Examensarbete
15 högskolepoäng, grundnivå
”Jag trivs ändå i min lilla bubbla” –
En studie om studenters attityder till
personalisering
“I am actually content in my little bubble” –
A study considering students’ attitudes towards web
personalization
Alice Hedin
Examen: Kandidatexamen 180 hp Examinator: Sven Packmohr
Huvudområde: Medieteknik Handledare: Simon Winter
webbaserade tjänster och utforska skillnader och likheter mellan studenternas attityder. Studiens empiriska material är insamlat genom fem kvalitativa intervjuer och en webbenkät med 72 respondenter. Studien behandlar fördelar och nackdelar med personalisering, möjligheter att förhindra personalisering och möjliga konsekvenser av personalisering. Majoriteten av
studenterna har en positiv attityd till personalisering av webbaserade tjänster. Resultatet visar att studenterna var mest positivt inställda till personalisering av streamingtjänster och minst
positiva till personalisering av nyhetstjänster. Jag fann att användare i stor utsträckning inte anser att nyhetstjänster bör vara personaliserade. Det visade sig finnas en tydlig skillnad mellan studenternas kännedom om olika verktyg som kan användas för att förhindra personalisering. Ju mer teknisk utbildning som studenterna läser, desto bättre kännedom hade studenterna om verktygen. Resultatet visade även att en stor del av studenterna önskade att de kunde stänga av personaliseringsfunktionen på tjänster. Personalisering har blivit en naturlig del av användarnas vardag och att majoriteten av användarna inte har tillräcklig kunskap om fenomenet och därför intar de en passiv attityd och undviker att reflektera närmare över personaliseringen och dess möjliga konsekvenser.
Nyckelord
Personalisering, Filterbubbla, Attityder, Streamingtjänster, Nyhetstjänster, Sociala medier, Sökmotorer
Abstract
“I am actually content in my little bubble” – A study of
students’ attitudes towards web personalization
This essay aims to study student’s attitudes towards web personalization and explore where the student’s attitudes differ and converge. The empirical materials of the study where assembled by the usage of five qualitative interviews and a quantitative survey with 72 respondents. The study discusses the pros and cons, the ability to constrain web personalization and possible effects and outcomes of web personalization. The majority of the students have a positive attitude towards web personalization. The students were most positive towards personalization of streaming services and least positive towards personalization of media channels that output news. There was an explicit difference between the students’ knowledge of the possibilities to constrain web personalization through the usage of different extensions and tools. Those
students who studied a more technical program showed more knowledge of extensions and tools that can be used to prevent or constrain web personalization. The results also showed that the over all students desire more control over web personalization and demand a function where the personalization of web services could be turned off. The study resulted in the findings that web personalization has become a part of the users every-day life and that the students do not have enough knowledge of web personalization which have led to a passive attitude towards it.
Keywords
Web personalization, Filter bubble, Attitudes, Streaming services, Media channels, News, Social media, Search engines
Förord
Jag vill tacka samtliga respondenter som tagit sig tid att delta i studien. Jag vill även passa på att tacka min handledare Simon Winter. Jag riktar ett extra stort tack till familj och vänner som stöttat mig under processen och agerat bollplank. Utan er hade jag inte kunnat skriva mitt examensarbete.
Ordlista
Adblock
Ett tillägg till webbläsaren som blockerar annonser och reklamtillägg (Adblock, u.å).
Privacy Badger
Ett tillägg till webbläsaren, som blockerar annonser och tredjepartsspårare från att spåra vilka webbsidor användaren använder. Om Privacy Badger känner av att en annonsör spårar en användarens aktivitet över flera webbsidor blockerar Privacy Badger den annonsören från vidare spårning. (Privacy Badger, u.å)
Disconnect
Ett tillägg till webbläsaren, som blockerar osynliga spårare genom att använda VPN (Disconnect, u.å).
Do not track me
Ett tillägg till webbläsaren, som blockerar spårare (Wikipedia, 2016a).
Ghostery
Ett tillägg till webbläsaren, som upptäcker och blockerar spårare åt användaren (Wikipedia, 2016b).
VPN
Virtuellt privat nätverk (VPN) är en teknik för att skapa en säker kommunikation eller en "tunnel" mellan två punkter i ett datanätverk. Kommunikationen blir krypterad och användaren kan surfa anonymt. (Wikipedia, 2016c)
Tor
Ett verktyg och ett nätverk som användare kan ansluta sig till genom att använda en serie av virtuella tunnlar. Detta leder till att ingen kan spåra innehållets väg från avsändare till mottagare. Tor kan användas för att skydda sig mot datatrafikanalys och spårning samt möjliggöra för användare att använda internet anonymt och få tillgång till webbsidor som är blockerade på grund av innehåll eller plats där användaren befinner sig. (Tor, u.å)
DuckDuckGo
Innehållsförteckning
1
Inledning ... 1
1.1 Problemdiskussion ... 2 1.2 Syfte ... 4 1.3 Frågeställning ... 4 1.4 Avgränsningar ... 4 1.5 Målgrupp ... 5 1.6 Disposition ... 52
Metod ... 6
2.1 Metodval ... 62.2 Urval av studieobjekt ... 6
2.3 Kvalitativa intervjuer ... 7 2.3.1 Urval ... 8 2.3.2 Tillvägagångssätt ... 8 2.3.3 Efterarbete ... 9 2.4 Enkäten ... 10 2.4.1 Undersökningsdesign ... 10
2.4.2 Urval av respondenter ... 12
2.4.3 Tillvägagångssätt ... 12
2.4.4 Analys ... 13
2.5 Metoddiskussion ... 13
2.5.1 Validitet och reliabilitet ... 14
2.5.2 Generaliserbarhet ... 15
2.5.3 Etiska överväganden ... 16
3
Teori ... 17
3.1 Personalisering ... 17
3.1.1 Hur personalisering fungerar ... 19
3.1.2 Rekommendationssystem ... 19
3.1.3 Personalisering av olika tjänster ... 20
3.2 Gatekeeping theory ... 21
3.3 Attityder till personalisering ... 22
3.4 Konsekvenser av personalisering ... 23
4
Resultat ... 25
4.1 Reflektion kring personalisering ... 25
4.2 Attityder till personalisering av olika tjänster ... 26
4.3 Fördelar och nackdelar med personalisering ... 28
4.4 Kunskap om hur personalisering kan förhindras ... 30
4.5 Utvecklingen av personalisering ... 33
5
Diskussion ... 36
5.1 Fördelar och nackdelar med personalisering ... 36
5.2 Attityder till personalisering av olika tjänster ... 36
5.3 Konsekvenser av personalisering ... 38
5.4 Utveckling av personalisering ... 39
5.4.1 Använda verktyg för att förhindra personalisering ... 40
5.4.2 Använda tjänster som inte personaliserar ... 40
5.5 Okunskap kring personalisering ... 41
6
Slutsats ... 45
6.1 Förslag till vidareutveckling ... 46
Referensförteckning ... 47
Bilaga 1. Intervjuguide ... 51
Bilaga 2. Enkät ... 52
Bilaga 3. Korrelation mellan attityden till olika typer av tjänster som har
personalisering. ... 63
Figur 1. Genomsnittlig tid på internet bland användare fördelat på sysselsättning 2015. (Hedin, 2016 baserad på Findahl & Davidsson, 2015) ... 7
Figur 2. Förhållandet mellan respondenterna utifrån studieinriktning. ... 13
Figur 3. En övergripande bild av personaliseringens nytta och kostnad för företag och kund (Hedin, 2016 baserad på Vesanen, 2007). ... 18
Figur 4. Diagram över hur ofta respondenterna reflekterar över att webbaserade tjänster är personaliserade. ... 26
Figur 5. Diagram som illustrerar i hur stor utsträckning studenterna har en positiv attityd till personalisering av olika typer av tjänster. ... 26
Figur 6. Diagrammet visar de fördelar som respondenterna anser att personalisering har. ... 28
Figur 7. Diagram som visar de nackdelar som respondenterna anser att personalisering har. ... 28
Figur 8. Diagrammet visar i hur stor utsträckning respondenterna anser att fördelarna med personalisering överträffar nackdelarna. ... 29
Figur 9. Diagram som illustrerar i hur stor utsträckning respondenterna önskar att de kunde stänga av och sätta på personaliseringsfunktionen på tjänster. ... 31
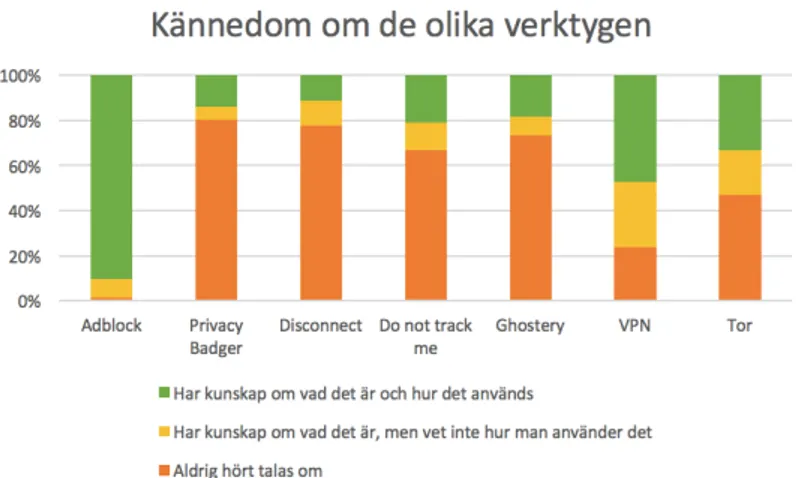
Figur 10. Diagram som illustrerar studenternas kännedom om Adblock, Privacy Badger, Disconnect, Do not track me, Ghostery, VPN och Tor. ... 31
Figur 11. Diagram som visar på skillnaden mellan studenterna beroende på studieinriktning och vilken kunskap de har kring de olika verktygen som kan användas för att förhindra personalisering. Om en respondent har kunskap om samtliga verktyg och vet hur de används erhöll respondenten 14 poäng, om en respondent fick noll poäng hade studenten aldrig hört talas om något av de nämnda verktygen i figur 10. ... 32
Figur 12. Diagram över respondenternas önskan om mer kunskap kring hur personalisering fungerar. ... 34
1
Inledning
Troligtvis har du googlat på pizzeria någon gång under det senaste året. Förmodligen kom det upp några olika förslag på pizzerior i ditt närområde i ditt sökresultat. Om du ber någon bekant googla pizzeria kommer hen troligtvis få ett annorlunda sökresultat än du får. Det här är nog något som de flesta känner igen.
Google är en sökmotor som utgår ifrån individens geografiska punkt när sökresultat presenteras (Google, 2015). På Googles hemsida står det att en av Googles grundare, Larry Page, en gång beskrivit att den perfekta sökmotorn ”förstår precis vad du menar och ger dig exakt vad du vill ha” (Google, u.å). Men det är långt ifrån bara din geografiska position som påverkar vilka sökresultat du får när du googlar något. År 2009 skrev Horling & Kulick (2009, 4 december) ett blogginlägg på Googles officiella blogg att Google expanderade sin personaliserade
sökfunktion. Innan hade endast de individer som varit inloggade med ett Google-konto erhållit personaliserade sökresultat. År 2009 ändrades detta till att alla som sökte på Google kunde få personaliserade resultat baserat på individens aktivitet länkat till kakor under de senaste 180 dagarna.
Du kanske även har lagt märke till att det mesta som konsumeras via digitala kanaler idag har någon typ av personalisering. YouTube, som i och för sig också ägs av Google (YouTube, u.å), rekommenderar kanaler och klipp baserat på vad användaren tidigare tittat på (Billboard, 2015). Men enligt Billboard (2015) har YouTube planer på att ta sin personalisering ett steg längre genom att även anpassa rekommendationerna till vilken plattform individen använder sig av, detta kan exempelvis visa sig genom att kortare klipp rekommenderas om användaren använder sin mobiltelefon.
Dock är Google långt ifrån ensamma om personalisering av sina tjänster. Spotify, Netflix och Pinterest skriver följande på sina webbsidor:
”Updated every Monday morning, Discover Weekly brings you two hours of custom-made music recommendations, tailored specifically to you and delivered as a unique Spotify playlist.” (Spotify, 2015) ”Drama, action, komedier, dokumentärer, tv-serier – allt som du gillar att titta på, skräddarsytt för dig.” (Netflix, u.å.)
”We also use the information we collect to offer you customized content. […] Suggesting Pins or boards you might like. For example,
if you’ve indicated that you’re interested in cooking or visited recipe websites that have Pinterest features, we may suggest food-related Pins, boards, or people that we think you might like. Showing you ads you might be interested in.” (Pinterest, 2015)
Idag har många webbaserade tjänster någon typ av rekommendationssystem, vilket du som användare kan upptäcka i form av personaliserade erbjudanden om produkter eller innehåll (Nguyen, Hui, Harper, Terveen & Konstan, 2014). Personalisering definieras av Velásquez & Palade (2008) som förmågan att erbjuda innehåll eller service som är anpassad till användaren baserat på kunskap om individens preferenser och beteende.
Anledningen till att personalisering och rekommendationssystem är så populärt och utbrett beror på att det kan påverka en tjänsts framgång och företagets vinst i stor utsträckning. Företaget Amazon rapporterade att så mycket som 35 procent av deras försäljning berodde på deras rekommendationssystem. Så mycket som 75 procent av det som Netflix användare tittade på under 2012 hade sitt ursprung i personaliserade rekommendationer. (Nguyen et al. 2014)
1.1
Problemdiskussion
Denna trend av personaliserade tjänster kan till synes ses som positiv för både företagen, som uppenbarligen tjänar pengar på funktionen, samt för användarna som smidigare kan komma i kontakt med innehåll som ter sig relevant för individen.
Eli Pariser myntade uttrycket filterbubbla för att beskriva ett fenomen som vuxit fram genom personalisering av olika webbaserade tjänster och beskriver personaliseringen som problematisk (Nguyen et al. 2014; Pariser, 2011). Eli Pariser har funnit att personalisering har lett fram till att internetanvändare i stor utsträckning exponeras för innehåll och information som går i linje med individens tidigare attityder och övertygelser kring information och innehåll inom ett visst ämne (Liao & Fu, 2013; Pariser, 2011). Detta resulterar i att användaren isoleras från annat innehåll och fångas i en statisk digital omgivning. Användarens filterbubbla påverkar och ökar
individens tilltro till innehåll som redan stämmer överens med individens uppfattningar. Samtidigt kan filterbubblan minska användarens inlärningsförmåga och kreativitet. (Nguyen et al. 2014)
Artificiella rekommendationssystem har utvecklats för att efterlikna mänskliga rekommendationer genom att spåra internetmönster från stora grupper av användare.
Exempelvis kan ett system titta på vilka produkter som tidigare har konsumerats för att kunna göra individuella rekommendationer till användare. Generellt så inkluderas tre viktiga aspekter i ett rekommendationssystems design. Algoritmer är en aspekt, och de flesta algoritmer utgår från användarens preferenser för att kunna utläsa mönster. Den mänskliga faktorn är den andra faktorn, och relaterar till systemet som samlar in data om användarens preferenser. Idealiskt sett ska denna process inte vara inkräktande för användaren. Den tredje faktorn är personlig
integritet och handlar om hur insamlad data om användaren används samt innefattar att
informationen inte bör spridas och utnyttjas av andra aktörer på ett felaktigt sätt. (Velásquez & Palade, 2008)
Velásquez & Palade (2008) menar att det finns en fara med denna typ av filtrering av information, då det är möjligt att systemet filtrerar bort viktig information eller väsentliga rekommendationer. Mycket spårning och överdrivet många rekommendationer kan även upplevas som påträngande och irriterande för användare. Det kan även leda till att användare upplever att personalisering är ett verktyg för att utnyttja individen för att öka företagets framgång och vinst.
Webbaserade system som personaliserar innehåll kan dessutom leda till att det skapas ett band mellan användaren och tjänsten, men på bekostnad av individens personliga integritet. Studier angående användares känslor kring personalisering på webben i förhållande till personlig integritet visade på att användare uppskattar att företag och tjänster försöker underlätta och hjälpa användaren att hitta det innehåll som individen söker. Dock menade majoriteten att de inte uppskattade att deras personliga data utnyttjades och spreds så att andra företag kunde utnyttja informationen om deras beteende. (Velásquez & Palade, 2008)
Samtidigt finns det tjänster som profilerar sig genom att kommunicera att de inte anpassar innehåll och aktivt inte registrerar och spårar användarna. Några exempel är sökmotorn DuckDuckGo, browsern Tor, Privacy Badger och AdBlock, se ordlista.
I denna studie ska användares attityder till personalisering av tjänster undersökas samt attityder till fenomenet filterbubblan studeras. Denna studies relevans styrks av Nguyen et al. (2014), som menar att det är av vikt att studera hur rekommendationssystem och personalisering påverkar användare i förhållande till filterbubblan. Det faktum att Haider & Sundin (2016) nyligen skrev rapporten, Algoritmer i Samhället, på uppdrag av Regeringskansliet är även en styrkemarkör för att ämnet är intressant och aktuellt att studera. Haider & Sundin menar att i takt med att medier och internetbaserad information spelar en allt större roll i samhället ökar
även algoritmernas betydelse. Det är viktigt att förstå algoritmers funktion och vilka konsekvenser de kan resultera i.
Det är intressant att studera attityder till filterbubblan hos användare som studerar till
Civilingenjör inom Datateknik, Civilingenjör inom Informations- och Kommunikationsteknik, Produktionsledare: Media och Medieproduktion och Processdesign. Eftersom dessa fyra utbildningar är inriktade på media och IT är det möjligt att studenterna, genom utbildningarna har kunskap om personalisering och är mer insatta i hur personalisering fungerar än andra studenter. Det är därför intressant att studera skillnader och likheter i studenternas attityder till personalisering.
1.2
Syfte
Syftet med studien är att undersöka studenters attityder till utvecklingen av personalisering inom webbaserade tjänster. Genom att undersöka detta skulle skillnader och likheter mellan studenternas attityder kunna studeras och därmed kunna skapa en ökad förståelse för personalisering och attityder till personalisering.
1.3
Frågeställning
• Vilka attityder har studenter till personalisering inom webbaserade tjänster? • Vilka likheter och skillnader finns hos studenternas attityder till personalisering?
1.4
Avgränsningar
Studien kommer inte att undersöka studenter som studerar andra utbildningar än de fyra utvalda. Detta på grund av att de troligtvis inte i lika stor utsträckning har kunskap om personalisering. De fyra utvalda utbildningarna är baserade vid Lunds Tekniska Högskola och Malmö Högskola. Motsvarande utbildningar belägna i andra delar av Sverige kommer inte att ingå i studien då studiens utgångspunkt är Lund. Studien kommer inte att ha ett internationellt fokus på grund av studiens begränsade resursomfattning. Studien kommer inte att behandla eller undersöka algoritmers tekniska funktion eller utveckling på grund av studiens fokus på studenters attityder till personalisering.
1.5
Målgrupp
Studiens målgrupp är företag som har personaliserade tjänster och som använder sig av olika rekommendationssystem. Studien kan bidra med information till systemutvecklare om hur personaliseringssystem skulle kunna justeras eller förbättras. Studien riktar sig även till studenter och yrkesverksamma inom medieteknik samt IT.
1.6
Disposition
Inledningsvis presenteras samtliga metoder som används för att genomföra studien följt av en metoddiskussion. Därefter följer teorikapitlet som är uppdelat i fyra olika huvuddelar. Det efterföljande resultatkapitlet behandlar den empiri som erhållits genom de fem kvalitativa intervjuerna och den kvantitativa webbenkäten. Därefter presenteras en diskussion där teori och resultat analyseras och diskuteras. I slutsatsen besvaras sedan syfte och frågeställningar följt av förslag till vidare forskning.
2
Metod
Vid framställandet av studien har ett flertal metoder nyttjats och nedan beskrivs
tillvägagångssätt samt metodval. Denna studie har påverkats av projektets tidsramar vilket återspeglas i antal respondenter, omfattning och studiens bredd.
2.1
Metodval
Inom samhällsvetenskaplig forskning skiljer man på kvalitativ och kvantitativ metod (Eliasson, 2013). En kvantitativ studie kan vara att föredra om en forskare vill generera allmän kunskap om förhållanden som kan beräknas statistiskt, skapa en överblick av omfattningen av ett fenomen eller undersöka om en hypotes stämmer (Harboe, 2013). Om en forskare istället har som mål att skapa förståelse för ett fenomen och fenomenets utmärkande struktur, egenskaper, variationer och avvikelser rekommenderar Ekström & Larsson (2010) att forskaren genomför en kvalitativ undersökning.
Jag har valt att kombinera kvalitativ och kvantitativ metod genom fem kvalitativa intervjuer och en kvantitativ webbenkät. Därav kunde jag skapa en förståelse för vilka attityder studenterna har kring fenomenet och närmare undersöka hur utbredda dessa attityder är bland studenterna. Yin (2013) beskriver fem utmärkande drag för kvalitativ forskning. Två av dessa berör att man kan återge studiedeltagares synsätt och åsikter samt täcka in de omständigheter och sammanhang som människor lever i. Därav föll valet på att använda kvalitativ metod. Valet av kvantitativ metod styrks av Harboes (2013) beskrivning av att en kvantitativ studie är att föredra om man vill generera en överblick av omfattningen av ett fenomen.
2.2
Urval av studieobjekt
Eftersom personalisering på webben är utbrett och därmed, i stor utsträckning, berör de flesta användarna av webbaserade tjänster behövde studiens studieobjekt fastställas. Studenter valdes ut som studieobjekt vilket grundar sig i Findahl & Davidssons (2015) undersökning, Svenskarna och internet, där det visat sig att studenter tillbringar mest tid på internet, se figur 1.
Figur 1. Genomsnittlig tid på internet bland användare fördelat på sysselsättning 2015. (Hedin, 2016 baserad på Findahl & Davidsson, 2015)
Om studenter överlag skulle agera studieobjekt hade det troligtvis krävts en mer omfattande studie eller resulterat i en studie med för svag tillförlitlighet, på grund av projektets
resursomfattning. Därför föll valet på att fokusera på studenter som läser till Civilingenjör inom Datateknik, Civilingenjör inom Informations- och Kommunikationsteknik, Produktionsledare: Media och Medieproduktion och Processdesign. De fyra nämnda utbildningarna valdes ut med tanke på att de fokuserar på media och IT och därmed är det möjligt att de berör personalisering på olika sätt och på olika djup. Studenterna kan därför ha kunskap om personalisering och vara mer medvetna om att personalisering sker än andra studenter som inte utbildar sig inom media och IT. Det ansågs därför av intresse att undersöka hur dessa studentgrupper resonerade kring personalisering och vilka attityder det fanns kring fenomenet. Urvalet av utbildningar grundar sig även i att jag hade kontakter inom de fyra olika utbildningarna. Då kunde jag få tillgång till respondenter på ett smidigt sätt samt distribuera webbenkäten genom kanaler som endast var tillgängliga för studenterna, exempelvis genom slutna Facebookgrupper.
2.3
Kvalitativa intervjuer
En kvalitativ studie kan genomföras genom exempelvis kvalitativa intervjuer, observationer eller insamling av objekt (Yin, 2013). Den kvalitativa intervjun är bra att använda om man vill skapa förståelse för enskilda individers erfarenheter och uppfattningar av ett fenomen (Ekström & Larsson, 2010). Valet av kvalitativ metod föll därmed på den kvalitativa intervjun. Harboe (2013) menar att kvantitativ metod kräver viss förkunskap vilket kvalitativ metod kan bidra med om metoderna kombineras. Detta styrker valet att först genomföra de kvalitativa intervjuerna för att erhålla tillräcklig kunskap för att sedan kunna skapa webbenkäten.
Innan de kvalitativa intervjuerna genomfördes hade relevant teori sökts och studerats för att forskaren skulle kunna få ut tillräckligt med information från respondenterna för att kunna skapa en enkät i ett senare skede. Detta går i linje med det Ekström & Larsson (2010) beskriver, att forskaren bör ha goda förkunskaper om ämnet som studeras för att kunna ställa konstruktiva följdfrågor, förstå sammanhanget samt kunna tolka termer korrekt.
2.3.1
Urval
Vid urvalsprocessen av studieobjekt ska man svara på frågan vem eller vilka som ska studeras. Beroende på vad forskaren önskar att urvalet ska representera samt studiens syfte måste en urvalsteknik väljas. (Ekström & Larsson, 2010) Enligt Yin (2013) är det vanligt med avsiktligt urval, vilket betyder att syftet med urvalet är att välja respondenter som är mest relevanta för studien och kan erbjuda rik data. Det är eftersträvansvärt att ha respondenter som representerar det bredaste spektrat av information och synpunkter samt respondenter som återger motstridiga åsikter (Yin, 2013). I linje med detta valde jag som forskare att tillfråga respondenter som jag visste hade olika syn på fenomenet för att kunna erhålla ett brett spektra av attityder. Jag hade förförståelse om de tillfrågade studenternas olika attityder då jag som nämnts hade kontakter och insyn i samtliga utvalda utbildningar. Utöver avsiktlighetsurval har variationsurval och snöbollstekniken nyttjats. Ekström & Larsson (2010) beskriver variationsurval som att intervjugruppen representerar en bredd inom fenomenet. Snöbollstekniken innebär att urvalet börjar med att en respondent lokaliserar nästa intervjuperson. I linje med Ekström & Larssons (2010) beskrivning av variationsurval skickades en förfrågan ut till fyra studenter som läser termin sex på respektive program. Detta för att kunna studera om det fanns en skillnad mellan studenternas uppfattning om fenomenet. Tanken var att intervjua en student från varje
utbildning, men snöbollstekniken tillämpades vid lokaliseringen av en femte intervjuperson, då en av intervjupersonerna tipsade om att personen troligen var intressant att intervjua kring ämnet.
2.3.2
Tillvägagångssätt
Harboe (2013) menar att det finns olika frågetekniker som man kan använda vid kvalitativ intervju. Det kan till exempel vara personlig intervju, fokusgrupp, telefonintervju eller frågeformulär. Vid en personlig intervju träffar forskaren respondenten vid ett fysiskt möte vilket resulterar i att forskaren har möjlighet att tolka respondentens reaktioner, tonläge och kroppsspråk. Beroende på studiens syfte kan en kvalitativ intervju ha en mer eller mindre
strukturerad karaktär (Eliasson, 2013). De kvalitativa intervjuerna som genomfördes var av semistrukturerad karaktär. Ekström & Larsson (2010) beskriver att den semistrukturerade intervjuformen är temamässigt disponerad och ofta baseras på de frågeställningar som studien har som utgångspunkt. Ett antal teman bygger upp strukturen för samtalsintervjun och inom vardera tema formuleras frågor som kan vara öppna eller mer stängda. (Ekström & Larsson, 2010) Utifrån följande teman utvecklades en manual med frågor (Bilaga 1).
• Övergripande frågor om personalisering?
• I vilka sammanhang är personalisering ok/bra/dåligt? Attityder mellan olika tjänster? • Tankar om hur man kan kringgå personalisering?
Samtliga intervjuer genomfördes som personliga intervjuer vid ett fysiskt möte. Intervjuerna genomfördes enskilt och varje respondent fick välja plats och tid som personen var bekväm med. En del intervjuer genomfördes hemma hos respondenten medan andra genomfördes på café. Intervjuerna varade mellan 45 till 70 minuter. Alla respondenter informerades om studiens syfte samt tillfrågades om samtycke till att intervjun spelades in, detta i linje med Eliassons (2013) råd. Eliasson (2013) menar att intervjuerna som genomförs bör dokumenteras på något sätt, förslagsvis genom inspelning eller anteckningar. Om intervjuerna spelas in ska den intervjuade lämna samtycke till detta innan intervjun genomförs. Att spela in en intervju möjliggör för forskaren att citera ordagrant samt gå tillbaka och lyssna på det som sagts för att reda ut om någonting var otydligt.
2.3.3
Efterarbete
Enligt Ekström & Larsson (2010) är transkriberingen av en intervju inte en neutral aktivitet, utan beroende av den som genomför transkriberingen. Intervjuer bör transkriberas in extenso, vilket betyder att alla ord som uttalas, upprepningar och pauser ska dokumenteras (Ekström & Larsson, 2010). All transkribering har utförts av forskaren själv och då i in extenso. Därefter genomfördes bearbetning av intervjumaterialet genom att materialet strukturerades, reducerades och organiserades, utifrån Ekström & Larssons (2010) rekommendation. Det empiriska
• Olika grundinställningar
• Olika kunskap om vad man kan göra och hur det går till • Attityder till personalisering av olika tjänster
• Konsekvenser av personalisering
• Vad man önskar vore möjligt samt tankar kring utvecklingen av fenomenet
2.4
Enkäten
Kvantitativa undersökningar kan genomföras som exempelvis experiment, enkätundersökningar och statistisk databehandling. (Harboe, 2013; Eliasson, 2013) Valet att skapa en enkät grundade sig i att Ekström & Larsson (2010) menar att enkätundersökningar är den främsta metoden för att studera attityder hos en grupp individer. De kvalitativa intervjuerna agerade som förstudie till enkäten och detta styrks av Eliasson (2013) och Harboe (2013) som beskriver att en studie exempelvis kan inledas med kvalitativa intervjuer som erhåller en primär uppfattning av förhållanden vilket sedan kan studeras närmare med en kvantitativ undersökning.
2.4.1
Undersökningsdesign
För att utforma webbenkäten användes tekniken frågeformulär. Harboe (2013) beskriver att en av fördelarna med att använda frågeformulär är att respondenten har möjlighet att överlämna svaren helt anonymt. Eliasson (2013) lyfter fram att för att kunna skapa ett bra frågeformulär är det av vikt att förbereda undersökningen väl och täcka in ämnet systematiskt och fullständigt med frågor. Ett frågeformulär bör ligga nära studiens syfte och vara enkelt att förstå för respondenten (Ekström & Larsson, 2010; Harboe, 2013). Baserat på resultaten av de fem kvalitativa intervjuerna skapades en webbenkät med frågor som behandlade attityder till personalisering. De tydliga likheter och skillnader som framkom mellan studenterna genom intervjuerna blev enkätens utgångspunkt. Ett exempel är kunskapen om verktygen som kan användas för att förhindra personalisering där det fanns stora skillnader mellan studenterna som intervjuades vilket då var intressant att undersöka vidare i enkäten. Enkäten delades upp i fyra olika avsnitt som behandlade följande teman, se bilaga 2:
• Attityder till personalisering av webbaserade tjänster • Personalisering av olika tjänster
• Förhindra personalisering • Filterbubbla
Enligt NE (u.å) betyder attityd en tydligt visad inställning till en viss företeelse och ordet
inställning förklaras som uppfattning eller värdering som styr någons uppträdande i viss fråga.
Ens uppfattning till någonting kan påverkas av en mängd olika faktorer som exempelvis erfarenhet, tidigare upplevelser, kunskap och känslor. För att undersöka studenternas attityder till personalisering via enkäten skapades frågor som berörde faktorer som kan påverka ens attityd till personalisering, som exempelvis om man känner ett obehag kring personaliserade tjänster eller vilka nackdelar och fördelar som respondenterna ser med personalisering. Då kunde jag få en bild av vilka fördelar och nackdelar som respondenterna ansåg var viktigast rörande personalisering och som påverkar respondenternas attityder främst. Påståendet ”Jag tycker att fördelarna med personalisering av webbaserade tjänster överträffar nackdelarna” användes för att undersöka om respondenterna hade en positiv inställning till personalisering och därmed ansåg att fördelarna överträffar nackdelarna eller om de i större utsträckning hade en negativ inställning till personalisering och ansåg att fördelarna inte överträffar nackdelarna. De frågor som berör faktorer som kan påverka ens attityd till personalisering är placerade innan påståendena som mer går in på ens attityd till personalisering och personalisering av olika typer av tjänster. Detta gjordes på grund av att jag räknar med att respondenterna då har kunnat fundera kring faktorerna, positiva som negativa och därmed förberett sig på att kunna besvara vad deras attityd är till personalisering och personalisering av olika typer av tjänster.
Att använda påstående och likertskala är enligt Eliasson (2013) bra vid attitydmätningar. En likertskala sträcker sig mellan två motpoler. Det kan variera hur stor skalan är, oftast har den fem eller sju steg. Om man utesluter det neutrala steget, och använder sig av en jämn skala ”tvingar” man respondenten att välja ståndpunkt. (Eliasson, 2013) Jag har i linje med detta valt att använda mig av en skala med fyra steg för att ”tvinga” respondenten att välja sida vid frågorna som består av påståenden.
Innan enkäten distribuerades testades den på fyra representativa studenter. Ekström & Larsson (2010) likt Harboe (2013) menar att en pilotstudie av ett frågeformulär är att föredra för att säkerställa frågornas relevans och tydlighet.
2.4.2
Urval av respondenter
På Malmö Högskolas program Produktionsledare: Media och Medieproduktion och
Processdesign studerar idag cirka 356 studenter (F. Murnau, personlig kommunikation, 24 april 2016). Det finns totalt ca 700 studenter som studerar på Lunds Tekniska Högskola på
programmen Civilingenjör inom Datateknik och Civilingenjör inom Informations- och Kommunikationsteknik (Lunds Tekniska Högskola, 2015). Den totala populationen av
studieobjektet ligger då på ungefär 1050 individer. Ett problem som Ekström & Larsson (2010) menar är vanligt förekommande är förhållandet mellan populationen och det register som finns tillgängligt över populationen. Detta kallas urvalsram och urvalsramens täckning av
populationen kan variera. Ibland kan urvalsramen vara större än populationen eller så kan urvalsramen ha undertäckning, vilket betyder att man inte har möjlighet att nå ut till hela populationen utifrån urvalsramen. (Ekström & Larsson, 2010) Webbenkäten distribuerades till studenterna via slutna Facebookgrupper som riktar sig till respektive utbildningsgrupp. I denna studies fall har urvalsramen undertäckning då de individer som inte har Facebook inte täckts in. Genom att använda de olika Facebookgrupperna innehöll urvalsramen totalt ungefär 750 individer. Endast en Facebookgrupp användes för att nå ut till studenterna som läser till civilingenjör och totalt innehöll den 479 gruppmedlemmar. Flera olika Facebookgrupper användes för att nå ut till studenterna som läser medieteknik. Många medieteknikstudenter är med i flera av grupperna och därav gjordes ett överslag på hur många studenter som ingår i Facebookgrupperna, vilket beräknades till ungefär 270 individer. Urvalsprocessen av respondenter skedde genom självselektion. Urval genom självselektion bygger på att respondenterna ansluter sig frivilligt (Harboe, 2013).
2.4.3
Tillvägagångssätt
Eliasson (2013) menar att tillvägagångsättet kan påverka undersökningens utfall i form av hur många som svarar och vilka det är. Det är av vikt att få in så många svar som möjligt samt att täcka in alla grupper av de tillfrågade lika bra. Om det är få respondenter som deltar i
undersökningen är det större risk att studiens resultat inte blir tillförlitligt. Därmed är det av vikt att anpassa undersökningens tillvägagångsätt så att det resulterar i så många svar som möjligt inom ramen för studiens resurser.
Enkäten skickades ut den fjärde april 2016 till de olika Facebookgrupperna. En påminnelse gick ut under de två veckorna som enkäten var aktiv och totalt svarade 72 respondenter. Förhållandet mellan respondenterna från de olika tillfrågade studentgrupperna är illustrerat i figur 2.
Figur 2. Förhållandet mellan respondenterna utifrån studieinriktning.
Det eftersträvades att alla studiegrupper skulle täckas in lika bra men programmen Medieproduktion och Processdesign och Civilingenjör inom Informations- och
Kommunikationsteknik representerades av färre respondenter jämfört med programmen Produktionsledare: Media och Civilingenjör inom Datateknik. Dock så blev det en jämn fördelning mellan antalet deltagande medieteknikstudenter och civilingenjörsstudenter.
2.4.4
Analys
Efter att enkäten avslutades bearbetades och analyserades all data med hjälp av programmen Excel och SPSS. En Excel-fil med all data genererades genom tjänsten som användes för att skapa enkäten. Samtliga svar delades sedan in i klasser förutom svaren från de två frågorna som innehöll kategorin övrigt på grund av att svaren då var beskrivande. Om kategorier som annan eller övrigt (öppna frågor) finns med som svarsalternativ komplicerar det databehandlingen, då dessa svar måste bearbetas och kategoriseras manuellt (Harboe, 2013). Efter att svaren hade klassificerats i Excel kunde grafer och tabeller genereras genom Excel-programmet. Excel-filen analyserades genom SPSS för att finna samband mellan de olika frågorna.
2.5
Metoddiskussion
Eliasson (2013) menar att en kombination av kvalitativ och kvantitativ metod kan vara en fördel. En kombination av olika metoder kan tillföra information av olika slag samt tillsammans täcka olika infallsvinklar vilket ofta genererar en mer fullständig bild än om studien genomförs med endast en metod. Harboe (2013) menar att vid en kombinerad metod där en kvalitativ undersökning genomförs först är förutsättningarna bättre för att den kvantitativa
undersökningens resultat blir användbart. Även Ekström & Larsson (2010) styrker detta och menar att det är en strategi, för att stärka en studies kvalitet, att använda en kombination av
olika metoder som kan styrka varandra. Med stöd av detta menar jag att den kombinerade metoden har varit till studiens fördel då en bred bild av attityder till fenomenet har kunnat genereras.
Den som är ansvarig för en studie bör vara medveten om att en respondent kan ha ett syfte och en dold agenda med sin medverkan. Forskare bör därför ha en kritisk hållning till respondenten och det är av vikt att skilja på respondenter och informanter. En respondent erbjuder sin subjektiva syn på händelser och företeelser medan en informant delger sak- och
bakgrundsupplysningar. (Ekström & Larsson, 2010) Studiens samtliga deltagare agerade som respondenter då de inte tillhandahöll sak- och bakgrundsupplysningar. Det är möjligt att en del av respondenterna kan ha haft en agenda med sitt deltagande i studien. Forskaren har haft en kritisk inställning till samtliga respondenter och beaktat möjligheten till dolda agendor. Det är ett mer omfattande problem inom den kvalitativa delen av studien eftersom endast fem intervjuer genomfördes. Enskilda deltagares möjliga agendor blir inte lika påtagliga vid den kvantitativa delen av studien eftersom den inkluderar 72 respondenter.
2.5.1
Validitet och reliabilitet
Reliabilitet behandlar i hur stor utsträckning studiens empiriska data är tillförlitlig och om materialet är bearbetat på ett korrekt sätt (Harboe, 2013; Ekström & Larsson, 2010). Det förutsätter exempelvis relevant frågeställning, ett genomtänkt urval, ett rikt material samt en god analys (Ekström & Larsson, 2010). Validitet berör om man har studerat det som var ämnat att studeras. Det finns en skillnad på intern och extern validitet. Intern validitet berör vikten av att alla delmoment i studien är relevanta utifrån problemformuleringen, från planering till slutsats. Extern validitet behandlar studiens giltighet i förhållande till verkligheten. Exempel på extern validitet är att studien bygger på konkreta existerande förhållanden, att slutsatserna går att generalisera och kan anammas på liknande situationer. (Harboe, 2013)
Ekström & Larsson (2010) beskriver att intervjumaterialets fyllighet samt uppgifternas relevans för studien är en kvalitetsfaktor. Intervjumaterialet kan betraktas som mättat då ytterligare intervjuer inte bidrar till att ny information framkommer (Ekström & Larsson, 2010). Endast fem intervjuer genomfördes och intervjumaterialet upplevdes inte som mättat, dock ansågs uppgifterna av hög relevans för studien. Men eftersom de kvalitativa intervjuerna agerade som en förstudie kunde utsagorna och intervjumaterialet fyllas på och testas genom den kvantitativa webbenkäten. De kvalitativa intervjuerna och webbenkäten anser jag tillsammans skapade ett fylligt och tillräckligt empiriskt material sett till studiens omfattning och de slutsatser jag har
kunnat erhålla. Om resursomfattningen hade varit större hade forskaren till studien föredragit fler intervjuer med fler studieobjekt för att kunna skapa en bredare och mer tillförlitlig studie. Urvalsramen har som nämnts undertäckning i och med att Facebookgrupper användes för att distribuera enkäten. De individer som inte har Facebook kanske ser på fenomenet annorlunda vilket är en svaghet i studien då detta inte kunde undersökas på grund av urvalsramen. Om studien skulle upprepas hade det varit att föredra att använda sig av en urvalsram där samtliga studenter ingår, exempelvis en e-maillista som skulle kunna tillhandahållas av
utbildningsinstitutionerna. Då hade studiens empiriska data möjligtvis blivit mer tillförlitlig och studiens reliabilitet hade ökat. Facebookgrupperna användes på grund av studiens resursramar och då jag hade tillgång till de slutna Facebookgrupperna som innehöll en stor del av
populationen ansågs det som smidigare och mindre tidskrävande än om jag skulle ha kontaktat utbildningsinstitutionerna för att erhålla mailadresser till samtliga studenter.
Det naturliga bortfallet berör de som inte skulle ha deltagit i undersökningen på grund av att de inte uppfyllde respondentkraven (Ekström & Larsson, 2010). I den kvantitativa delen av studien förekom inget naturligt bortfall. Alla svarande uppfyllde kraven på att studera på någon av de fyra utvalda utbildningarna. Det externa bortfallet behandlar de som inte besvarade enkäten på grund av bristande intresse, vilja eller tid för att besvara enkäten, men som ingick i populationen (Ekström & Larsson, 2010). Det externa bortfallet för webbenkäten låg på ungefär 678 individer då förfrågan om att delta i studien gick ut till ungefär 750 studenter varav 72 svarade på
enkäten, det vill säga ungefär 10 procent. Internt bortfall rör om respondenter hoppar över att besvara en eller flera frågor (Ekström & Larsson, 2010). Fyra interna bortfall har visat sig men på olika frågor vilket har resulterat i att det i snitt är 71 svar på varje fråga. Om enkäten hade en högre svarsfrekvens hade det kunna leda till en mer tillförlitlig studie.
2.5.2
Generaliserbarhet
Generalisering inom kvalitativ metod behandlar främst om resultaten kan gå att applicera på liknande situationer eller ge vägledning i andra situationer. Generalisering inom kvantitativ metod berör om man kan generalisera utifrån ett urval av en större population. (Ekström & Larsson, 2010) En fördel med kvantitativa metoder är att möjligheten att erhålla ett
generaliserbart empiriskt material är relativt stor på grund av att det oftast är ett större antal studiedeltagare än vid kvalitativa studier samt att de bygger på ett representativt urval av undersökningsgruppen. (Ekström & Larsson, 2010; Harboe, 2013) Deltagarna i studien anses representativa eftersom samtliga ingick i studentgrupperna som studien fokuserar på. Det är
dock svårt att svara på om respondenterna är representativa utifrån hela populationen eftersom urvalet av respondenter till enkäten skedde genom självselektion. En nackdel med urval genom självselektion är att risken finns att det främst är kritiska eller aktiva respondenter som svarar, vilket kan leda till att undersökningen blir snedvriden (Harboe, 2013). Om urvalet hade skett genom ett obundet slumpmässigt urval hade det kanske genererat en mer representativ grupp av respondenter. För att undersöka om respondenterna som deltog är representativa för hela populationen skulle det behövas en mer omfattande studie för att fastställa det. Harboe (2013) menar att det krävs ett så stort urval som möjligt för att en studie ska kunna anses vara generaliserbar men menar även att om man som forskare inte är ute efter exakta slutsatser kan ett mindre urval vara acceptabelt. Denna studie är inte tillräckligt omfattande för att kunna resultera i en generaliserbar studie och generera helt korrekta slutsatser.
2.5.3
Etiska överväganden
Vetenskapsrådet (2002) beskriver ett grundläggande individskyddskrav, som de råder forskare att beakta vid genomförande av studier. Kravet består av fyra komponenter som är
konfidentialitetskravet, informationskravet, samtyckeskravet och nyttjandekravet. Konfidentialitetskravet berör att deltagare i en studie ska behandlas med största möjliga konfidentialitet. Informationskravet innefattar att studiedeltagarna skall informeras om syftet med studien samt villkoren som gäller för deltagande. Där inkluderas att forskaren ska informera om att deltagaren har rätt att avbryta sin medverkan och att deltagande är frivilligt. Samtyckeskravet behandlar att studiedeltagare själv ska samtycka till medverkan i studien och nyttjandekravet berör det empiriska materialet och att det endast får användas i studiesyfte. Samtliga krav har beaktats vid denna studie. Respondenterna har informerats om att deltagandet i studien är anonymt och frivilligt. Intervjupersonernas namn skrivs inte ut i rapporten för att garantera att utomstående inte kan identifiera individerna som deltagit i studien.
Informationskravet har uppfyllts genom att respondenterna har informerats om studiens syfte samt om respondentens roll i studien. Hänsyn har tagits till samtyckeskravet genom att
respondenterna har förfrågats om samtycke att delta i studien och nyttjandekravet har uppfyllts genom att studiedeltagarna har informerats om att det empiriska materialet endast kommer att nyttjas i föreliggande studie.
3
Teori
Teorin som presenteras nedan ligger till grund för uppsatsen. En bakgrund till personalisering och hur personalisering fungerar introducerar läsaren in i ämnet. Därefter kommer teorin om Gatekeeping att beskrivas följt av attityder och möjliga konsekvenser av personalisering samt teori om fenomenet filterbubblan. Teorin som presenteras utgörs av sekundära litterära och elektroniska källor.
3.1
Personalisering
Fill (2013) definierar personalisering som kommunikation med intressenter som kan innehålla information eller meddelanden som är tydligt riktade till mottagaren. Av Velásquez & Palade (2008) definieras personalisering som förmågan att erbjuda innehåll och service anpassad till användaren baserat på kunskap om individens preferenser och beteende. Montgomery & Smith (2009) å sin sida definierar personalisering som anpassningen av produkter eller tjänster, av producenten till konsumenten, genom att använda information om konsumentens beteende. Enligt Salonen & Karjaluoto (2016) förekommer det ingen tydlig, allmän definition av vad som skiljer personalisering från personalisering men Salonen & Karjaluoto menar att webb-personalisering är processen av webb-personalisering i en webbaserad miljö, där webb-personalisering av struktur, innehåll och interaktiva referenspunkter är inkluderade. Personalisering är nära
besläktat med ordet kundanpassning, skillnaden är att kundanpassning är specifikt efterfrågat av kunden för att passa individens behov medan personalisering sker på initiativ av företag, som en automatiserad process.
Förväntningarna kring fördelarna med personalisering har drivit fram personaliseringens popularitet (Vesanen, 2007). I och med att de teknologiska möjligheterna samt konsumenters förväntningar och beteende ständigt förändras, utvecklas personalisering som område samt vad som anses vara framgångsrik personalisering ständigt (Salonen & Karjaluoto, 2016).
Personalisering har sina fördelar då internets innehåll bara ökar vilket leder till att det kan vara svårt att orientera sig som användare. Personaliseringen spelar en viktig roll eftersom det underlättar för användare att hitta innehåll eller information som hen söker och finner relevant. (Pariser, 2011) Aguirre, Mahr, Grewal, de Ruyter & Wetzels (2015) menar att styrkan i personalisering ligger i att det kräver minimal ansträngning från kundens sida, då det ligger i marknadens intresse att identifiera och möta kundens behov.
Figur 3 presenterar en övergripande bild av personalisering och vilken nytta och kostnad det kan innebära för användare och företag. (Vesanen, 2007)
Figur 3. En övergripande bild av personaliseringens nytta och kostnad för företag och kund (Hedin, 2016 baserad på Vesanen, 2007).
Vesanen (2007) lyfter fram att personalisering kan skapa nytta för kunden. Detta kan vara bättre matchning mellan användaren och produkt utifrån preferenser eller bättre produkt, service, kommunikation eller upplevelse (Vesanen, 2007; de Pechpeyrou, 2009). Men personalisering kan samtidigt vara en slags kostnad för användaren eller en investering. Detta i form av exempelvis risk för minskad personlig integritet, spam och spenderad tid. När fördelarna med personalisering är större än kostnaderna, skapas konsumentvärde för kunden. (Vesanen, 2007) Om användarens kostnader överskrider fördelarna och nyttan med personalisering menar Vesanen (2007) att tjänsten eller produkten inte är redo för att implementera personalisering. Nyttan för företaget som bedriver tjänster som är personaliserade kan exempelvis vara lojalare kunder, nöjdare kunder, differentiering till konkurrenter och bättre respons. Kostnaden för företagen som använder personalisering som strategi kan exempelvis vara utbildning,
3.1.1
Hur personalisering fungerar
Personlisering är en process då tjänster eller produkter anpassas för att matcha individuella behov och preferenser genom att använda data från konsumenten. Processen går ut på att ett företag erhåller kunskap om användarens preferenser som därmed kan omvandla kunskapen om användaren till rekommendationer, erbjudanden och olika interaktionsmöjligheter. (Salonen & Karjaluoto, 2016)
Haider & Sundin (2016) beskriver att algoritmer spelar en avgörande roll för exempelvis Google, Netflix och Facebook för att de ska kunna personalisera sina tjänster. En algoritm är en sekvens av förutbestämda steg som utgår från värden, i form av indata som omformas till andra värden som blir utdata. Den indata som algoritmerna använder sig av kan användaren antingen dela med sig av medvetet, genom att till exempel fylla i en användarprofil eller mindre medvetet eller omedvetet, exempelvis i form av kakor (Haider & Sundin, 2016; Aguirre et al., 2015). Kakor är en textfil som lagras på användarens dator och meddelar till en server hur användaren använder sin webbläsare. Den osynliga bakgrundsaktivitet som kakorna bedriver är en
förutsättning för att algoritmerna ska fungera. (Haider & Sundin, 2016) Enligt Haider & Sundin (2016) är det omöjligt att exakt studera hur algoritmerna fungerar och fastställa deras påverkan då användare och algoritmer ständigt förändras. Dessutom påverkas kännedomen om
algoritmerna av att det främst är kommersiella företag som har kontrollen över algoritmerna och därmed vill hålla dem dolda på grund av konkurrenskraft.
Velásquez & Palade (2008) beskriver personalisering i tre kategorier. Den ena är kollaborativ filtrering där användaren uppmuntras till att värdera och recensera produkter och tjänster. Användare som har liknande åsikter om en produkt förväntas gilla samma produkter. Filtrering baserat på beslut använder sig av ett frågeformulär för att kunna reda ut vad användaren
föredrar. Innehållsbaserad filtrering utgår ifrån användarens webbaserade beteende för att sedan analysera det och finna användarens preferenser. Enligt Choi, Lee & Kim (2011) finns det även hybrider mellan dessa olika typer av personalisering.
3.1.2
Rekommendationssystem
Att använda sig av rekommendationer och andras erfarenheter är ett effektiv sätt att undvika misstag samt att finna det man söker (Velásquez & Palade, 2008). Enligt Velásquez & Palade (2008) efterfrågas rekommendationer konstant och artificiella rekommendationssystem, som är en typ av personalisering har utvecklats för att efterlikna mänskliga rekommendationer genom
att spåra internetmönster från stora grupper av personer. Exempelvis kan ett system titta på vilka produkter som tidigare har konsumerats för att kunna göra individuella rekommendationer till användare.
Velásquez & Palade (2008) beskriver att det är billigare att satsa på att behålla kunder än att skaffa nya inom den digitala marknaden. Företagen använder rekommendationssystem som marknadsstrategi för att skapa en värdefull relation med sina kunder. Missanpassade
rekommendationer kan dock upplevas som inkräktande för användaren. Malik & Fyfe (2012) lyfter fram detta och kallar det för Black box filtration. Black box filtration uppstår då
användaren inte har möjlighet att kontrollera en rekommendationsprocess och i samband med det inte förstår anledningen till varför en rekommendation rekommenderas.
3.1.3
Personalisering av olika tjänster
Sökmotorer använder personalisering för att förfina användares sökresultat (Aguirre et al., 2015), och att söka information på nätet har idag blivit synonymt med att Googla (Pariser, 2011). Haider & Sundin (2016) beskriver att det som har bidragit till att Google har överträffat konkurrenterna beror på algoritmen PageRank. PageRank utgår från att webbsidor med många in-länkar anses ha högre relevans än de webbsidor som har få in-länkar (Velásquez & Palade, 2008; Haider & Sundin, 2016). Idag används PageRank i kombination med andra faktorer som sökhistorik, plats och tidigare beteendemönster och sökalgoritmen ändras runt 500-600 gånger varje år. Även Facebooks algoritm uppdateras löpande likt Googles algoritm. Facebooks
algoritm bestämmer vad som ska visas i varje användares nyhetsflöde och algoritmen EdgeRank som Facebook använde från början utgick från närhet, aktualitet och vikt. 2013 byttes
EdgeRank ut till Newsfeed algoritm som är en mer komplex algoritm. Den nya algoritmen utgår från de tre faktorerna som EdgeRank utgick ifrån men väger även in ett tusental andra faktorer för att möjliggöra en hög individanpassning. Exempel på faktorer som Newsfeed algoritm använder sig av är vilka sidor användaren och användarens vänner gillar och vilka inlägg eller uppdateringar som individen klickar på, delar, kommenterar och gillar. (Haider & Sundin, 2016) Streamingtjänster som Netflix, YouTube och Spotify använder sig av kollaborativ filtrering för att kunna erbjuda användare rekommendationer och tips. Netflix försöker med sin algoritm förutse vad en användare skulle vilja se baserat på användarens preferenser och liknande användares beteendemönster. (Haider & Sundin, 2016) Det är inte bara streamingtjänster som använder sig av kollaborativ filtrering utan även e-handeltjänster som Amazon,
et al., 2015). Kollaborativ filtrering visar sig ofta genom rekommendationer som ”andra som köpte x, köpte även y”, men mer avancerade algoritmer som genomför kollaborativ filtrering kan använda sig av en mängd faktorer som användarens sociala nätverk, beteendehistorik, profilinställning eller tid och dag. Användaren uppmuntras ofta till att rekommendera,
betygsätta och recensera tjänster eller produkter för att personalisering ska bli bättre. (Haider & Sundin, 2016)
Haider & Sundin (2016) beskriver även att nyhetsmedier använder sig av algoritmer för att anpassa nyheterna till läsarna och dels genererar nyheter ur data, vilket kallas robot-journalistik. Individer kan läsa nyheter för att det är avkopplande, underhållande, eller på grund av ett mer specifikt intresse eller för att erhålla generell information (Lavie, Sela, Oppenheim, Inbar & Meyer, 2010). Det kan därmed vara utmanande för ett personaliseringssystem att skapa en god balans mellan individens olika intressen och tillfredsställa individens behov av olika typer av nyheter (Ibid.).
3.2
Gatekeeping theory
Gatekeeping är processen då mängder av information utsorteras och arbetas om till det begränsade antalet meddelanden som dagligen når människor genom kanaler av olika slag. Processen kring gatekeeping påverkar allas sociala verklighet eftersom att det influerar hur vi definierar omvärlden och våra liv och informationen som tar sig igenom alla grindar blir en del av människors sociala verklighet. (Bozdag, 2013; Shoemaker & Vos, 2009) Enligt Bozdag (2013) har tjänster som Facebook och Google blivit viktiga gatekeepers i vårt samhälle då de tagit över stora delar av traditionella kanalers roll kring att sprida information.
Gatekeepingprocessen som behandlar algoritmer börjar med att information eller innehåll väljs ut och slutar då användaren möts av budskapet. Algoritmerna som används under processen påverkas av de som har designat dem då de bestämmer vilka faktorer som algoritmen ska inkludera och hur faktorerna ska värderas. Det är viktigt att man som användare inte har en tro på att algoritmerna och personaliseringssystemen är objektiva. Algoritmerna är automatiserade och externa parter kan manipulera dem eller anpassa sig till dem på olika sätt, exempelvis genom sökoptimering. Haider & Sundin (2016) menar att det krävs källkritik men även kritik kring varför användare exponeras för en del källor men inte av andra.
Inom vinstdrivande företag är gatekeeping-processen en del av strategin. Marknaden är den mekanism som balanserar tillgång och efterfrågan och marknaden belönar media som producerar en produkt som möter den efterfrågan som finns på marknaden. De företag som
erbjuder en tjänst som bäst möter konsumenternas behov och det som efterfrågas kommer att bli mest framgångsrik. Mediemarknaden består av två produkter då medieföretag säljer
medieprodukter till konsumenter och konsumenterna säljs som produkter till marknadsförare. Mediekanaler som inte erbjuder det innehåll som konsumenterna efterfrågar kommer att få mindre publik, och därmed sämre produkter som de kan sälja till marknadsförare. (Shoemaker & Vos, 2009)
Haider & Sundin (2016) beskriver hur företagen strävar efter att behålla användarna genom att ”låsa in” dem och därmed utestänga konkurrenterna. Detta visar sig exempelvis genom att företag går ihop i partnerskap och erbjuder en komplett lösning för användarna eller att företagen gör konkurrenternas tjänster icke-kompatibla med deras plattformar eller tjänster. Detta leder till att det skapas konkurrerande sammansättningar av plattformar och tjänster som skapar en kulturell och social verklighet. Haider & Sundin (2016) frågar sig om det är möjligt att välja bort exempelvis Facebook utan att stängas ute från en bit av samhället. När många företag och organisationer använder Facebook som primär kommunikationskanal, och offentliga institutioner informerar och kommunicerar genom Facebook kan det bli svårt att som användare stå utanför denna verklighet.
3.3
Attityder till personalisering
Trots att personalisering av tjänster kan underlätta för användaren kan det upplevas som påträngande och påverka individens känsla av personlig integritet.Känslan av att
personaliseringssystem hotar ens personliga integritet är den främsta orsaken till att användare avstår från att använda en webbaserad tjänst som personaliserar. (Velásquez & Palade, 2008) Som nämnt kan användaren antingen vara medveten eller omedveten om att data samlas in. När användaren är omedveten om att data samlas in kan det leda till att individen upplever att hens privata integritet är hotad. (IJsselsteijn, Markopoulos, Eggen, Ruyter & Garde-Perik, 2008) Bozdag (2013) menar att explicit personalisering, där användaren tydligt förstår att en tjänst är personaliserad, bör kombineras med implicit personalisering. Bozdag anser att det bör finnas en dialog med användaren där användaren tydligt informeras om att tjänsten är personaliserad och att varför tjänsten är det. När personaliseringssystemet gör antaganden om användarens
preferenser bör användaren få bekräfta eller dementera antagandena. På så sätt kan systemet få användbar feedback från användaren och användaren kan påverka och enkelt förstå varför personaliseringssystemet agerar på ett visst sätt.
En samtyckeslag kring kakor infördes 2011 med hopp om att öka användares medvetenhet kring kakor och tjänsters insamling av uppgifter om användaren. Dock menar Haider & Sundin (2016) att det troligtvis är få som aktivt väljer bort en webbplats på grund av att tjänsten använder sig av kakor. Det finns en generell kunskap kring algoritmernas betydelse men enligt Haider & Sundin är kunskapen för liten för att användare ska agera. De menar att medborgare i allmänhet behöver kompetensutveckling inom medie- och informationskunnighet. Detta på grund av att informationsstrukturen har förändrats och att makten över informationsflöden och kanaler resulterar i att aktörerna får viss kontroll över samhället (Haider & Sundin, 2016; Bozdag, 2013).
3.4
Konsekvenser av personalisering
Internets innehåll ökar ständigt och detta har resulterat i en uppmuntran om selektiv exponering av internets innehåll (Aguirre et al., 2015). Det har lett fram till att internetanvändare i stor utsträckning exponeras för innehåll och information som går i linje med individens attityder och övertygelse (Liao & Fu, 2013). Personalisering handlar om att skapa en omgivning som bara består av det okända som angränsar till det som är känt för användaren. All denna
personalisering leder till att varje individ omges av sin egen lilla informationsbubbla.
Användaren matas med innehåll och information som är välbekant, behagligt och som bekräftar individens tidigare övertygelser. (Pariser, 2011) Det här menar Pariser (2011) är en revolution kring hur information konsumeras vilket påverkar demokratin och formar individers
inlärningsförmåga och kunskap.
Enligt Pariser (2011) har individer alltid konsumerat media utifrån egna intressen och ignorerat media som inte är lockande vilket kan tolkas som att varje individ redan innan internet levde i sin egen filterbubbla. Det som dock skiljer internets filterbubbla från hur individer har
konsumerat och skapat sina egna bubblor vid användande av traditionella medier visar sig på tre olika sätt. För det första är användaren ensam i sin filterbubbla eftersom allt innehåll anpassas till individens preferenser. För det andra är filterbubblan osynlig och användaren har ingen chans att veta eller ta reda på vilka antaganden filtersystemet utgår ifrån och hur de uppstår från början, och därmed har användaren ingen vetskap om vad för innehåll som stängs ute och varför. För det tredje så väljer inte användaren att vara i sin filterbubbla. När traditionella medier används är det ett aktivt val och individen är medveten om vilket slags filter som filtrerar innehållet. Exempelvis om man läser en dagstidning är det tydligt vilken slags tidning det är, vilket gör att läsaren kan tolka in tidningens agenda i tolkningen av innehållet. När
användaren befinner sig i sin filterbubbla är det inte lika enkelt eftersom att individen inte själv kan göra samma val på grund av personaliserade filter. Zuiderveen Borgesius, Trilling, Möller, Bodó, de Vreese & Helberger (2016) menar dock att det inte finns något empiriskt stöd för rädslan kring filterbubblor och dess konsekvenser. De beskrev en studie som visade på att personalisering av nyhetstjänster hade en polariserande effekt. Dock menar de att det inte finns någon risk för att filterbubblor ska skapas och påverka demokratin idag. Detta på grund av att de menar att ingen individ lever i en absolut sluten bubbla. Individer i dagens samhälle har tillgång till en mängd olika informationskanaler. Om personaliserade nyhetstjänster blir individers huvudsakliga informationskälla kan det bli ett problem i framtiden, som kan påverka
demokratin. De menar dock att debatten kring filterbubblor är viktig på grund av att teknologin kring personalisering och medielandskapet ständigt utvecklas och förändras.
När en användares filterbubbla skapas är det företagen som äger tjänsterna som väljer vilka alternativ som användaren kan reglera och inte reglera (Pariser, 2011). Bozdag (2013) beskriver att en del forskare argumenterar och uppmanar användare att sabotera eller försvåra
personaliseringen av tjänster genom att rensa kakor, ändra sitt handlingsmönster eller genom att börja använda tjänster som inte personaliserar. Att stänga av personaliseringen eller att börja använda tjänster som inte personaliserar är enligt Bozdag inte ett bra alternativ för användaren, då det är en belastning att orientera sig bland all tillgänglig information på webben. Själv menar Bozdag att användare bör ta till vara på den positiva effekt som personalisering kan ha och menar att man genom design bör minimera de negativa effekterna och förbättra de positiva effekterna av personalisering.
4
Resultat
Nedan följer en presentation av empirin från webbenkäten och de fem kvalitativa intervjuerna med studenter som läser universitetsprogrammen Civilingenjör inom Datateknik, Civilingenjör inom Informations- och Kommunikationsteknik, Produktionsledare: Media samt
Medieproduktion och Processdesign. Då fem respondenter intervjuades finns det en intervjuperson som representerar respektive utbildning med undantag från utbildningen Civilingenjör inom Informations- och Kommunikationsteknik, där två studenter intervjuades. Respondenterna som läser till civilingenjör benämns som Student Datateknik, Student Infocom 1 och Student Infocom 2 och respondenten som läser till Produktionsledare: Media benämns som Student PM och studenten som läser Medieproduktion och Processdesign nämns som Student MPP. Studenterna benämns ibland även i grupp där Student Datateknik, Student Infocom 1 och Student Infocom 2 betecknas som civilingenjörerna och Student PM och Student MPP benämns som medieteknikstudenter.
4.1
Reflektion kring personalisering
Personalisering kan te sig på olika vis beroende på vilken tjänst som är personaliserad. Samtliga intervjurespondenter har märkt av personalisering på olika sätt vid användning av webbaserade tjänster. De beskrev att de främst har märkt av personalisering genom riktad marknadsföring och annonsering på webbsidor. Detta har oftast visat sig genom att de varit inne på en webbsida för att finna en produkt och kort därefter exponerats för reklam om produkten, via exempelvis Facebook. Datateknik-studenten (2016) beskrev följande om hur hen tydligast har märkt av personalisering och menar att anledningen till att hen exponeras för vissa specifika annonser inte alltid är tydlig:
”Jag har fått mycket reklam för olika slags gymartiklar, men jag vet inte riktigt varför det är så. Eller jo, jag är väl allmänt ett fan av Arnold Schwarzenegger […], jag vet inte om det är något som har kommit fram där.” (Student Datateknik, 2016)
Samtliga intervjurespondenter hade någon gång reagerat och reflekterat över att en tjänst varit personaliserad. Det visade sig att över 85 procent av respondenterna i enkäten menade att de ofta eller ibland reflekterar över att webbaserade tjänster är personaliserade, se figur 4. Det förekom inga skillnader mellan de olika studieinriktningarna angående hur ofta man reflekterar över att en tjänst är personaliserad.