VTI rapport 1010
Utgivningsår 2019
www.vti.se/publikationer
Prognosmetoder för spårdjup och IRI
Vägytedata 1997–2016
Olle Eriksson
Peter Andrén
VTI r apport 1010 | Pr ognosmetoder för spårdjup och IRI. V
VTI rapport 1010
Prognosmetoder för spårdjup och IRI
Vägytedata 1997–2016
Olle Eriksson
Peter Andrén
Författare:
Olle Eriksson, VTI
Peter Andrén, VTI
Diarienummer: 2013-0673/9.1
Omslagsbilder: Hejdlösa Bilder AB
Utgiven av VTI, 2019
Referat
Rapporten presenterar ett förslag till en prognosmetod för framtida värden av spårdjup och IRI på det
belagda statliga vägnätet samt olika mått på prognosnoggrannhet. Metoden kan även användas för att
fylla i saknade värden bakåt i tiden.
En tidigare VTI rapport inom samma område kom fram till att ett prognosunderlag endast ska
inne-hålla information om utvecklingen lokalt och baserade sin prognos på data endast från den senaste
beläggningsomgången. En väsentlig förändring här är att metoden utvidgats till att inkludera data från
tidigare beläggningsomgångar i prognosberäkningen, med redovisning av de för- och nackdelar som
det medför. Andra delar, t.ex. hur data förbereds, har inte ändrats i någon större utsträckning.
Resultaten blir i huvudsak att prognoser inte blir tydligt bättre generellt, inte heller tydligt sämre, av att
ta med data från tidigare beläggningsomgångar. Det fnns ändå en fördel med att ta med dem därför att
fer sträckor över huvud taget kan få en prognos baserad på lokala förutsättningar.
Titel:
Prognosmetoder för spårdjup och IRI. Vägytedata 1997–2016
Författare:
Olle Eriksson (VTI, www.orcid.org/0000-0002-5306-2753)
Peter Andrén (VTI, www.orcid.org/0000-0002-4317-6351)
Utgivare:
VTI, Statens väg- och transportforskningsinstitut
www.vti.se
Serie och nr:
VTI rapport 1010
Utgivningsår:
2019
VTI:s diarienr:
2013-0673/9.1
ISSN:
0347-6030
Projektnamn:
Prognosmodeller för vägytemått 2013-2015
Uppdragsgivare:
VTI
Nyckelord:
Prognosmetod, prognosintervall, regressionsanalys, IRI, spårdjup,
Pavement Management System, PMS
Språk:
Svenska
Abstract
This report presents a proposal for a prediction method for future values of rut depth and IRI on the
paved state road network and various measures of forecast exactness. The method can also be used to
fll in missing values backward in time.
An earlier VTI report within the same area concluded that a prediction method should use only data
about the development locally and based its prediction on data from the current pavement cycle only.
A major di˙erence here is that the method has been expanded to include data from previous pavement
cycles in the prediction method, with presentation of the advantages and disadvantages that this entails.
Other parts, e.g. how data is prepared, has not been changed in any great extent.
The results are mainly that forecasts do not generally become clearly better, nor clearly worse, by
in-cluding data from previous pavement cycles. There is nevertheless an advantage in inin-cluding these data
because that makes prediction based on local conditions possible for more sections.
Title:
Prediction methods for rut depth and IRI. Road surface data 1997–2016
Author:
Olle Eriksson (VTI, www.orcid.org/0000-0002-5306-2753)
Peter Andrén (VTI, www.orcid.org/0000-0002-4317-6351)
Publisher:
Swedish National Road and Transport Research Institute (VTI)
www.vti.se
Publication No.:
VTI rapport 1010
Published:
2019
Reg. No., VTI:
2013-0673/9.1
ISSN:
0347-6030
Project:
Prediction models for road surface data 2013-2015
Commissioned by:
VTI
Keywords:
Prediction method, prediction interval, regression analys, IRI, rut depth,
Pavement Management System, PMS
Language:
Swedish
Förord
Författarna och projektledaren tackar Trafkverket för fnansiering av projektet. Fredrik Lindström har
varit Trafkverkets kontaktperson.
Linköping maj 2019
Olle
Eriksson, Peter Andrén
Kvalitetsgranskning
Extern peer review har genomförts 29 mars 2019 av John Lundström, NCC. Olle Eriksson har
genom-fört justeringar av slutligt rapportmanus. Forskningschef Leif Sjögren har därefter granskat och
god-känt publikationen för publicering 16 april 2019. De slutsatser och rekommendationer som uttrycks är
författarnas egna och speglar inte nödvändigtvis myndigheten VTI:s uppfattning.
Quality review
External peer review was performed on 29 March 2019 by John Lundström, NCC. Olle Eriksson has
made alterations to the fnal manuscript of the report. The research director Leif Sjögren examined and
approved the report for publication on 16 April 2019. The conclusions and recommendations expressed
are the authors’ and do not necessarily refect VTI’s opinion as an authority.
Innehållsförteckning
Sammanfattning . . .
9
Summary . . . 11
1. Inledning . . . 13
1.1. Tillståndsbedömning . . . 13
1.2. Utvalda vägytemått . . . 13
1.3. Tillståndsprognoser . . . 13
1.4. Syfte . . . 13
2. Dataunderlag och redovisningsgrupper . . . 14
2.1. Datakälla . . . 14
2.2. Matchning . . . 14
2.3. Tvättning . . . 14
2.4. Redovisningsgrupper . . . 15
2.4.1. Län . . . 15
2.4.2. Beläggningskategorier . . . 15
2.4.3. Vägkategorier och hastighetsgränser . . . 15
3. Underlag för val av prognosmetod . . . 16
3.1. Tidigare resultat . . . 16
3.2. Andra publikationer . . . 16
3.3. Data från tidigare beläggningsomgångar . . . 19
3.4. Rätlinjigt förlopp . . . 19
3.5. Lika varians . . . 19
4. Förslag till prognosmetod . . . 20
4.1. Linjär regression . . . 20
4.2. Prognosintervall och andra resultat av regressionsanalyser . . . 20
4.3. Sammanvägd variansskattning . . . 21
4.4. Skrivsätt för olika metoder . . . 22
4.5. Linjär regression med nivåskift . . . 22
5. Resultat . . . 23
5.1. Resultatmått . . . 23
5.2. Sammanställda resultat . . . 23
5.3. Resultat uppdelat på redovisningsgrupper . . . 24
5.4. Jämförelser mellan metoderna . . . 24
5.5. Jämförelse mellan spårdjup 17 och spårdjup 15 . . . 25
6. Kontroller . . . 26
6.1. Tillväxttakt före och efter senaste åtgärd . . . 26
6.2. Oberoende mellan tidpunkter och mellan sträckor . . . 26
6.3. Accelererad spårbildning . . . 26
6.4. Initial e˙ekt . . . 26
7. Slutsats . . . 27
8. Diskussion . . . 28
Bilaga A. Matchning . . . 33
Bilaga B. Några speciella problem vid matchning . . . 35
Bilaga C. Tvättningsmetoden . . . 37
Bilaga D. Maskering av uteliggare . . . 43
Bilaga E. Regressionsanalys med nivåskift . . . 45
Bilaga F. Alla resultattabeller . . . 47
F.1. Spårdjup 17 . . . 48
F.1.1. Uppdelning per län och beläggningskategori . . . 48
F.1.2. Uppdelning per län och hastighet . . . 53
F.1.3. Uppdelning per län och vägkategori . . . 58
F.2. Spårdjup 15 . . . 63
F.2.1. Uppdelning per län och beläggningskategori . . . 63
F.2.2. Uppdelning per län och hastighet . . . 68
F.2.3. Uppdelning per län och vägkategori . . . 73
F.3. IRI . . . 78
F.3.1. Uppdelning per län och beläggningskategori . . . 78
F.3.2. Uppdelning per län och hastighet . . . 83
F.3.3. Uppdelning per län och vägkategori . . . 88
Bilaga G. Jämförelse mellan tillväxttakt efter och före åtgärd . . . 93
Bilaga H. Accelererad spår- och IRI-tillväxt . . . 95
Bilaga I. Exempel på längre serier . . . 97
Sammanfattning
Prognosmetoder för spårdjup och IRI – Vägytedata 1997–2016
av Olle Eriksson (VTI) och Peter Andrén (VTI)
Det tekniska tillståndet hos alla belagda statliga vägar bedöms varje år. Underlaget består av mätningar
och kompletteras med prognoser framåt i tiden. Prognoser kan även användas för att fylla i saknade
värden bakåt i tiden.
I ett tidigare arbete baserades prognoser helt på utvecklingen lokalt under den senaste
beläggnings-omgången. Prognosernas precision beror på antalet tidigare mätningar och hur de är fördelade i tid
samt på datakvaliteten. Många gånger behöver de baseras på få mätningar vilket antyder att man kan
ha fördel av att använda representativ tilläggsinformation från en omgivning i tid eller rum. Det som får
störst utrymme i den här rapporten är att undersöka om prognoser av spårdjup och IRI under nuvarande
beläggningsomgång kan förbättras av att även använda data från tidigare beläggningsomgångar.
Den större delen av rapporten beskriver en prognosmetod baserad på multipel linjär regression och
sammanfattar resultat då metoden tillämpas på data från hela det statliga belagda vägnätet under 20 år.
Rapporten behandlar även datakvalitet och beskriver kontroll och tvättning av data.
Resultaten antyder att det är en fördel att använda data från tidigare beläggningsomgångar. Prognoser
blir därmed inte bättre, inte heller sämre, men fer sträckor kan över huvud taget få en prognos baserad
på lokala förutsättningar.
Summary
Prediction methods for rut depth and IRI – Road surface data 1997–2016
by Olle Eriksson (VTI) and Peter Andrén (VTI)
The technical condition of all paved state roads is assessed every year. The assessment is based on
me-asurements that are supplemented with predictions for future values. Predictions can also be used to fll
in missing values backward in time.
In an earlier work, predictions were based entirely on the development locally during the last pavement
cycle. The prediction precision depends on the number of observations, how they are distributed in
ti-me and on the data quality. For many sections, they need to be based on few observations, which
sug-gests that one should beneft from being able to use representative additional information from the
sur-roundings in time or space. A major part of the work in this report is to investigate whether forecasts
of rut depths and IRIs during the current pavement cycle can be improved by also using data from
pre-vious pavement cycles.
The report deals with data quality and describes the control and cleaning of data. The majority of the
report describes a prediction method based on multiple linear regression and summarizes the results
when the method is applied to data from the entire paved state road network for 20 years.
The results indicate that it is an advantage to use data from previous pavement cycles. The predictions
will not be better, nor will they be worse, but more sections can get a prediction based on local
condi-tions.
1.
Inledning
1.1.
Tillståndsbedömning
Det tekniska tillståndet hos alla belagda statliga vägar bedöms varje år. För att få ett bra underlag mäts
vägarnas yta med speciellt utrustade mätfordon. Ojämnheter längs och tvärs vägen m.m. mäts
berörings-fritt med laserljus. Gyron och andra givare används för att mäta vägens geometri samt för att justera för
mätfordonets krängning och liknande rörelser. Vägytemätningen kan användas för att bedöma ytans
till-stånd och, i förlängningen, för att kontrollera hur kvalitetsmål uppfylls, planera åtgärder, ge underlag till
rullmotstånds- och olycksmodeller m.m.
1.2.
Utvalda vägytemått
I den här rapporten behandlas spårdjup och IRI. Spårdjup är ett mått på ytans ojämnhet tvärs vägen.
Stora spår kan bl.a. medföra att vatten på vägen inte rinner av och istället samlas i spåren. IRI är ett
mått på ytans ojämnhet längs vägen i ett sådant våglängdsområde att den sätter fjädringen hos en bil i
rörelse. Mer omfattande beskrivningar fnns i t.ex. en VTI rapport [20]. Flera andra mått, t.ex. MPD
1,
mäts av samma fordon men behandlas inte i den här rapporten. Ytterligare andra mått, t.ex. friktion,
mäts med andra typer av fordon och med en helt annan teknik som inte heller behandlas här. Många
sådana mått har en annan modellstruktur, t.ex. med tydlig säsongsvariation, och förväntas inte kunna
analyseras med någon av de metoder som diskuteras här.
Resultatredovisningen omfattar spårdjup mätt med 17 lasrar över en bredd om 3,2 meter (spårdjup 17),
spårdjup mätt med 15 lasrar över en bredd om 2,6 meter (spårdjup 15) och IRI i höger hjulspår. I den
fortsatta texten nämns ofta analys av spårdjup men metodvalen, metodens egenskaper o.s.v. avser även
analys av IRI även om det inte nämns.
1.3.
Tillståndsprognoser
Alla vägar mäts inte alla år. Mycket av det man önskar att använda mätdata till kräver att man kan göra
rimliga prognoser för att fylla i de år man inte mäter och att bedöma utvecklingen inom en rimligt lång
framtid. I ett tidigare arbete på det här området [2] diskuteras en prognosmetod för spårdjup och IRI.
Viktiga resultat från den rapporten sammanfattas i kapitel 3.1.
I [2] var det en förutsättning att endast använda data från den senaste beläggningsomgången. Man kan
betrakta den här rapporten som en fortsättning på eller en utvidgning av [2] där den största
metod-förändringen i den här rapporten är att även data från tidigare beläggningsomgångar betraktas. Det ger
ett mer omfattande underlag men förutsätter att utvecklingen under tidigare beläggningsomgångar var
ungefär likadan som under den nuvarande. Mindre metodförändringar är att matchning av datakällor
och tvättning av data utförts på lite annat sätt.
1.4.
Syfte
Föreslå en prognosmetod för att göra prognos framåt i tid och fylla i saknade värden bakåt i tid med
hjälp av data från alla tidpunkter där det fnns mätvärden d.v.s. utan att begränsa till endast data från
senaste beläggningsomgång. Metoden ska omfatta punktprognos och intervallprognos. Utred för- och
nackdelar med att inkludera data från tidigare beläggningsomgångar i prognosmetoden. Prognosen ska
avse en spårdjupsutveckling och IRI-tillväxt vid normal tillväxttakt på platsen d.v.s. den behöver inte
kunna förutspå åtgärder eller andra enskilda händelser som ger tydligt avtryck i utvecklingen. Genomför
nödvändiga kontroller av förutsättningarna och diskutera betydelse av eventuella avvikelser.
1MPD, mean profle depth, är ett mått på ojämnheter längs vägen med ett mycket kortare våglängdsområde än IRI. Det
2.
Dataunderlag och redovisningsgrupper
2.1.
Datakälla
Data hämtas från Trafkverkets Pavement Management System (PMSv3) [19]. De begränsas till
väg-ytemätningar från 1997 eller senare och beläggningar från 1986 eller senare. De sträcker sig framåt
i tid till mätningar genomförda 2016. I sin mest preliminära form omfattas 1 507 513 generaliserade
sträckor. Inom detta antal räknas varje körfält och riktning som egna sträckor. Data måste förberedas
genom matchning och tvättning innan de kan användas för de beräkningar som föreslås här.
2.2.
Matchning
PMS-systemet är inte organiserat så att det går att ta ut all önskad information i ett enda uttag.
Väg-ytedata lagras per generaliserad sträcka, som i de festa fall är en 100-meterssträcka. Beläggningsdata
däremot lagras per homogen sträcka, som har varierande längd och avgränsas av olika förändringar
som t.ex. ändrad vägbredd eller ändrad hastighet. Man kan göra ett uttag för att få ut all vägytedata
historiskt, men då får man bara med senaste beläggningsdata. Man kan göra ett uttag för att få ut all
beläggningsdata historiskt, men då får man bara med senaste vägytedata. För att kunna sätta ihop
väg-ytedata med beläggningsdata historiskt måste man göra två uttag baserade på generaliserade
respek-tive homogena sträckor och sätta ihop dem, det som här kallas matchning. I båda uttagen kan man få
med vägnummer, OID, löpande längd, riktning m.m. så de är väl förberedda som underlag för att
ut-föra matchningen. En mer exakt beskrivning av matchningsproceduren fnns i bilaga A. Några speciella
problem vid matchningen beskrivs i bilaga B.
2.3.
Tvättning
Det förekommer förändringar i tidsserien som inte hör till normalt slitage och inte heller kan förklaras
av någon känd åtgärd, därför behövs tvättning. Tvättningen här har sökt efter två olika avvikelser vid
tillfällen då det inte fnns någon registrerad åtgärd.
Uteliggare:
Om ett enskilt värde avviker kraftigt från sin omgivning betraktas det som en uteliggare
som måste tas bort på något sätt. Vanligen raderar man det värdet men här har tillvägagångssättet
rent tekniskt istället varit att behålla värdet men låtit det få en egen koeÿcient i analysen som
anpassas så att uteliggaren inte påverkar skattningen av sambandet eller storleken hos den
slump-mässiga variationen.
Hopp:
Om ett värde avviker kraftigt från föregående värde (som inte får vara en uteliggare) och man
inte observerar att det går tillbaka till ungefär den tidigare nivån vid nästa mätning så betraktas
det som ett hopp. Ett hopp inuti en tidsserie kräver att det fnns minst två på varandra följande
värden som avviker ungefär lika mycket från sin omgivning. Ett hopp i början eller slutet av en
tidsserie kan omfatta bara ett värde eftersom underlag saknas för att kunna observera att det går
tillbaka till tidigare nivå. Hopp till en lägre nivå kan uppstå därför att man gjort en åtgärd men
inte registrerat den. Ett sådant hopp kan betraktas som att det motsvarar s.k. fktiv åtgärd.
Om man jämför med Trafkverkets metod för att tvätta data så är ordningen här en lite annan. Deras
metod betraktar tidigare data och avgör sedan om nya data passar tillräckligt bra för att de nya data ska
accepteras som en fortsättning på tidigare data. Annars kan det vara fråga om att klassa nya data som
uteliggare eller som att det skett en åtgärd. Metoden här utgår från att mättekniken ständigt förbättras
och ser det som en rimlig följd att främst äldre data bör ifrågasättas ifall äldre och nyare data inte verkar
passa ihop. Det senaste mätvärdet kommer därför att accepteras medan äldre data eventuellt kan klassas
som uteliggare. Äldre data ska inte avgöra om nya data över huvud taget ska användas, men kan påverka
hur de ska användas. Hanteringen av hopp är också annorlunda här. Trafkverkets nuvarande metod kan
klassa det senaste mätvärdet som för lågt för att kunna accepteras som en fortsättning på tidsserien och
därmed tilldelas en okänd åtgärd, men om värdet är för högt fnns inte en motsvarande möjlighet.
En-skilda höga värden kan klassas som uteliggare men det kan inte tillämpas på det värde som ligger sist
i serien. Här har ett mer symmetriskt synsätt på hopp uppåt respektive nedåt använts. En mer komplett
beskrivning av tvättningsproceduren fnns i bilaga C.
2.4.
Redovisningsgrupper
Resultaten kan behöva redovisas med olika indelningar eller beräknas på olika delmängder av all
till-gänglig data. Det kan vara fråga om hur man önskar att få redovisningen. Det kan också vara fråga om
att egenskaperna varierar så att sammanslagna resultat inte representerar delmaterial på ett tillräckligt
bra sätt. Samma beräkningsmetod används oavsett en eventuell indelning. Antaganden om en generell
struktur i data gäller för alla delområden. Däremot kan resultat redovisas separat eller vara baserade på
olika delmängder av data.
2.4.1. Län
Förutsättningarna kan antas vara olika i olika delar av landet. Det kan gälla trafk/slitage men också
markrörelse, mätning och annat. En geografsk indelning kan vara välmotiverad därför att
uppdrags-givaren vill ha separat redovisning för olika områden.
2.4.2. Beläggningskategorier
Olika beläggningar förväntas ha olika beständighet mot avnötning och den genomsnittliga
spårdjupstill-växten bör redovisas per beläggningskategori. Spårdjupstillspårdjupstill-växten måste inte därmed vara olika om de
mer beständiga beläggningarna används där trafken är hög.
Kategori 1, Asfaltbetong tät:
ABT, ABb, ALBT, HABT, J, MABT, MJAB, ÅAB
Kategori 2, Ytbehandling:
Y1B, Y1G, Y2B, Y2G
Kategori 3, Asfaltbetong stenrik:
ABS, HABS, MABS
Kategori 4, Oljegrus:
AEOG, MJOG, OG
Kategori 5, Tunnskikt:
TSK
Kategori 6, Indränkt makadam:
IM, IMT, JIM
Kategori 7, Cementbetong:
BTG, CB
Kategori 8, Asfaltbundet grus:
AEG, AG, AGS, ALG, MJAG
Kategori 9, Asfaltbetong dränerande:
ABD, HABD, MABD
Kategori 10, Ovanliga beläggningar:
AEB, AEBT, AEBÖ, BBCH, BCS, BL, BS, CG, ES, F, FM,
FR, Funk, GAP, GJA, GJAP, HABÖ, Infr, Kons, MABÖ, MM, NaN, PGJA, REOL, SB, SF, S,
GJA, SPY, STEN, TOP, VA, ÅA, ÅAHV, ÅAK, ÅAV, ÅM
Kategori 11, Övriga beläggningar:
Alla övriga beläggningskoder
2.4.3. Vägkategorier och hastighetsgränser
Större vägar byggs mer påkostat och mer från grunden. De mäts också oftare. Nedan diskuteras även
ett antagande om lika stor slumpmässig variation. En indelning i vägkategorier kan vara välmotiverad
om t.ex. mätningar på större vägar har en lägre slumpmässig variation än mätningar på mindre vägar.
Resultaten redovisas därför uppdelat per vägkategori. En indelning i hastighetsgränser kan motiveras
på snarlikt sätt som indelningen i vägkategorier. Resultaten kommer också att redovisas uppdelat per
hastighet. Dessa två indelningar förekom inte i [2].
3.
Underlag för val av prognosmetod
3.1.
Tidigare resultat
I [2] framgår:
1. Datahanteringen är omfattande och tvättningen är svår att automatisera fullt ut. Det kan fnnas
logiska skäl som talar för att spårdjupet inte ska minska kraftigt såvida man inte gör en åtgärd.
Det är svårare att bedöma plötsliga förändringar till större spårdjup. Även om man kan sätta upp
regler för hur snabb och stor förändring som ska accepteras så fnns problemet med att en åtgärd
är utförd men registrerad vid fel tidpunkt kvar.
2. Vid analys av enskilda generaliserade sträckor blir antalet observationer många gånger lågt. Det
leder till att man inte får någon pålitlig skattning av variationen. Även om nivå och
förändrings-takt skattas lokalt så är det en fördel att skatta storleken på den slumpmässiga variationen genom
att väga samman information från ett större område. Det fnns naturligtvis argument mot det men
ett argument för är att variationskällorna är desamma för varje generaliserad sträcka.
3. Det kan fnnas skäl att anta att spårdjupsutvecklingen är snabbare i början och slutet medan den
är långsammare i en större mittdel av beläggningens livslängd. Någon tydlig sådan e˙ekt i början
av förloppet gick inte att se i data.
4. Prognosintervall för ett nytt mätvärde blir något vidare än vad som hade förväntats.
5. Samstämmigheten i spårdjup och spårdjupsutveckling från en generaliserad sträcka till nästa är
låg även om hastighet, beläggningsålder, vägbredd m.m. är oförändrad. Det talar mot att
spår-djupet skulle kunna beräknas med sådana egenskaper som underlag.
6. Vid analys av en sträcka som är ovanligt väl undersökt ser man i stort sett samma slumpmässiga
variation som i andra sträckor. Man får därmed intrycket att data inte blir mycket bättre för att
man undersöker en sträcka regelbundet med samma mätfordon, samma förare o.s.v. Prognosen
blir något bättre men det beror på att det fnns en mer omfattande datamängd, inte att data själva
är av väsentligt bättre kvalitet.
7. Ett lite högre eller lägre mätvärde på en generaliserad sträcka vid en viss tidpunkt tenderar att
återkomma på nästa generaliserade sträcka vid samma tidpunkt. Det kan förklaras av att om
mät-fordonets sidoläge är fel så påverkar det fera efterföljande generaliserade sträckor, att det fnns
systematisk skillnad mellan mätfordon o.s.v. Däremot verkar det inte fnnas ett beroende i tid.
Om mätfordonet ligger fel i sidoläge ett år så medför inte det att den ligger fel på liknande sätt vid
nästa mätning på samma generaliserade sträcka.
3.2.
Andra publikationer
Föreliggande genomgång redogör för relevant litteratur rörande prognosmetoder för tillståndsdata, men
berör även datakvalitet eftersom dessa två områden är så nära förknippade. Vissa begränsningar av det
tillgängliga materialet har gjorts. I litteraturen rörande prognosmetoder fnns det många referenser till
arbeten om ”Life cycle assessment (LCA)” och/eller ”Life cycle cost (LCC)”, där tillståndsutvecklingen
är ett centralt begrepp. Denna typ av arbeten (samt artiklar om PMS) har dock en tendens att betrakta
tillståndsutvecklingen väldigt schablonmässigt, och har inte studerats närmare.
Mycket av den tidiga forskningen handlar om hur nedbrytningen ska modelleras. Då vi har funnit att
utvecklingen av både IRI och spårdjup beskrivs bäst med en rät linje (oberoende av beläggningstyp,
klimatzon, etc.) är koncept som Markov-kedjor och spline-funktioner inte av nämnvärt intresse, och
kommer inte att behandlas i detalj.
En vanligt förekommande uppfattning är att all tillståndsutveckling följer en kurva likande den i
fgu-ren nedan. Johnson och Cation [13] skriver, angående tillståndsutvecklingen för ojämnheter att ”[t]he
predictions must make sense and follow the traditional line expected by the pavement engineer on the
basis of past experience. If this basic principle is overlooked or not achieved through the development
process, the pavement management system has failed.” För IRI och spårdjup på det statliga vägnätet kan
vi inte se någonting av denna e˙ekt. Det fnns anledning att tro att denna typ av utveckling är begränsad
till sprickor (och möjligtvis ytskador) och inte bör överföras till IRI eller spårdjup.
Utmärkt
Bra
Obrukbar
Tid Tillstånd
Den tidiga forskningen behandlas endast översiktligt här. Den intresserade läsaren hänvisas till
Pater-sons synnerligen omfattande rapport ”Road Deterioration and Maintenance E˙ects — Models for
Plan-ning and Management” [16] (kapitel 7 för spårdjup och kapitel 8 för IRI). Nedan följer en i övrigt på
det stora hela kronologisk genomgång av relevant litteratur.
Bill Carey, en av den amerikanska vägforskningens centralfgurer skriver i förordet till 1963 års
”Sym-posium on Pavement Condition and Evaluation”:
” The most important need for condition surveys of highways is to establish trends of
pave-ment condition with time in order that advance estimates of maintenance needs and costs
can be made. Condition surveys are also needed to provide information on the performance
of particular materials and construction techniques. A further need is to provide
informa-tion on the performance of particular contractors and the quality of construcinforma-tion
inspec-tion.” [4]
Nunez och Shahin [15] upprepar Careys uppfattning med ”To maximize the benefts of pavement
ma-nagement, a reliable method of pavement condition forecasting is extremely important.” Artikeln
be-handlar förbättringar och utvecklingen av PMS-programmet PAVER. Eftersom arbetet föregår IRI är det
PCI
1-trender som analyseras. Det kan nämnas att Nunez och Shahin hade problem med datakvaliteten
inte olika de vi har med dagen data: ”Information on several pavement sections was found to be in
er-ror; these errors originated during data collection, coding, or entering in the data base.”
Lytton [14] fortsätter att betona vikten av tillståndsmätning då han i introduktionen till ”Concepts of
Pavement Performance Prediction and Modeling” skriver att ”[m]onitoring pavement performance, in
its broadest sense, has one major purpose: to determine objectively the current condition of pavements
and their historical trends so as to use that information in formulating a management plan of action.”
Perera et al. [18] presenterar i ”Investigation of Development of Pavement Roughness” en omfattande
genomgång av nordamerikansk LTPP data. Efter en redovisning av hur problem med datakvaliteten
hanterats redovisas en stor mängd fgurer med IRI mot tid. Samtliga fgurer ger ett, på det stora hela,
linjärt intryck.
Även Evans och Eltahan [5] redovisar IRI mot tid för ett stort antal LTPP-sträckor och konstaterar att
det är ungefär lika vanligt att IRI-trenden accelererar som avtar med tiden, helt i linje med våra
erfaren-heter. ”Because of the lack of a trend indicating that the IRI increased more rapidly following a certain
time in a pavement’s life, this approach was abandoned.” I övrigt handlar rapporten mestadels om
data-kvalitet och hur man bäst tvättar data.
Ytterligare en rapport baserad på LTPP-data är Jacksons och Puccinellis ”Long-term Pavement
Per-formance Program (LTPP) data analysis support” [12]. De kommer fram till samma slutsats angående
modellval: ”Using a linear relationship between IRI and age results in a model that is less biased than
the exponential relationship.”
Perera och Kohn [17] presenterar ett omfattande material i rapporten ”LTPP Data Analysis: Factors
A˙ecting Pavement Smoothness”. En intressant iakttagelse är: ”It was observed that pavements that
were of similar age show a parallel trend in roughness progression, indicating pavements that are built
smoother provide a smoother pavement over its design life.” Kvalitetsproblemen illustreras av: ”Several
areas of data defciencies have been identifed in this report. The LTPP sta˙ is making a concerted
ef-fort to close gaps in the database. This level of e˙ort should be increased or at least maintained.”. Här
ser vi alltså att problem med datakvalitet förekommer, trots att LTPP är ett noggrant kontrollerat
forsk-ningsprojekt.
Den i särklass bästa beskrivningen av problematiken rörande datakvalitet ges av Bennett i rapporten
”Evaluating the quality of road survey data” [3]. Som titeln antyder handlar rapporten huvudsakligen
om just datakvalitet (och inte prognosmetoder). Men, eftersom datakvaliteten är så viktigt för
resul-tatet av prognosmetoderna tas den med i denna litteraturgenomgång. Det är ju i praktiken
menings-löst att göra prognosmetoder om datakvaliteten inte är tillräckligt hög. Eller som Bennett uttrycker det:
”/.../ in order to assess pavement trends, and even evaluate data quality, one needs to have a high level
of precision in the measurements. If this is not achieved the apparent pavement deterioration will be
unreliable.”
Bennett fortsätter med: ”A particular problem was the variability of the data. When many sections were
reviewed as a time series, i.e. looking at the annual changes in pavement condition for the same 100-m
sections of road, often signifcant changes in condition were observed which could not be explained by
pavement deterioration or any other factor.” En stor del av arbetet med den prognosmetod som
presente-ras i föreliggande rapport handlar just om att hantera ”outliers” och dylikt.
Problemen rörande informationen om beläggningsarbeten liknar i väldigt hög utsträckning de som
fnns i PMSv3. Bennett skriver: ”Maintenance presented a particular problem since it leads to major
changes in the condition of a pavement. Unfortunately, re-surfacings and overlays/shape corrections
are not recorded reliably in RAMM
2, i.e. changes in pavement condition indicate that a treatment was
performed but it is not in the database.” Han fortsätter med: ”These lead to discontinuities in the
dete-rioration trends which make any form of trend analysis diÿcult at best, and most likely meaningless in
many situations since the other problems such as lack of precision and small sample sizes, are being
compounded.”
Slutligen konstateras att ”/.../ this problem is not confned to New Zealand, but is present throughout the
world. Yet the issue of systematic techniques for evaluating data quality does not appear to have been
considered in the technical literature.” Ett talande faktum är att, enligt Google Scholar, Bennetts rapport
har refererats endast fem gånger sedan 2001, fera gånger av honom själv i senare arbeten.
De allra festa arbeten om prognosmetoder handlar om längsgående ojämnheter. Antagligen beror detta
på att det är ett större problem än spårbildning i merparten av världen. Huvstig har dock, inom ramen
för NordFOU, utvecklat en modell för prognostisering av spårdjup [10, 11].
Tre artiklar med på det stora hela förklarande titlar publicerade under 2018 är: ”Does Pavement
Degra-dation Follow a Random Walk with Drift? Evidence from Variance Ratio Tests for Pavement
Rough-ness” av Swei et al. [21]; ”Soft Computing Models to Predict Pavement Roughness: A Comparative
Study” av Georgiou et al. [6] där prognostisering av IRI med artifciella neurala nätverk (ANN) och
stödvektormaskin (eng. Support Vector Machine) behandlas; samt ”Use of random forests regression
for predicting IRI of asphalt pavements” av Gong et al. [7] där prognostisering av IRI med hjälp av
”random forests regression” presenteras. Vi har inte funnit att resultaten i dessa tre artiklar tillämpbara
på data från Sveriges statliga vägnät.
Följande tre referenser har publicerats i januari 2019 vilket, om inte annat, illustrerar omfattningen av
forskning rörande prognosmetoder. Samtliga referenser använder artifciella neurala nätverk.
Alhar-bis avhandling [1] behandlar ”ride, cracking, rutting, and faulting indices” och använder klimatdata i
kombination med tillståndsutvecklingen. Yao et al. [22] behandlar ”rutting, roughness, skidresistance,
transverse cracking, and pavement surface distress”, medan artikeln av Hossain et al. [9] begränsar sig
till IRI.
3.3.
Data från tidigare beläggningsomgångar
Vägytemätning har en lång historia, längre än livslängden hos ytskiktet på många vägar. Vanligen har
man tillgång till mätdata från fer än en beläggningsomgång. Vid en snabb granskning verkar det som
att spårdjupstillväxten under nuvarande beläggningsomgång är ungefär lika snabb som den var under
den förra, eller t.o.m. samma som under fera beläggningsomgångar bakåt. En rimlig ansats är därför
att använda en metod som inkluderar data från fera beläggningsomgångar och ansätter att
takten ska vara densamma för alla. Det fnns naturligtvis en hel del som talar för att inte
förändrings-takten ska vara densamma över fera beläggningsomgångar, inte ens över tid inom samma
beläggnings-omgång. Ökad trafk och tyngre fordon ger en förväntan om en snabbare spårdjupstillväxt. Bättre
mate-rial och tjockare asfaltslager efter en åtgärd ger en förväntan om en långsammare spårdjupstillväxt.
3.4.
Rätlinjigt förlopp
De variabler som analyseras här har ett förlopp mot tiden som ser nära rätlinjigt ut och har rimlig
an-ledning att vara rätlinjigt, eller åtminstone så nära rätlinjigt att en rät linje utgör en god approximation
och en tillräcklig grund för en prognos. Spårbildning som uppstår av avnötning bör ha ett närmast
rät-linjigt förhållande mot beläggningsålder, åtminstone om man sammanfattar till att mäta under
sommar-tid en gång per år. Spårbildning som uppstår av deformation är mer svårbedömd.
Här antas att spårbildning och även IRI har rätlinjig utveckling mot tid. Andra variabler, med kanske
MPD som bästa exempel, har inte en sådan utveckling och ska därför inte analyseras med en modell av
samma matematiska struktur som de modeller som används här. Prognoser för MPD har behandlats i en
annan VTI rapport [8].
3.5.
Lika varians
Mätvärden varierar kring det rätlinjiga förloppet. Variationen kan bero på mätfordonets sidoposition,
olikhet mellan fordon, olika kalibrering o.s.v. men också brus i mätningarna som inte har någon direkt
förklaring. Sådan variation fnns och måste hanteras, här genom att helt enkelt betrakta den som en
slumpkomponent. Det förutsätts att den är av samma storlek vid varje tillfälle oavsett plats, tidpunkt och
beläggningsålder. När man inspekterar data som tidsserier med rätlinjigt bakgrundsförlopp och
slump-mässigt brus så ser antagandet rimligt ut. Det kan synas vara motsägelsefullt då instrumenten antas bli
bättre för varje år, men förklaringen kan vara att fel i instrumenten är små jämfört med andra felkällor.
Slumpkomponentens fördelning har stor betydelse för prognosintervall för enskilda mätvärden. Ett
spårdjup kan inte vara negativt och en svårighet här är att framför allt en stor negativ slumpkomponent
inte kan förekomma vid riktigt lågt förväntat spårdjup. Analyserna förutsätter att slumpkomponenten är
normalfördelad, vilket bör vara rimligt i de allra festa fall. Vid lågt spårdjup kan speciellt den vänstra
delen av den fördelningen ha en lite annan form. Kapitel 4.2 har en diskussion om olika mått som ges
av regressionsanalysen där bl.a. täckningsgrad för prognosintervall ingår. Täckningsgrad för
konfdens-intervall är inte lika känsligt för slumpkomponentens fördelning. Redovisning av hur stort felet är,
ut-tryckt i hur prognosintervall med en viss sannolikhet faller ut med lite annan än den önskade
sannolik-heten, nämns i den numrerade listan i kapitel 5.1 och motsvarande värden fnns med i de tabeller som
listan hänvisar till.
4.
Förslag till prognosmetod
Data presenteras som tidsserier. Här föreslår vi att data ska analyseras med regressionsanalys där tid är
förklaringsvariabel och spårdjup är respons. Uteliggare och hopp kan ganska lätt hanteras inom denna
ram. Det är inte ovanligt att behandla tidsserier så, även om området Tidsserieanalys också omfattar
många andra metoder.
4.1.
Linjär regression
Linjär regression är en teknik där en responsvariabel modelleras som summan av en linjär funktion av
en eller fera förklaringsvariabler och en slumpkomponent. Om man har 1 förklaringsvariabel brukar
metoden benämnas enkel linjär regression, annars multipel linjär regression. Anpassning av
koeÿcien-terna i funktionen sker typiskt med minstakvadaratmetoden. För den inferens som vanligen ingår ställer
man krav på att slumpkomponenten ska vara normalfördelad med lika stor varians oavsett nivå samt att
observationerna ska vara oberoende. Slumpmässig variation ska fnnas i responsdimensionen, alltså inte
i förklaringsvariablerna.
Vid data från bara 1 beläggningsomgång kan en beskrivning av metoden med fördel läsas i [2]. Där
beskrivs skillnaden mellan olika intervalltyper samt enskild respektive sammanvägd variansskattning.
Förklaringen här upprepar vissa delar och utvidgar till hur det blir om man har data från fer än 1
beläggningsomgång.
Modellbaserad prognos kan göras på sträckor där man har minst 1 observation från nuvarande
omgång och minst 2 observationer med tillräcklig tidlucka mellan observationerna från någon
beläggnings-omgång. Därutöver kan man ha ytterligare data från samma eller från ytterligare beläggningsomgångar.
Prognosnoggrannheten blir bättre ju fer observationer man har och ju mer utspridda de är i tid inom
respektive beläggningsomgång.
4.2.
Prognosintervall och andra resultat av regressionsanalyser
Linjär regression är inte begränsad till att bara skatta sambandsfunktionen. Annan information som kan
vara värdefull är bl.a.
Mean square error (
MSE): En skattning av storleken på observationernas variation runt
sambands-funktionen. Det är alltså en skattning av variansen hos det brus som nämndes i kapitel 3.5. MSE
har en frihetsgrad som beskriver hur många observationer den byggs upp av korrigerat för hur
många skattningar som ingår. Varje ny observation ökar frihetsgraden men varje skattning sänker
den.
Anpassat värde och punktprognos:
Det anpassade värdet är en god gissning av vilket värde
respons-variabeln borde ha hos en given observation om man rensar bort det slumpmässiga bruset genom
att ta stöd i den skattade responsfunktionen. En punktprognos beräknas på samma sätt men avser
mer en gissning som inte är knuten till någon befntlig observation utan snarare till en ny tänkbar
observation med vissa värden på förklaringsvariablerna.
Prognosintervall:
Eftersom data förutsätts ha slumpmässigt brus och bara ett urval av data fnns
till-gängligt blir även anpassningen och punktprognoser osäkra. Osäkerhetens storlek går att skatta.
Ett prognosintervall byggs upp genom att ta en punktprognos och addera en felmarginal så att
man får ett intervall där en ny observation med givna värden på förklaringsvariablerna ska hamna
med en viss sannolikhet. I det här sammanhanget svarar ett prognosintervall typiskt på en fråga
liknande ”Kan man beräkna ett intervall sådant att om vi mäter spårdjupet om 1 år så kommer
mätvärdet att hamna inom detta intervall med 95 % sannolikhet?”. För prognoser bakåt i tiden
kan man istället tänka sig frågan ”Kan man beräkna ett intervall så att om vi hade mätt spårdjupet
för 3 år sedan så borde mätvärdet ha hamnat inom detta intervall med 95 % sannolikhet?” men
bakåt i tiden är antagligen punktprognos mer efterfrågat.
Konfdensintervall:
Ett konfdensintervall byggs upp på liknande sätt som ett prognosintervall men
har inte samma osäkerhetskällor och avsikt. I det här sammanhanget svarar ett konfdensintervall
på en fråga liknande ”Kan man beräkna ett intervall sådant att om vi bestämmer spårdjupet om
1 år utan mätbrus så kommer mätvärdet att hamna inom detta intervall med 95 % sannolikhet?”.
Allt underlag innehåller brus som också blir en källa till osäkerhet men konfdensintervallet
av-ser ett spårdjupvid vid givna värden på förklaringsvariablerna om det inte fnns mätbrus i detta
enskilda värde. Man kan här se det som ett intervall för det sanna spårdjupet medan
prognos-intervall avsåg det uppmätta spårdjupet som också har ett slumpmässigt mätfel. För
konfdens-intervall bakåt i tiden kan man inte bara formulera om samma fråga som ovan till att gälla en
tidi-gare tid eftersom man inte använder ”sannolikhet” om ett utfall som har fxerats, även om det är
okänt. Ett konfdensintervall avser mer generellt i det här sammanhanget att bestämma gränser för
sambandsfunktionen vid en given tidpunkt, men tidpunkten måste inte knytas till tidpunkten för
någon utförd eller planerad mätning.
Täckningsgrad:
Här avses sannolikheten att en intervallprognos verkligen fångar in det mätvärde som
prognosen avser. Metoden för prognosintervall är beroende av bl.a. att slumpkomponenten är
normalfördelad, men det kan man inte veta med säkerhet. Täckningsgraden utvärderas genom att
utesluta det senaste värdet, använda de tidigare värdena för att beräkna en intervallprognos för det
senaste värdet och sedan kontrollera om prognosintervallet täcker det uteslutna värdet.
Systematiskt fel:
Här avses att, liksom för täckningsgrad, utesluta det senaste mätvärdet, beräkna
en prognos för det och kontrollera hur väl prognosen slår in. Det systematiska felet är här den
genomsnittliga skillnaden mellan punktprognos och utfall.
4.3.
Sammanvägd variansskattning
Prognos- respektive konfdensintervall för en generaliserad sträcka blir väldigt breda om de beräknas
utifrån ett dataunderlag från endast den sträckan. En av orsakerna är att osäkerheten skattas med låg
precision när man har få observationer och därmed att en del av beräkningen kräver stor
säkerhets-marginal. Varje intervallberäkning tar vara på den information som fnns tillgänglig och får också de
egenskaper den teoretiskt ska få. Breda intervall visar inte en svaghet i den statistiska metoden, snarare
att underlaget är litet eller att förutsättningarna är sådana att metoden inte kan dra nytta av all tillgänglig
information.
Man kan anta att den slumpmässiga variationen i alla mätningar har samma felkällor och därför
för-väntas vara lika stora. Då följer att mätfelens variation på generaliserad sträcka 1 skattar samma storhet
som mätfelens variation på generaliserad sträcka 2 o.s.v. om de utgör delar av samma väg. Man kan
dra nytta av den vetskapen genom att anpassa metoden därefter. Det ger snävare intervall i genomsnitt,
vilket först kan vara oväntat men ändå går att förklara. Vid intervall med individuell variansskattning
kommer några att bli snäva och några att bli breda medan intervallens vidd får mindre variation vid
sammanvägd variansskattning. Vid individuellt beräknade intervall är vidden dock inte symmetriskt
fördelad utan de snäva intervallen kan bli lite snävare medan de breda kan bli mycket bredare. Detta
gäller även intervall med sammanvägd variansskattning men i lägre grad. Om man använder bara de
enskilda variationerna får man därför intervall som i genomsnitt har en större vidd. Täckningsgraden
blir dock oförändrad, och rätt i varje fall om förutsättningarna för övrigt är rätt. Metoden ger således
rätt täckningsgrad men ändå snävare intervall i genomsnitt. Därför bör man använda en sammanvägd
skattning av variationen från alla sträckor i beräkningen och därigenom utnyttja mer än den information
man har om variation baserat på bara den enskilda sträckan. Det är en vinst att använda sammanvägd
variansskattning, och vinsten uppstår därför att man har tillgång till mer information vid beräkning av
prognos- respektive konfdensintervall och att man använder den informationen.
Rent beräkningsmässigt bestäms den sammanvägda variansskattningen för en grupp av generaliserade
sträckor genom att man tar MSE från var och en av de generaliserade sträckorna och väger ihop dem till
ett gemensamt mått. Här ska vikterna självklart summeras till 1 och de väljs proportionellt mot
frihets-graderna. Det medför att en generaliserad sträcka med många observationer får större vikt än en med
få observationer. Sträckor som har fer observationer får en större betydelse därför att variansen, som
antogs vara densamma, skattas med mindre osäkerhet hos de sträckorna.
4.4.
Skrivsätt för olika metoder
För att korta ned skrivningen något i den här rapporten något används följande skrivsätt:
• Metod 1: Linjär regression med endast data från senaste beläggningsomgång, lokal
varians-skattning.
• Metod 2: Linjär regression med endast data från senaste beläggningsomgång, sammanvägd
varians-skattning.
• Metod 3: Linjär regression med alla tillgängliga data från senaste beläggningsomgång därutöver
minst 1 tidigare beläggningsomgång, sammanvägd variansskattning.
Tidigare resultat visade tydligt att sammanvägd variansskattning (metod 2) gav mindre felmarginaler i
genomsnitt än metoden med individuell variansskattning (metod 1). Därför används här metod 1 och 2
för att jämföra med tidigare resultat och metod 3 för att undersöka för- och nackdelar som följer av att
inkludera tidigare data. Det fnns ingenting som förbjuder att man skapar en metod 4 med data från alla
beläggningsomgångar och lokal variansskattning, men då metod 2 varit så mycket bättre än metod 1 så
verkar det inte meningsfullt att prova en sådan metod 4.
4.5.
Linjär regression med nivåskift
Genom att välja förklaringsvariabler på ett strukturerat sätt så kan man få responsfunktionen att
upp-träda som räta linjestycken med samma förändringstakt och med nivåskift mellan dessa linjestycken.
Detta stämmer exakt med det utseende som spårdjupets utveckling mot tid förväntas följa i metod 3, om
nivåskiften sker vid åtgärder och förändringstakten avser den normala spårdjupstillväxten. Nivåskift i
regressionsanalys motsvarar det som lite mer generellt kallats hopp ovan. En mer omfattande förklaring
av regressionsanalys med nivåskift ges i bilaga E.
Metoderna 2 och 3 använder sammanvägd MSE och beskrivs ovan som beräkningar i 2 steg, men de
kan genomföras i bara 1 steg enligt beskrivning i bilaga J. De är alltså inte speciellt framtagna endast
för den här uppgiften utan följer snarare allmänt regressionsanalysens ramverk. Villkor, kontroller, krav
på data o.s.v. kan diskuteras inom detta ramverk.
5.
Resultat
5.1.
Resultatmått
De resultat som redovisas här svarar på följande frågor eller önskade redovisningar:
1. Hur god precision, uttryckt som felmarginal, får man vid prognos av ett nytt mätvärde på
spår-djupet (prognosintervall) ett år framåt från senaste mätning om man använder metod 1?
2. Hur god precision, uttryckt som felmarginal, får man vid prognos av ett nytt mätvärde på
spår-djupet (prognosintervall) ett år framåt från senaste mätning om man använder metod 2?
3. Hur god precision, uttryckt som felmarginal, får man vid prognos av ett nytt mätvärde på
spår-djupet (prognosintervall) ett år framåt från senaste mätning om man använder metod 3?
4. Redovisa antal generaliserade sträckor som kan användas i punkt 1 ovan.
5. Redovisa antal generaliserade sträckor som kan användas i punkt 2 ovan. Det blir fer eftersom
även sträckor med bara 2 observationer omfattas.
6. Redovisa antal generaliserade sträckor som kan användas i punkt 3 ovan. Det blir ännu fer
efter-som även sträckor med bara 1 observation under nuvarande beläggningefter-somgång omfattas ifall det
fnns tillräckliga data från tidigare beläggningsomgångar för att skatta tillväxttakten.
7. Hur god täckningsgrad får man vid prognosintervall motsvarande punkt 1 ovan om man väljer en
metod som ska ge 95 % täckningsgrad vid ideala förutsättningar?
8. Hur god täckningsgrad får man vid prognosintervall motsvarande punkt 2 ovan om man väljer en
metod som ska ge 95 % täckningsgrad vid ideala förutsättningar?
9. Hur god täckningsgrad får man vid prognosintervall motsvarande punkt 3 ovan om man väljer en
metod som ska ge 95 % täckningsgrad vid ideala förutsättningar?
10. Hur stort genomsnittligt systematiskt fel får man vid punktprognos motsvarande punkt 1 och 2
ovan? De ska bli lika eftersom metod 1 och 2 utgår från samma punktprognos men har olika sätt
att beräkna felmarginalen.
11. Hur stort genomsnittligt systematiskt fel får man vid punktprognos motsvarande punkt 3 ovan?
12. Hur god precision, uttryckt som felmarginal, får man vid prognos av spårdjupet (konfdensintervall)
ett år framåt från senaste mätning om man använder metod 3?
13. Redovisa sammanvägd MSE vid metod 2.
14. Redovisa sammanvägd MSE vid metod 3.
Resultaten redovisas i tabell 1. Tabellens rader följer exakt samma ordning som ovan medan tabellens
kolumner visar vilken vägytevariabel som avses.
5.2.
Sammanställda resultat
Tabell 1 visar genomsnittliga resultat. Delresultat har först beräknats för varje kombination av län och
beläggningskategori. Därefter har värdena viktats ihop proportionellt mot antal generaliserade sträckor
per län×beläggningskategori. Ett län med många sträckor får därför en lite högre vikt än ett med få
sträckor. Resultaten blir ibland något ändrade, ytterst lite, om man utgår från en annan indelning. Man
kunde tänka sig andra vikter, t.ex. att varje mätning är lika mycket värd, men då kommer sträckor med
många mätningar att få större betydelse än de med få mätningar, vilket kan kännas tveksamt. För den
gemensamma variansskattningen fnns skäl att välja vikter proportionellt mot frihetsgraderna. I just
Tabell 1. Sammanställda resultat.
Spårdjup 17 Spårdjup 15 IRI Genomsnittlig felmarginal, prognos av ett mätvärde
Metod 1 4,00 3,67 0,71
Metod 2 1,83 1,69 0,30
Metod 3 1,90 1,72 0,31
Antal beräknade felmarginaler, prognos av ett mätvärde Metod 1 569194 544630 541176 Metod 2 736305 719556 718591 Metod 3 888016 848122 867638 Genomsnittlig täckningsgrad, prognos av ett mätvärde
Metod 1 0,91 0,92 0,91
Metod 2 0,91 0,91 0,90
Metod 3 0,91 0,91 0,91
Systematiskt fel, prognos av ett mätvärde
Metod 1 och 2 0,06 -0,01 -0,01
Metod 3 0,12 0,05 0,01
Genomsnittlig felmarginal, prognos av ett väntevärde
Metod 3 1,32 1,21 0,22
MSE
Metod 2 0,39 0,33 0,01
Metod 3 0,47 0,38 0,01
det fallet får sträckor med data från många mätningar normalt större vikt än sträckor med få mätningar,
men bara inom sin kombination län×beläggningskategori. När dessa sedan viktas ihop till medelvärdet
i tabell 1 har varje generaliserad sträcka lika stor vikt. Många generaliserade sträckor faller bort därför
att det är en för gammal beläggning, för gamla mätningar, för få mätningar, för många uteliggare eller
hopp, saknad information, ingen tillgänglig beläggningshistoria eller ingen tillgänglig dominerande
beläggningshistoria. Ungefär hälften av de generaliserade sträckorna kan användas i metod 3.
5.3.
Resultat uppdelat på redovisningsgrupper
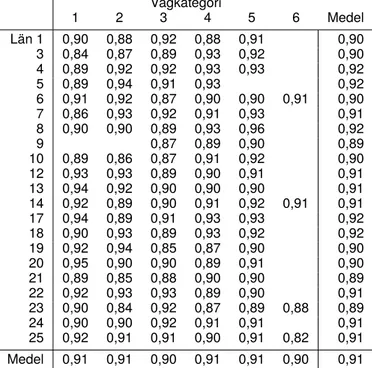
Flera av måtten i tabell 1 fnns också redovisade på fnare nivå i bilagor. I [2] delades redovisningen
upp per län och beläggningskategori. Utöver den uppdelningen kommer resultaten att redovisas
upp-delat per län och hastighet respektive per län och vägkategori. All den redovisningen fnns i tabellerna 5
t.o.m. 85, bilaga F. Inom varje rubrik (motsv. delkapitel) visas 9 tabeller som omfattar felmarginaler,
täckningsgrad och systematiskt fel i samma ordning som i tabell 1.
5.4.
Jämförelser mellan metoderna
Jämförelserna mellan metoderna är inte rättvisa på alla plan. Metod 1 kan inte räkna felmarginaler på
fall med 2 observationer. Metod 2 kan räkna felmarginaler på fall med 2 observationer, men det är
oför-delaktigt eftersom de får större osäkerhet just därför att det är så få observationer. Om man ska jämföra
metoderna så bör man kanske beakta att fer svåra fall är inkluderade i metod 2 än i metod 1. Metod 3
kan inkludera fall där man har 1 observation i sista omgången. Återigen får man större felmarginaler
därför att man inkluderar ofördelaktiga fall. Inte alla resultat påverkas av problemet med vilka fall
som inkluderas. Texten ovan gäller för felmarginalen i olika prognoser, men den gäller inte för MSE
eftersom väntevärdet av MSE inte påverkas av antalet observationer.
En rimlig jämförelse kan vara att betrakta endast de fall där alla 3 metoderna gett ett svar, om det är
själva metoderna som ska jämföras. Eftersom vi här mest vill diskutera egenskaperna om man
inklu-derar data från tidigare beläggningsomgångar så jämförs metoderna som har sammanvägd
varians-skattning men är olika med avseende på om data från tidigare beläggningsomgångar ska inkluderas
eller inte. Tabell 2 visar samma information som 1 men uppgifterna för metod 3 sammanfattar endast de
fall där metod 2 har gett ett svar. Värdena vid metod 2 fnns med som jämförelse men ska vara
oföränd-rade jämfört med tidigare. Om metod 1 tillämpas på de fall där metod 2 har gett ett svar blir antalet
be-räknade felmarginaler lägre för metod 1 därför att den kan göra en punktprognos men inte en
intervall-Tabell 2. Sammanställda resultat, samma data för alla metoder.
Spårdjup 17 Spårdjup 15 IRIGenomsnittlig felmarginal, prognos av ett mätvärde
Metod 1 4,00 3,67 0,71
Metod 2 1,83 1,69 0,30
Metod 3 1,88 1,71 0,31
Antal beräknade felmarginaler, prognos av ett mätvärde Metod 1 569194 544630 541176 Metod 2 736305 719556 718591 Metod 3 736305 719556 718591 Genomsnittlig täckningsgrad, prognos av ett mätvärde
Metod 1 0,91 0,92 0,91
Metod 2 0,91 0,91 0,90
Metod 3 0,91 0,91 0,91
Systematiskt fel, prognos av ett mätvärde
Metod 1 och 2 0,06 -0,01 -0,01
Metod 3 0,10 0,03 0,00
Genomsnittlig felmarginal, prognos av ett väntevärde
Metod 3 1,30 1,20 0,21
MSE
Metod 2 0,39 0,33 0,01
Metod 3 0,47 0,38 0,01