Fakulteten f¨or teknik och samh¨alle Datavetenskap
Examensarbete 15 h¨ogskolepo¨ang, grundniv˚a
Replikation: Prestanda med MongoDB
Replication: Performance with MongoDBSebastian Nirfelt
Examen: Kandidatexamen 180 hp Huvudomr˚ade: Datavetenskap Program: Systemutveckling
Datum f¨or slutseminarium: 2016-05-27
Handledare: Mia Persson
Sammanfattning
F¨orm˚agan att lagra data ¨ar en stor bidragande faktor till att vetenskapen st¨andigt r¨ort sig fram˚at. Under n˚agra tusen ˚ar har m¨anniskan utvecklats fr˚an att lagra data p˚a grottv¨aggar till h˚arddiskar och kraven p˚a prestanda, tillg˚ang och fels¨akerhet ¨okar i rasande takt. F¨or att hantera data i det moderna samh¨allet utvecklas st¨andigt nya metoder och en av dessa metoder ¨ar replikation. Den h¨ar unders¨okningen testar hur replikation p˚averkar prestandan i en distribuerad MongoDB-l¨osning. Testerna i unders¨okningen ¨ar automatiserade och k¨ors mot databasen i olika konfigurationer f¨or att se hur prestandan f¨or¨andras.
Abstract
The ability to store data is a contributing factor in making science constantly move for-ward. In a few thousand years man has evolved from storing information on cave walls to hard drives and requirements in performance, availability and fault tolerance are rapidly increasing. To manage information in modern society new methods are constantly evol-ving and one of these methods is replication. This study tests how replication affects the performance in a distributed MongoDB solution. The tests in this survey are automated and run against the database in different configurations to see how performance changes.
Inneh˚
all
1 Inledning 1 1.1 Introduktion . . . 1 1.2 Bakgrund . . . 1 1.2.1 Replikation . . . 1 1.2.2 MongoDB . . . 21.2.3 Replikation i andra databaser . . . 2
1.2.4 Tidigare forskning . . . 3 1.3 Problemst¨allning . . . 4 1.4 Fr˚agest¨allning . . . 4 1.5 Syfte . . . 4 2 Metod 5 2.1 Metodbeskrivning . . . 5 2.2 Experiment . . . 5 2.2.1 Inmatningstest . . . 6 2.2.2 H¨amtningstest . . . 6 2.2.3 Uppdateringstest . . . 6 2.2.4 Borttagningstest . . . 6 2.2.5 Haveritest . . . 7 2.3 Testplattform . . . 7 2.3.1 H˚ardvara . . . 7 2.3.2 Mjukvara . . . 7 2.4 Metoddiskussion . . . 8 3 Resultat 9 3.1 Inmatningstest . . . 9 3.2 H¨amtningstest . . . 10 3.3 Uppdateringstest . . . 11 3.4 Borttagningstest . . . 12 3.5 Haveritest . . . 13 4 Analys 14 5 Diskussion 15
6 Slutsatser och vidare forskning 15
Referenser 16
1
Inledning
1.1 IntroduktionUnder de senaste trettio ˚aren har olika system f¨or att hantera datalagring utvecklats och successivt f¨orb¨attrats. Fram till b¨orjan av 2000-talet dominerades marknaden totalt av relationella databaser f¨or att sedan ta en v¨andning i och med introduktionen av web 2.0 som ¨oppnade d¨orren f¨or icke-relationella databaser p˚a stor skala. Flera stora f¨oretag som Amazon, Facebook, Google och Yahoo har tvingat utvecklingen av databassystem fram˚at och kraven p˚a prestanda och fels¨akerhet har ¨okat drastiskt. [5]
Ett s¨att att ta sig an problemet med h¨ogre krav p˚a prestanda och fels¨akerhet ¨ar att implementera distribuerade databaser genom att koppla ihop flera individuella servrar. N¨ar flera enskilda servrar har egna kopior av samma information kallas det replikation (se [11][12][13] och stycke 1.2.1) och det anv¨ands f¨or att uppn˚a b˚ade prestanda och feltolerans men bidrar till en konflikt mellan konsistens och effektivitet. [7]
1.2 Bakgrund 1.2.1 Replikation
Det har under m˚anga ˚ar forskats inom omr˚adet replikation. Syftet med replikation ¨ar i grunden att ha h¨og tillg¨anglighet till data samtidigt som systemet ¨ar fels¨akert. Om en en-skild server (h¨adanefter kallad nod) havererar ¨ar datan fortfarande lagrad p˚a en eller flera andra noder, vilket kr¨aver att systemet ¨ar konsistent vid lagring av data. All data m˚aste hela tiden finnas p˚a flera noder och d˚a systemet hela tiden m˚aste kontrollera att datan ¨
ar konsistent kan problem med prestanda uppst˚a. F¨or att h˚alla alla noder uppdaterade anv¨ands processorkraft fr˚an servrarna vilket g¨or att f¨arre f¨orfr˚agningar kan hanteras sam-tidigt och behandlingstiden kan bli l¨angre. Detta i sin tur leder till att olika replikerande databaser inriktas mot specifika syften. [2]
Hur en databas hanterar replikation klassificeras enligt tv˚a grundl¨aggande fr˚agor: • Var hanteras ¨andringar av data?
• N¨ar hanteras ¨andringar av data?
Var ¨andringar hanteras ¨ar uppdelat i tv˚a olika s¨att. Det ena ¨ar att databasen har en prim¨ar nod som hanterar alla ins¨attningar, uppdateringar och borttagningar. Den prim¨ara noden skickar i sin tur ut uppdateringen till de andra noderna. Det andra s¨attet ¨ar att alla noder kan hantera ¨andringar i databasen. F¨ordelen med att endast en nod hanterar ¨andringar ¨
ar att kontrollsystemet blir mindre avancerat. Om alla noder i systemet kan ¨andra i datan kommer kontrollsystemets komplexitet ¨oka drastiskt. F¨ordelen med att alla noder kan uppdatera datan ¨ar att systemet blir v¨aldigt flexibelt. N¨ar alla ¨andringar hanteras av en nod kallas det primary copy och n¨ar alla noder kan hantera ¨andringar kallas det update anywhere. [2]
N¨ar ¨andringar hanteras ¨ar ocks˚a det uppdelat i tv˚a olika s¨att som kallas eager och lazy. Med eager menas att ¨andringarna skickas ut till alla noder och sparas samtidigt och n¨ar ¨andringen ¨ar sparad skickas bekr¨aftelsen tillbaka. Eager replikation garanterar att data ¨ar konsistent ¨over alla noder och eftersom eager replikation v¨antar p˚a alla noder kan svarstiden potentiellt bli l˚ang. I lazy replikation sparas ¨andringarna lokalt p˚a den nod
som tagit emot f¨orfr˚agningen och skickar direkt tillbaka svar innan f¨orfr˚agningen skickas vidare till de andra noderna. Eftersom ¨andringarna inte skickas vidare direkt kan inte heller konsistensen garanteras i alla l¨agen. Det enda som kan garanteras ¨ar att databasen f¨orr eller senare ¨ar konsistent. F¨ordelen med lazy replikation ¨ar att svarstiderna ofta blir v¨aldigt snabba. [2][7]
Var och n¨ar en databas hanterar ¨andringar kombineras till fyra olika kategorier. Alla kontrollsystem f¨or replikation tillh¨or en av dessa kategorier. [2]
1.2.2 MongoDB
MongoDB ¨ar i skrivande stund v¨arldens fj¨arde mest popul¨ara databas enligt [9]. MongoDB ¨
ar en icke-relationell databastyp och ¨ar av typen document store [4]. All data som sparas i MongoDB l¨aggs i dokument som kan i sin tur samlas i collections. Syftet med MongoDB ¨
ar att ha h¨og prestanda och garantera att datan f¨orblir intakt. F¨or att garantera h¨og prestanda ¨ar en av MongoDBs k¨arnfunktioner horisontell skalbarhet. [10]
Vertikal skalbarhet inneb¨ar att f¨or att ¨oka prestandan p˚a en databas (eller annat system) uppgraderas serverns h˚ardvara. Horisontell skalbarhet inneb¨ar i st¨allet att en eller flera servrar l¨aggs till f¨or att f¨ordela belastningen mellan sig. I takt med att belastningen mot en MongoDB databas ¨okar kan fler servrar l¨aggas till utan att n˚agot mellansystem kr¨avs. [10]
F¨or att garantera att datan som lagrats i MongoDB ¨ar intakt och alltid finns tillg¨anglig har mjukvara f¨or replikation implementerats. I MongoDB kallas detta ett replica set. [10] Ett replica set i MongoDB byggs upp av flera noder som har samma data. Varje replica set har en prim¨ar nod som hanterar alla ¨andringar och f¨or att h˚alla databasen konsistent anv¨ands metoden lazy replikation. Efter att en ¨andring gjorts mot den prim¨ara noden skickas den ut till de ¨ovriga noderna och h¨og feltolerans garanteras genom att alla noder har samma data vilket leder till att ingen data g˚ar f¨orlorad om en server skulle haverera. Om den prim¨ara noden havererar kommer en omr¨ostning mellan noderna att ske. Den nod som f˚ar flest r¨oster blir den nya prim¨arnoden. I fallet att antalet noder skulle vara j¨amnt kan antingen en nod ha befogenhet att l¨agga tv˚a r¨oster eller s˚a kan replica setet ha en arbiter. En arbiter ¨ar en nod vars enda syfte ¨ar att r¨osta om en ny prim¨ar nod och den har ingen data sparad. Replica set till˚ater ¨aven h¨amtningar fr˚an alla noder. Detta kombinerat med lazy replikation g¨or att den nod som hanterar h¨amtningen inte alltid kan garantera att den f˚att datan fr˚an prim¨arnoden. I dessa fall kan ingen eller fel data returneras. [11] 1.2.3 Replikation i andra databaser
Olika databaser hanterar och strukturerar data p˚a olika s¨att. Tv˚a av de mest popul¨ara databaserna enligt [9] ¨ar MySQL och Cassandra. D˚a dessa databaser hanterar data an-norlunda ¨an MongoDB blir deras s¨att att hantera replikation ocks˚a annorlunda.
MySQL ¨ar en relationell databas som i standardkonfigurationen hanterar replika-tion enligt primary copy och lazy precis som MongoDB. Ut¨over standardinst¨allningarna kan MySQL konfigureras f¨or flera olika ¨andam˚al och ett av de s¨att som fr˚ang˚ar stan-dardl¨osningen ¨ar att replikationen sker semisynkroniserat som en blandning av eager och lazy. Detta sker genom att den prim¨ara noden fortfarande hanterar alla f¨orfr˚agningar som inneh˚aller ¨andringar men v¨antar bara p˚a svar fr˚an en sekund¨ar nod i st¨allet f¨or alla. Replikation till de ¨ovriga noderna sker sedan enligt metoden lazy. [12]
Cassandra ¨ar en icke-relationell databas som ¨ar inriktad p˚a att hantera stora m¨angder data och mycket trafik. Den ¨ar uppbygd av noder som ¨ar samlade i data centers. Varje data center kan ha egna inst¨allningar f¨or replikation. Data centers ¨ar i sin tur samlade i ett kluster. Databasen h˚alls synkroniserad enligt lazy replikation men anv¨ander update any-where i st¨allet f¨or primary copy. Eftersom alla noder kan hantera ¨andringar blir Cassandra en v¨aldigt flexibel databastyp. Nackdelen med kombinationen update anywhere och lazy ¨
ar att databasen kr¨aver mycket intern kommunikation f¨or att h˚allas synkroniserad.[8] 1.2.4 Tidigare forskning
De senaste tre decennierna har det forskats v¨aldigt mycket inom omr˚adet replikation. Att kunna ha samma data p˚a flera olika geografiska platser kan ge b˚ade f¨ordelar i prestanda och fels¨akerhet. F¨or att h˚alla datan synkroniserad st¨aller replikation h¨oga krav p˚a databasens kontrollsystem och att utveckla snabba och stabila kontrollsystem har varit fokus f¨or m˚anga studier. [2]
Med fokus p˚a prestanda hos databastyperna MongoDB och Cassandra testas databa-serna i olika scenario i [1]. Artikeln b¨orjar med en j¨amf¨orese av hur de olika databaserna anv¨ands och vilka funktioner de innefattar f¨or att sedan g˚a vidare till att j¨amf¨ora prestan-dan under olika belastningar. De olika belastningar som beskrivs i rapporten best˚ar av blandningar av inmatningar, uppdateringar och h¨amtningar f¨or att symbolisera verkliga scenarion. Slutsatsen blir att Cassandra hanterar stora m¨angder ¨andringar av data b¨attre ¨
an MongoDB vilket kan h¨arledas till att Cassandra anv¨ander sig av update anywhere i st¨allet f¨or primary copy. [1]
I [6] j¨amf¨ors MongoDB med Microsoft SQL Server. I testet ska mallar f¨or anv¨andare hanteras av databaserna d¨ar varje anv¨andare tillh¨or en avdelning och ett antal projekt. Testerna innefattar inmatningar, uppdateringar och h¨amtningar som genereras till de olika databaserna. I slutsatsen f¨ormedlar f¨orfattarna att MongoDB presterade v¨aldigt mycket b¨attre i en majoritet av fallen och d˚a testerna endast k¨ors mot databaser med en nod f¨oresl˚ar f¨orfattarna att tester g¨ors mot databasser med flera noder. [6]
Under kapitel fem i [2] utreds olika typer av replikation f¨or att se hur prestanda p˚averkas. N˚agra av testerna inkluderar hur prestanda p˚averkas vid replikation ¨over sto-ra geogsto-rafiska omr˚aden och n¨ar en databas ska kunna administreras av flera individuella akt¨orer. Slutsatsen blir att mer forskning inom decentralicering av databaser beh¨ovs f¨or att prestanda ska kunna h˚allas h¨og i framtiden. [2]
I [3] ges ett f¨orslag p˚a hur konsistens kan delas upp f¨or att ¨oka prestanda. I artikeln implementeras en algoritm f¨or att delvis replikera en distribuerad databas med 64 no-der. Databasen i fokus var av typen PostgreSQL. F¨orfattarna fick ett lyckat resultat och tiden f¨or en transaktion var omkring 15% snabbare ¨an mot en fullt replikerad databas. F¨orfattarna l¨agger i slutsatsen stor vikt p˚a hur systemet konfigureras f¨or att k¨ortiden f¨or transaktioner ska g˚a ner. [3]
F¨or att lyfta fram de olika NoSQL databaserna har i [4] en lista sammanst¨allts. F¨orfattaren beskriver de olika NoSQL-databaserna och ger exempel p˚a olika databaser inom varje kategori. Varje databas f¨orklaras och grunderna i funktionaliteten f¨orklaras. Till varje typ av NoSQL har f¨orfattaren skrivit en sammanfattning som lyfter styrkor och svagheter i typen av databas. F¨orfattaren f¨orklarar att det ursprungliga syftet med NoSQL-databaser ¨ar att snabbt och s¨akert kunna lagra information i samband med ett
v¨axande internet vilket gjort att fokus mer varit p˚a prestanda ¨an garanterad konsistens. Ett bevis p˚a detta ¨ar bristande st¨od f¨or transaktioner i m˚anga NoSQL l¨osningar. Enligt f¨orfattaren har NoSQL-databaser ofta andra f¨ordelar som horisontell skalbarhet och snabb replikation. Eftersom NoSQL till viss del fr˚ang˚ar de relationella databaserna kan de ocks˚a specialiceras till specifika ¨andam˚al. [4]
1.3 Problemst¨allning
Replikation inneb¨ar extra kommunikation mellan noderna i databasen (se 1.2.1) och kan d¨armed p˚averka prestandan. Replikerande databaser best˚ar av flera noder och ska fungera ¨
aven om en nod havererar. Vid haveri beh¨over databasen hantera f¨orlusten av en nod och detta kan i sin tur ocks˚a p˚averka prestandan. D˚a f¨or¨andringar i prestanda kan p˚averka ett system positivt eller negativt beh¨ovs unders¨okningar som visar hur prestandan f¨or¨andras i olika fall. Unders¨okningen av tidigare forskning visar att det finns unders¨okningar som testar skillnader i prestanda mellan olika databaser men f¨arre unders¨okningar som testar prestandan hos en databas i olika konfigurationer.
1.4 Fr˚agest¨allning
Hur p˚averkas prestandan i en distribuerad MongoDB-l¨osning med h¨ansyn till replikation? Hur p˚averkas prestandan i en replikerande MongoDB-l¨osning med h¨ansyn till haveri? 1.5 Syfte
Den h¨ar unders¨okningen syftar till att testa hur prestandan f¨or¨andras i en databas med h¨ansyn till den ¨okade m¨angden kommunikation vid replikation. Unders¨okningen ska ocks˚a visa hur prestandan f¨or¨andras vid haveri av olika typer av noder i en databas.
Fr˚an den information som testerna genererar ska en tydlig bild av hur replikation kan p˚averka prestandan i MongoDB presenteras. Informationen ska kunna anv¨andas som underlag till vidare forskning och vid val av databaskonfiguration till olika digitala system.
2
Metod
2.1 Metodbeskrivning
Precis som i [1] och [6] best˚ar testerna i den h¨ar artikeln av att uts¨atta en databas f¨or olika belastningar. Skillnaden ¨ar att i st¨allet f¨or att j¨amf¨ora en databas med en annan j¨amf¨ors endast en databas med sig sj¨alv i olika konfigurationer f¨or att i sin tur avg¨ora om och i s˚a fall hur prestandan f¨or¨andras.
F¨or att visa f¨or¨andringar i prestandan ¨ar testerna kvantitativa och genererar m¨atbar data ¨over hur l˚ang tid det tar f¨or databasen att behandla olika operationer.
Unders¨okningen har en experimentell ansats som syftar till att unders¨oka en f¨or¨andring vid olika i konfigurationer av databasen. Experimentet resulterar i en j¨amf¨orelse mellan prestandan i de olika konfigurationerna och ger en tydligare bild av eventuella f¨or¨andringar. F¨or presentationen av resultatet f¨oljer den h¨ar unders¨okningen den struktur med stapeldiagram och hela millisekunder som enhet som anv¨ants i [1] och [6].
2.2 Experiment
Prestandatesterna k¨ors mot en instans av databasen MongoDB. Testerna ¨ar uppdelade i tre faser. I f¨orsta fasen k¨ors testerna mot en databas med endast en nod d¨ar ingen replikation av datan hanteras. I andra fasen k¨ors testerna mot en databas med tv˚a noder och samma information replikeras p˚a b˚ada noderna. Den tredje fasen ¨ar lik den andra med skillnaden att testerna k¨ors mot en databas med tre noder och datan replikeras p˚a alla tre noderna.
Faserna ¨ar i sin tur uppdelade i fyra delar d¨ar f¨orsta delen best˚ar av ett inmatningstest som fyller databasen med information. Det andra testet ¨ar ett h¨amtningstest d¨ar infor-mationen h¨amtas fr˚an databasen. Det tredje testet ¨ar ett uppdateringstest som g˚ar ut p˚a att m¨ata tiden det tar att ¨andra den befintliga informationen och det sista testet ¨ar ett borttagningstest som i sin tur t¨ommer databasen p˚a information.
Testerna ¨ar automatiserade och k¨ors 100, 500, 1000, 5000, och 10000 g˚anger i snabb f¨oljd. De automatiserade testerna k¨ors tre g˚anger mot varje databaskonfiguration och sedan r¨aknas ett medelv¨arde av tiderna ut.
Databasen ¨ar inst¨alld s˚a att alla noder i de distribuerade databaskonfigurationerna kan hantera h¨amtningar.
Slutligen k¨ors ett haveritest f¨or att unders¨oka hur prestandan p˚averkas av att en nod havererar under k¨orningen.
2.2.1 Inmatningstest
F¨or inmatningstestet skapas ett databasobjekt. Objektet ¨ar av typen BasicDBObject som finns med i javadrivrutinerna f¨or MongoDB. Objektet kommer att best˚a av grundl¨aggande personuppgifter.
Inmatningen representerad i JSON: { “username”: username, “firstname”: “Test”, “lastname”: “Testsson”, “address”: { “street”: “Teststreet”, “streetnr”: “100”, “city”: “Testville”, “zip”: “12345” } }
Fokus ligger p˚a username och det ¨ar unikt f¨or varje inmatning. F¨or att garantera att username ¨ar unikt best˚ar det av ett nummer. F¨orsta inmatningen har “username”: “0”och sedan inkrementeras v¨ardet med ett f¨or varje inmatning. Efter att hela inmatningstestet ¨
ar k¨ort kontrolleras antalet dokument i databasen s˚a de st¨ammer ¨overens med anta-let k¨orningar. Inmatningen g¨ors via metoden collection.insert() i javadrivrutinerna f¨or MongoDB.
2.2.2 H¨amtningstest
I h¨amtningstestet g¨or f¨orfr˚agningar till databasen f¨or att f˚a ut informationen fr˚an inmat-ningstestet. F¨orfr˚agningarna kommer att g¨oras utifr˚an username d˚a det ¨ar unikt f¨or varje dokument. Vid h¨amtningstestet kontrolleras ¨aven att svaret fr˚an databasen inte har v¨ardet null f¨or att garantera att databasen har returnerat ett korrekt dokument. H¨amtningen g¨ors via metoden collection.findOne() i javadrivrutinerna f¨or MongoDB.
2.2.3 Uppdateringstest
I uppdateringstestet ¨andras v¨ardet i f¨altet “streetnr”fr˚an “100”till “110”f¨or varje en-skilt dokument i databasen. I testet anv¨ands “username”f¨or att hitta varje individuellt dokument. Uppdateringen g¨ors via metoden collection.update() i javadrivrutinerna f¨or MongoDB.
2.2.4 Borttagningstest
I borttagningstestet tas varje dokument bort enskilt. D˚a “username”¨ar unikt anv¨ands det som s¨okv¨ag ¨aven i det h¨ar testet. Efter testet har itererat genom alla “username”kontrolleras att databasen inte inneh˚aller n˚agra dokument. Borttagningen g¨ors via metoden collec-tion.findAndRemove() i javadrivrutinerna f¨or MongoDB.
2.2.5 Haveritest
Under haveritestet ¨ar tre noder aktiva: en prim¨ar, en sekund¨ar och en arbiter. Haveri-testet testar h¨amtningar och uppdateringar p˚a samma s¨att som under h¨amtningstestet och uppdateringstestet med skillnaden att en av noderna st¨angs av under testets g˚ang. Avst¨angningen av vald nod sker genom att processen f¨or MongoDB avslutas lokalt 10 se-kunder efter testets start. Testet best˚ar av 5000 h¨amtningar och 5000 uppdateringar och testar b˚ade haveri av den prim¨ara noden och den sekund¨ara noden.
2.3 Testplattform 2.3.1 H˚ardvara
D˚a databasen ska vara distribuerad f¨or det test som utf¨ors m˚aste databasen sp¨anna ¨over flera individuella enheter. Valet blev d¨arf¨or att anv¨anda tre stycken raspberry pi d˚a dessa ¨
ar identiska. Specifikation:
• Raspberry Pi 2 med ett 8 gb klass 10 SD-kort, Rasbian
F¨or att k¨ora testerna med ett s˚a j¨amf¨orbart resultat som m¨ojligt k¨ors testerna mot data-basen fr˚an en extern dator. Den externa datorn ¨ar kopplad i samma lokala n¨atverk som de tre raspberry pi som har databasen.
Specifikation:
• PC intel core i7, Windows 7
Det lokala n¨atverket hanteras av en router. Router modell:
• D-link DIR 615 2.3.2 Mjukvara
De automatiserade testerna ¨ar kodade i Java. F¨or att testerna ska kunna k¨oras mot en databas av typen MongoDB har ett bibliotek med drivrutiner f¨or MongoDB lagts till. Koden f¨or de automatiserade testerna ¨ar presenterad i Bilaga A.
Bibliotek:
• mongo-java-driver-3.2.2 Utvecklingsm¨olj¨o:
• IntelliJ IDEA 14.1.1 Databas:
• MongoDB version 2.4.10 32-bitar
2.4 Metoddiskussion
F¨or att se hur prestandan i MongoDB f¨or¨andras om antalet kopior ¨okar anv¨ands stan-dardkonfigurationen f¨or replica set. F¨or att f˚a j¨amf¨orbar data k¨ors f¨orst testerna mot en konfiguration med en nod d¨ar det inte f¨orekommer n˚agon replikation. Testerna k¨ors sedan mot en databas med tv˚a och tre noder. Anledningen till att b˚ade tv˚a och tre noder testas ¨
ar att kontrollera hur prestandan p˚averkas inom ett aktivt replica set.
De tester som k¨ors i j¨amf¨orelserna mellan MongoDB och SQL och MongoDB och Cassandra ¨ar baserade p˚a olika typer av belastningar (se [1][6]). I det h¨ar testet v¨aljs att fokusera testerna mot grundoperationerna i databaserna. De olika belastningar som testas ¨
ar inmatning, h¨amtning, uppdatering och borttagning och de testas separat f¨or att ge en tydlig bild ¨over eventuella f¨or¨andringar.
P˚a grund av att MongoDB anv¨ander sig av lazy konsistens kan det inte garanteras att noder har den uppdaterade informationen och f¨or att kontrollera detta har en funktion lagts till i testet som vid varje h¨amtning kontrollerar att svaret fr˚an databasen inte ¨ar null. D˚a kontrollen utf¨ors p˚a samtliga h¨amtningstest r¨aknas dess eventuella p˚averkan p˚a prestandan in i resultatet och p˚averkar inte skillnaden i prestanda.
Efter varje omg˚ang ins¨attningar och borttagningar kontrolleras ¨aven det totala antalet dokument som finns i databasen f¨or att se att operationerna har sparats korrekt.
Under haveritestet testas hur prestanda f¨or¨andras under f¨oruts¨attningen att tillg¨angligheten minskar. Testet utg˚ar ifr˚an att det tar lika l˚ang tid f¨or databasen att ˚aterh¨amta sig varje g˚ang och k¨ors d¨arf¨or bara med 5000 k¨orningar. Till haveritestet har en arbiter lagts till f¨or att s¨akra att databasen kan r¨osta fram en ny prim¨arnod n¨ar den havererar.
Utformningen av experiementet bortser fr˚an eventuella effekter routern kan ha p˚a resultatet. F¨or att garantera att de effekter som kan uppst˚a ¨ar samma i alla testfallen ¨
andras inga inst¨allningar i routern under experimentets g˚ang.
3
Resultat
3.1 Inmatningstest
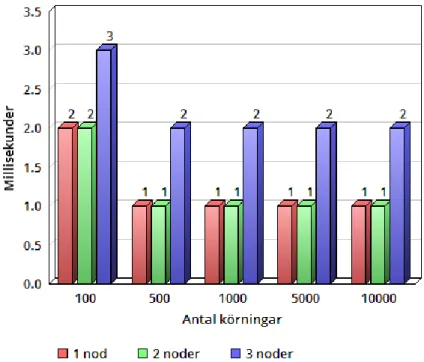
Vid inmatningstestet h¨oll alla databaskonfigurationerna en j¨amn niv˚a. Skillnaderna mellan de olika konfigurationerna var v¨aldigt sm˚a och visar att det inte tar l¨angre tid f¨or MongoDB att l¨agga ny information i databasen trots att den ska ha datan sparad p˚a flera noder. Resultatet av inmatningstestet visas i figur 1.
Figur 1: Inmatningstest
3.2 H¨amtningstest
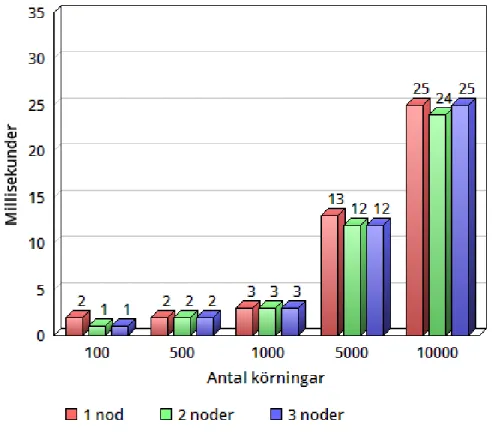
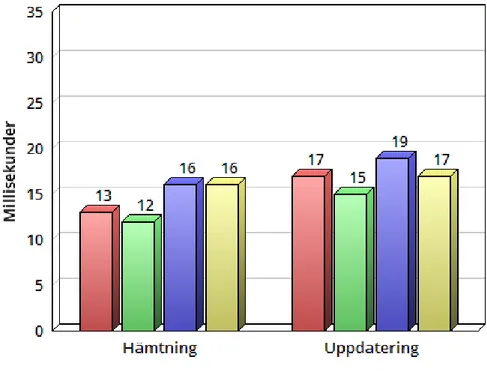
Vid h¨amtningstestet ¨okade tiderna efter hand som databasen hade mer information. Vid testerna med 100, 500 och 1000 h¨amtningar h¨oll databasen en j¨amn niv˚a f¨or att sedan ta l¨angre tid vid 5000 och 10000 h¨amtningar. Mellan de olika konfigurationerna fanns endast sm˚a skillnader och h¨amtningar tog lika l˚ang tid mot en databas med en, tv˚a och tre noder. Under h¨amtningstestet fanns alla inmatningar lagrade i databasen vid samtliga k¨orningar. Resultatet av h¨amtningstestet visas i figur 2.
Figur 2: H¨amtningstest
3.3 Uppdateringstest
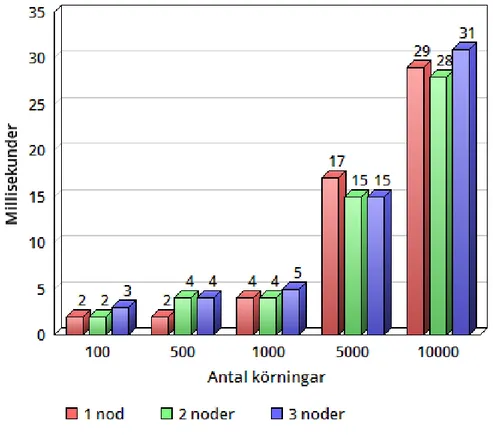
Resultatet vid uppdateringstestet var likt resultatet fr˚an h¨amtningstestet med skillnaden att varje operation tog n˚agra millisekunder l¨angre tid att utf¨ora. Tiderna h¨oll en j¨amn niv˚a under 100, 500 och 1000 uppdateringar f¨or att sedan ¨oka vid 5000 och 10000 upp-dateringar. Det var precis som i tidigare tester v¨aldigt sm˚a skillnader mellan de olika databaskonfigurationerna. Resultatet av uppdateringstestet visas i figur 3.
Figur 3: Uppdateringstest
3.4 Borttagningstest
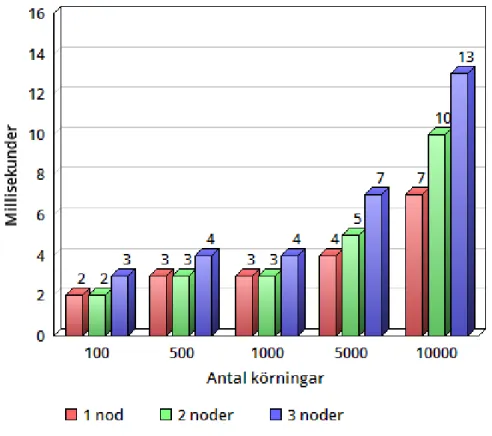
Vid borttagningstestet tog tiderna f¨or varje operation kortare tid ¨an vid h¨amtningstestet och uppdateringstestet. Tiderna ¨okade n˚agot vid 5000 och 10000 borttagningar. Vid bort-tagningstestet mot databas med tv˚a och tre noder tog varje operation n˚agra millisekunder l¨angre tid. I ¨ovrigt var tiderna j¨amna mellan de olika konfigurationerna. Resultatet av borttagningstestet visas i figur 4.
Figur 4: Borttagningstest
3.5 Haveritest
Under haveritestet br¨ots processen hos en av noderna i databasen. Under h¨amtningsdelen av testet var tiden n˚agra millisekunder l˚angsammare ¨an tiden fr˚an h¨amtningstestet och det var ingen skillnad mellan om prim¨arnoden havererade eller om sekund¨arnoden havererade. Under uppdateringsdelen av testet var det st¨orre skillnad om prim¨arnoden havererade ¨
an om sekund¨arnoden havererade. Vid haveri av prim¨arnoden hamnade snittiden n˚agot ¨
over tiderna fr˚an uppdateringstestet medan vid haveri av sekund¨arnoden var det ingen skillnad. Vid haveri av prim¨arnoden skedde en omr¨ostning om ny prim¨arnod vilket gjorde att databasen f¨orsattes i ett ej responsivt l¨age i n˚agra sekunder. I resultatet av haveritestet j¨amf¨ors tiderna vid haveri med tiderna fr˚an h¨amtningstestet och updateringastestet d¨ar ej haveri f¨orekommit. Resultatet av haveritestet visas i figur 5.
Figur 5: Haveritest
4
Analys
Resultatet av unders¨okningen som utf¨ors visar att MongoDB h˚aller en j¨amn niv˚a genom alla tester. Att testerna visar v¨aldigt lika resultat vid tester av standardoperationerna kan bero p˚a att f¨orfr˚agningar endast skickas direkt efter varandra. Om testerna genererats pa-rallellt hade resultatet troligen blivit annorlunda vid h¨amtningar. Databasen borde kunna hantera fler h¨amtningar desto fler noder som l¨aggs till men d˚a alla f¨orfr˚agningar skickas efter varandra hanteras bara en f¨orfr˚agning ˚at g˚angen.
Testresultaten visar att databasen inte f¨orlorar n˚agon prestanda p˚a grund av intern kommunikation. Trots att tiderna fr˚an testerna h¨oll j¨amn niv˚a fanns all information lagrad i databasen vid samtliga h¨amtningar. Med de inst¨allningar garanterar inte ett MongoDB replica set vilken nod som skickar tillbaka informationen vid h¨amtningar vilket betyder att en av de sekund¨ara noderna kan hantera de f¨orfr˚agningarna [10]. Inte under n˚agot av h¨amtningstesterna returnerade databasen ett nullv¨arde.
Att databasen kunde h˚alla en h¨og prestanda vid inmatningstestet, uppdateringstestet och borttagningstestet under alla belastningar beror p˚a att lazy konsistens implementerats [2]. Vid inmatningstestet var tiderna helt oberoende av databasens storlek och det kan f¨orklaras med att prim¨arnoden inte beh¨over g¨or mer ¨an att l¨agga till det nya dokumentet och skicka ett svar tillbaka. Replikationen sker efter att svaret skickats vilket g¨or att sj¨alva operationen upplevs som extremt snabb.
Vid uppdateringstestet och h¨amtningstestet beh¨ovde databasen s¨oka upp informatio-nen innan svar kunde skickas tillbaka vilket gjorde att tiderna ¨okade i takt med belastning-en. Att uppdateringstestet endast tog ett f˚atal millisekunder l¨angre tid ¨an h¨amtningstestet beror p˚a att uppdateringen av dokumentet g¨ors bara i prim¨arnoden innan svar skickas till-baka. [10]
Vid haveritestet visades hur prestandan p˚averkades i samband med haveri av prim¨arnoden eller sekund¨arnoden i en databaskonfiguration med tv˚a lagrande noder. Under testet av-br¨ots en av noderna f¨or att se hur det p˚averkade snittiden f¨or h¨amtningar och uppda-teringar. N¨ar prim¨arnoden bryts kallar de andra noderna till en omr¨ostning [10]. Detta ledde till ett avbrott i exekveringen av de automatiska testerna och ¨okade snittiden med n˚agra f˚atal millisekunder. Vid avbrott av den sekund¨ara noden ¨okade tiden mindre vid uppdateringar ¨an vad den gjorde n¨ar prim¨arnoden avbr¨ots. Testerna f¨or h¨amtning och uppdatering ¨ar i denna unders¨okningen utformade s˚a att systemet f˚ar en ny koppling till databasen innan f¨orfr˚agningarna forts¨atter efter haveri vilket inte alltid ¨ar fallet i verkliga scenario. I ett verkligt scenario hade uppdateringar kunnat g˚a f¨orlorade och h¨amtningar hade kunnat utebli under de f˚a sekunder databasen ej ¨ar responsiv.
5
Diskussion
Resultatet i den h¨ar unders¨okningen visade v¨aldigt sm˚a skillnader mellan de olika data-baskonfigurationerna. Att resultaten inte visar en f¨ors¨amring i prestanda trots mer intern kommunikation och fler kopior av informationen tyder p˚a att lazy konsistens ¨ar ett stark alternativ till eager. Eftersom lazy oftast implementeras p˚a bekostnad av databasens kon-sistens skulle problem kunna uppst˚a vid h¨amtningar, uppdateringar och borttagningar men inga problem uppvisades under testernas g˚ang vilket tyder p˚a att databasen hanterat synkroniseringen p˚a ett smidigt s¨att utan att minska prestandan.
F¨or att uppn˚a ett mer varierat resultat kunde testerna k¨orts parallellt fr˚an flera in-stanser. Med parallella tester borde tiden f¨or h¨amtningar skiljt sig mer fr˚an uppdateringar ¨
an vad resultatet av den h¨ar unders¨okningen visade. F¨or att ytterligare variera testerna skulle de olika operationerna kunna blandas. Om testerna k¨ort h¨amtningar, inmatningar och uppdateringar parallellt hade de varit mer lika ett verkligt scenario. Vid mer varierade testerna hade troligen skillnader mellan de olika databaserna ocks˚a kunnat presenteras.
Den m¨angden data som anv¨ands i testerna ¨ar relativt liten och om mer omfattande eller annorlunda strukturerad data anv¨ants vid inmatningstestet hade resultatet kunnat p˚averkas. Den data som anv¨ants i testerna ¨ar lik den data som kr¨avs f¨or en inloggning p˚a en mindre webbplats och passar d¨arf¨or bra med tanke p˚a vilken h˚ardvara som anv¨ants.
F¨or att ˚aterknyta till forskningsfr˚agorna visar resultaten fr˚an testerna av de olika grundoperationerna hur prestanda f¨or¨andras (eller inte f¨or¨andras) mellan en distribue-rad MongoDB-l¨osning med standardinst¨allningar och en med flera noder d¨ar replikation anv¨ands. Resultatet fr˚an haveritestet visar hur ett haveri p˚averkar prestandan i en repli-kerande MongoDB-l¨osning och redog¨or f¨or vissa risker som ett haveri medf¨or.
Under experimentet kan routern haft viss effekt p˚a resultatet.
6
Slutsatser och vidare forskning
Den h¨ar unders¨okningen har redogjort f¨or uttrycket replikation och f¨orklarat hur olika databastyper hanterar replikerad data med h¨ansyn till prestanda. Vid testerna bekr¨aftades att lazy konsistens inte f¨ors¨amrar prestandan trots att flera noder ska h˚alla samma data och att prestandan ej heller f¨orb¨attras om operationer sker efter varandra.
Vid haveritestet visades att data kan g˚a f¨orlorad om inte mjukvaran utanf¨or MongoDB hanterar det. Haveritestet visade ocks˚a att v¨aldigt lite tid g˚ar f¨orlorad under sj¨alva haveriet och att tiden f¨or MongoDB att ˚aterh¨amta sig ¨ar relativt snabb.
Som vidare forskning hade det varit intressant att se st¨orre tester av prestanda mot b˚ade MongoDB och andra databastyper som Cassandra och SQL med inriktning p˚a replikation. F¨or att simulera verkliga scenario skulle tester kunna innefatta parallella f¨orfr˚agningar och k¨oras mot databaser med m˚anga noder i mer komplexa konfiguratio-ner.
Referenser
[1] Abramova V, Bernardino J. NoSQL Databases: MongoDB vs Cassandra. C3S2E ’13 Proceedings of the International C* Conference on Computer Science and Software Engineering, New York, NY, USA 2013
[2] Charron-Bost B, Pedone F, Schiper A. Replication Theory and Practice. Berlin Heidelberg: Springer-Verlag; 2010.
[3] Coulon C, Pacitti E, Valduriez P. Consistency management for partial replication in a high performance database cluster. 11th International Conference on Parallel and Distributed Systems. 20-22 July 2005
[4] Kuznetsova S D, Poskoninb A V. NoSQL data management systems. Programming and Computer Software. November 2014, Volume 40, Issue 6, pp 323-332
[5] Mohan C. History repeats itself: sensible and NonsenSQL aspects of the NoSQL hoopla. EDBT ’13 Proceedings of the 16th International Conference on Extending Database Technology, Pages 11-16, New York, NY, USA 2013
[6] Parker Z, Poe S, Vrbsky S. Comparing NoSQL MongoDB to an SQL DB. C3S2E ’13 ACMSE ‘13 Proceedings of the 51st ACM Southeast Conference, Article No. 5, New York, NY, USA 2013
[7] Wiesmann M, Pedonet F, Schiper A, Kemmet B, Alonso G. Database Replication Techniques: a Three Parameter Classification. Proceedings The 19th IEEE Sympo-sium on Reliable Distributed Systems, Date 16-18 Oct. 2000. Nurnberg
[8] DataStax Apache Cassandra 2.0, DataStax, Inc. [H¨amtad: 2016-03-31]
<http://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/ architectureDataDistributeReplication_c.html>
[9] DB-Engines: Ratings, Solid IT. [H¨amtad: 2016-04-06] <http://db-engines.com/en/ranking>
[10] MongoDB: Manual, Oracle Corporation. [H¨amtad: 2016-04-06] <https://docs.mongodb.org/manual/>
[11] MongoDB: Replication Introduction, MongoDB, Inc [H¨amtad: 2016-03-31] <https://docs.mongodb.org/manual/core/replication-introduction/> [12] MySQL 5.7 Reference Manual, MongoDB, Inc. [H¨amtad: 2016-03-31]
<http://dev.mysql.com/doc/refman/5.7/en/replication.html> [13] Oracle8 Concepts Release 8.0, Oracle Corporation. [H¨amtad: 2016-03-31]
<http://docs.oracle.com/cd/A59447_01/nt_804ee/doc/database.804/ a58227/ch_repli.htm>
Bilaga A
Testkod
import com.mongodb.*; import com.mongodb.DB; import com.mongodb.MongoClient; import java.util.Arrays; /*** Created by Sebastian Nirfelt on 2016-03-03. */
public class Tests {
public void run(){
MongoClient mongo = new MongoClient(Arrays.asList(
new ServerAddress("192.168.0.102", 27017),
new ServerAddress("192.168.0.107", 27017)
new ServerAddress("192.168.0.106", 27017)); DB db = mongo.getDB("test");
DBCollection collection = db.getCollection("users");
long start = System.currentTimeMillis(); System.out.println("Test 100 runs:"); testInsert(100, collection); System.out.println(collection.getCount()); testRead(100, collection); testUpdate(100, collection); testDelete(100, collection); System.out.println(collection.getCount()); System.out.println("Test 500 runs:"); testInsert(500, collection); System.out.println(collection.getCount()); testRead(500, collection); testUpdate(500, collection); testDelete(500, collection); System.out.println(collection.getCount()); System.out.println("Test 1000 runs:"); testInsert(1000, collection); System.out.println(collection.getCount()); testRead(1000, collection); testUpdate(1000, collection); testDelete(1000, collection); System.out.println(collection.getCount()); System.out.println("Test 5000 runs:"); testInsert(5000, collection); System.out.println(collection.getCount()); testRead(5000, collection); testUpdate(5000, collection); testDelete(5000, collection); System.out.println(collection.getCount()); System.out.println("Test 10000 runs:"); testInsert(10000, collection);
System.out.println(collection.getCount()); testRead(10000, collection);
testUpdate(10000, collection);
testDelete(10000, collection);
System.out.println(collection.getCount());
long stop = System.currentTimeMillis(); mongo.close();
System.out.println("Total time: " + (int)((stop-start)/1000)/60 + " minutes");
System.out.println("\nDone!"); }
public void testInsert(int runs, DBCollection collection){
long start = System.currentTimeMillis();
for(int i = runs-1; i >= 0; i--){ collection.insert(build(i + "")); }
long stop = System.currentTimeMillis(); printResults("Insert", (stop-start)/runs); }
public void testRead(int runs, DBCollection collection){
long start = System.currentTimeMillis();
int i = 0;
while(i < runs){
try{
BasicDBObject query = new BasicDBObject(); query.put("username", i+"");
if(collection.findOne(query) == null) System.out.println("Read null");
i++;
}catch(Exception e) {} }
long stop = System.currentTimeMillis(); printResults("Read ", (stop - start)/runs); }
public void testUpdate(int runs, DBCollection collection){
long start = System.currentTimeMillis();
int i = 0;
while(i < runs){
try{
BasicDBObject query = new BasicDBObject(); query.put("username", i+"");
BasicDBObject newDocument = new BasicDBObject(); newDocument.put("streetnr", "100");
BasicDBObject update = new BasicDBObject(); update.put("$set", newDocument);
collection.update(query, update); i++;
}catch(Exception e) {} }
long stop = System.currentTimeMillis(); printResults("Update", (stop-start)/runs);
}
public void testDelete(int runs, DBCollection collection){
long start = System.currentTimeMillis();
for(int i = 0; i < runs; i++){
BasicDBObject query = new BasicDBObject(); query.put("username", i+"");
collection.findAndRemove(query); }
long stop = System.currentTimeMillis(); printResults("Delete", (stop-start)/runs); }
public BasicDBObject build(String username){ BasicDBObject payload = new BasicDBObject(); BasicDBObject address = new BasicDBObject(); payload.put("username", username);
payload.put("firstname", "Test"); payload.put("lastname", "Testsson"); address.put("street", "Teststreet"); address.put("streetnr", "100"); address.put("city", "Testville"); address.put("zip", "12345"); payload.put("address", address);
return payload; }
public void printResults(String type, long time){
System.out.println(type + ": " + time + " milliseconds"); }
}