.
• Ålder • Kön
• Läser du eller har du läst en utbildning på höskolenivå?
• Har du läst en eller flera kurser där analys av data har varit det primära läromålet? • Hur länge har du använt verktyg för självloggning?(Ange antal månader)
• Om du har läser eller har läst en utbildning på högskolenivå. Vilket är/var ditt huvudområde?
Efter föregående frågor så har följande frågor ställts för respektive verktyg(maximalt fem stycken).
• Namnet på verktyget?
• Ange hur länge du har använt verktyget(Ange antalet månader som du har använt verktyget)
• Använder du det här verktyget just nu? • Varför valde du detta verktyg?
• Finns det någon funktion som du tycker att detta verktyg saknar?
• Om du flyttade till detta verktyg från ett annat. Vad var då anledningen till bytet av verktyg?
2.3 Dataanalys
Insamlad data har blivit validerad genom att svaren på frågan om vilken funktionalitet användarna saknar kategoriserats. Kategorierna har sedan jämförts med tidigare studier, till exempel de typer av spårning Rooksby[14] identifierat. Genom att jämföra med tidi-gare studier går det att komma fram till om upptäckta mönster är rimliga. Kategorierna presenteras i form av en tabell under rubriken Saknad funktionalitet i resultatdelen av artikeln.
Att använda en enkät för att samla in data har gjort det möjligt att urskilja eventuella mönster bland personerna som deltagit i studien. Detta hade varit svårare att uppnå genom intervjuer då det inte skulle ha funnits tillräckligt med tid för att intervjua tillräckligt många användare. Det hade dessutom blivit svårare att hantera data från personer som använder eller har använt flera verktyg. Även om många av deltagarna inte använder mer än ett eller två verktyg behövde vi ändå använda en metod där det var lättare att få överblick över insamlade data.
3
Resultat
I den här sektionen presenteras en sammanställning av resultatet från den gjorda under-sökningen. Totalt har 30 personer deltagit i underunder-sökningen. Sammanställningen består huvudsakligen av en presentation av saknad funktionalitet i självloggningsverktyg som deltagarna har uttryckt behov av. Detta presenteras med hjälp av en tabell(tabell. 2) där svaren har delats in i kategorier. Hur kategorierna definierats beskrivs efter tabellen. Efter presentationen av tabellen presenteras externa faktorer och hur dessa har påverkat resulta-tet. I diskussionsdelen av artikeln kommer vi att systematiskt diskutera respektive aspekt av resultaten.
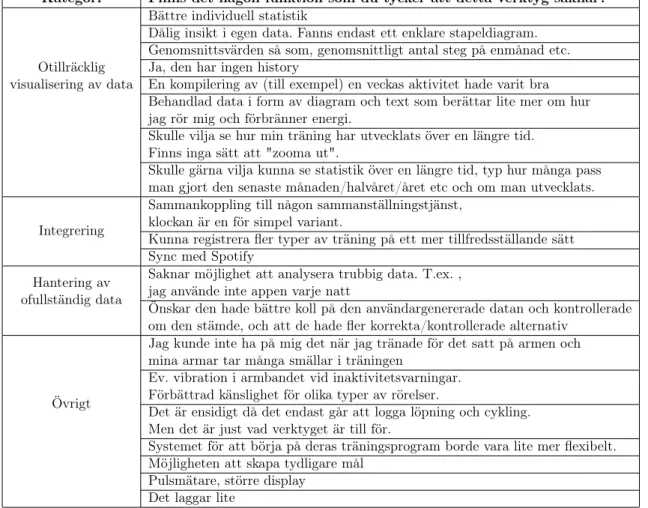
3.1 Saknad funktionalitet
Svaren som vi fick på frågan ”Finns det någon funktion som du tycker att detta verktyg saknar?” har infogats i en tabell(tabell. 2) för att tydligt visa vilka områden som det går att kategorisera efterfrågade funktioner i. Några av svaren har sorteras bort eftersom de inte var relevanta. Ett exempel på ett sådant svar är ”det laggar lite”. Eftersom det inte är verktygens prestation på det sättet som ska undersökas har det inte varit relevant att inkludera sådana svar.
Otillräcklig visualisering av data är den kategori där kommentarer från användare ham-nar om dessa reflekterar behov av avläsning av data på ett sätt som inte kan tillgodoses av det aktuella verktyget. Kommentarer under kategorin integrering berättar om behov som användare har för hur diverse verktyg ska kunna arbeta med varandra. Behoven be-höver nödvändigtvis inte involvera andra självloggningsverktyg. Hantering av ofullständig data är en kategori där användarna har uttryckt sig kring hur deras valda verktyg hante-rar datainsamlingen när de till exempel inte använder verktyget under en period. Under Övrigt hittar vi kommentarer som inte kan kategoriseras tillsammans med några andra kommentarer eftersom de är specifika för ett speciellt verktyg eller en aktivitet.
3.2 Motivation
Åtta av användarna som deltog i undersökningen angav att de valde sitt verktyg utifrån upplevd popularitet eller för att en vän rekommenderat det. 14 deltagare valde verktyget utifrån den typ av spårning de intresserade sig för. De var i många av fallen medvetna om vilka funktioner verktyget erbjöd och hur de kunde uppnå sina mål med hjälp av det. Ett exempel på detta är deltagaren som motiverade sitt val av applikationen Lifesum genom följande mening ”Bra funktioner så som att scanna EAN- koder, stor databas över livsmedel, bra gränssnitt”. Fyra deltagare angav att de börjat använda sina verktyg för att det följt med ett verktyg eller för att de fått det som en gåva. Två deltagare angav att de valde verktygen av nyfikenhet, t.ex. med motiveringen ”Appen såg tilltalande ut i Play Store och jag var nyfiken på att tracka sömn”. En användare angav behandling som anledning till sitt val, eftersom det svaret tillhör verktyget CogMed så antar vi att det blivit rekommenderat av en arbetsterapeut eller liknande. Den sista deltagen angav ingen anledning till sitt användande av verktyget. Med hjälp av dessa svar kunde vi bilda följande kategorier för vad som motiverade användarnas val av verktyg: social uppmuntran, förbättring av en aktivitet och nyfikenhet. Kategorierna som vi har skapat kommer att jämföras med kategorierna från
Tabell 2: Funktioner som deltagarna i undersökningen upplever saknas eller kan förbättras.
Kategori Finns det någon funktion som du tycker att detta verktyg saknar?
Otillräcklig visualisering av data
Bättre individuell statistik
Dålig insikt i egen data. Fanns endast ett enklare stapeldiagram. Genomsnittsvärden så som, genomsnittligt antal steg på enmånad etc. Ja, den har ingen history
En kompilering av (till exempel) en veckas aktivitet hade varit bra Behandlad data i form av diagram och text som berättar lite mer om hur jag rör mig och förbränner energi.
Skulle vilja se hur min träning har utvecklats över en längre tid. Finns inga sätt att "zooma ut".
Skulle gärna vilja kunna se statistik över en längre tid, typ hur många pass man gjort den senaste månaden/halvåret/året etc och om man utvecklats.
Integrering
Sammankoppling till någon sammanställningstjänst, klockan är en för simpel variant.
Kunna registrera fler typer av träning på ett mer tillfredsställande sätt Sync med Spotify
Hantering av ofullständig data
Saknar möjlighet att analysera trubbig data. T.ex. , jag använde inte appen varje natt
Önskar den hade bättre koll på den användargenererade datan och kontrollerade om den stämde, och att de hade fler korrekta/kontrollerade alternativ
Övrigt
Jag kunde inte ha på mig det när jag tränade för det satt på armen och mina armar tar många smällar i träningen
Ev. vibration i armbandet vid inaktivitetsvarningar. Förbättrad känslighet för olika typer av rörelser.
Det är ensidigt då det endast går att logga löpning och cykling. Men det är just vad verktyget är till för.
Systemet för att börja på deras träningsprogram borde vara lite mer flexibelt. Möjligheten att skapa tydligare mål
Pulsmätare, större display Det laggar lite
Tabell. 1 i diskussionsdelen av denna artikeln för att jämföra skillnaderna mellan motivering för extremanvändare och vardagsanvändare.
3.3 Externa faktorer
16 män och 14 kvinnor deltog i undersökningen. Endast tre av dessa var över 30 år gamla men inget i deras svar utmärker sig till synes på grund av detta. Utbildningsmässigt svarade samtliga av deltagarna att de läser eller har läst en utbildning på högskolenivå. Tolv av deltagarna har inte läst en eller flera kurser där analys av data har varit det primära läromålet och 18 stycken har läst en eller flera kurser med det som det primära läromålet. Av dessa 30 deltagare angav tolv stycken datavetenskap eller närliggande fält som sitt huvudområde, fyra deltagare studerade till någon typ av ingenjör, två stycken studerade litteraturvetenskap, två studerade medicin, två stycken studerade ekonomi, två stycken studerade juridik, en studerade grafisk design, en studerade väg och samhällsplanering, en studerade medie- och kommunikationsvetenskap, en studerade samhällsvetenskap och en studerade fysioterapi.
4
Diskussion
I denna del av artikeln jämförs resultaten, från undersökningen som gjorts, med mönster från tidigare studier. Resultaten blir validerade genom att identifiera likartade mönster från tidigare studier. Efter att resultaten blivit validerade diskuteras fynden och den inverkan problem kan ha på marknaden om de inte åtgärdas. Förslag på hur problemen kan lösas diskuteras också.
4.1 Saknad funktionalitet
I denna del av diskussionen återkopplar vi till kommentarerna om saknad funktionalitet med hjälp av fynd från tidigare studier eller förslag på verktyg som uppfyller de önskemål användaren har. Flera av de barriärer Li[10] nämner som problem för bredare adoptering av självloggningsverktyg går att känna igen i resultatet(tabell. 2) från undersökningen som gjorts för denna artikel. Barriärerna är olämplig visualisering av data, olämpliga verktyg och fragmenterad data som är spridd över flera plattformar. Barriärerna visar sig till ex-empel i kommentarerna ”Dålig insikt i egen data. Fanns endast ett enklare stapeldiagram” och ”Sammankoppling till någon sammanställningstjänst, klockan är en för simpel variant”. 4.1.1 Visualisering
Problem med bristande visualisering har visat sig i kommentarer som ”Dålig insikt i egen data. Fanns endast ett enklare stapeldiagram” och ”Behandlad data i form av diagram och text som berättar lite mer om hur jag rör mig och förbränner energi” i den studie som vi har genomfört. Det är i detta sammanhang viktigt att lyfta fram fynden från den studie som Epstein et al[5] gjorde 2014. Där framgår det att insikten i den egna datan kan förbättras genom att inte enbart presentera information som tillhör de mål användaren satt upp. Användaren kan på detta sätt utforska korrelationer i sina rutiner som inte annars skulle upptäckts men som ändå leder till en djupare insikt i den egna datan.
4.1.2 Integrering
Användaren som gav kommentaren ”Sammankoppling till någon sammanställningstjänst, klockan är en för simpel variant” om sitt valda verktyg använde sig av Nike+ som är en simplare variant av en smartklocka. Den kan spåra förbrända kalorier, historik och rekord. Att klockan är för simpel kan inte åtgärdas på annat sätt än genom ett byte av verktyg. Sammankopplingen kan lösas genom användande av till exempel Google Fit[8] som är kompatibelt med Nike+. Mer om Googles roll inom ”personal informatics” tas upp under rubriken Möjliga lösningar.
Kommentaren ”Kunna registrera fler typer av träning på ett mer tillfredsställande sätt” tolkas som att användaren inte är nöjd med sättet som verktyget loggar flera typer av träning eftersom kommentaren var om verktyget Lifesum som är gjort för att samla in data om olika typer av träning. Studien hade behövt mer information om detta fall eftersom Lifesum kan sammankopplas med andra verktyg så som Runkeeper, Fitbit och Google Fit och det blir förblir därför oklart varför insamlandet av data inte är tillfredställande för användaren. Kommentaren kan även tolkas som att den information användaren får tillbaka från appen efter registrering av flera typer av träning inte är tillfredställande
En deltagare i studien gav kommentaren ”Sync med Spotify” som en funktion som saknades i verktyget S health. S health är inriktat på att agera som en pedometer och som ett sätt att spåra löpning men kan också arbeta med andra självloggningsverktyg och det skulle på så sätt vara möjligt för användaren att använda ett till verktyg som har den saknade funktionen och sammanställa träningen i S health. Om det är verktygets pedometer användaren vill åt skulle det vara möjligt att lösa problemet med hjälp av iPod nano som har en inbyggd pedometer och möjlighet att spela upp musik från Spotify. Om det är löpningen användaren intresserar sig för kan Runkeeper vara ett effektivt verktyg eftersom det där går att välja att sammankoppla verktyget med Spotify. Problemet som kan uppstå om användaren inte har möjlighet att synkronisera sin musik med verktyget är att motivationen inte blir lika hög och därför uppnås målet inte lika effektivt eller inte alls 4.1.3 Hantering av ofullständig data
Post hoc-redigering[11] är ett möjligt hjälpmedel för användare som kan känna igen sig i kommentaren ”Saknar även möjlighet att analysera trubbig data. T.ex. , jag använde inte appen varje natt.”. Med denna typ av redigering får användaren möjlighet att gå tillbaka och fylla i saknad eller ofullständig data. Om användaren inte kan åtgärda de tillfällen då data inte samlats in, trots användarens önskemål om att samla in, kan den negativa effekten bli att användaren inte når sitt utsatta mål.
4.2 Mönster i användandet
Det har inte gått att urskilja något mönster mellan användarna som läst kurser om dataa-nalys och användarna som inte har gjort det. Ålder eller kön har ingen märkbar påverkan på preferens av verktyg eller funktioner i denna studie. Från de insamlade svaren går det däremot att fastslå att ett verktygs popularitet påverkar valet mer än om användarna själva anser verktyget vara tillräckligt för deras behov.
De olika typerna av spårning Rooksby[14] har identifierat i sin studie går att känna igen till viss del i de problemområden(tabell. 2) som identifierats i undersökningen i denna
artikel. Direktivspårning går att känna igen i form av kommentarer angående att infor-mation saknades för ”Möjligheten att skapa tydligare mål” och ”Systemet för att börja på deras träningsprogram borde vara lite mer flexibelt”.
Spårning med syfte att dokumentera[14] går tydligt att se i resultaten från undersök-ningen som genomförts för denna studie. Flera användare saknar funktioner som ”den har ingen history”, ”Det är ensidigt då det endast går att logga löpning och cykling” och ”Kunna registrera fler typer av träning på ett mer tillfredsställande sätt”. Det råder en viss tveksam-het om implementation av dessa funktioner skulle leda till att användarna skulle placeras i kategorin direktivspårning istället eller om de skulle vara nöjda med att dokumentera mer effektivt. Ett problem som skulle kunna uppstå är om de vill komplettera spårningen med hjälp av andra verktyg. Rooksby[14] förklarar att problem uppstår inte vid spårandet av data med hjälp av flera verktyg utan när data av samma typ ska sammanställas från mer än ett verktyg. Då kan ett verktyg riskera att skriva över data som importerats från ett annat verktyg.
Li[10] identifierar flera problem om användare istället skulle välja ett nytt verktyg för att effektivisera sin spårning. Han anser att det kan vara svårt för användare att flytta till ett nytt verktyg eftersom det många gånger antingen inte går att exportera data eller att export av data är möjligt men inte i ett format som fungerar med verktyget användaren vill flytta till.
Diagnostiserande spårning[14] visade sig bara i en kommentar ”Behandlad data i form av diagram och text som berättar lite mer om hur jag rör mig och förbränner energi” men är tillräckligt tydlig för att kunna placera den i kategorin för diagnostiserande spårning. Som denna artikel tidigare tagit upp kan diagnostiserande spårning vara problematisk enligt Calvo och Peters[3] om användaren inte litar på sin insamlade data, om användaren om-tolkar sammanhanget som datan samlades in i eller om den omtolkas externt av verktyget eller användarens sociala krets. Lösningen på de nämnda problemen kan enligt författarna vara anpassbara teknologier, profilering, ”data mining” och utökad metadata, det vill säga data om insamlad data.
Precis som i studien Rooksby genomfört är det tydligt att belönande spårning är sam-mankopplad med den dokumentära spårningen. Kommentaren ”Skulle gärna se statistik över en längre tid, typ hur många pass man har gjort den senaste månaden/halvåret/året etc och om man har utvecklats” visar på en användare som både skulle kunna vara en del av kategorin för dokumentär spårning och belönande spårning. Önskan om information kring utveckling som skett inom träningen kan tolkas som att användaren vill sätta upp eller har satt upp mål samtidigt som det finns en önskan om att få överblick över den totala mängden av genomförd träning.
Den sista typen av spårning där användare enbart intresserar sig för att samla in data och inte för att undersöka går att se tydliga spår av i ett av svaren på frågan om varför användarna valde sitt verktyg. En av deltagarna i studien svarade där ”Appen såg tilltalande ut i Play Store och jag var nyfiken på att tracka sömn”. Personen i fråga förväntar sig inte några resultat från spårningen. Istället ligger intresset i själva spårningen. I ett senare stadie kan intresset öka och där med falla inom en annan typ av spårning. Det är dock inget som vi funnit bevis för i detta fall.
4.3 Jämförelse av motivering
I tabell 1 presenterades de motiveringar som extrema användare hade till att spåra data. Anledningarna var att förbättra hälsa, förbättra andra aspekter i livet och för att finna nya livsupplevelser. De motiveringar som deltagarna i vår studie angav bildade kategori-erna: social uppmuntran, förbättring av en aktivitet och nyfikenhet. Motiveringarna från extremanvändarna går till viss del att likna med de hos de användare som vi har valt att kalla nyckelanvändare. Tidigare har nyckelanvändare inom personlig databehandling varit extremanvändarna. När vardagsanvändare sedan blivit inkluderade i denna grupp, som de har blivit i denna studie, går det att se att användarens sociala krets blivit en viktig del i motivationen till att spåra data. Många av användarna förklarade att sociala funktioner i applikationer var betydelsefulla vid deras val av verktyg. Det var också viktig för använda-ren att deras vänner använde samma verktyg så att de kunde jämföra sina resultat. Detta är ett viktigt fynd eftersom det antyder att verktyg åtminstone behöver ha funktionalitet som låter användare jämföra resultat.
Motivet ”att förbättra hälsa” hos extremanvändare är jämförbart med ”förbättring av en aktivitet” från vår studie. Trots att ”förbättring av en aktivitet” inkluderar både spårning av matvanor och ekonomi utöver träning liknar vår kategori ”att förbättra hälsa”. Eftersom det var den kategori som majoriteten av deltagarna från vår studie hamnade inom går det att se att det största användningsområdet för självloggning förblir betydelsefullt även när vardagsanvändare blivit en del av nyckelanvändarna.
Extremanvändarnas intresse för att hitta nya livsupplevelser är lik den nyfikenhet som användarna från vår studie uttryckt. Denna typ av motivation styrs av viljan att upptäcka eller lära sig något nytt. Förväntningarna av resultat är därför inte en betydande del av användandet. Att en sådan kategori framgår hos båda typerna av användare indikerar att självloggning inte alltid behöver vara användbar för att tillfredsställa användarens behov. Fyndet kan betyda att marknaden har plats för en typ av självloggning där underhållnings-värde har en mer betydande roll än potentialen till förbättring.
4.4 Möjliga lösningar
Ett problem vardagsanvändare stöter på som inte varit ett problem för de mer kunniga användarna är behovet av visualisering. Det är tydligt att denna grupp förväntar sig att verktyget ska göra betydligt mer än hjälpa till med insamling av data. Existerande och framtida verktyg kommer behöva erbjuda fler möjligheter till visualisering av data. Detta kan ske både genom sammanställningar av den totala data som samlats in, en visualisering som presenterar den dagliga loggningen och möjligheter för att anpassa den efter individens behov. Kort sagt behöver personlig databehandling bli mer personlig. I en artikel[9] från 2015 föreslår en grupp forskare förslag på förbättringar av visualisering baserat på fynd i deras tidigare studier. Författarna vill med sin artikel ge designförslag som kan göra resultat mer överskådliga för användare. Det första förslaget är att uppmuntra användare till att spåra förändringar i sin data oftare. De föreslår att förändringarna skulle presenteras som ett aktivitetsflöde som kontinuerligt uppdateras med små förändringar så att det hela tiden ska finnas ett nytt stycke av information att undersöka. En sådan design skulle leda till att användaren skulle hålla sig informerad utan att behöva göra en omfattande reflektion i slutet av en insamlingsperiod. Det är en funktionalitet som främst gynnar vardagsanvändare som får samma möjlighet att förbättra sig som de extremanvändare
som har förmågan att göra utförliga reflektioner av stora mängder data. Därför behövs vidare forskning kring hur presentation av sådan information bör ske.
Eftersom vi även kan se mönster bland användarna som tyder på att det finns behov av att verktyg och tjänster interagerar med varandra kommer en standard behöva tas fram för hur kommunikationen ska ske. Den kommer att behöva vara utbyggbar till följd av att nya typer av verktyg för självloggning kommer ut på marknaden regelbundet. Om det inte är möjligt att finna en sådan standard behöver insamlad data sparas i ett format som gör att det blir lätt att exportera data till ett kompletterande verktyg. Extrema användare kan troligtvis arbeta sig runt sådana hinder. Vardagsanvändare har inte liknande kunskaper för att ta sig runt sådana barriärer. Det är därför viktigt att export och import av data görs så lätt som möjligt. Det finns redan tjänster som försöker göra detta men dessa tjänster ägs av Apple[1] och Google[8]. Det är därför troligt att marknaden kan påverkas negativt om ett av dessa företag skulle få för mycket kontroll över data från användare av olika självloggningsverktyg. Ett möjligt scenario är att konkurrerande självloggningsverktyg er-bjuder bättre funktionalitet än företaget med monopol. Men de kan inte erbjuda ett lika sömlöst flöde av data eftersom de inte har ett operativsystem till sin förfogande, i vilket de kan integrera egna självloggningsverktyg. Ett exempel på en konkurrerande tjänst till de som tillhandahålls av Apple och Google är verktyget Lifesum. Lifesum är ett verktyg som låter användare spåra olika former av träning både genom själva verktyget och genom import av data från andra utvalda självloggningsverktyg. Det är dock möjligt för Apple[1] och Googles[8] verktyg att importera data från Lifesum.
En standard bör därför istället ha målet att vara så öppen som möjligt för att låta användarna behålla kontrollen över deras data och på så sätt låta dem bestämma över vilken tjänst de vill använda utifrån vilken som för tillfället erbjuder önskvärd funktionalitet.
Ett annat exemplet på vidare forskning som bör genomföras är sådan som behandlar skalbarhet i självloggningsverktyg. Det vill säga hur ett verktyg bäst kan uppnå en design där verktyget anpassar sig efter användarens behov för stunden. Exempel på detta kan vara verktyg för träning som under träningen visar en jämförelse mellan hur en användare presterar under träningen som genomförs och det bästa resultatet som användaren har uppnått under samma aktivitet vid tidigare tillfällen. När användaren sedan är färdig med träningspasset så uppstår kanske ett annat behov, att användaren vill se all historik istället för det bästa resultatet.
4.5 Utökad användargrupp
Från den jämförelse med tidigare studier som gjorts går det att se att när vardagsanvändare blivit inkluderade som en del av nyckelanvändare kvarstår nästintill samma mönster som identifierats med hjälp av expert- och extremanvändare. Däremot skiljer sig motiveringen till spårandet. Där spelar social uppmuntring en stor roll för vardagsanvändare. De har alltså en benägenhet att kommunicera sina framsteg med sin sociala krets, vilket de mer extrema användarna inte har.
Den sociala kommunikationen behöver också utforskas på det sätt som Gouveia et al[9] föreslår. Alltså undersöka om visualisering av insamlad data i form av aktivitetsflöden som kontinuerligt uppdateras.
Därför behöver framtida forskning undersöka hur denna den sociala företeelsen kan hjälpa vardagsanvändare att uppnå sina mål. Studien har även upptäckt att det går att
identifiera en grupp av användare som är missnöjda med verktyg de valt men som ändå håller fast vid det. Det går här att se ett behov av fortsatt forskning om varför de inte väljer att flytta till ett nytt verktyg eller komplettera med ett till verktyg om de känner att det första inte är tillräckligt. En förklaring till varför det är så kan vara att de inte känner till andra verktyg på grund av att de fick det första rekommenderat från en bekant.
5
Slutsatser och vidare forskning
Denna artikel hade som syfte att undersöka skillnaden mellan vardagsanvändare och ex-tremanvändare efter att den förstnämnda användartypen introducerats till användartypen nyckelanvändare. Vi ville också undersöka hur vardagsanvändare kan övervinna de barriärer som uppstår till följd av att de inte kan arbeta sig runt problemen med teknisk kompetens, så som extremanvändarna gör.
Genom att studera de användarmönster som tidigare studier identifierat och sedan jämföra dessa med resultatet från vår undersökning har vi kunnat validera våra fynd. Vår data blev validerad genom att samma typer av spårning som identifierats i tidigare studier kunde återfinnas i våra resultat. Det gick också att se likartade mönster i den motivering som extremanvändare har när vardagsanvändarnas motivering jämfördes med denna. Den största skillnaden var att vardagsanvändarna utmärkte sig genom ett stort intresse för en social interaktion med sin data. Det vill säga genom att dela sin data med sin sociala krets för att jämföra resultat.
Att låta vardagsanvändare anta rollen som nyckelanvändare har vi funnit nya områ-den för fortsatta studier. Forskning som behöver göras för att öppna upp självloggning för vardagsanvändare är: utveckling av ett flexibelt och öppet format för export samt im-port av data, skapandet av en typ av integrering som ger användare större möjlighet att komplettera ett verktyg med andra verktyg och skalbarhet som sker efter användarmöns-ter. Forskning kring dessa områden kan hindra personlig databehandling och självloggning från att förbli fritidsintressen enbart för expert- och extremanvändare. Det skulle ge även vardagsanvändare samma möjligheter att förbättra sina liv genom sådana verktyg.
Referenser
[1] Apple Inc. Apple HealthKit[Internet]. 2016 [cited 2016 januari 10]. Available from: https://developer.apple.com/healthkit/
[2] E.K. Choe, N.B. Lee, B. Lee, W. Pratt, J.A. Kientz. Understanding quantified- sel-fers’ practices in collecting and exploring personal data. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (2014) 1143-1152.
[3] R.A. Calvo, D. Peters. The irony and re-interpretation of our quantified self. In Proceedings of the 25th Australian Computer-Human Interaction Conference: Aug-mentation, Application, Innovation, Collaboration (2013) 367-370.
[4] G. Ejlertsson, Enkäten i praktiken - en handbok i enkätmetodik. 3rd ed. Lund: Stu-dentlitteratur AB, c2014.
[5] D.A. Epstein, F. Cordeiro, E. Bales, J. Fogarty, S.A. Munson. Taming data complex-ity in lifelogs: exploring visual cuts of personal informatics data. In Proceedings of the 2014 conference on designing interactive systems (2014) 667-676.
[6] Fitbit Inc. Fitbit[Internet]. 2016 [cited 2016 januari 10]. Available from: https://fitbit.com
[7] Fitbit Inc. Fitbit Aria[Internet]. 2016 [cited 2016 januari 10]. Available from: https://fitbit.com/aria
[8] Google Inc. Google Fit[Internet]. 2016 [cited 2016 januari 10]. Available from: https://www.fit.google.com/fit
[9] R. Gouveia, S.A. Munson, E. Karapanos, A. Caraban, F. Pereira. You have 5 se-conds: designing glancable feedback for physical activity trackers. In Proceedings of the 2015 ACM international joint conference on pervasive and ubiquitous ting and proceedings of the 2015 ACM international symposium on wearable compu-ters (2015) 643-647.
[10] I. Li, A. Dey, J. Forlizzi. A stage-based model of personal informatics systems. In Performance, Stagecraft, and Magic (2010) 557-566.
[11] F. Ohlin, C.M. Olsson. Intelligent computing in personal informatics: key design con-siderations. In Personalization/Adaptation/Recommendation/Sentiment (2015) 263-274.
[12] F. Ohlin, C.M. Olsson, P. Davidsson. Analyzing the design space of personal in-formatics: a state-of-practice based classification of existing tools. In Proceedings of HCI International Conference Universal Access In Human Computer Interaction (2015) 85-97.
[13] I. Li. Personal Informatics[Internet] 2013 [cited 2015 oktober 8] Available from: www.personalinformatics.org
[14] J. Rooksby, M. Rost, A. Morrison, M. Chalmers. Personal tracking as lived informa-tics. In One of a CHInd (2014) 1163-1172.
[15] FitnessKeeper, Inc. Runkeeper[Internet]. 2016 [cited 2016 januari 10]. Available from:https://www.runkeeper.com
[16] E. Von Hippel, The sources of innovation. 1st ed. Oxford: Oxford University Press. c1988.
[17] G. Wolf. The Data-Driven Life. New York Times Magazi-ne[Internet]. 2010 april 28[cited 2015 oktober 8]. Available from: http://www.nytimes.com/2010/05/02/magazine/02self-measurement-t.html
![Tabell 1: Varför användare spårar data och vilken data som spåras[2].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4149324.89128/9.892.122.758.196.712/tabell-användare-spårar-data-data-spåras.webp)